BS4基本使用
bs4
- 数据解析的原理: - 1.标签定位 - 2.提取标签、标签属性中存储的数据值 - bs4数据解析的原理: - 1.实例化一个BeautifulSoup对象,并且将页面源码数据加载到该对象中 - 2.通过调用BeautifulSoup对象中相关的属性或者方法进行标签定位和数据提取
bs4是一个HTML/XML的解析器,主要的功能是解析和提取HTML/XML数据。它不仅支持CSS选择器,而且支持Python标准库中的HTML解析器,以及lxml的XML解析器,通过使用这些转化器,实现了惯用的文档导航和查找方式,节省了大量的工作时间,提高了开发项目的效率。
bs4库会将复杂的HTML文档换成树结构(HTML DOM),这个结构中的每个节点都是一个Python对象,这些对象可以归纳为如下四种:
bs4.element.Tag类:表示HTML中的标签,最基本的信息组织单元。它有两个非常重要的属性,分别为表示标签名字的name属性,表示标签属性的attrs属性。
bs4.element.NavigableString类:表示HTML中标签的文本(非属性字符串)。
bs4.BeautifulSoup类:表示HTML DOM中的全部内容,支持遍历文档树和搜索文档树的大部分方法。
bs4.element.Comment类:表示标签内字符串的注释部分,是一种特殊的NavigableString对象。
- 对象的实例化:
- 1.将本地的html文档中的数据加载到该对象中
fp = open('./test.html','r',encoding='utf-8')
soup = BeautifulSoup(fp,'lxml')
- 2.将互联网上获取的页面源码加载到该对象中
page_text = response.text
soup = BeatifulSoup(page_text,'lxml')
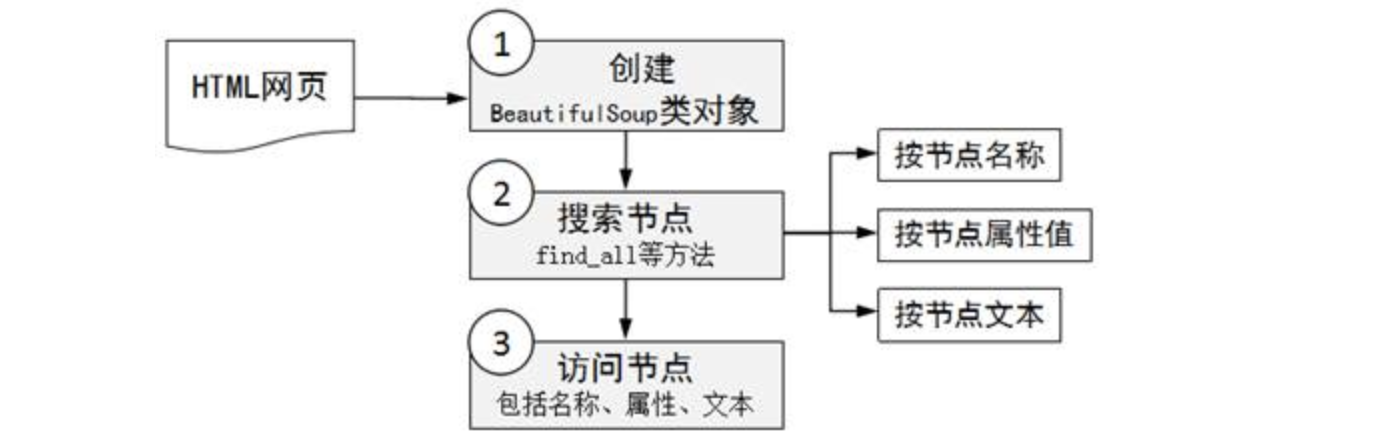
使用bs4流程
- 第1步:创建一个BeautifulSoup类型的对象
根据HTML或者文件创建BeautifulSoup对象。
- 第2步:通过上述对象的操作方法进行解读搜索
根据DOM树进行各种节点的搜索(比如,find_all方法可以搜索出所有满足要求的节点,find方法只 会搜索出第一个满足要求的节点),只要获得了一个节点,就可以访问节点的名称、属性和文本。
- 第3步:利用DOM树结构标签的特性,进行更为详细的节点信息提取
用法
soup.tagName:返回的是文档中第一次出现的tagName对应的标签
print(soup.a)
>>> <a name="top"></a>
soup.find():
- find('tagName'):等同于soup.div
- 属性定位:
-soup.find('div',class_/id/attr='song')
soup.find_all('tagName'):返回符合要求的所有标签(列表)
select
- select:
- select('某种选择器(id,class,标签...选择器)'),返回的是一个列表。
- 层级选择器:
- soup.select('.tang > ul > li > a'):>表示的是一个层级
- soup.select('.tang > ul a'):空格表示的多个层级
获取标签数据
- soup.a.text/string/get_text() - text/get_text():可以获取某一个标签中所有的文本内容 - string:只可以获取该标签下面直系的文本内容 获取属性值: soup.img['alt']
实战

根据层级可以找到章节名字
url = 'http://www.shicimingju.com/book/sanguoyanyi.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36'}
page_text = requests.get(url=url,headers=headers).text
from bs4 import BeautifulSoup
soup = BeautifulSoup(page_text,'lxml')
book_list = soup.select('.book-mulu > ul > li')
with open('chapters.txt', 'w', encoding='utf-8') as fp:
for i in book_list:
title = text = i.a.string
detail_url = 'https://www.shicimingju.com/' + i.a['href']
detail = requests.get(url=detail_url,headers=headers).text
detail_soup = BeautifulSoup(detail,'lxml')
context = detail_soup.find('div',class_ = 'chapter_content').text
fp.write(title +': ' + context+ '\n')
本文来自博客园,作者:ivanlee717,转载请注明原文链接:https://www.cnblogs.com/ivanlee717/p/17098501.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号