
常见排序算法总结分析之选择排序与归并排序-C#实现
本篇文章对选择排序中的简单选择排序与堆排序,以及常用的归并排序做一个总结分析。
常见排序算法总结分析之交换排序与插入排序-C#实现是排序算法总结系列的首篇文章,包含了一些概念的介绍以及交换排序(冒泡与快速排序)和插入排序(直接插入与希尔排序)的总结,感兴趣的同学可以先去看一下。
选择排序
选择排序主要包括两种排序算法,分别是简单选择排序和堆排序
简单选择排序
基本思想
每一趟在待排序列中选出最小(或最大)的元素,依次放在已排好序的元素序列后面(或前面),直至全部的元素排完为止。
简单选择排序也被称为直接选择排序。首先在待排序列中选出最小的元素,将它与第一个位置上的元素交换。然后选出次小的元素,将它与第二个位置上的元素交换。以此类推,直至所有元素排成递增序列为止。
选择排序是对整体的选择。只有在确定了最小数(或最大数)的前提下才进行交换, 大大减少了交换的次数。
复杂度与稳定性与优缺点
- 空间复杂度:O(1)
- 时间复杂度:O(n2)
- 最好情况:O(n2),此时不发生交换,但仍需进行比较
- 最坏情况:O(n2)
- 稳定性:不稳定,因为在将最小或最大元素替换到前面时,可能将排在前面的相等元素交换到后面去
- 优点:交换数据的次数已知(n - 1)次
- 缺点:不稳定,比较的次数多
算法实现
public void SimpleSelectionSort(int[] array){
for(int i = 0; i < array.Length - 1; i ++){
int index = i;
for(int j = index + 1; j < array.Length; j ++){
if(array[j] < array[index]){
index = j;
}
}
if(index != i)
Swap(array, i, index);
}
}
public void Swap(int[] array, int i, int j){
int temp = array[i];
array[i] = array[j];
array[j] = temp;
}
【算法解读】
初始时无序区为整个待排序列。算法内层循环遍历整个无序区的所有元素,找到其中最小的元素,用index记录其下标位置。然后将找到的最小元素与无序区的首元素进行交换,这样就完成了一趟选择排序,此时序列的首元素处于有序区中,剩下的元素处于无序区中。重复上面的操作,继续查找无序区中的最小元素,并将找到的最小元素和无序区首元素进行交换。直至完成所有排序。
【举个栗子】
对于待排序列3,1,4,2
首先将序列首元素3的索引0保存在index中,从元素1开始与index位置上的元素(此时是3)进行比较,1<3,则index保存元素1的索引。继续将index位置上的元素(此时是1)与元素4比较,4>1,继续与2比较,1<2,不需要改变。没有需要再比较的元素了,此时将index记录的索引位置上的元素3和无序区首元素进行交换。则完成一趟选择排序.,序列为1,3,4,2。有序区为1,无序区为3,4,2。继续下一趟排序,将找到的无序区最小元素,和无序区首元素进行交换。这一趟选择排序结束后,序列为1,2,4,3。有序区为1,2,无序区为4,3。重复上述操作直到完成排序。
堆排序
堆排序是借助堆来实现的选择排序。
什么是堆呢?堆是满足下列性质的数列{ R1, R2, R3, R4, ..., Rn }:
Ri<=R2i且Ri<=R2i + 1或者是Ri>=R2i且Ri>=R2i + 1,前者称为小顶堆,后者称为大顶堆。
例如小顶堆:{10,34,24,85,47,33,53},位置i(i从1开始)上的元素小于2i位置上的元素,且小于2i+1位置上的元素。绘制成堆的形状,如下图所示,可以发现每个堆的堆顶元素(每个二叉树的根节点)均小于其左子节点(2i)与右子节点(2i + 1)元素。
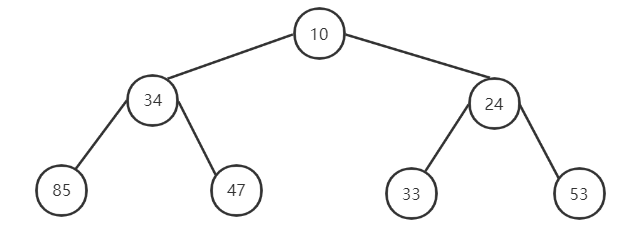
对于小顶堆而言,整个堆的堆顶元素便是整个序列的最小值,大顶堆同理。
基本思想
对待排序列的所有元素,首先将它们排成满足大顶堆或小顶堆的定义的序列,常称为建堆。建堆完成后堆顶元素便是最大或最小元素。然后将堆顶元素移出(比如移动到序列尾部),再对剩余的元素进行再建堆,常称为重新调整成堆,即可通过堆顶元素得到次大(次小)元素,如此反复进行,直到完成排序为止。
实现堆排序有两个关键步骤,建堆和调整堆
如何建堆:首先将待排序列画成一颗完全二叉树,然后再把得到的完全二叉树转换成堆。
从最后一个有孩子节点的节点(这样可以构成一颗有孩子的树,根节点才能够向下渗透)开始(对于数组而言就是下标为n / 2 - 1的节点)),依次将所有以该节点为根的二叉树调整成堆,即先调整子树,再调整父树,当这个过程持续到整颗二叉树树的根节点时,待排序列就被调整成了堆,即建堆完成。
如何调整堆:假设被调整的节点为A,它的左孩子为B,右孩子为C。那么当A开始进行堆调整时,根据上面建堆的方式,以B和以C为根的二叉树都已经为堆。如果节点A的值大于B和C的值(以大顶堆为例),那么以A为根的二叉树已经是堆。如果A节点的值小于B节点或C节点的值,那么节点A与值最大的那个孩子节点变换位置。此时需要继续将A与和它交换的那个孩子的两个孩子节点进行比较,以此类推,直到节点A向下渗透到适当的位置为止。
如果要从小到大排序,则使用大顶堆,如果要从大到小排序,则使用小顶堆。原因是堆顶元素需要交换到序列尾部
复杂度与稳定性与优缺点
- 空间复杂度:O(1)
- 时间复杂度:O(nlog2n)
- 最好情况:O(nlog2n)
- 最坏情况:O(nlog2n),它的最坏情况接近于平均性能
- 稳定性:不稳定
- 优点:在最坏情况下性能优于快速排序。由于在直接选择排序的基础上利用了比较结果形成堆。效率提高很大。
- 缺点:不稳定,初始建堆所需比较次数较多,因此记录数较少时不宜采用
算法实现
public void HeapSort(int[] array){
// 建堆
for(int i = array.Length / 2 - 1; i >= 0; i --){
BuildHeap(array, i, array.Length - 1);
}
// 调整堆
for(int i = array.Length - 1; i > 0; i --){
Swap(array, 0, i);
BuildHeap(array, 0, i - 1);
}
}
public void BuildHeap(int[] array, int left, int right){
int target = array[left];
for(int i = 2 * left + 1; i <= right; i = 2 * i + 1){
if(i < right && array[i + 1] > array[i]){
i ++;
}
if(target >= array[i]){
break;
}
array[left] = array[i];
left = i;
}
array[left] = target;
}
public void Swap(int[] array, int i, int j){
int temp = array[i];
array[i] = array[j];
array[j] = temp;
}
【算法解读】
算法也是按照先建堆再调整堆的步骤执行的。第一个for循环,从n / 2 - 1节点开始依次通过调用BuildHeap来形成堆,最终完成整个待排序列建堆。第二个for循环,利用之前已经建好的大顶堆(首元素为最大值),将首元素交换到序列末尾。然后将剩下的元素,再调整堆,再次获得大顶堆(首元素为次大值),将其首元素交换到倒数第二个位置,以此类推。
算法的关键点在于堆调整BuildHeap方法。该方法调整的节点为left位置的元素(称其为目标元素)。该元素的左右孩子分别是2 * left + 1,2 * left + 2。若目标元素大于等于它的的两个孩子,则已经是大顶堆,不需要调整了。否则,目标元素和两个孩子中的较大值交换(对应代码array[left] = array[i];,即向下渗透),并将left设置为目标元素交换后所在的位置,重复上述操作,直到目标元素渗透到适当的位置。
【举个栗子】
对于待排序列1,4,3,2
首先为了便于理解,我们可以将其画成二叉树:
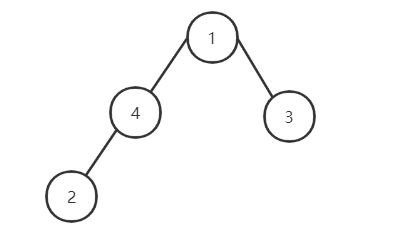
转换方法是将待排序列的元素,从上到下,从左到右,依次填入到二叉树的节点中。
开始建堆。本例中实际上只需要调整节点1,所以以调整节点1为例:过程如下图
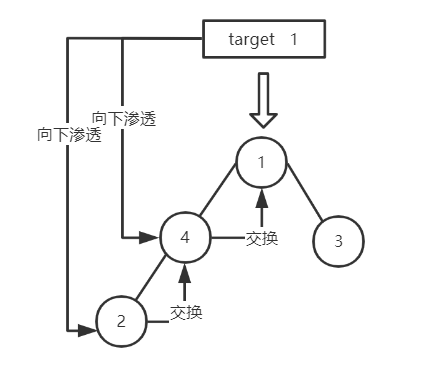
节点1作为目标元素,先找到其左右孩子(4和3)的较大值4,即比较目标元素1和4,1<4,则交换位置。目标元素1渗透到元素4位置(4被交换到1的位置)。在此位置上继续寻找,其左右孩子,此时只有一个左孩子,元素2,与目标元素做比较,1<2,则1渗透到2的位置,此时目标元素1已经向下渗透到最终位置。建堆成功,序列为4,2,3,1。然后通过大顶堆,得到首元素最大值4,并将其移动到序列尾部。去掉元素4后,再次建堆,重复上述操作,完成排序。
归并排序
基本思想
所谓归并是指,把两个或两个以上的待排序列合并起来,形成一个新的有序序列。2-路归并是指,将两个有序序列合并成为一个有序序列。
2-路归并排序的基本思想是,对于长度为n的无序序列来说,归并排序把它看成是由n个只包括一个元素的有序序列组成,然后进行两两归并,最后形成包含n个元素的有序序列
即先将待排序列通过递归拆解成子序列,然后再对已经排好序的子序列进行合并
复杂度与稳定性与优缺点
- 空间复杂度:O(n),因为在实现过程中用到了一个临时序列来暂存归并过程中的中间结果
- 时间复杂度:O(nlog2n)
- 最好情况:O(nlog2n)
- 最坏情况:O(nlog2n)
- 稳定性:稳定
- 优点:稳定,若采用单链表作为存储结构,可实现就地排序,不需要额外空间
- 缺点:需要O(n)的额外空间
算法实现
public void MergeSort(int[] array){
MergeSortImpl(array, 0, array.Length - 1);
}
public void MergeSortImpl(int[] array, int left, int right){
if(left >= right) return;
int middle = (left + right) / 2;
MergeSortImpl(array, left, middle);
MergeSortImpl(array, middle + 1, right);
Merge(array, left, middle, right);
}
// 合并两个子序列
public void Merge(int[] array, int left, int middle, int right){
int[] temp = new int[right - left + 1];
int index = 0, lindex = left, rindex = middle + 1;
while(lindex <= middle && rindex <= right){
if(array[rindex] < array[lindex]){
temp[index ++] = array[rindex ++];
}else{
temp[index ++] = array[lindex ++];
}
}
while(lindex <= middle){
temp[index ++] = array[lindex ++];
}
while(rindex <= right){
temp[index ++] = array[rindex ++];
}
while(--index >= 0){
array[left + index] = temp[index];
}
}
【算法解读】
算法首先通过递归,不断将待排序列划分成两个子序列,子序列再划分成两个子序列,直到每个子序列只含有一个元素(对应代码:if(left >= right) return;),然后对每对子序列进行合并。合并子序列是通过Merge方法实现,首先定义了一个临时的辅助空间,长度是两个子序列之和。然后逐个比较两个子序列中的元素,元素较小的先放入辅助空间中。若两个子序列长度不同,则必定有一个子序列有元素未放入辅助空间,因此分别对左边子序列和右边子序列中的剩余元素做了处理。最后,两个子序列的合并结果都存在于辅助空间中,将辅助空间中的有序序列替换到原始序列的对应位置上。
【举个栗子】
对于待排序列1,4,3,2
第一次递归,middle = 1,将待排序列分成(1,4),(3,2)。继续对每个子序列划分子序列。对于序列(1,4,),(3,2),middle都是0,即分别被划分成(1)(4),(3)(2)直到每个子部分只含有一个元素。然后开始合并,合并(1)(4)得到有序序列(1,4) ,合并(3)(2)得到有序序列(2,3)。再次合并(1,4)(2,3),得到最终有序序列(1,2,3,4)
更多
本篇文章算法的源码都放在了GitHub上,感兴趣的同学可以点击这里查看
更多算法的总结与代码实现(不仅仅是排序算法),可以查看GitHub仓库Algorithm了解
可以发现本篇所汇总的算法,时间复杂度最低也就是O(nlog2n),包括上一篇汇总讲到的交换排序和插入排序也是同样的结果。其实,基于比较的排序算法,时间复杂度的下界就是O(nlog2n),下一篇会总结分析可以突破下界O(nlog2n),达到O(n)的排序算法。敬请期待。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号