深度学习相关概念理解
【cuda安装教程】GTX1050Ti+win10+cuda9.0+cudnn7.4.1安装过程记录
win10下CUDA和CUDNN的安装(超详细)!亲测有效! cuda10.1安装教程 NVIDIA驱动下载
C:\Users\epsoft\AppData\Local\Temp\CUDA
nvcc -V / nvcc --version
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.2 将CUDNN解压文件夹下的文件放入以上对应文件夹下即可
环境变量:CUDA_PATH、CUDA_PATH_V9_2
%CUDA_PATH%\bin
%CUDA_PATH%\include
%CUDA_PATH%\lib
%CUDA_PATH%\lib\x64
%CUDA_PATH%\extras\CUPTI\libx64
————————————————
如果装了samples
CUDA_SDK_PATH = C:\ProgramData\NVIDIA Corporation\CUDA Samples\v9.2
%CUDA_SDK_PATH%\bin\win64;%CUDA_SDK_PATH%\common\lib\x64
验证
首先win+R启动cmd,cd到安装目录下的 ...\extras\demo_suite,然后分别执行bandwidthTest.exe和deviceQuery.exe
都返回Result=PASS表示成功
深度学习环境搭建:ubuntu16.04+python3.6(anaconda)+nvidia cuda9.2+cudnn(for cuda 9.2)+pytorch(cuda 9.2)
深度学习笔记:优化方法总结(BGD,SGD,Momentum,AdaGrad,RMSProp,Adam) 每种优化方法之间的区别与联系
【机器学习】神经网络-激活函数-面面观(Activation Function) 每种激活函数的优缺点
【Stanford CNN课程笔记】5. 神经网络解读1 几种常见的激活函数 看下整个系列的笔记
浅谈PCA算法 PCA的计算过程
通俗理解LDA主题模型 + 狄利克雷分布 + 贝叶斯估计、最大似然估计、最大后验概率估计 + 最大似然估计 (MLE) 最大后验概率(MAP)
最小角回归Least Angle Regression(LARS)
TensorFlow中的变分自动编码器 VAE的tensorflow实现
变分自编码器(一):原来是这么一回事 VAE的推导过程及理解
python机器学习库sklearn——DBSCAN密度聚类, Python实现DBScan
聚类︱python实现 六大 分群质量评估指标(兰德系数、互信息、轮廓系数)
笔记︱多种常见聚类模型以及分群质量评估(聚类注意事项、使用技巧) 聚类的常见问题及解答
sklearn中LinearRegression使用及源码解读
sklearn源码解读:1.10 Decision Trees & 1.11 Ensemble methods
对AUC的重新理解 :auc的面积可表示为任取应该正例和负例,正例排在负例之前的概率
tp:真正,被模型正确预测为正的正样本
tn:真负,被模型正确预测为负的负样本
fp:假正,被模型错误预测为正的负样本
fn:假负,被模型错误预测为负的正样本
x: fpr, y: tpr 》ROC(Receiver Operating Characteristic)曲线
描点方式按照样本预测结果的得分高低从左至右开始遍历。从原点开始,每遇到1便向y轴正方向移动y轴最小步长1个单位,这里是1/5=0.2;每遇到0则向x轴正方向移动x轴最小步长1个单位,这里也是0.2。不难看出,上图的AUC等于1,印证了正例排在负例前面的概率的确为100%。
auc <- mean(sample(pos.decision,1000,replace=T) > sample(neg.decision,1000,replace=T))
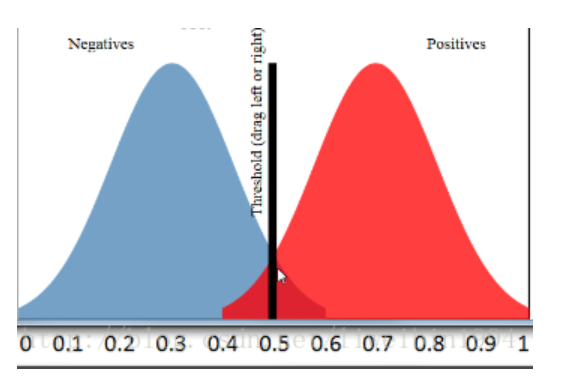
ROC曲线有一个很好的特性:当测试集中的正负样本分布发生变化了,ROC曲线可以保持不变。在实际的数据集中经常会出现类不平衡(class imbalance)现象,即负样本比正样本多很多(或者相反),而且测试数据中的正负样本的分布也可能随着时间变化。
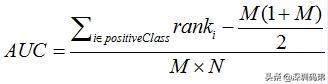
首先rank项就是样本按照score值从小到大升序排序,然后只对正样本的序号相加;
即将所有小于某正样本得个数去掉,得到的便是小于该正样本的负样本数


 浙公网安备 33010602011771号
浙公网安备 33010602011771号