
day24-20180526笔记
笔记:python3 复习Celery异步分布式
一、复习Celery异步分布式
Celery模块调用
既然celery是一个分布式的任务调度模块,那么celery是如何和分布式挂钩呢,celery可以支持多台不通的计算机执行不同的任务或者相同的任务。
如果要说celery的分布式应用的话,我觉得就要提到celery的消息路由机制,就要提一下AMQP协议。具体的可以查看AMQP的文档。简单地说就是可以有多个消息队列(Message Queue),不同的消息可以指定发送给不同的Message Queue,而这是通过Exchange来实现的。发送消息到Message Queue中时,可以指定routiing_key,Exchange通过routing_key来把消息路由(routes)到不同的Message Queue中去

多进程
多worker,多队列
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2018/05/27 09:10 # @Author : yangyuanqiang # @File : demon3.py from celery import Celery app = Celery() app.config_from_object("celeryconfig") @app.task def taskA(x, y): return x*y @app.task def taskB(x, y, z): return x+y+z @app.task def add(x, y): return x+y
上面的代码中,首先定义了一个Celery的对象,然后通过celeryconfig.py对celery对象进行设置。之后又分别定义了三个task,分别是taskA, taskB和add。接下来看看celeryconfig.py
注意:代码的缩进格式:
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2018/05/27 09:30 # @Author : yangyuanqiang # @File : celeryconfig.py from kombu import Queue, Exchange BROKER_URL = "redis://192.168.3.11:6379/1" CELERY_RESULT_BACKEND = "redis://192.168.3.11:6379/2" CELERY_QUEUES = { Queue("default",Exchange("default"),routing_key="default"), Queue("for_task_A",Exchange("for_task_A"),routing_key="for_task_A"), Queue("for_task_B",Exchange("for_task_B"),routing_key="for_task_B") } CELERY_ROUTES = { "demon3.taskA":{"queue":"for_task_A","routing_key":"for_task_A"}, "demon3.taskB":{"queue":"for_task_B","routing_key":"for_task_B"} }
配置文件一般单独写在一个文件中。
启动一个worker来指定taskA
ivandeMacBook-Pro:celery ivan$ celery -A demon3 worker -l info -n workerA.%h -Q for_task_A

启动一个worker来指定taskB
ivandeMacBook-Pro:celery ivan$ celery -A demon3 worker -l info -n workerB.%h -Q for_task_B
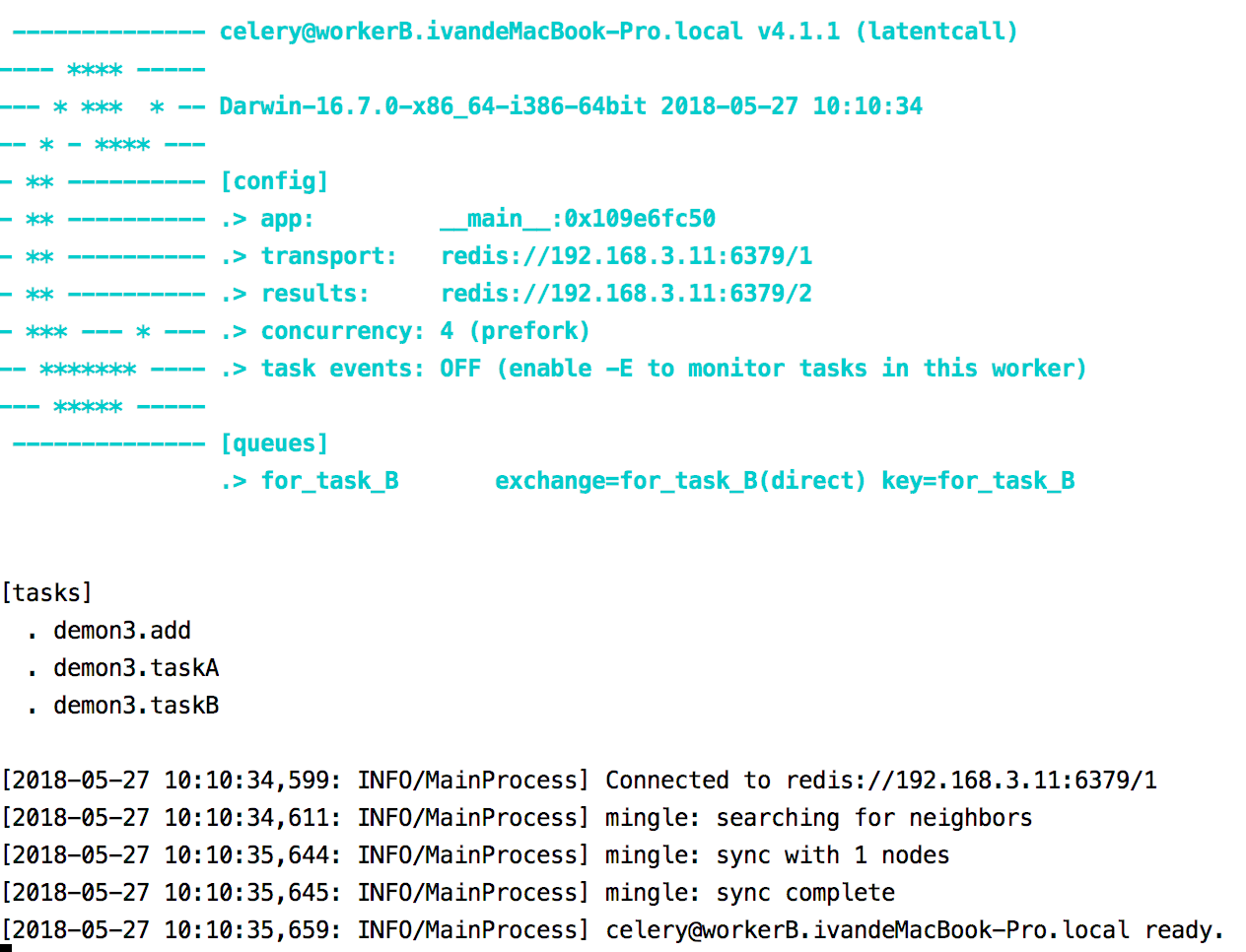
执行以下程序
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2018/05/27 10:05 # @Author : yangyuanqiang # @File : test.py import time from demon3 import * re1 = taskA.delay(10, 20) re2 = taskB.delay(100, 200, 300) re3 = add.delay(1000, 2000) time.sleep(2) print(re1.result) print(re2.result) print(re3.status) print(re3.result)
以上实例输出的结果
200
600
PENDING
None
tasks_A输出的结果
[2018-05-27 10:11:08,855: INFO/MainProcess] Received task: demon3.taskA[f245bc49-7db7-48cf-b1e0-2631f4ea35b9]
[2018-05-27 10:11:08,866: INFO/ForkPoolWorker-2] Task demon3.taskA[f245bc49-7db7-48cf-b1e0-2631f4ea35b9] succeeded in 0.008108521999929508s: 200
tasks_B输出的结果
[2018-05-27 10:11:08,858: INFO/MainProcess] Received task: demon3.taskB[1edbc326-0949-4d1b-b45f-d7b15cdf17a5] [2018-05-27 10:11:08,868: INFO/ForkPoolWorker-2] Task demon3.taskB[1edbc326-0949-4d1b-b45f-d7b15cdf17a5] succeeded in 0.006413651000002574s: 600
我们看到add的状态是PENDING,表示没有执行,这个是因为没有celeryconfig.py文件中指定改route到哪一个Queue中,所以会被发动到默认的名字celery的Queue中,但是我们还没有启动worker执行celery中的任务。下面,我们来启动一个worker来执行celery队列中的任务。
ivandeMacBook-Pro:celery ivan$ celery -A demon3 worker -l info -n worker.%h -Q celery
执行test.py输出的结果
200
600
SUCCESS
3000
Celery与定时任务
在celery中执行定时任务非常简单,只需要设置celery对象中的CELERYBEAT_SCHEDULE属性即可。
下面我们接着在celeryconfig.py中添加CELERYBEAT_SCHEDULE变量
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2018/05/27 09:30 # @Author : yangyuanqiang # @File : celeryconfig.py from kombu import Queue, Exchange BROKER_URL = "redis://192.168.3.11:6379/1" CELERY_RESULT_BACKEND = "redis://192.168.3.11:6379/2" CELERY_QUEUES = { Queue("default",Exchange("default"),routing_key="default"), Queue("for_task_A",Exchange("for_task_A"),routing_key="for_task_A"), Queue("for_task_B",Exchange("for_task_B"),routing_key="for_task_B") } CELERY_ROUTES = { "demon3.taskA":{"queue":"for_task_A","routing_key":"for_task_A"}, "demon3.taskB":{"queue":"for_task_B","routing_key":"for_task_B"} } #在celeryconfig.py中添加以下代码: CELERY_TIMEZONE = 'UTC' CELERYBEAT_SCHEDULE = { 'taskA_schedule' : { 'task':'demon3.taskA', 'schedule':2, 'args':(5,6) }, 'taskB_scheduler' : { 'task':"demon3.taskB", "schedule":10, "args":(10,20,30) }, 'add_schedule': { "task":"demon3.add", "schedule":5, "args":(1,2) } }
Celery启动定时任务
ivandeMacBook-Pro:celery ivan$ celery -A demon3 beat
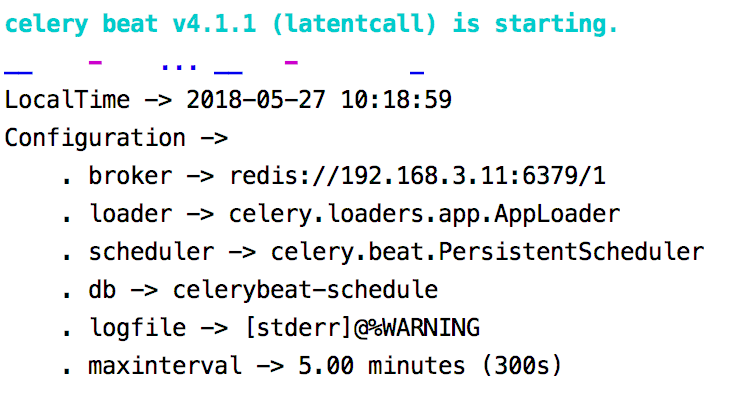
Celery启动定时任务
这样taskA每20秒执行一次taskA.delay(5, 6)
taskB每200秒执行一次taskB.delay(10, 20, 30)
Celery每10秒执行一次add.delay(1, 2)
习题一:不断记录服务器输入日志
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2018/5/26 20:26 # @Author : lingxiangxiang # @File : utils.py import codecs from threading import Thread, Lock import os class TraceLog(Thread): def __init__(self, logName): super(TraceLog, self).__init__() self.logName = logName self.lock = Lock() self.contexts = [] self.isFile() def isFile(self): if not os.path.exists(self.logName): with codecs.open(self.logName, 'w') as f: f.write("this log name is: {0}\n".format(self.logName)) f.write("start log\n") def write(self, context): self.contexts.append(context) def run(self): while 1: self.lock.acquire() if len(self.contexts) !=0: with codecs.open(self.logName, "a") as f: for context in self.contexts: f.write(context) del self.contexts[:]#注意不能忘记清空 self.lock.release()
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2018/5/26 20:19 # @Author : lingxiangxiang # @File : main.py '''不断记录服务端输入的日志 实现>> 和> ''' import time import sys from day24.test.utils import TraceLog class Server(object): def printLog(self): print("start server\n") for i in range(100): print(i) time.sleep(0.1) print("end server\n") if __name__ == '__main__': traceLog = TraceLog("main.log") traceLog.start() sys.stdout = traceLog sys.stderr = traceLog server = Server() server.printLog() # 每当调用print的时候,底层就是在代用sys.stdout.write(str) # sys.stdout.write() = traceLog.write()
以上实例输出的结果,在当前目录下生成一个main.log文件
this log name is: main.log start log start server 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 end server
习题二:
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2017/12/3 21:55 # @Author : lingxiangxiang # @File : utils.py import codecs import threading import os class WriteLog(threading.Thread): def __init__(self, logName): super(WriteLog, self).__init__() self.logName = logName self.lock = threading.Lock() #课上这里写是Lock没有写() self.contexts = [] self.mkfile() def mkfile(self): if not os.path.exists(self.logName): with codecs.open(self.logName, 'w') as f: f.write("This file is log for {0}\n".format(self.logName)) def write(self, context): self.contexts.append(context) def run(self): while 1: self.lock.acquire() if len(self.contexts) != 0: with codecs.open(self.logName, "a") as f: for context in self.contexts: f.write(context) del self.contexts[:] self.lock.release() # class A(threading.Thread): # def __init__(self): # super(A, self).__init__() # self.contexts = [] # self.lock = threading.Lock() # def run(self): # while 1: # self.lock.acquire() # if len(self.contexts) !=0: # with open('main.log', 'a') as f: # for context in self.contexts: # f.write(context) # del self.contexts[:] # self.lock.release() # # def write(self, context): # self.contexts.append(context)
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2017/12/3 21:42 # @Author : lingxiangxiang # @File : main.py import time from utils import WriteLog import sys reload(sys) sys.setdefaultencoding("utf-8") def Xh(): for i in xrange(1, 100): print(i) # sys.stdout.write(str(i)) time.sleep(0.1) def main(): writeLog = WriteLog("main.log") writeLog.start() sys.stdout = writeLog sys.stderr = writeLog Xh() if __name__ == '__main__': main()
以上实例输出的结果
This file is log for main.log 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99

 浙公网安备 33010602011771号
浙公网安备 33010602011771号