spakr-sql 持久化操作对 自动生成的每条数据的唯一 ID的影响
背景
项目中的Spark程序中需要针对处理的每条数据进行唯一标识,所以使用了Spark 内置的 monotonically_increasing_id() 函数
自动ID生成 monotonically_increasing_id()
import static org.apache.spark.sql.functions.*;
dateset.withColumn("ID",monotonically_increasing_id());
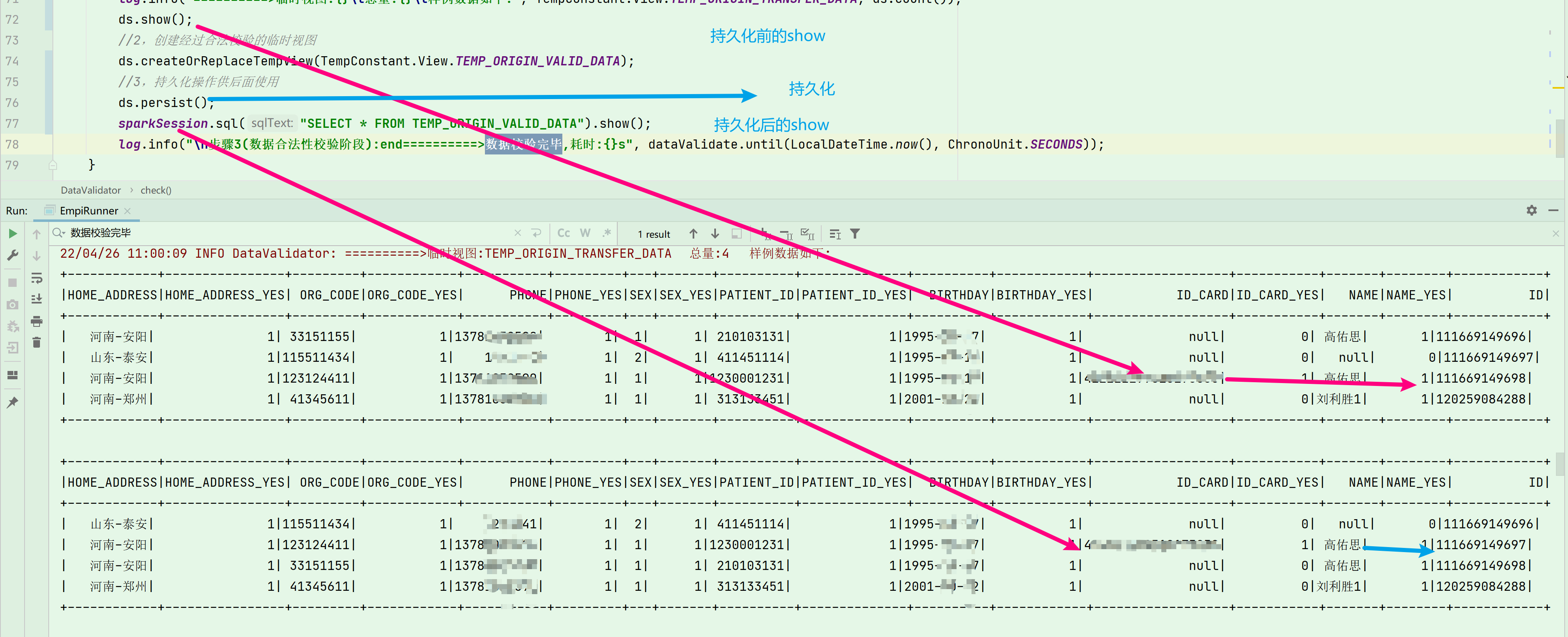
持久化对 自动生成ID的影响
下图可视,对于同一条数据来讲,持久化前show的和持久化后show的 唯一ID发生了变化 由 98 变成了 97 ,原因待后续有空深入研究,如果使用到了ID 推荐 持久化之后再进行show
Spark 临时视图数据和RDD等数据持久化需要注意的点
https://blog.csdn.net/nanfeizhenkuangou/article/details/121276117

 浙公网安备 33010602011771号
浙公网安备 33010602011771号