Java EE入门(四)——MySQL基础(DDL、DML、DQL、约束)
Java EE入门(四)——MySQL基础 (DDL、DML、DQL、约束)
iwehdio的博客园:https://www.cnblogs.com/iwehdio/
导图
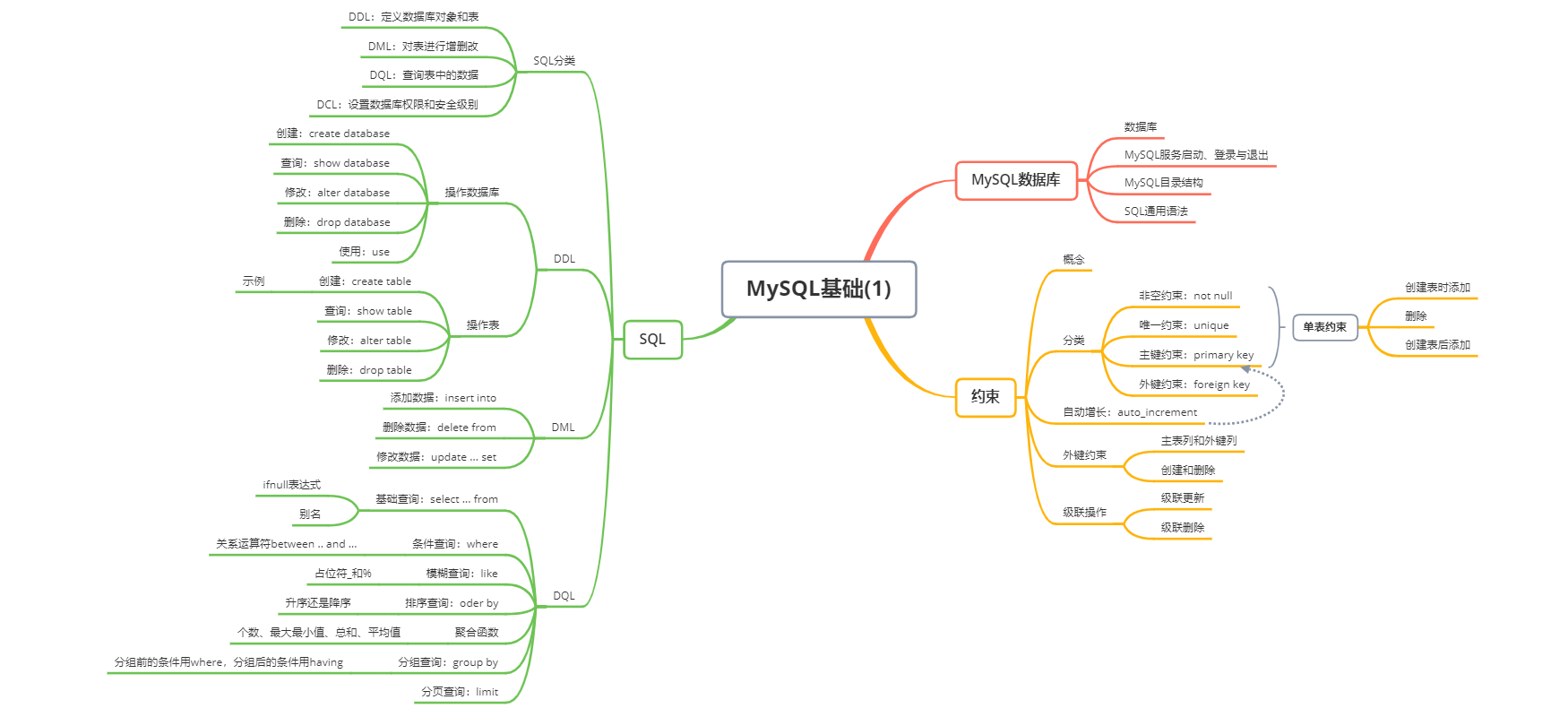
1、MySQL数据库
数据库:DataBase,简称 DB 。用于存储和管理数据的仓库。
- 数据库的特点:
- 持久化存储数据。其实数据库就是一个文件系统。
- 方便存储和管理数据。
- 使用了统一的方式来操作数据库(SQL)。
- MySQL 服务启动:
- 使用管理员打开命令行 cmd 。
- 使用命令
net start mysql:启动 mysql 服务。 - 使用命令
net stop mysql:关闭 mysql 服务。
- MySQL 的登录和退出:
- 登录:
mysql -uroot -proot:本地登陆,两个 root 分别是用户名和密码。mysql -h127.0.0.1 -uroot -proot:远程连接,127.0.0.1 是所要远程连接的 IP 地址。mysql --host=127.0.0.1 --uesr==root --password=root:远程连接。
- 退出:
exit和quit命令。
- 登录:
- MySQL 的目录结构:
- 安装目录:
- bin 下是二进制的可执行文件。
- share 下是报错信息。
- my.ini 是配置文件。
- 数据目录:
- data 下的文件夹对应数据库。
- 文件夹下的 .frm 文件对应数据库中的表。
- .frm 文件中的内容对应数据库中的数据记录。
- 安装目录:
2、SQL
SQL是结构化查询语言(Structured Query Language),是定义了所有关系型数据库的语言。但是每一种具体的数据库操作方式也有差别。
-
SQL 通用语法:
- SQL 语句可以单行或多行书写,以分号结尾。
- 可使用空格和缩进提高语句可读性。
- MySQL 数据库不区分大小写,但是关键字建议大写。
- 注释:
- 单行注释1:
-- 注释内容。(--后有一个空格) - 单行注释2:
# 注释内容。 - 多行注释:
/*注释内容*/。
- 单行注释1:
-
SQL 分类:
- Data Definition Language (DDL数据定义语言) ,用来定义数据库对象:数据库、表、列表。
- Data Manipulation Language(DML数据操纵语言),用来对表中的记录操作增删改。
- Data Query Language(DQL 数据查询语言),用来查询表中的记录(数据)。
- Data Control Language(DCL 数据控制语言),用来定义数据库的访问权限和安全级别。
3、DDL
- DDL:操作数据库和表。
-
操作数据库:CRUD。
- C(Creat):创建。
create database 数据库名:创建数据库。create database if not exists 数据库名:创建数据库前先判断该数据库名是否存在。creat database 数据库名 character set 字符集:设置指定字符集的数据库。
- R(Retrieve):查询。
show databases:查询所有数据库的名称。show create database 数据库名:查看数据库的创建语句(可以查询数据库的字符集)。
- U(Update):修改。
alter database 数据库名 character set 字符集:修改数据库的字符集。
- D(Delete):删除。
drop database 数据库名:删除数据库。drop database if exists 数据库名:删除前判断数据库是否存在。
- 使用数据库:
select database():查询当前正在使用的数据库。use 数据库名:使用数据库。
- C(Creat):创建。
-
操作表:CRUD。
-
C(Creat):创建。
-
create table 表名( 列名1 数据类型1, 列名n 数据类型n) ; # 列由逗号分隔,最后一列后不需要逗号 -
create table 表名2 like 表名1:创建一个表1的复制表2。 -
数据类型:
- int 整数类型。
int。 - double 小数类型。
double(m, n),共 m 位数字,小数点后 n 位。 - date 日期,包含年月日。
yyyy-MM--dd。 - datetime 日期,包含年月日时分秒。
yyyy-MM-dd HH:mmLss。 - timestamp 时间戳类型,包含年月日时分秒。
yyyy-MM-dd HH:mmLss。如果将来不给这个字段赋值,或者赋值为 null,则默认使用当前的系统时间自动赋值。 - varchar 字符串类型。
varchar(m),最大20个字符。
- int 整数类型。
-
例:创建一个表:
create table student( id int, name varchar(32), age int, score double(4, 1), birthday date, insert_time timestamp );
-
-
R(Retrieve):查询。
show tables:查询某个数据库中所有表的名称(前提先要进入使用数据库)。desc 表名:查询表结构。
-
U(Update):修改。
alter table 表名 rename to 新表名:修改表的名称。show create table 表名:查看表。alter table 表名 character set 字符集:修改表的字符集。alter table 表名 add 列名 数据类型:添加一列。alter table 表名 change 列名 新列名 新数据类型或alter table 表名 modify 列名 新数据类型:修改列的名称和类型。alter table 表名 drop 列名:删除一列。
-
D(Delete):删除。
drop table 表名:删除表。drop table if exists 表名:删除表前判断表是否存在。
-
4、DML
-
DML:增删改表中的数据。
-
添加数据。
insert into 表名(列名1, 列名2) values(值1, 值2):向列1、列2中分别添加数据。- 列名和值必须要按顺序一一对应,数据类型不能出错。
- 如果表名后不定义列名,则默认给所有列添加数据,但是所有列都要有对应的数据。如
insert into values(值1, 值2)。 - 除了数字类型,其他的数据类型都要用引号引起来(单引号双引号都可以)。
-
删除数据。
delete from 表名 where 删除条件:对于某个表,删除所有满足删除条件的数据(行)。- 如果不加条件,则删除表中的所有数据。
truncate table 表名:删除表,然后再创建一个完全相同的空表,可以用于删除表中的所有记录。
-
修改数据。
update 表名 set 列名1=值1,列名2=值2 where 修改条件:对于某个表,修改所有满足修改条件的数据,按列进行赋值。- 如果不加条件,则会将表中所有记录都修改。
5、DQL
-
基础查询:
select 字段列表 from 表名列表 where 条件列表 groub by 分组字段 having 分组后的条件字段 order 排序字段 limit 分页限定:DQL 的所有查询功能。select * from 表名:查询表中的所有值。select 字段列表 from 表名:字段列表是指逗号分隔的列名。select distinct 字段列表 from 表名:distinct 字段去除结果集中的重复值。select 列名1 + 列名2 from 表名:数值类型的两列按行相加。- 二者相加,如果有一个值为 null 则结果为 null 。使用
ifnull(表达式1,表达式2),表示如果表达式1为 null 字符,则结果替换为表达式2,否则取表达式1中的原值。 - 起别名:
列名 as 别名或列名 别名。
-
条件查询:
select * from 表名 where 条件列表:查询所有符合条件的值。- 关系运算符:< , > , >= , <= , <> , != , =(没有 ==)。or , and , between ... and ... (某列的值在二者之间), in (...) (某列的值在列表中)。
- null 值不能用等号等一般的关系运算符判断,要用 is 或 is not 来判断。
-
模糊查询:
select * from 表名 where 条件列表 like 查询字段:查询符合某个条件的值中,符合模糊查询字段的值。- 占位符:_ :下划线表示单个任意字符;% :百分号表示多个任意字符。如查询第二个字母是B的字段 '_B%',如查询字段中包含B的 '%B%'。
-
排序查询:
select * from 表名 order by 排序字段1 排序方式1,排序字段2 排序方式2:排序语法。排序字段就是列名,默认升序。- 排序方式:ASC——升序;DESC——降序。
- 如果有两个排序字段,则先满足排序字段1,对于字段1相同的再按排序字段2排序。有多个排序字段时同理。
-
聚合函数:
- 将一列数据作为一个整体,进行纵向计算。运算结果都是单行单列。
select 聚合函数(列名) from 表名:聚合函数按列计算。- 聚合函数:count——计算个数;max——计算最大值;min——计算最小值;sum——计算总和;avg——计算平均值。
- 聚合函数默认排除值为 null 的值(如n行数据中有一个为null,则count返回的值为n-1)。解决方法有:
- 选择不包含 null 的列。
- 使用
ifnull(列名, 0)。 - 使用表的主键。
-
分组查询:
- 按照一定条件分组,计算分组后的按列聚合函数值。
select 分组字段,聚合函数(列名) from 表名 group by 分组字段:分组字段是按某个列的值进行分组,然后求分组后某个列的聚合函数。select 分组字段,聚合函数(列名) from 表名 where 条件字段 group by 分组字段:在分组之前限定,不满足条件则不参与分组。where 后的条件字段不能跟聚合函数。select 分组字段,聚合函数(列名) from 表名 group by 分组字段 having 条件字段:在分组之后限定,不满足的结果不会被显示出来。having 后的条件字段可以跟聚合函数。- 在聚合函数后可以给其结果起别名:
聚合函数(列名) 别名。
-
分页查询:
- 将查询结果分为几页显示。
select * from 表名 limit 开始的索引,每页查询的条数:显示查询到的从开始索引开始的,与查询条数相等的结果。- 开始的索引 = ( 当前页码 - 1 ) × 每页显示的条数。
- 这种分页操作语法是MySQL中特有的。
6、约束
对表中的数据进行限定,保证数据的正确性、有效性和完整性。
-
约束的分类:
- 主键约束:primary key。
- 非空约束:not null。
- 唯一约束:unique。
- 外键约束:foreign key。
-
非空约束:
-
创建表时添加非空约束:
create table stu( # 创建后加 not null id int not null, name varchar(20) not null ); -
删除 id 的非空约束:
alter table stu modify id int。 -
创建表后添加 id 的非空约束:
alter table stu modify id int not null。
-
-
唯一约束:
-
创建表时添加唯一约束:
create table stu( # 创建后加 unique id int unique, name varchar(20) unique ); -
唯一约束对两个 null 不起作用。
-
删除 id 的唯一约束:
alter table stu drop index id。 -
创建表后添加 id 的唯一约束:
alter table stu modify id int unique。
-
-
主键约束:
-
主键约束,表示非空且唯一。
-
一张表只能有一个字段为主键,是表中记录的唯一标识。
-
创建表时添加主键约束:
create table stu( # 创建后加 primary key id int primary key , # 注意 key 后也有一个空格 name varchar(20) ); -
删除 id 的主键约束:
alter table drop primary key。 -
创建表后添加 id 的主键约束:
alter table stu modify id int primary key。
-
-
自动增长:
-
如果某一列是数值类型的,使用 auto_increment 可以来完成值的自动增长。一般和主键一起使用。
-
创建表时添加自动增长:
create table stu( # 创建后加 auto_increment id int primary key auto_increment, name varchar(20) ); -
自动增长的值只与上一条记录的值有关。
-
如果有自动增长,添加值时可以指定 id 为 null,这样可以添加成功,id 的值为自动增长赋予的。
-
即使有自动增长,也可以指定值,这时最终写入的值为所指定的值而不是自动增长的值。
-
删除 id 的自动增长:
alter table stu modify id int。 -
创建表后添加 id 的自动增长:
alter table stu modify id int auto_increment。
-
-
外键约束:
-
将外键表与主表中的主表列关联,让表与表之间产生关系,保证数据的正确性。
-
对于外键表中存在的冗余数据,可以通过外键列链接到另一个表(主表)中。外键列中存储的是主表中主表列的索引,根据外键列的值可以索引主表列,从而索引到所需要的数据行。
-
创建表时添加外键约束:
create table 主表名称( ..., 主表列 # 一般为主键约束,起码要为唯一约束 ); create table 外键表名( ..., 外键列, constraint 外键名称 foreign key (外键列名称) references 主表名称(主表列名称) ); -
添加外键约束后,主表中的行不能随意删除,除非此行的主表列的值在外键表中无对应数据。
-
外键列中外键列的值可以为 null ,但不能为主表列中不存在的值。
-
删除外键:
alter table 外键表名 drop foreign key 外键名称。 -
创建表后添加外键:
alter table 外键表名 add constraint 外键名称 foreign key (外键列名称) references 主表名称(主表列名称)。
-
-
级联操作:
- 由于外键约束,导致修改外键列和主表列的操作比较麻烦,需要使用级联操作。
- 级联更新:主表列中的值改变时,同时也改变外键列中所对应的值。
- 设置级联更新:
alter table 表名 add constraint 外键名称 foreign key (外键列名称) references 主表名称(主表列名称) on update cascade。 - 级联删除:主表列中的值所对应的行删除时,同时也删除外键列中值所对应的行。
- 设置级联删除
alter table 表名 add constraint 外键名称 foreign key (外键列名称) references 主表名称(主表列名称) on delete cascade。
iwehdio的博客园:https://www.cnblogs.com/iwehdio/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号