linux命令__grep【参数】
grep
grep命令的功能似乎过滤制定规则的信息。
冷知识:grep的名字来源于一个sed格式:g/re/p g:所有行,re:正则规则,p:打印
用法:
grep(global search regular express and print out line)打印匹配的行(内容)
类似的命令包括egrep、fgrep、rgrep
grep [OPTION...] PATTERNS [FILE...]
grep [OPTION...] -e PATTERNS ... [FILE...]
grep [OPTION...] -f PATTERN_FILE ... [FILE...]
grep在指定的文件中搜索包含PATTERN匹配的行。如果不指定文件或指定了“-”,则从标准输入中进行搜
索。 默认情况下,grep打印匹配的行。
此外,grep还有很多演变命令,如egrep、fgrep和rgpre,分别对应grep -E、grep -F和grep -r。
这些变种已经弃用,但他们被提供用作向后兼容。
选项
1. 匹配方式的选择
-E, --extended-regexp
将PATTERN作为扩展的正则表达式(ERE)
-F,--fixed-strings
将PATTERN作为为固定字符串的列表,由换行符分隔,匹配其中任意一个
-G, --basic-regexp
将PATTERN作为基本正则表达式(BRE),该选项为默认设置
-P,--perl-regexp
将PATTERN作为perl兼容正则表达式(PCRE)。
2. 匹配控制
-e PATTERN, --regexp=PATTERN
将PATTERN作为匹配项,如果该选项被多次使用或和-f(--file)选项一起使用,匹配所有
的匹配项。该选项可以用来保护以'-'开头的匹配项。
-f FILE,--file=FILE
将FILE中的每行都作为匹配项,如果此选项被多次使用或与-e(--regexp)选项组合使用,搜索所有给定的匹配项。空文件包含零个匹配项,因此不匹配任何内容
-i,--ignore-case
忽略匹配项的大小写
-v,--invert-match
反向匹配,选择没有匹配上的行
-w,--word-regexp
仅匹配完整单词,匹配的子字符串必须位于行的开头,或者前面有一个非字词字符。类似地,它必须位于行尾或后面跟非字词组成字符(字词组成字符是字母、数字和下划线)。
-x,--line-regexp
仅选择与整行完全匹配的匹配项。对于正则表达式匹配项,这类似于将匹配项括起来,然后用^和$将其包围。
-y 和-i作用相同,但已过时
3. 通用输出控制
-c,--count
不打印匹配结果,而是打印匹配的行数
--color[=WHEN],--colour[=WHEN]
将匹配到的字符串、行、上下文行、文件名、行号、字节偏移量和带转义符的分隔符(用于字段和上下文行组)序列着色,颜色有环境变量GREP_COLORS决定,虽然GREP_COLOR已经过时,但grep依然支持该环境变量,只不过优先权比GREP_COLORS低。WHEN可以为never、always和auto。相关环境变量介绍
:略。
-L,--files-without-match
不打印正常匹配结果,而是打印没有匹配上的文件的名称,扫描将在第一次匹配时停止。
-l,--files-with-matches
不打印正常匹配结果,而是打印匹配上的输入文件的名称,扫描将在第一次匹配时停止
-m NUM --max-count=NUM
在匹配到NUM行后停止读取文件
-o,--only-matching
仅打印匹配行中(非空的)匹配部分,每个部分在单独的输出行上
-q,--quiet,--silent
不向标准输出打印任何内容,匹配到内容立刻退出,即使检测到错误
-s,--no-messages
当文件不存在或文件不可读取时,不显示错误信息
4. 输出行前缀控制
-b,--byte-offset
在每行输出之前,打印输入文件中基于0的字节偏移量。如果指定了-o(--only-matching),则打印
匹配项本身的偏移量
-H,--with-filename
打印每个匹配的文件名,当匹配到多个匹配项时,该选项为默认配置
-h,--no-filename
在输出中不显示文件名,只匹配到单个结果时,默认不显示文件名
--label=LABEL
将标准输入显示为来自文件标签的输入(???不理解)
-n,--line-number
显示行号
-T,--initial-tab
使匹配结果中每行的第一个字符位于制表位上,以便制表的对齐看起来显得正常。该选项对一些给输出内
容加前缀的选项很有作用:-H、-n和-b
-u,--unix-byt-offsets
报告Unix样式的字节偏移量,此开关使grep报告字节偏移量,就像文件是Unix样式的文本文件一样,即
去掉CR字符。这将产生与在Unix机器上运行grep相同的结果。除非同时使用-b选项,否则此选项无效,
它对MS-DOS和MS Windows以外的平台没有影响。
-Z,--null
将文件名后面的符号(冒号或回车)改为零字节(ASCII NUL 字符),例如,grep -lZ在每个文件名
后输出一个零字节,而不是通常的换行。此选项使输出明确,甚至如果文件名包含不寻常的字符,如新行。
此选项可与其他命令一起使用,如find -print0、perl-0、sort-z和xargs-0来处理任意文件名,
甚至包含换行符的文件名。
5. 上下文控制
-A NUM,--after-context=NUM
在匹配行之后打印下文的NUM行,连续的匹配组之间用分隔符“--”隔开。和-o或--only-matching选项
一起使用时,该选项没有任何效果,并且会发出警告
-B NUM,--before-context=NUM
在匹配行的前面打印上文的NUM行,,连续的匹配组之间用分隔符“--”隔开。和-o或--only-matching
选项一起使用时,该选项没有任何效果,并且会发出警告
-C NUM,-NUM,--context=NUM
打印匹配行的上下文各NUM行,连续的匹配组之间用分隔符“--”隔开。和-o或--only-matching选项
一起使用时,该选项没有任何效果,并且会发出警告
6. 文件及目录的选择
-a,--text
像处理文本一样处理二进制文件,相当于--binary-files=text选项
--binary-files=TYPE
如果文件的前几个字节指示该文件包含二进制数据,则假定文件的类型为TYEP。默认情况下,TYPE为
binary,grep通常只输出一行表示二进制文件匹配的消息,或者因为没有匹配结果而没有输出;如果
TYPE为without-match,则grep不对二进制文件进行匹配,相当于-I选项;如果TYPE为text,grep
将二进制文件当作文本文件处理,这相当于-a选项,处理二进制数据时,grep可以将非文本字节视为行
终止符,例如,模式“.”(句点)可能不能匹配空字节,因为空字节可能被视为行终止符。警告:grep
--binary-files=text可能输出二进制垃圾,如果输出是终端且终端驱动程序将其中一些文本解释为
命令则可能会产生严重的副作用。
-D ACTION,--devices=ACTION
如果输入文件是一个设备、FIFO或则套接字,使用ACTION去处理它,ACTION默认为read,意味着该文
件将被当作普通文件进行读取。如果ACTION为skip,设备文件被忽略。
-d ACTION,--directories=ACTION
如果输入文件为一个目录,使用ACTION处理它。ACTION默认为read,即将目录作为普通文件处理。如果
ACTION为skip,跳过该目录。如果ACTION为recurse,递归读取目录下的所有文件,并且遵循命令行
符号链接,相当于-r选项
--exclude=GLOB
跳过名称与GLOB匹配的文件(使用通配符匹配),文件名glob可以使用*、?、和[…]作为通配符,并逐
字引用通配符或反斜杠字符。
--exclude-from=FILE
跳过其基名称与从FILE读取的任意文件名通过glob匹配的文件(使用通配符匹配,如--exclude下所述)
--exclude-dir=DIR
从递归搜索中排除与DIR匹配的目录
-I
处理二进制文件,就像它不包含匹配的数据一样,这相当于--binary-files=without-match选项。
--include=GLOB
搜索名称与从GLOB匹配的文件(使用通配符匹配,如--exclude下所述)
-r,--recursive
递归读取目录下的所有文件,并且遵循命令行符号链接。如果没有给定文件操作数,grep将搜索当前工作
目录。该命令相当于-d recurse选项
-R,--dereference-recursive
递归读取目录下所有文件,遵循所有符号链接
7. 其他选项
--line-buffered
在输出上使用行缓冲,这可能会导致性能下降
-U,--binary
将文件视为二进制文件,默认情况下,在MS-DOS和MS-Window中,grep通过读取文件前32KB的内容决
定这个文件的类型,如果文件为文本文件,grep从原始文件中删除CR字符(使带有‘^'和’$'的正则表达
式能正常工作),指定-U可以让其对文件进行逐字读取。如果文件为文本文件,每行末尾有CR/LF,这将
造成一些正则表达式失效。该选项对MS-DOS和MS-Windows以外的平台无影响。
-z,--null-data
将输入视为一组行,每个行以零字节(ASCII NUL字符)而不是换行符终止,与-Z或--null选项类似,
此选项可以与sort -z等命令一起使用,以处理任意文件名。
示例
1. 在文件中搜索字符串
grep -i 字符串 文件名

加上-n参数可以显示匹配出来的行号

显示不匹配的行-v

-v参数显示的就是不包含字符串的所有内容
2. 使用grep过滤命令输出

3. 使用正则
由于在grep中,基本正则表达式和扩展正则表达式在使用时的区别在于:在基本正则表达式中,元字符?、+、{、|、(、和)失去了特殊意义,需要使用反斜杠版本\?、+、{、|、(、和\)。如果不加任何匹配方式的选项,默认为-G,即基本正则表达式。

匹配某个字符在行首的情况

匹配某个字符在行尾的情况

匹配某个字符前有任意字符的情况

匹配某个字符前面是特定字符的情况

匹配某个字符前面不是特定字符的情况

4. 扩展正则
匹配 bz 或 gz 或 z 开头,后边跟 ip 的行,这里用到了扩展正则中的 小括号 和 或符号"|":
这里就需要用到-E参数,实质上是过滤多个参数的表达式匹配,用小括号扩起来表示一个整体

grep -E的用法等同于egrep

打印ip信息


上述两个命令里面,必须要加上转义符号才能表达符号原本的意思,
5. grep -F
grep -F PATTERN… [FILE…] 将PATTERN作为固定字符串形式的匹配项,不识别正则表达式。等同于fgrep命令
在实践中,我有一个需求,搜索日志关键字,而这一串关键字中包含了特殊字符,这些字符在正则式中有独特的语法,而你又不想用复杂的正则表达式去匹配的时候。那么grep -F 就派上了用场:

现在有这么一堆文件,里面包含了各式各样的文件名,如果我们想要找文件名为‘^abc’的文件

寻找efg$的文件:

与此类推:

6. grep -e
grep -e PATTERN… [FILE…] 和grep -f FILE… [FILE…]-e的作用和不加参数时类似,唯一区别是可以保护以‘-’开头的匹配项
[root@honey-master data] cat test
-test
test

-f的作用是将FILE中的每行都作为匹配项,和-e一样可以多次使用
把模板(pattern)写在一个文件里,然后使用-f参数来读取这些pattern,如果文件中包含0个pattern,那么什么都不匹配;如果有多个pattern,那么必须一行写一个pattern,即:打印后面文件中与前面文件中相同的行,并且,-f参数后面作为标准的文件一定不能有空格

我们可以看到使用test1文件去匹配test文件,所以输出会有全部的test文件内容
 这里解释了为什么-f参数后面的文件不能有空格。
这里解释了为什么-f参数后面的文件不能有空格。
7. grep -i
忽略大小写
[root@honey-master test] cat test
test1_ivanlee
test1_ivanlee1
tesT1_IVANlee2

8. grep -w
匹配完整的单词,单词前后不能有其他字母或数字,但允许单词前面有非字词符号(包括空格)。

9. grep -x
整行匹配

10. grep -c
打印匹配的行数

11. grep -color[=WHEN] PATTERN… [FILE…]
可以看到centos系统默认使用红色显示匹配项,只不过他只有三个选项,分别是never,auto,always
always和auto的区别就是,always会在任何情况下都给匹配字段加上颜色标记,当通过管道或重定向时就会多出一些控制字符,结果会变成
export [[1;32m[[KGREP[[m[[K_OPTIONS='--color=always'
export [[1;32m[[KGREP[[m[[K_COLOR='1;32'
而auto则只在输出到终端时才加上颜色。

如果想改变匹配颜色,可以修改./bashrc文件
export GREP_COLOR='a;b' #默认是1;31,即高亮的红色
来设置,其中:
a可以选择:【0,1,4,5,7,8】
0 关闭所有属性
1 设置高亮度
4 下划线

5 闪烁
7 反显
8 消隐
其他的效果太难看了~~~~
自己也可以去琢磨颜色,把b值设置为20就是绿色

12 grep -L和l
L不打印匹配的内容,打印FILE中没有匹配上的文件(不能是文件内容了,只能是文件名)。l打印匹配成功的文件名
13. grep -m
grep -m NUM PATTERN… [FILE…] 每个文件最多匹配出NUM行,
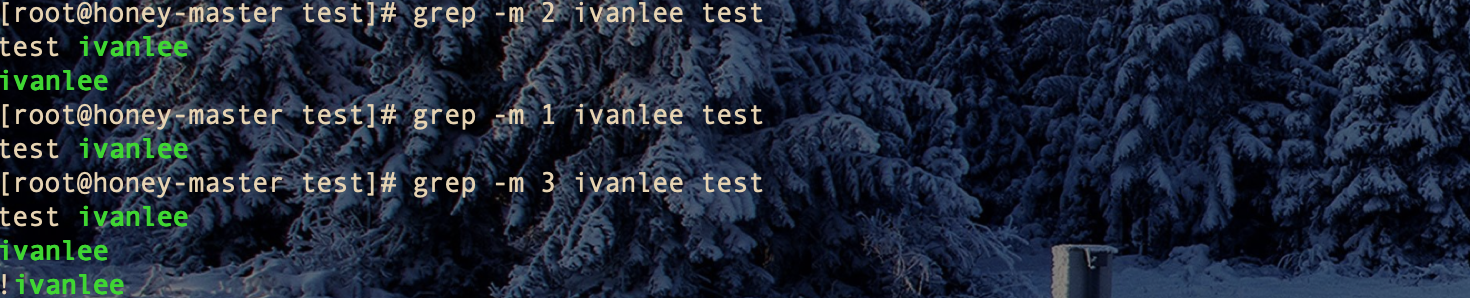
14. grep -o
仅打印匹配的内容,而不是匹配的一整行

15. grep -q
不显示匹配结果,匹配结束立刻退出
16. grep -s
不显示文件不存在和读取失败的错误信息

17. grep -b
打印匹配项基于文件开头的偏移量

18 grep -n
显示匹配项在文件中的行号

19 grep -h
不显示文件名,单个文件匹配时,默认不显示文件名

20. grep -T
显示时使用制表符

21. grep -Z
文件名后面的符号改为零字节(ASCII NUL字符)

22. grep -A

23. grep -a PATTERN… [FILE…]
将二进制文件当做文本文件来处理。
28. grep --binary-files=TYPE PATTERN… [FILE…]
TYPE的值可以为:binary(默认)、without-match、text,binary和without-match的区别是前者使用时会提示二进制文件无法匹配,后者不会提示,–binary-files=text相当于-a选项。
29. grep -r🌟🌟
递归搜索文件

本文来自博客园,作者:ivanlee717,转载请注明原文链接:https://www.cnblogs.com/ivanlee717/p/16340188.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号