oracle 正则表达式
运算符及含义
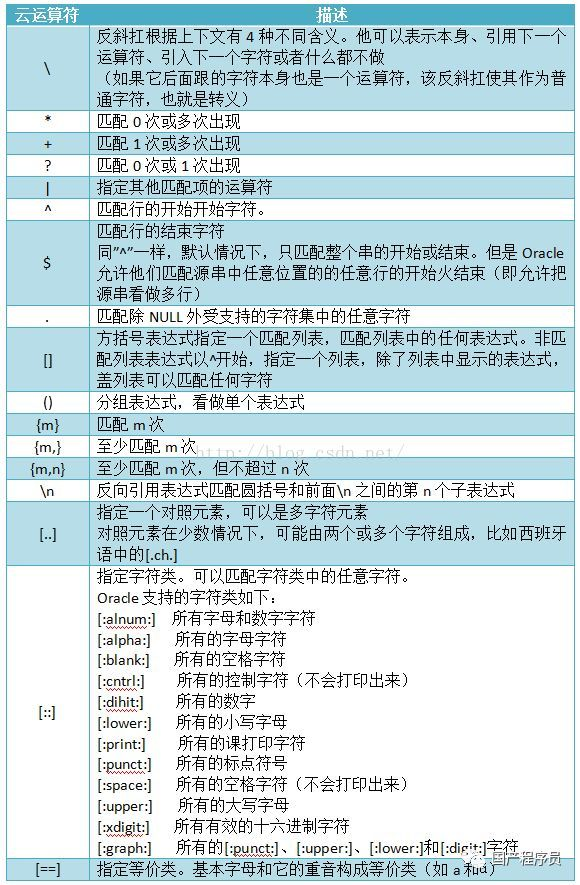
oracle 正则表达式 匹配
ORACLE中的支持正则表达式的函数主要有下面四个:
- REGEXP_LIKE :与LIKE的功能相似
- REGEXP_INSTR :与INSTR的功能相似
- REGEXP_SUBSTR :与SUBSTR的功能相似
- REGEXP_REPLACE :与REPLACE的功能相似
它们在用法上与Oracle SQL 函数LIKE、INSTR、SUBSTR 和REPLACE 用法相同,但是它们使用POSIX 正则表达式代替了老的百分号(%)和通配符(_)字符。
POSIX 正则表达式由标准的元字符(metacharacters)所构成:
'^' 匹配输入字符串的开始位置,在方括号表达式中使用,此时它表示不接受该字符集合。
'$' 匹配输入字符串的结尾位置。如果设置了 RegExp 对象的 Multiline 属性,则 $ 也匹
配 '\n' 或 '\r'。
'.' 匹配除换行符之外的任何单字符。
'?' 匹配前面的子表达式零次或一次。
'+' 匹配前面的子表达式一次或多次。
'*' 匹配前面的子表达式零次或多次。
'|' 指明两项之间的一个选择。例子'^([a-z]+|[0-9]+)$'表示所有小写字母或数字组合成的
字符串。
'( )' 标记一个子表达式的开始和结束位置。
'[]' 标记一个中括号表达式。
'{m,n}' 一个精确地出现次数范围,m=<出现次数<=n,'{m}'表示出现m次,'{m,}'表示至少
出现m次。
\num 匹配 num,其中 num 是一个正整数。对所获取的匹配的引用。
字符簇:
[[:alpha:]] 任何字母。
[[:digit:]] 任何数字。
[[:alnum:]] 任何字母和数字。
[[:space:]] 任何白字符。
[[:upper:]] 任何大写字母。
[[:lower:]] 任何小写字母。
[[:punct:]] 任何标点符号。
[[:xdigit:]] 任何16进制的数字,相当于[0-9a-fA-F]。
各种操作符的运算优先级
\转义符
(), (?:), (?=), [] 圆括号和方括号
*, +, ?, {n}, {n,}, {n,m} 限定符
^, $, anymetacharacter 位置和顺序
范例: 函数中pattern为正则表达式,最多可以包含512个字节。
REGEXP_LIKE
--查询value中以1开头60结束的记录并且长度是7位
select * from fzq where value like '1____60';
select * from fzq where regexp_like(value,'1....60');
--查询value中以1开头60结束的记录并且长度是7位并且全部是数字的记录。
--使用like就不是很好实现了。
select * from fzq where regexp_like(value,'1[0-9]{4}60');
-- 也可以这样实现,使用字符集。
select * from fzq where regexp_like(value,'1[[:digit:]]{4}60');
-- 查询value中不是纯数字的记录
select * from fzq where not regexp_like(value,'^[[:digit:]]+$');
-- 查询value中不包含任何数字的记录。
select * from fzq where regexp_like(value,'^[^[:digit:]]+$');
--查询以12或者1b开头的记录.不区分大小写。
select * from fzq where regexp_like(value,'^1[2b]','i');
--查询以12或者1b开头的记录.区分大小写。
select * from fzq where regexp_like(value,'^1[2B]');
-- 查询数据中包含空白的记录。
select * from fzq where regexp_like(value,'[[:space:]]');
--查询所有包含小写字母或者数字的记录。
select * from fzq where regexp_like(value,'^([a-z]+|[0-9]+)$');
--查询任何包含标点符号的记录。
select * from fzq where regexp_like(value,'[[:punct:]]');
REGEXP_SUBSTR
REGEXP_SUBSTR函数使用正则表达式来指定返回串的起点和终点。
语法:
regexp_substr(source_string,pattern[,position[,occurrence[,match_parameter]]])
- source_string:源串,可以是常量,也可以是某个值类型为串的列。
- position:从源串开始搜索的位置。默认为1。
- occurrence:指定源串中的第几次出现。默认值1.
- match_parameter:文本量,进一步订制搜索,取值如下:
- 'i' 用于不区分大小写的匹配。
- 'c' 用于区分大小写的匹配。
- 'n' 允许将句点“.”作为通配符来匹配换行符。如果省略改参数,句点将不匹配换行符。
- 'm' 将源串视为多行。即将“^”和“$”分别看做源串中任意位置任意行的开始和结束,而不是看作整个源串的开始或结束。如果省略该参数,源串将被看作一行来处理。
- 如果取值不属于上述中的某个,将会报错。如果指定了多个互相矛盾的值,将使用最后一个值。如'ic'会被当做'c'处理。
- 省略该参数时:默认区分大小写、句点不匹配换行符、源串被看作一行。
REGEXP_INSTR
REGEXP_INSTR函数使用正则表达式返回搜索模式的起点和终点(整数)。如果没有发现匹配的值,将返回0。 语法:
regexp_instr(source_string,pattern[,position[,occurrence[,return_option[,match_parameter]]]])
- REGEXP_INSTR函数常常会被用到where子句中。
REGEXP_LIKE
通常使用REGEXP_LIKE进行模糊匹配。 语法:
regexp_like(source_string,pattern[match_parameter])
- 该函数可以使用前面介绍的所有搜索功能作为REGEXP_LIKE搜索的一部分,可以是非常复杂的搜索变得简单。
REPLACE和REGEXP_REPLACE
REPLACE函数用于替换串中的某个值。 语法:
replace(char,search_string[,replace_string])
- 如果不指定replace_string,会将搜索到的值删除。
REGEXP_REPLACE是REPLACE的增强版,支持正则表达式,扩展了一些功能。
regexp_replace(source_string,pattern[,replace_string[,position[,occurrence[,match_parameter]]]])
- replace_string表示用什么来替换source_string中与pattern匹配的部分。
- occurrence为非负整数,0表示所有匹配项都被替换,为正数时替换第n次匹配。
REGEXP_COUNT
REGEXP_COUNT函数返回在源串中出现的模式的次数,作为对REGEXP_INSTR函数的补充。
虽然COUNT是一个集合函数,操作的是行组,但是REGEXP_COUNT是单行函数,分别计算每一行。 语法:
regexp_count(source_char,pattern[,position[,match_param]])
REGEXP_COUNT返回pattern在source_char串中出现的次数。如果未找到匹配,函数返回0。 metch_param参数,相对于前面介绍的match_parameter参数多一个取值“x”。 'x':忽略空格字符。默认情况下,空格与自身想匹配。 metch_param如果指定了多个互相矛盾的值,将使用最后一个值。
常用正则表达式
用户名: /^[a-z0-9_-]{3,16}$/
密码: /^[a-z0-9_-]{6,18}$/
十六进制值: /^#?([a-f0-9]{6}|[a-f0-9]{3})$/
电子邮箱: /^([a-z0-9_\.-]+)@([\da-z\.-]+)\.([a-z\.]{2,6})$/
URL: /^(https?:\/\/)?([\da-z\.-]+)\.([a-z\.]{2,6})([\/\w \.-]*)*\/?$/
IP 地址: /^(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$/
HTML 标签:/^<([a-z]+)([^<]+)*(?:>(.*)<\/\1>|\s+\/>)$/
Unicode编码中的汉字范围: /^[u4e00-u9fa5],{0,}$/
匹配中文字符的正则表达式: [\u4e00-\u9fa5]
--评注:匹配中文还真是个头疼的事,有了这个表达式就好办了
匹配双字节字符(包括汉字在内):[^\x00-\xff]
--评注:可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1)
匹配空白行的正则表达式:\n\s*\r
--评注:可以用来删除空白行
匹配HTML标记的正则表达式:<(\S*?)[^>]*>.*?</\1>|<.*? />
--评注:网上流传的版本太糟糕,上面这个也仅仅能匹配部分,对于复杂的嵌套标记依旧无能为力
匹配首尾空白字符的正则表达式:^\s*|\s*$
--评注:可以用来删除行首行尾的空白字符(包括空格、制表符、换页符等等),非常有用的表达式
匹配Email地址的正则表达式:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*
--评注:表单验证时很实用
匹配网址URL的正则表达式:[a-zA-z]+://[^\s]*
--评注:网上流传的版本功能很有限,上面这个基本可以满足需求
匹配帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
--评注:表单验证时很实用
匹配国内电话号码:\d{3}-\d{8}|\d{4}-\d{7}
--评注:匹配形式如 0511-4405222 或 021-87888822
匹配腾讯QQ号:[1-9][0-9]{4,}
--评注:腾讯QQ号从10000开始
匹配中国大陆邮政编码:[1-9]\d{5}(?!\d)
--评注:中国大陆邮政编码为6位数字
匹配身份证:\d{15}|\d{18}
--评注:中国大陆的身份证为15位或18位
匹配ip地址:\d+\.\d+\.\d+\.\d+
--评注:提取ip地址时有用
匹配特定数字:
^[1-9]\d*$ //匹配正整数
^-[1-9]\d*$ //匹配负整数
^-?[1-9]\d*$ //匹配整数
^[1-9]\d*|0$ //匹配非负整数(正整数 + 0)
^-[1-9]\d*|0$ //匹配非正整数(负整数 + 0)
^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$ //匹配正浮点数
^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$ //匹配负浮点数
^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$ //匹配浮点数
^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$ //匹配非负浮点数(正浮点数 + 0)
^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$ //匹配非正浮点数(负浮点数 + 0)
评注:处理大量数据时有用,具体应用时注意修正
匹配特定字符串:
^[A-Za-z]+$ //匹配由26个英文字母组成的字符串
^[A-Z]+$ //匹配由26个英文字母的大写组成的字符串
^[a-z]+$ //匹配由26个英文字母的小写组成的字符串
^[A-Za-z0-9]+$ //匹配由数字和26个英文字母组成的字符串
^\w+$ //匹配由数字、26个英文字母或者下划线组成的字符串
去除精度纬度中非浮点数
select jd,wd from xx_xa_xsczaqpc t where t.id not in (
select id from xx_xa_xsczaqpc
where regexp_like(jd,
'^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$'));
是双小数点的数
select xx_jbxx_id,jd,wd
from xx_xa_xsczaqpc t
where regexp_like(jd,
'^[1-9]\d*\.\d*\.\d*[1-9]\d*$');
转自:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号