

第八回 字符串库(续)
字符串库在使用中还是有些问题的.
首先是字符串库中所有的字符串都是并列的关系,没有层次,导致在字符串库中查找某个字符会很不方便.所以需要一个归类的方法,所以我们在字符串库中引入了"组"的概念,我们可以把字符串库中的某些字符串标记为"组",表示这个字符串代表一个组,然后就可以为库里的其它字符串指定它们属于哪些组,像这样:
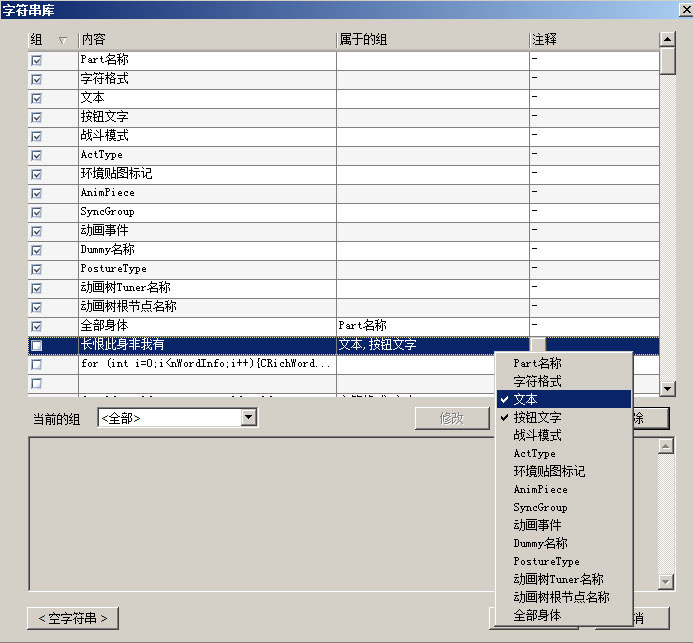
目前一个字符串可以属于多个组.组也可以属于另一个组
原文中提到过,当我们需要编辑一个字符串ID的值时,我们会为它指定一个语义,语义有两部分组成,一个预先定义好的code,和一个constraint字符串,我们可以在这个constraint字符串中传递一些编辑需要的额外信息.有了组的概念后,我们就可以在constraint中填入组的名字,而相应的字符串库编辑框则会检查这个constraint,并直接在编辑面板中显示出这个属于这个组的字符串来.比如一个按钮控件的数据结构可能是这样:
struct Button
{
StringID str;//按钮的文字
...
...
//对象描述信息
BEGIN_OBJ_DESC(Button,1);
GELEM_VAR_INIT(StringID,str,StringID_Invalid);//初始化为无效
GELEM_EDITVAR("String",GVT_UNSIGNED,GSem(GSem_StringID,"按钮文字"),"文本字符串");
...
...
END_OBJ_DESC();
};
(关于对象描述信息的内容,参见 http://www.cnblogs.com/ixnehc/archive/2008/09/15/1290939.html)
在编辑器中如下图,点击红框中的 ... 弹出字符串库编辑框.

这样可以让使用者方便一些.
还有一个问题是关于字符串库的版本更新的.一个字符串库保存为一个文件,被放到SourceSafe上,当任何人要修改它时,会去CheckOut这个文件,改完了再CheckIn. 但有个问题就是,在实际项目开发中,一般项目组会有一个SourceSafe Database,而引擎组也会有一个SourceSafe Database,这两个Database应该是完全分开的.引擎组和项目组都有可能会需要修改字符串库.当引擎组要给项目组更新引擎的最新版本时,问题就来了,怎么更新字符串库?没法混合,这两个都是独立的binary文件.这个问题花了我不少时间考虑,一度想把字符串库分成两个文件保存,但这会需要作大量的修改,同时代码上也会变得复杂,增加出错的几率.
最后我选择了一个相对简单,但是相对丑陋的解决方案.所有的编辑器会维护两个SourceSafe的连接,一个基本连接和一个扩展连接.
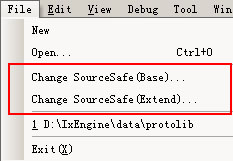
用户可以不设置扩展连接,这种情况下将使用基本连接进行SourceSafe控制,如果用户设置了扩展连接,那么字符串库将会使用这个扩展连接进行操作,注意是只有字符串库编辑框会用到这个扩展连接,编辑器的其它部分仍然使用基本连接.在实际应用中,项目组成员不需要设置扩展连接,而引擎组成员则要把扩展连接设置到项目组的Database上,也就是说引擎组和项目组成员将共用一个字符串库.而引擎组给项目组更新引擎版本的时候,将不会更新字符串库.
这的确是个丑陋的解决方法,为了区区一个字符串库,增加了一套新的SourceSafe连接.但这样做使问题简化了,避免了出错的可能性.并且也提供了一定的扩展性,说不定将来还有什么东西是要引擎组和项目组共享的呢?所以我选择了这个方案,希望没有选错.

