Oracle11g温习-第一章:Oracle 体系架构
2013年4月27日 星期六
10:20
|
1、oracle 网络架构及应用环境 |
|
|
|
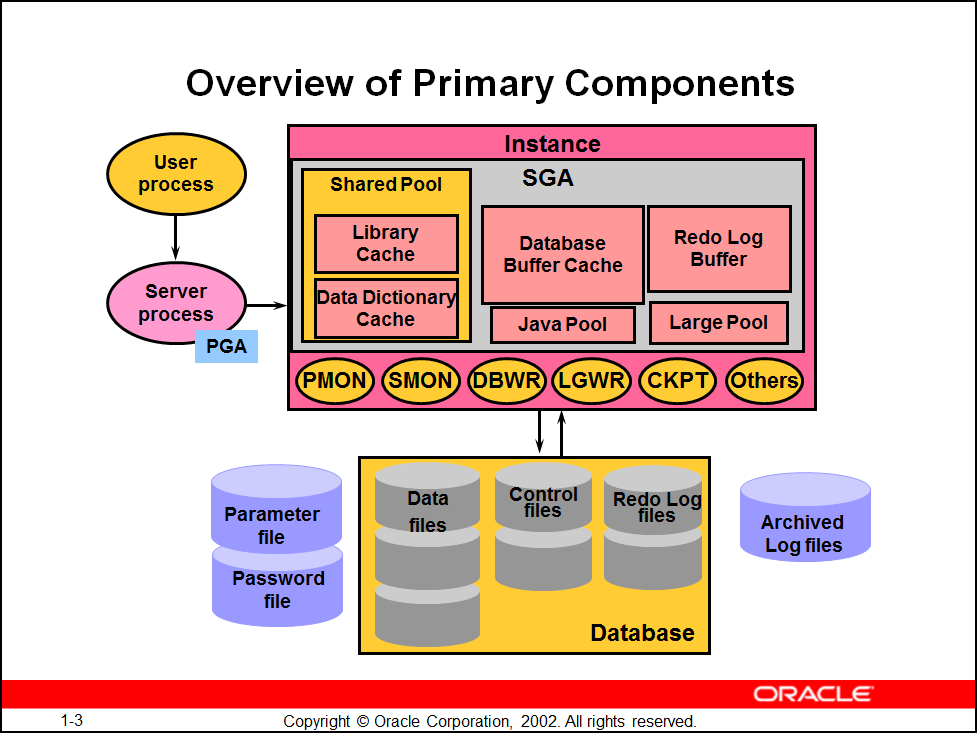
1、 ORACLE 实例——包括内存结构与后台进程 2、 ORACLE 数据库——物理操作系统文件的集合 3、 了解内存结构的组成 4、 了解后台进程的作用 5、 了解数据库的物理结构 6、 了解数据库的逻辑结构 |
|
2、oracle 体系结构 |
|
1)oracle server :database + instance 2)database:data file 、control file 、 redolog file 3)instance(实例):access a database,用实例来访问数据库,一个数据库一次只能打开一个实例,实例由sga和后台进程组成 ——oracle memory: sga + pga
4)instance :sga + backgroud process 5)sga组成:sga 在一个instance只有一个sga,sga所有的session共享,随着instance启动而分配,instance down ,sga被释放。
--------查看OS分配给oracle的内存------------------------------------------------------
[oracle@work oradata]$ ipcs
------ Shared Memory Segments -------- key shmid owner perms bytes nattch status 0x995eb2e8 65537 oracle 640 379584512 18
------ Semaphore Arrays -------- key semid owner perms nsems 0xbe3edae0 98304 oracle 640 44
------ Message Queues -------- key msqid owner perms used-bytes messages
[oracle@work oradata]$ ipcs -m
------ Shared Memory Segments -------- key shmid owner perms bytes nattch status 0x995eb2e8 65537 oracle 640 379584512 18 3. 内存自动管理:(Oracle Automatic Shared Memory Management -ASMM)
sga_max_size sga_target: share pool 、data buffer、large pool、java pool、stream pool【自动管理这5个池的内存大小】 【sga_target <= sga_max_size,大于0就等于启动ASMM】 granules(颗粒):组成oracle内存的最小单位 sga_max_size <1g ,4m sga_max_size >1g ,16m
-------查看内存颗粒
SYS @ prod > select name ,bytes/1024/1024 "Size(M)" from v$sgainfo; 【查看内存颗粒】
NAME Size(M) -------------------------------- ---------- Fixed SGA Size 1.16238022 Redo Buffers 2.8359375 Buffer Cache Size 80 Shared Pool Size 60 Large Pool Size 0 Java Pool Size 24 Streams Pool Size 0 Granule Size 4 Maximum SGA Size 244 Startup overhead in Shared Pool 28 Free SGA Memory Available 76 6)share pool : sql 语句的执行过程: 1)parse (语法分析、语义分析) 2)execute (建立计划,并执行) (sql硬解析从头开始,软解析从执行计划开始) 3)fetch 返回结果
library cache:存放最近使用的sql和plsql 代码【库缓存,减少硬解析的次数】 dictionary cache: 存放数据字典信息
SYS @ prod > SELECT shared_pool_size_for_estimate "SP", estd_lc_size "EL", estd_lc_memory_objects "ELM",estd_lc_time_saved "ELT", estd_lc_time_saved_factor as "ELTS",estd_lc_memory_object_hits as "ELMO" from v$shared_pool_advice;
SP EL ELM ELT ELTS ELMO ---------- ---------- ---------- ---------- ---------- ---------- 60 17 2465 514 1 35837 76 32 3921 514 1 36029 92 47 5292 514 1 36108 108 49 5718 514 1 36108 124 49 5718 514 1 36108 140 49 5718 514 1 36108 156 49 5718 514 1 36108 172 49 5718 514 1 36108 188 49 5718 514 1 36108 204 49 5718 514 1 36108 220 49 5718 514 1 36108 236 49 5718 514 1 36108 252 49 5718 514 1 36108 268 49 5718 514 1 36108 284 49 5718 514 1 36108 第一列表示Oracle所估计的shared pool的尺寸值,其他列表示在该估计的shared pool大小下所表现出来的指标值,具体含义可以参见Oracle的联机帮助。我们主要关注estd_lc_time_saved_factor列的值,当该列值为1时,表示再增加shared pool的大小对性能的提高没有意义。
7)sga_target: sga内存分配自动管理(ASMM) sga_target =0 关闭ASMM,>0 启动内存自动管理(可以对share pool、data buffer、large pool、java pool 、stream pool 实现自动管理) sga_target<= sga_max_size
8) data buffer:存放从datafile 里读出的数据块的镜像。 db_cache_size --------指定default cache大小-----LRU 默认数据块放到default cache db_keep_cache_size keep 存放经常使用小表和索引等 db_recycle_cache_size 回收 存放偶尔做全表扫描的表的数据块
SYS @ prod > alter system set db_recycle_cache_size =12m; 【设置数据循环缓存的大小,大于零启动该缓存】 SYS @ prod> conn scott/tiger SCOTT @ prod > alter table emp storage ( buffer_pool recycle); 【将emp表的数据缓存设置为循环模式】 SCOTT @ prod > create index emp_ename_id on emp(ename) storage (buffer_pool keep); 【将视图设置的数据缓存设置为keep模式】 SCOTT @ prod > desc user_segments; Name Null? Type ----------------------------------------------------------------- -------- -------------------------------------------- SEGMENT_NAME VARCHAR2(81) PARTITION_NAME VARCHAR2(30) SEGMENT_TYPE VARCHAR2(18) TABLESPACE_NAME VARCHAR2(30) BYTES NUMBER BLOCKS NUMBER EXTENTS NUMBER INITIAL_EXTENT NUMBER NEXT_EXTENT NUMBER MIN_EXTENTS NUMBER MAX_EXTENTS NUMBER PCT_INCREASE NUMBER FREELISTS NUMBER FREELIST_GROUPS NUMBER BUFFER_POOL VARCHAR2(7)
SCOTT @ cuug > select segment_name,BUFFER_POOL from user_segments where segment_name='EMP';
SEGMENT_NAME BUFFER_ --------------------------------------------------------------------------------- ------- EMP1 DEFAULT
SCOTT @ cuug > select segment_name,BUFFER_POOL from user_segments where segment_name='EMP_ENAME_ID';
SEGMENT_NAME BUFFER_ --------------------------------------------------------------------------------- ------- EMP1_ENAME_ID KEEP
9) log buffer:存放redo entries ,用于recover “先记后写” 在设置日志缓冲区时,可以参考下面这个建议的公式来计算:1.5×(平均每个事务所产生的重做记录大小×每秒提交的事务数量)。
首先先找到总事务量是多少:
SYS @ cuug >select a.value as trancount from v$sysstat a,v$statname b where a.statistic# = b.statistic# and b.name = 'user commits';
TRANCOUNT ---------- 409
然后,找到系统总共的运行时间:
SYS @ cuug >select trunc(sysdate - startup_time)*24*60*60 as seconds from v$instance;
SECONDS ---------- 0
第三,找到产生的所有重做记录大小: SYS @ cuug > select value as redoblocks from v$sysstat where name = 'redo blocks written';
REDOBLOCKS ---------- 4108
最后,我们可以分别计算公式中的值:平均每个事务所产生的重做记录大小= redoblocks/trancount;每秒提交的事务数量=trancount/seconds。这样,最后所建议的日志缓冲区的大小可以写为:1.5×(redoblocks/trancount)×(trancount/seconds)。
10) large pool:做批处理、备份恢复、用share server模式【不使用URL队列】 11) java pool:java 代码的解析 12) pga : program global area
随着server process分配给每一个session,随着server process终止,而被释放,独立非共享存放用户游标、变量、控制信息数据排序、存放hash值
workarea_size_policy =auto ;实现pga 的自动管理
【11g中SGA+PGA 通过memory_target实现集中自动管理,10g的分开管理】 pga_aggregate_target >0 hash_area_size sort_area_size
13) process【进程】: user process、 server process 、background process
user process:客户端请求 server process:服务端进程 backgroud process : 查看 ps 、v$process 、v$bgprocess
----------查看后台进程 [oracle@oracle ~]$ ps -ef |grep ora_|grep -v grep
oracle 7618 1 0 08:33 ? 00:00:01 ora_pmon_lx02 oracle 7620 1 0 08:33 ? 00:00:00 ora_psp0_lx02 oracle 7622 1 0 08:33 ? 00:00:00 ora_mman_lx02 oracle 7624 1 0 08:33 ? 00:00:01 ora_dbw0_lx02 oracle 7626 1 0 08:33 ? 00:00:01 ora_lgwr_lx02 oracle 7628 1 0 08:33 ? 00:00:05 ora_ckpt_lx02 oracle 7630 1 0 08:33 ? 00:00:02 ora_smon_lx02 oracle 7632 1 0 08:33 ? 00:00:00 ora_reco_lx02 oracle 7634 1 0 08:33 ? 00:00:04 ora_mmon_lx02 oracle 7636 1 0 08:33 ? 00:00:03 ora_mmnl_lx02 oracle 7640 1 0 08:34 ? 00:00:00 ora_arc0_lx02 oracle 7642 1 0 08:34 ? 00:00:00 ora_arc1_lx02 oracle 7646 1 0 08:34 ? 00:00:00 ora_qmnc_lx02 oracle 7652 1 0 08:34 ? 00:00:00 ora_q000_lx02 oracle 7654 1 0 08:34 ? 00:00:00 ora_q001_lx02
SYS @ cuug > select a.pid,a.spid,b.name,b.description from v$process a,v$bgprocess b where a.addr=b.paddr and b.paddr<>'00';
PID SPID NAME DESCRIPTION ---------- ------------ -------------------------------------------------- -------------------------------------------------- 2 7618 PMON process cleanup 3 7620 PSP0 process spawner 0 4 7622 MMAN Memory Manager 5 7624 DBW0 db writer process 0 6 7626 LGWR Redo etc. 7 7628 CKPT checkpoint 8 7630 SMON System Monitor Process 9 7632 RECO distributed recovery 10 7634 MMON Manageability Monitor Process 11 7636 MMNL Manageability Monitor Process 2 13 7640 ARC0 Archival Process 0 14 7642 ARC1 Archival Process 1 16 7646 QMNC AQ Coordinator
dbwr: 1、从数据文件读数据块到 buffer cache、写脏块 2、释放data buffer空间
lgwr:写日志条目到redo logfile (必须在dbwr写脏块之前写入日志)
smon :正常关闭实例:触发检查点事件,进行instance recovery 1)写脏块 2)写redo log 3)未提交事务回滚 4)在控制文件、数据文件头部、redo log 记录检查点
未正常关闭实例:不生成检查点 打开实例时: smon: 1) roll forward 前滚 :利用redo 把已经写入redo logfile ,而未写入datafile的脏块进行重做(redo) 2) open 开库 3) roll back 回滚 :通过undo segment 将未提交的事务进行回滚
pmon :process monitor(监控session) ckpt :生成检查点 arcn :归档模式下,日志切换时,备份历史日志。
14) logic structure:database数据库、tablespace表空间、segment段、extent盘区、data block数据块
|