
windows系统下pyspark安装
1. spark环境搭建
Win7 系统下用IDEA创建Spark工程,由于版本之间相互依赖,下载时要看清楚版本。
spark-3.1.1-bin-hadoop2.7.tgz spark是基于scala开发,具体可从 spark与scala版本对应关系 查看
hadoop-2.7.1.tar.gz index: https://archive.apache.org/dist/hadoop/common/
-- Spark不支持win7,原始下载的hadoop2.7.6的bin在win7下编译会缺少dll文件,此包加入了这些文件。
-- 用hadooponwindos-master的bin文件复制到D:\software\spark\hadoop-2.7.6\bin,替换hadoop-2.7.6的bin文件。(替换前可以重命名原始为 xx_bak)
好像下载 winutils 也可,将下载好的 winutils.exe文件放入到Hadoop的bin目录下
IntelliJ IDEA pyspark用pycharm应该就可以了,spark开发人员建议下载,注意选择版本
IDEA支持的Scala工程插件:scala-intellij-bin-2021.1.15.zip 注意版本号按IDEA plugins搜索结果来
环境配置
JAVA_HOME = D:\Java\jdk1.8.0_281
CLASSPATH = %JAVA_HOME%\lib;%JAVA_HOME%\lib\tools.jar
HADOOP_HOME = D:\hadoop-2.7.1
SCALA_HOME = D:\scala-2.12.13
--运行pyspark报错无'python3'解决
SPARK_HOME = D:\spark-3.1.1-bin-hadoop2.7
--py4j貌似还是得pip装
PYTHONPATH = %SPARK_HOME%/python;%SPARK_HOME%/python/lib/py4j-0.10.9-src.zip
PYSPARK_PYTHON = D:\Anaconda3\python.exe
PATH 追加
%JAVA_HOME%\bin;%JAVA_HOME%\jre\bin;
%HADOOP_HOME%\bin;
%SPARK_HOME%\bin;
%SPARK_HOME%\sbin;
%SPARK_HOME%\python; --有的直接把D:\spark-3.1.1-bin-hadoop2.7\python下的pyspark直接拷贝到D:\Anaconda3\Lib\site-packages下
%SCALA_HOME%\bin
cmd测试
spark-shell -version
cmd>spark-shell
scala>import org.apache.spark.sql.hive.HiveContext
python测试
# pip install py4j
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local[*]").setAppName("First_App")
sc = SparkContext(conf=conf)
# 计算0到9的总和
# 如果报错 java.io.IOException: Cannot run program "python3": CreateProcess error=2, 系统找不到指定的文件。
# 添加环境变量即可 PYSPARK_PYTHON = D:\Anaconda3\python.exe
data = sc.parallelize(range(10))
ans = data.reduce(lambda x, y: x + y)
print (ans)
# README.md的行数和第一行
lines = sc.textFile("D:\spark-3.1.1-bin-hadoop2.7\README.md")
print (lines.count())
print (lines.first())
一、测试
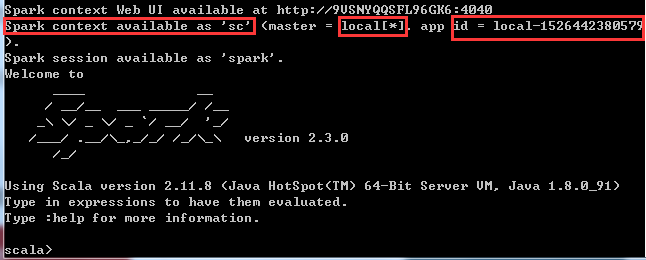
(1)任意目录下,运行 Win+R,并输入spark-shell脚本命令,测试spark
什么是spark-shell?
spark-shell是提供给用户即时交互的一个命令窗口,你可以在里面编写spark代码,然后根据你的命令进行相应的运算
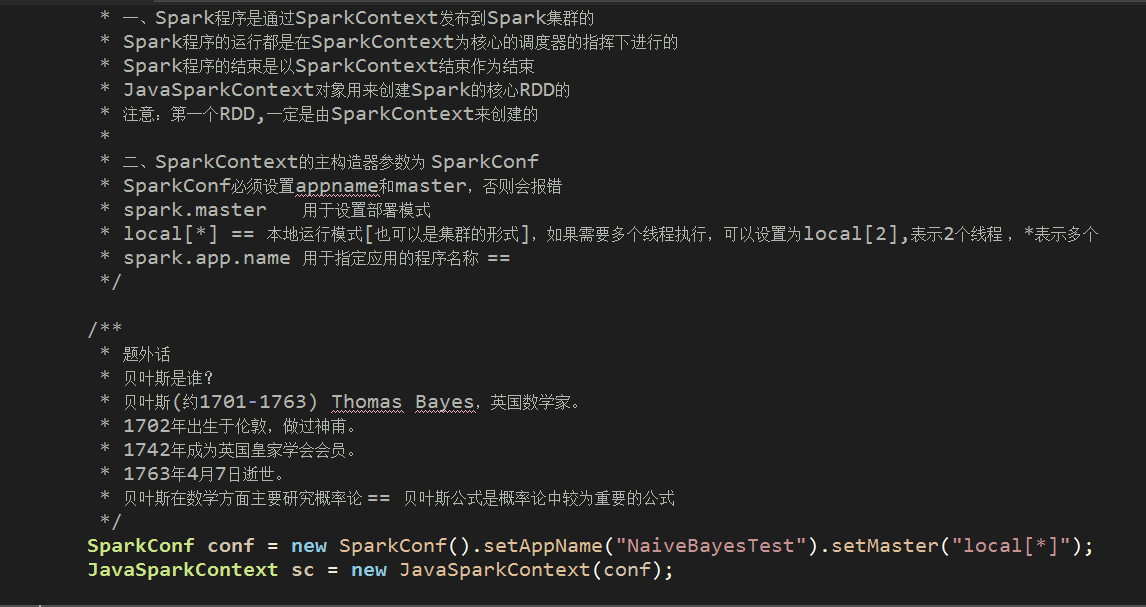
(2)实例化SparkContext对象
什么是SparkContext?
SparkContext是编写Spark程序用到的第一个类,其中包含了Spark程序用到的几乎所有的核心对象,可见其重要性
master:local[*] == 本地运行模式[也可以是集群的形式],*表示多个线程并行执行
在Java中实例化SparkContext对象的demo如下
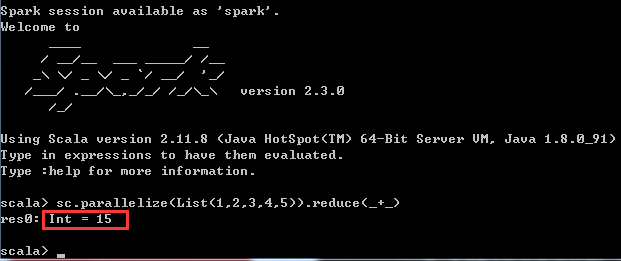
(3)通过scala语言,编写spark代码,利用reduce计算集合1,2,3,4,5的和
通过调用SparkContext的parallelize方法,在一个已经存在的Scala集合上创建一个Seq对象。集合的对象将会被拷贝,创建出一个可以被并行操作的分布式数据集RDD
体现在Java中的demo如下

体现在脚本语言中如下:
二、用Intellij IDEA创建Spark工程
(1)安装scala插件
Idea默认是不能创建Scala工程的。需要安装idea的scala插件,如何判断idea需要安装哪个版本?
安装此插件有两种方法:
方法一:IDEA
File-->Setting-->Plugins-->搜索scala(查看版本:scala Version 2017.3.15)-->点击install
方法二:直接下载scala-intellij-bin-2017.3.15.zip(无需解压),然后Install plugin from disk
安装完需要重启IDEA才能使用
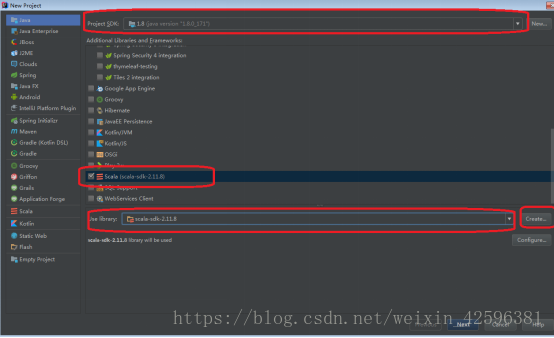
(2) scala sdk配置
File->New Project->Java
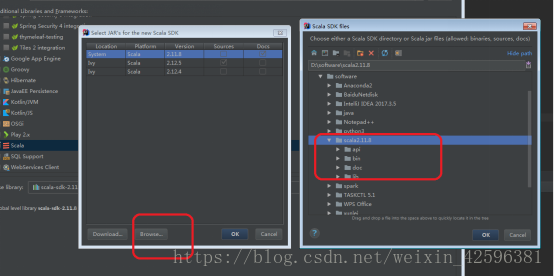
选择Java的SDK,选择Scala.
选择Create,将下载的scala添加进来
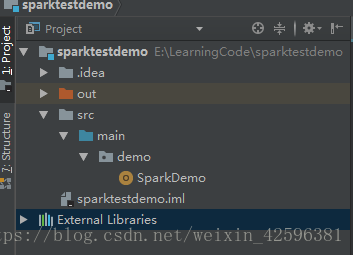
(3)创建工程目录
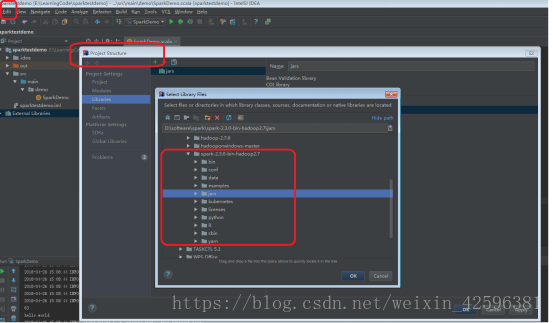
(4)添加spark的jar包
File->Project Structure->Libraries
将D:\spark-3.1.1-bin-hadoop2.7\jars添加进来。
在此操作之后,External Libraries中会出现 jdk 1.8、jars、scala-sdk 三个lib
(5)scala工程测试
创建一个SparkDemo的Object,并运行。
windows在cmd上运行以下命令:D:\hadoop-2.7.1\bin\winutils.exe chmod 777 D:\tmp\hive 否则可能会报错,后面的文件夹先创建好,参考链接package demo
import org.apache.spark._
object SparkDemo{
def main(args: Array[String]): Unit={
val masterUrl = "local[1]"
val conf = new SparkConf().setAppName("helenApp").setMaster(masterUrl)
val sc = new SparkContext(conf)
val rdd=sc.parallelize(List(1,2,3,4,5,6)).map(_*3)
rdd.filter(_>10).collect().foreach(println)
println(rdd.reduce(_+_))
println("hello world")
}
}
报错汇总:
1. 报错:Exception in thread "main" org.apache.spark.SparkException: A master URL must be set in your configuration
解决:
传递给spark的master url可以有如下几种:
local 本地单线程
local[K] 本地多线程(指定K个内核)
local[*] 本地多线程(指定所有可用内核)
spark://HOST:PORT 连接到指定的 Spark standalone cluster master,需要指定端口。
mesos://HOST:PORT 连接到指定的 Mesos 集群,需要指定端口。
yarn-client客户端模式 连接到 YARN 集群。需要配置 HADOOP_CONF_DIR。
yarn-cluster集群模式 连接到 YARN 集群。需要配置 HADOOP_CONF_DIR。
若是本地调试状态可以默认为local,设置如下:
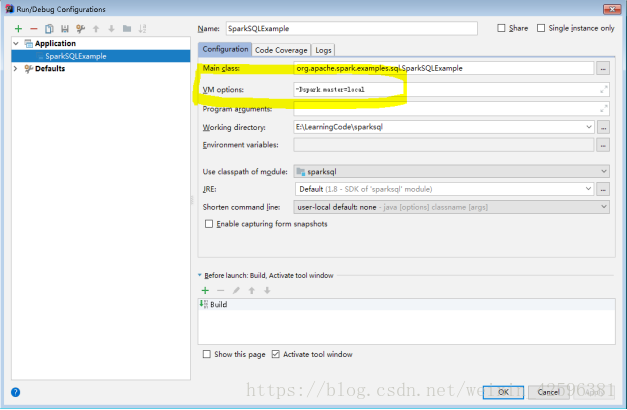
Run->Edit Configuration->
编辑VM option 输入: “-Dspark.master=local” 指示本程序本地单线程运行,再次运行即可。
2. 1 <console>:14: error: not found: value spark
2 import spark.implicits._ 3 ^ 4 <console>:14: error: not found: value spark 5 import spark.sql
其原因是没有权限在spark中写入metastore_db 这个文件。
处理方法:我们授予777的权限
Linux环境,我们在root下操作:
sudo chmod 777 /home/hadoop/spark #为了方便,可以给所有的权限 sudo chmod a+w /home/hadoop/spark
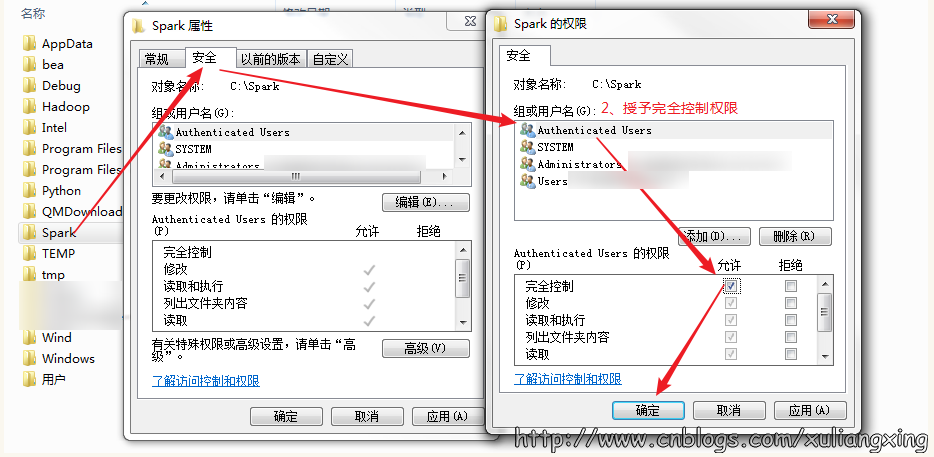
window环境下:
存放Spark的文件夹不能设为只读和隐藏
点击spark安装目录,右击>属性>去除“只读”勾选
授予完全控制的权限
参考链接:
windows安装Spark3.0.0+hadoop+JDK大数据开发平台
Spark MLlib 环境搭建超详细教程 看创建项目步骤截图
spark与scala版本对应关系 版本不对应可能会出各种问题
winutils下载 需下载对应版本并替换hadoop中的bin,也可下载


 浙公网安备 33010602011771号
浙公网安备 33010602011771号