聚类算法介绍
聚类,就是根据数据的“相似性”将数据分为多类的过程。
评估不同样本之间的“相似性”,通常使用的方法为计算样本之间的“距离”。距离计算方法的不同会影响聚类结果的好坏。
1)簇类型
(1)明显分离的簇

簇是对象的集合。
每个点到同簇中任意点的距离比到不同簇中所有点的距离更近。簇的形状任意。
(2)基于中心的簇
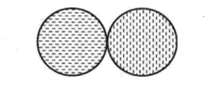
簇是对象的集合。
每个点到定义该簇的原型的距离比到任何其他簇的原型的距离更近。
对于连续属性的数据,簇的原型通常为质心(簇中所有点的平均值)。
当质心没有意义时(如当数据具有分类属性),原型通常为中心点(最有代表性的点)。这种簇倾向于球状。
(3)基于图的簇

当数据用图表示,结点表示对象、边代表结点之间的联系。
ⅰ简单地将一个连通分支视为一个簇。
ⅱ基于邻近的簇
每个点到该簇中至少一个点的距离比到不同簇中任意点的距离更近。(两个对象相连仅在它们之间的距离在指定的距离内)。但当出现噪声(如原本没有关系的两点之间因为噪声而有边相连)时容易出现问题。
ⅲ团
将团(图中相互之间完全连接的点的集 合)定义为簇。即我们将根据对象之间的距离添加连接,当形成团即可形成一个簇。该簇会趋于球形。
(4)基于密度的簇
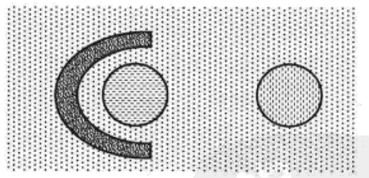
簇是被低密度区域分开的高密度区域。当簇不规则或是互相盘绕,并且存在噪声和离群点时,常使用该簇。
(5)概念簇
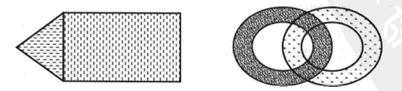
通常,我们将簇定义为有某种共同属性的对象的集合。
但对于一些特殊的簇,需要定义特定的簇(更加具体的簇概念),发现这样的簇的过程称为概念聚类。
2)聚类类型
(1)层次的与划分的(嵌套的与非嵌套的)
①划分聚类:简单地将数据对象集划分为不重叠的子集(簇),使得每个数据对象恰在一个子集当中。
②层次聚类:在允许簇拥有子簇的情况下。可以将层次聚类得到的簇集群组织成一棵树——每一个结点为子结点的并,树根是包含所有对象的簇。
(2)互斥的、重叠的与模糊的
①互斥的:每个对象都仅属于一个簇。
②重叠的(非互斥的):一个对象同时属于多个簇。
③模糊的:
ⅰ模糊聚类:每一个对象以一个[0,1]的隶属权属于每一个簇。通常会施加一个约束条件——每个对象的权值之和必须为1。
ⅱ概率聚类:每个对象都有某个概率隶属于各个簇。通常约定概率和为1。
以上两种并不能解决一个对象属于多个簇的问题,通常用于当某个对象接近多个簇时,将其指派到隶属权值最高或概率最大的簇,避免将对象随意地指派到任意一个簇,进而转化为互斥聚类。
(3)完全的与部分的:
①完全聚类:将每个对象指派到簇。
②部分聚类:某些对象没有明确定义。
出处:http://www.cnblogs.com/ivan-count/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号