Java编程的逻辑 (55) - 容器类总结
从38节到54节,我们介绍了多种容器类,本节进行简要总结,我们主要从三个角度进行总结:
- 用法和特点
- 数据结构和算法
- 设计思维和模式
用法和特点
我们在52节展示过一张图,其中包含了容器类主要的接口和类,我们还是用这个图总结一下:
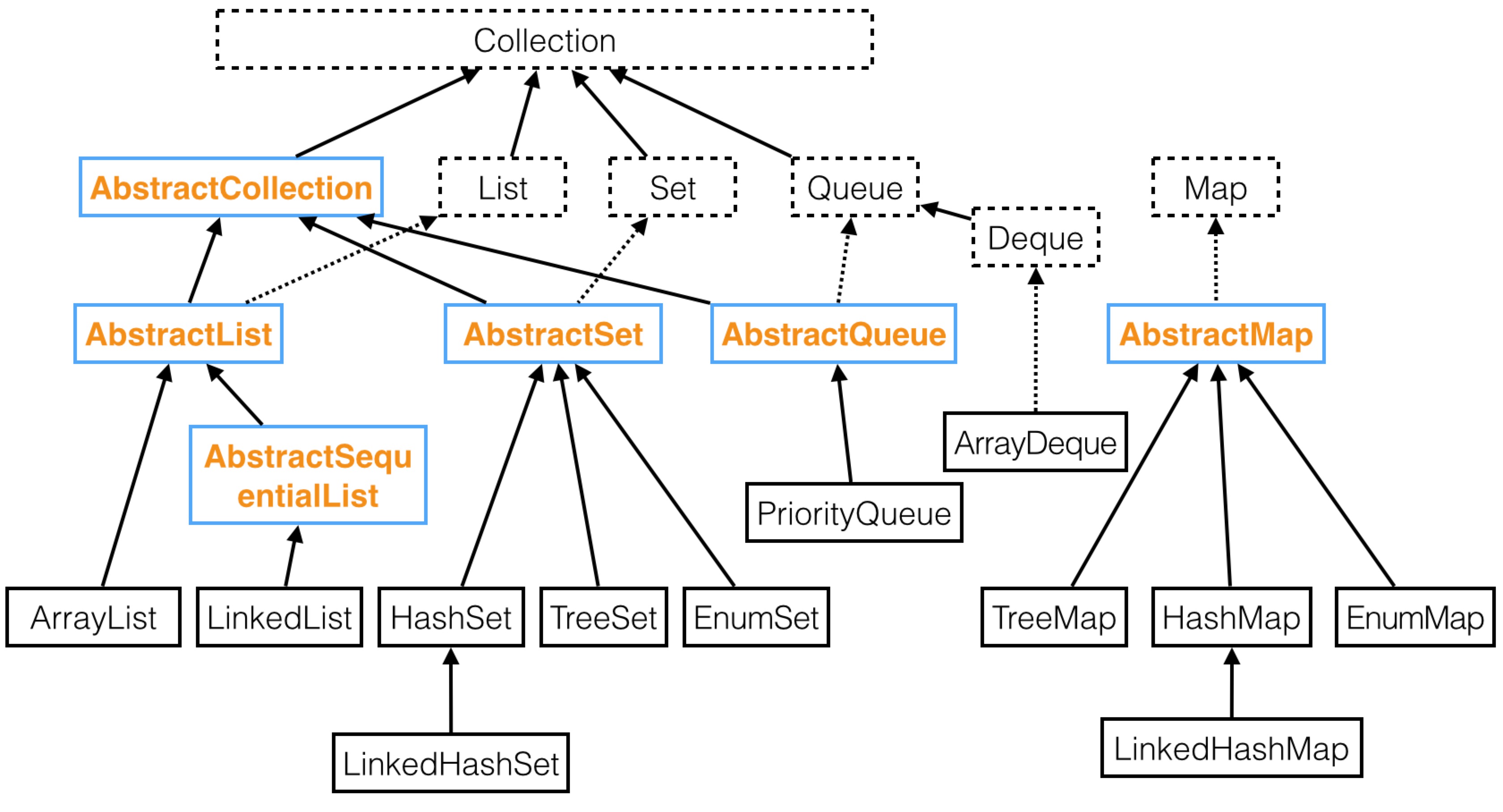
容器类有两个根接口,分别是Collection和Map,Collection表示单个元素的集合,Map表示键值对的集合。
Collection表示的数据集合有基本的增、删、查、遍历等方法,但没有定义元素间的顺序或位置,也没有规定是否有重复元素。
List是Collection的子接口,表示有顺序或位置的数据集合,增加了根据索引位置进行操作的方法。它有两个主要的实现类,ArrayList和LinkedList,ArrayList基于数组实现,LinkedList基于链表实现,ArrayList的随机访问效率很高,但从中间插入和删除元素需要移动元素,效率比较低,LinkedList则正好相反,随机访问效率比较低,但增删元素只需要调整邻近节点的链接。
Set也是Collection的子接口,它没有增加新的方法,但保证不含重复元素。它有两个主要的实现类,HashSet和TreeSet,HashSet基于哈希表实现,要求键重写hashCode方法,效率更高,但元素间没有顺序,TreeSet基于排序二叉树实现,元素按比较有序,元素需要实现Comparable接口,或者创建TreeSet时提供一个Comparator对象。HashSet还有一个子类LinkedHashSet可以按插入有序。还有一个针对枚举类型的实现类EnumSet,它基于位向量实现,效率很高。
Queue是Collection的子接口,表示先进先出的队列,在尾部添加,从头部查看或删除。Deque是Queue的子接口,表示更为通用的双端队列,有明确的在头或尾进行查看、添加和删除的方法。普通队列有两个主要的实现类,LinkedList和ArrayDeque,LinkedList基于链表实现,ArrayDeque基于循环数组实现,一般而言,如果只需要Deque接口,ArrayDeque的效率更高一些。
Deque还有一个特殊的实现类PriorityQueue,它表示优先级队列,内部是用堆实现的,堆除了用于实现优先级队列,还可以高效方便的解决很多其他问题,比如求前K个最大的元素、求中值等。
Map接口表示键值对集合,经常根据键进行操作,它有两个主要的实现类,HashMap和TreeMap。HashMap基于哈希表实现,要求键重写hashCode方法,操作效率很高,但元素没有顺序。TreeMap基于排序二叉树实现,要求键实现Comparable接口,或提供一个Comparator对象,操作效率稍低,但可以按键有序。
HashMap还有一个子类LinkedHashMap,它可以按插入或访问有序。之所以能有序,是因为每个元素还加入到了一个双向链表中。如果键本来就是有序的,使用LinkedHashMap而非TreeMap可以提高效率。按访问有序的特点可以方便的用于实现LRU缓存。
如果键为枚举类型,可以使用专门的实现类EnumMap,它使用效率更高的数组实现。
需要说明的是,我们介绍的各种容器类都不是线程安全的,也就是说,如果多个线程同时读写同一个容器对象,是不安全的。如果需要线程安全,可以使用Collections提供的synchronizedXXX方法对容器对象进行同步,或者使用线程安全的专门容器类。
此外,容器类提供的迭代器都有一个特点,都会在迭代中间进行结构性变化检测,如果容器发生了结构性变化,就会抛出ConcurrentModificationException,所以不能在迭代中间直接调用容器类提供的add/remove方法,如需添加和删除,应调用迭代器的相关方法。
在解决一个特定问题时,经常需要综合使用多种容器类。比如要统计一本书中出现次数最多的前10个单词,可以先使用HashMap统计每个单词出现的次数,再使用47节介绍的TopK类用PriorityQueue求前十个10单词,或者使用Collections提供的sort方法。
在之前各节介绍的例子中,为简单起见,容器中的元素类型往往是简单的,但需要说明的是,它们也可以是复杂的自定义类型,也可以是容器类型。比如在一个新闻应用中,表示当天的前十大新闻可以用一个List表示,形如List<News>,而为了表示每个分类的前十大新闻,可以用一个Map表示,键为分类Category,值为List<News>,形如Map<Category, List<News>>,而表示每天的每个分类的前十大新闻,可以在Map中使用Map,键为日期,值也是一个Map,形如Map<Date, Map<Category, List<News>>。
数据结构和算法
在容器类中,我们看到了如下数据结构的应用:
- 动态数组:ArrayList内部就是动态数组,HashMap内部的链表数组也是动态扩展的,ArrayDeque和PriorityQueue内部也都是动态扩展的数组。
- 链表:LinkedList是用双向链表实现的,HashMap中映射到同一个链表数组的键值对是通过单向链表链接起来的,LinkedHashMap中每个元素还加入到了一个双向链表中以维护插入或访问顺序。
- 哈希表:HashMap是用哈希表实现的,HashSet, LinkedHashSet和LinkedHashMap基于HashMap,内部当然也是哈希表。
- 排序二叉树:TreeMap是用红黑树(基于排序二叉树)实现的,TreeSet内部使用TreeMap,当然也是红黑树,红黑树能保持元素的顺序且综合性能很高。
- 堆:PriorityQueue是用堆实现的,堆逻辑上是树,物理上是动态数组,堆可以高效地解决一些其他数据结构难以解决的问题。
- 循环数组:ArrayDeque是用循环数组实现的,通过对头尾变量的维护,实现了高效的队列操作。
- 位向量:EnumSet是用位向量实现的,对于只有两种状态,且需要进行集合运算的数据,使用位向量进行表示、位运算进行处理,精简且高效。
每种数据结构中往往包含一定的算法策略,这种策略往往是一种折中,比如:
- 动态扩展算法:动态数组的扩展策略,一般是指数级扩展的,是在两方面进行平衡,一方面是希望减少内存消耗,另一方面希望减少内存分配、移动和拷贝的开销。
- 哈希算法:哈希表中键映射到链表数组索引的算法,算法要快,同时要尽量随机和均匀。
- 排序二叉树的平衡算法:排序二叉树的平衡非常重要,红黑树是一种平衡算法,AVL树是另一种,平衡算法一方面要保证尽量平衡,另一方面要尽量减少综合开销。
Collections实现了一些通用算法,比如二分查找、排序、翻转列表顺序、随机化重排、循环移位等,在实现大部分算法时,Collections也都根据容器大小和是否实现了RandomAccess接口采用了不同的实现方式。
设计思维和模式
在容器类中,我们也看到了Java的多种语言机制和设计思维的运用:
- 封装:封装就是提供简单接口,并隐藏实现细节,这是程序设计的最重要思维。在容器类中,很多类、方法和变量都是私有的,比如迭代器方法,基本都是通过私有内部类或匿名内部类实现的。
- 继承和多态:继承可以复用代码,便于按父类统一处理,但我们也说过,继承是一把双刃剑。在容器类中,Collection是父接口,List/Set/Queue继承自Collection,通过Collection接口可以统一处理多种类型的集合对象。容器类定义了很多抽象容器类,具体类通过继承它们以复用代码,每个抽象容器类都有详细的文档说明,描述其实现机制,以及子类应该如何重写方法。容器类的设计展示了接口继承、类继承、以及抽象类的恰当应用。
- 组合:一般而言,组合应该优先于继承,我们看到HashSet通过组合的方式使用HashMap,TreeSet通过组合使用TreeMap,适配器和装饰器模式也都是通过组合实现的。
- 接口:面向接口编程是一种重要的思维,可降低代码间的耦合,提高代码复用程度,在容器类方法中,接受的参数和返回值往往都是接口,Collections提供的通用算法,操作的也都是接口对象,我们平时在使用容器类时,一般也只在创建对象时使用具体类,而其他地方都使用接口。
- 设计模式:我们在容器类中看到了迭代器、工厂方法、适配器、装饰器等多种设计模式的应用。
小结
本节我们从用法和特点、数据结构和算法、以及设计思维和模式三个角度简要总结了之前介绍的各种容器类。到此为止,关于容器类我们就介绍完了。
到目前为止,我们还没有接触过文件处理,而我们在日常的电脑操作中,接触最多的就是各种文件了,让我们从下一节开始,一起探讨文件操作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号