Tensorflow实战三:天气识别
Tensorflow 第T3周:天气识别
本文将采用CNN实现多云、下雨、晴、日出四种天气状态的识别。较上篇文章,本文为了增加模型的泛化能力,新增了Dropout层并且将最大池化层调整成了平均池化层。
🚀 我的环境:
语言环境:Python3.11.9
编译器:jupyter notebook
深度学习环境:TensorFlow2.17.0
1. 设置GPU
如果使用的是CPU可以忽略这步
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")
if gpus:
gpu0 = gpus[0] #如果有多个GPU,仅使用第0个GPU
tf.config.experimental.set_memory_growth(gpu0, True) #设置GPU显存用量按需使用
tf.config.set_visible_devices([gpu0],"GPU")
2. 导入数据
import os,PIL,pathlib
import matplotlib.pyplot as plt
import numpy as np
from tensorflow import keras
from tensorflow.keras import layers,models
data_dir = "../data/weather_photos/"
data_dir = pathlib.Path(data_dir)
3. 查看数据
数据集一共分为cloudy、rain、shine、sunrise四类,分别存放于weather_photos文件夹中以各自名字命名的子文件夹中。
image_count = len(list(data_dir.glob('*/*.jpg')))
print("图片总数为:",image_count)
👉 输出
图片总数为: 1125
roses = list(data_dir.glob('sunrise/*.jpg'))
PIL.Image.open(str(roses[0]))

二、数据预处理
1. 加载数据
使用image_dataset_from_directory方法将磁盘中的数据加载到tf.data.Dataset中
batch_size = 32
img_height = 180
img_width = 180
"""
关于image_dataset_from_directory()的详细介绍可以参考文章:https://mtyjkh.blog.csdn.net/article/details/117018789
"""
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
👉 输出
Found 1125 files belonging to 4 classes.
Using 900 files for training.
我们可以通过class_names输出数据集的标签。标签将按字母顺序对应于目录名称。
class_names = train_ds.class_names
print(class_names)
👉 输出
['cloudy', 'rain', 'shine', 'sunrise']
2. 可视化数据
plt.figure(figsize=(20, 10))
for images, labels in train_ds.take(1):
for i in range(20):
ax = plt.subplot(5, 10, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")

3. 再次检查数据
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break
👉 输出
(32, 180, 180, 3)
(32,)
-
Image_batch是形状的张量(32,180,180,3)。这是一批形状180x180x3的32张图片(最后一维指的是彩色通道RGB)。 -
Label_batch是形状(32,)的张量,这些标签对应32张图片
4. 配置数据集
-
shuffle():打乱数据,关于此函数的详细介绍可以参考:https://zhuanlan.zhihu.com/p/42417456
-
prefetch():预取数据,加速运行
prefetch()功能详细介绍:CPU 正在准备数据时,加速器处于空闲状态。相反,当加速器正在训练模型时,CPU 处于空闲状态。因此,训练所用的时间是 CPU 预处理时间和加速器训练时间的总和。prefetch()将训练步骤的预处理和模型执行过程重叠到一起。当加速器正在执行第 N 个训练步时,CPU 正在准备第 N+1 步的数据。这样做不仅可以最大限度地缩短训练的单步用时(而不是总用时),而且可以缩短提取和转换数据所需的时间。如果不使用prefetch(),CPU 和 GPU/TPU 在大部分时间都处于空闲状态:
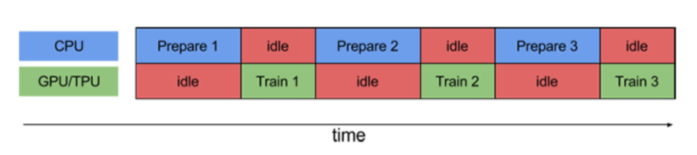
使用prefetch()可显著减少空闲时间:
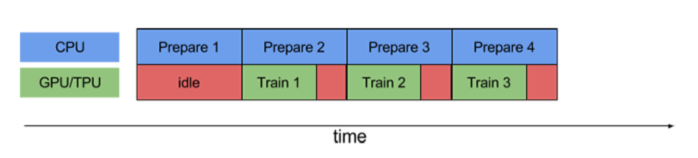
- cache():将数据集缓存到内存当中,加速运行
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
三、构建CNN网络
卷积神经网络(CNN)的输入是张量 (Tensor) 形式的 (image_height, image_width, color_channels),包含了图像高度、宽度及颜色信息。不需要输入batch size。color_channels 为 (R,G,B) 分别对应 RGB 的三个颜色通道(color channel)。在此示例中,我们的 CNN 输入形状是 (180, 180, 3)。我们需要在声明第一层时将形状赋值给参数input_shape。
网络结构图(可单击放大查看):
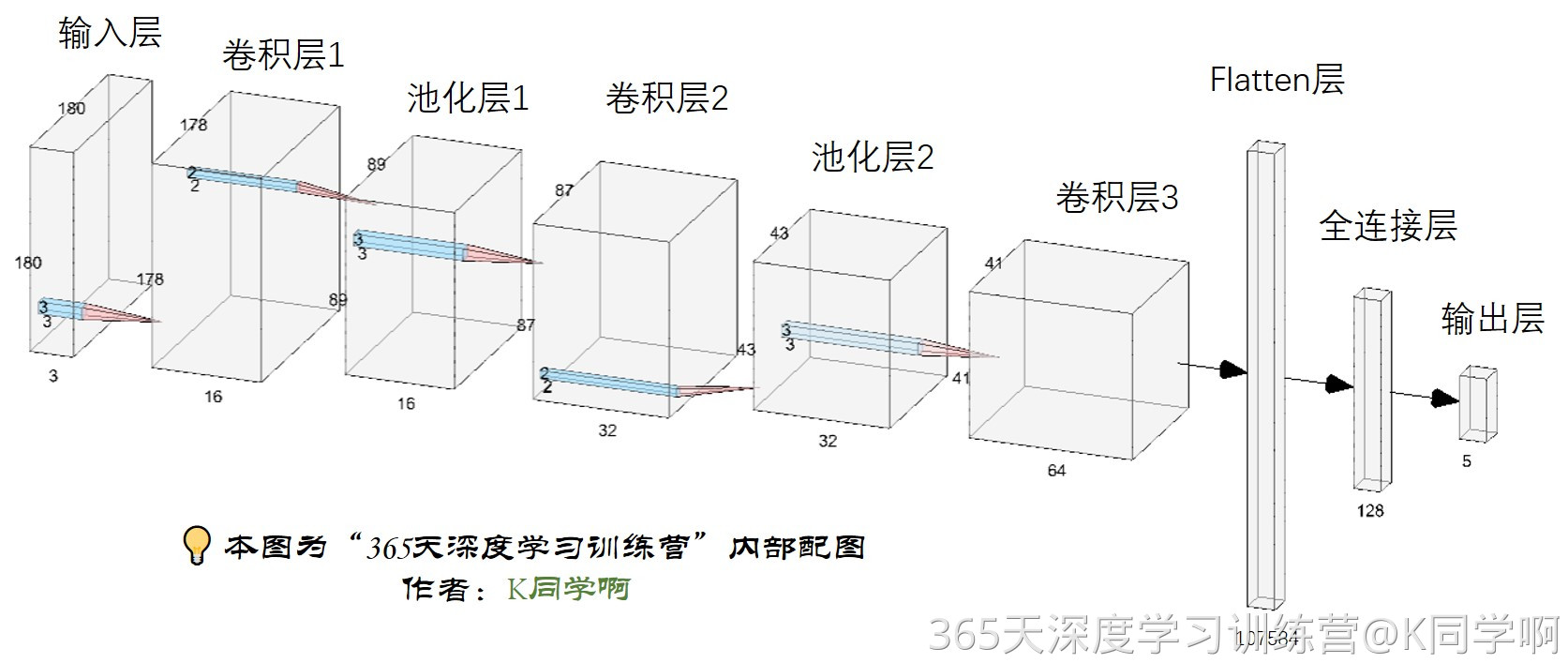
num_classes = 4
"""
关于卷积核的计算不懂的可以参考文章:https://blog.csdn.net/qq_38251616/article/details/114278995
layers.Dropout(0.4) 作用是防止过拟合,提高模型的泛化能力。
在上一篇文章花朵识别中,训练准确率与验证准确率相差巨大就是由于模型过拟合导致的
关于Dropout层的更多介绍可以参考文章:https://mtyjkh.blog.csdn.net/article/details/115826689
"""
model = models.Sequential([
#layers.experimental.preprocessing.Rescaling(1./255, input_shape=(img_height, img_width, 3)),
layers.Rescaling(1./255, input_shape=(img_height, img_width, 3)),
layers.Conv2D(16, (3, 3), activation='relu', input_shape=(img_height, img_width, 3)), # 卷积层1,卷积核3*3
layers.AveragePooling2D((2, 2)), # 池化层1,2*2采样
layers.Conv2D(32, (3, 3), activation='relu'), # 卷积层2,卷积核3*3
layers.AveragePooling2D((2, 2)), # 池化层2,2*2采样
layers.Conv2D(64, (3, 3), activation='relu'), # 卷积层3,卷积核3*3
layers.Dropout(0.3), # 让神经元以一定的概率停止工作,防止过拟合,提高模型的泛化能力。
layers.Flatten(), # Flatten层,连接卷积层与全连接层
layers.Dense(128, activation='relu'), # 全连接层,特征进一步提取
layers.Dense(num_classes) # 输出层,输出预期结果
])
model.summary() # 打印网络结构
// 👉 输出:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
rescaling (Rescaling) (None, 180, 180, 3) 0
_________________________________________________________________
conv2d (Conv2D) (None, 178, 178, 16) 448
_________________________________________________________________
average_pooling2d (AveragePo (None, 89, 89, 16) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 87, 87, 32) 4640
_________________________________________________________________
average_pooling2d_1 (Average (None, 43, 43, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 41, 41, 64) 18496
_________________________________________________________________
dropout (Dropout) (None, 41, 41, 64) 0
_________________________________________________________________
flatten (Flatten) (None, 107584) 0
_________________________________________________________________
dense (Dense) (None, 128) 13770880
_________________________________________________________________
dense_1 (Dense) (None, 4) 645
=================================================================
Total params: 13,795,109
Trainable params: 13,795,109
Non-trainable params: 0
_________________________________________________________________
四、编译
在准备对模型进行训练之前,还需要再对其进行一些设置。以下内容是在模型的编译步骤中添加的:
-
损失函数(loss):用于衡量模型在训练期间的准确率。
-
优化器(optimizer):决定模型如何根据其看到的数据和自身的损失函数进行更新。
-
指标(metrics):用于监控训练和测试步骤。以下示例使用了准确率,即被正确分类的图像的比率。
# 设置优化器
opt = tf.keras.optimizers.Adam(learning_rate=0.001)
model.compile(optimizer=opt,
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
五、训练模型
epochs = 10
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)
// 👉 输出:
Epoch 1/10
29/29 [==============================] - 6s 58ms/step - loss: 1.5865 - accuracy: 0.4463 - val_loss: 0.5837 - val_accuracy: 0.7689
Epoch 2/10
29/29 [==============================] - 0s 12ms/step - loss: 0.5289 - accuracy: 0.8295 - val_loss: 0.5405 - val_accuracy: 0.8133
Epoch 3/10
29/29 [==============================] - 0s 12ms/step - loss: 0.2930 - accuracy: 0.8967 - val_loss: 0.5364 - val_accuracy: 0.8000
Epoch 4/10
29/29 [==============================] - 0s 12ms/step - loss: 0.2742 - accuracy: 0.9074 - val_loss: 0.4034 - val_accuracy: 0.8267
Epoch 5/10
29/29 [==============================] - 0s 11ms/step - loss: 0.1952 - accuracy: 0.9383 - val_loss: 0.3874 - val_accuracy: 0.8844
Epoch 6/10
29/29 [==============================] - 0s 11ms/step - loss: 0.1592 - accuracy: 0.9468 - val_loss: 0.3680 - val_accuracy: 0.8756
Epoch 7/10
29/29 [==============================] - 0s 12ms/step - loss: 0.0836 - accuracy: 0.9755 - val_loss: 0.3429 - val_accuracy: 0.8756
Epoch 8/10
29/29 [==============================] - 0s 12ms/step - loss: 0.0943 - accuracy: 0.9692 - val_loss: 0.3836 - val_accuracy: 0.9067
Epoch 9/10
29/29 [==============================] - 0s 12ms/step - loss: 0.0344 - accuracy: 0.9909 - val_loss: 0.3578 - val_accuracy: 0.9067
Epoch 10/10
29/29 [==============================] - 0s 11ms/step - loss: 0.0950 - accuracy: 0.9708 - val_loss: 0.4710 - val_accuracy: 0.8356
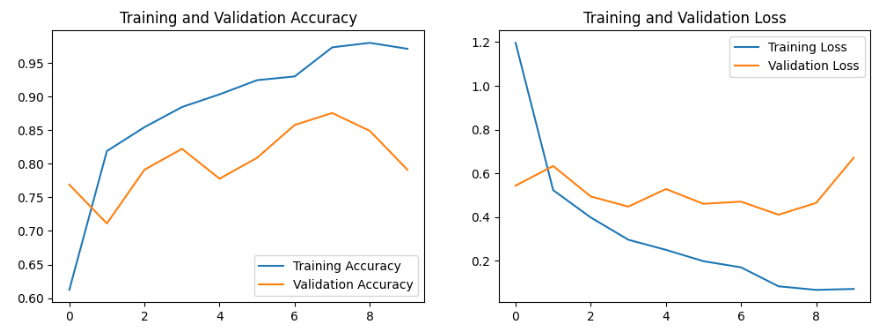
六、模型评估
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
知识补充:
- accuracy、 loss介绍
在机器学习和深度学习中,特别是在卷积神经网络(CNN)的应用中,"accuracy"(准确率)和"loss"(损失)是两个非常重要的指标。
1. Accuracy(准确率):
-
准确率是衡量模型性能的一个指标,它表示模型正确预测的样本数占总样本数的比例。
-
在分类任务中,准确率通常定义为
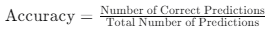
-
准确率越高,表示模型的预测结果越接近真实标签。
2. Loss(损失):
- 损失函数是衡量模型预测值与真实值之间差异的函数,用于训练过程中优化模型参数。
- 常见的损失函数包括均方误差(MSE)、交叉熵损失(Cross-Entropy Loss)等。
- 在训练过程中,目标是最小化损失函数的值,即找到一组参数使得损失函数的输出尽可能小
在卷积神经网络中,通常使用交叉熵损失函数来处理分类问题,因为它能够更好地处理概率分布的差异。损失函数的值会随着训练的进行而逐渐减小,而准确率则通常会逐渐提高。
在实际应用中,我们希望模型的损失尽可能小,准确率尽可能高。但是,有时候也会出现准确率和损失之间的矛盾,比如过拟合现象,即模型在训练集上表现很好(准确率高,损失低),但在测试集或实际应用中表现不佳。这时,可能需要采取正则化、早停(early stopping)等策略来提高模型的泛化能力。
复制分享
-
在训练卷积神经网络时,如何平衡准确率和损失函数以达到最佳性能?
在训练卷积神经网络(CNN)时,平衡准确率和损失函数以实现最佳性能是一个复杂的过程,涉及到多个方面的考虑。以下是一些关键策略:
- 选择合适的损失函数:
- 对于分类问题,通常使用交叉熵损失函数,因为它能够更好地处理概率分布的差异。
- 对于回归问题,可能会使用均方误差(MSE)或均方根误差(RMSE)等损失函数。
- 使用正则化技术:
- L1和L2正则化:通过在损失函数中添加权重衰减项,可以防止模型过拟合。
- Dropout:在训练过程中随机丢弃一些神经元,减少模型对训练数据的依赖,提高泛化能力。
- 调整模型复杂度:
- 模型太简单可能导致欠拟合(高偏差),模型太复杂可能导致过拟合(高方差)。
- 通过调整网络层数、神经元数量和连接方式来找到合适的模型复杂度。
- 数据增强:
- 通过旋转、缩放、裁剪等方法增加训练数据的多样性,提高模型的泛化能力。
- 早停(Early Stopping):
- 在验证集上的损失不再下降时停止训练,以避免过拟合。
- 学习率调整:
- 使用学习率衰减策略,如逐步衰减或指数衰减,以确保在训练后期能够进行更细致的调整。
- 使用自适应学习率优化算法,如Adam、RMSprop等,它们能够根据参数的更新历史动态调整学习率。
- 使用不同的评估指标:
- 除了准确率,还可以使用精确率、召回率、F1分数等指标来评估模型性能。
- 交叉验证:
- 使用交叉验证来评估模型在不同数据集上的性能,确保模型的稳定性和泛化能力。
- 模型集成:
- 通过集成多个模型来提高整体性能,例如使用Bagging、Boosting或Stacking等方法。
- 超参数调优:
- 使用网格搜索、随机搜索或贝叶斯优化等方法来找到最佳的超参数组合。
- 监控训练过程:
- 密切监控训练过程中的损失和准确率变化,以便及时调整策略。
通过上述策略的综合应用,可以在训练过程中有效地平衡准确率和损失函数,以达到最佳的模型性能。
- 选择合适的损失函数:
-
在训练卷积神经网络时,有哪些常见的过拟合现象,我应该如何避免?
在训练卷积神经网络(CNN)时,过拟合是一个常见的问题,它会导致模型在训练集上表现良好,但在测试集或实际应用中表现不佳。以下是一些常见的过拟合现象和避免策略:
常见的过拟合现象:
- 训练损失持续降低,但验证损失不再下降或开始上升。
- 训练准确率持续提高,而验证准确率停滞不前或下降。
- 模型在训练数据上的表现远好于在未见过的数据上。
如何避免过拟合:
- 数据增强(Data Augmentation):通过对训练数据应用一系列随机变换(如旋转、缩放、裁剪等),增加数据的多样性,提高模型的泛化能力。
- 正则化(Regularization):在损失函数中添加正则项,如L1或L2正则化,以惩罚模型复杂度,限制模型的过拟合倾向。
- Dropout:在训练过程中随机“丢弃”一部分神经元,减少它们之间的依赖,增强模型的泛化能力。
- 早停法(Early Stopping):在验证损失不再下降时停止训练,以避免过度拟合训练数据。
- 集成学习:通过结合多个模型的预测结果来提高整体性能,减少单一模型的过拟合风险。
- 调整模型复杂度:简化模型结构,减少层数或神经元数量,降低模型的复杂度。
- 批量归一化(Batch Normalization):在卷积层和全连接层之间加入批量归一化层,可以减少内部协变量偏移,加速训练过程,提高泛化能力。
- 使用更多的训练数据:如果可能的话,增加训练数据的数量和多样性,使模型有更多的机会学习到泛化的特征。
通过上述策略的综合应用,可以有效地减少CNN在训练过程中的过拟合现象,提高模型在新数据上的表现和泛化能力。
-
如何通过数据增强技术提高卷积神经网络的泛化能力?
数据增强是提高卷积神经网络(CNN)泛化能力的有效手段,它通过在训练过程中对图像数据进行一系列的随机变换,生成新的训练样本,从而增加模型的泛化能力。以下是一些常用的数据增强技术:
-
几何变换:包括旋转、缩放、平移和裁剪等操作,这些操作可以模拟拍摄角度的变化,增加模型对空间位置变化的鲁棒性。例如,可以通过
transforms.RandomRotation和transforms.RandomResizedCrop在PyTorch中实现旋转和随机裁剪 。 -
颜色空间变换:改变图像的颜色强度和对比度,模拟光照变化。可以通过
transforms.ColorJitter在PyTorch中调整亮度、对比度和饱和度 。 -
像素操作:包括添加噪声、滤波等,以增强模型对图像噪声的容忍度。例如,可以使用
transforms.GaussianBlur在PyTorch中添加高斯噪声 。 -
水平翻转:是最常用的数据增强技术之一,可以通过
transforms.RandomHorizontalFlip在PyTorch中实现。 -
归一化:通过
transforms.Normalize调整图像的均值和标准差,有助于模型训练的稳定性。 -
自动增强(AutoAugment):是一种更高级的数据增强技术,通过自动搜索最佳的数据增强策略来提高模型性能。
在实践中,数据增强应该与模型的验证性能一起监控,以确保增强策略有效且不会引入过多的噪声。此外,数据增强通常在训练集上应用,而在验证集和测试集上则使用原始数据,以准确评估模型的性能。
通过上述方法,数据增强可以帮助模型在有限的数据条件下学习到更丰富和鲁棒的特征,从而提高模型在新数据上的表现和泛化能力。
-
-
如何确定数据增强技术对卷积神经网络性能提升的具体影响?
要确定数据增强技术对卷积神经网络(CNN)性能提升的具体影响,可以采取以下几种方法:
-
比较模型性能:在应用数据增强前后,使用相同的模型架构和训练数据集进行训练,并在相同的验证集或测试集上评估模型性能。通过比较准确率、召回率、精确率、F1分数等指标的变化,可以量化数据增强的效果。
-
可视化分析:通过可视化的方式,展示数据增强后的图像与原始图像的差异。观察增强后的图像是否更具有多样性和辨识度,从而帮助模型学习到更泛化的特征。
-
对比实验:尝试多种不同的数据增强技术,如旋转、翻转、缩放、裁剪、颜色变换等,并比较它们对模型性能的影响。这可以通过在相同的模型和数据集上应用不同的增强策略,然后评估它们在验证集上的性能来实现。
-
混淆矩阵分析:使用混淆矩阵来评估模型在不同类别上的性能。混淆矩阵可以帮助识别模型在哪些类别上表现良好,以及在哪些类别上存在问题。通过比较使用数据增强前后的混淆矩阵,可以了解增强技术对模型分类能力的具体影响。
-
交叉验证:采用交叉验证的方法来评估数据增强的有效性。这种方法涉及将数据集分成多个部分,在不同的部分上进行训练和验证,以确保评估结果的稳定性和可靠性。
-
实验记录和统计测试:记录每次实验的设置和结果,并进行统计测试,如t-test,以确定性能提升是否具有统计学意义。
-
文献对比:参考相关文献和研究,如CVPR2021深度框架训练研究 ,了解数据增强在类似任务和网络架构中的效果,以及如何选择合适的数据增强技术。
通过上述方法,可以全面评估数据增强技术对CNN性能提升的具体影响,并指导实际应用中数据增强策略的选择和优化。
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号