Yolo实战二:详解YOLO检测算法的训练参数
Yolo第Y1周:详解YOLO检测算法的训练参数
- 🍨 本文为🔗IT男的一人企业中的学习记录博客
- 🍖 原作者:[IT男的一人企业]
人工智能的技术圈有一项“一招鲜,吃遍天”的免费开源技术。软件外包公司拿着它就可以吃饱喝足。这项技术就是目标检测,用的是YOLO算法。
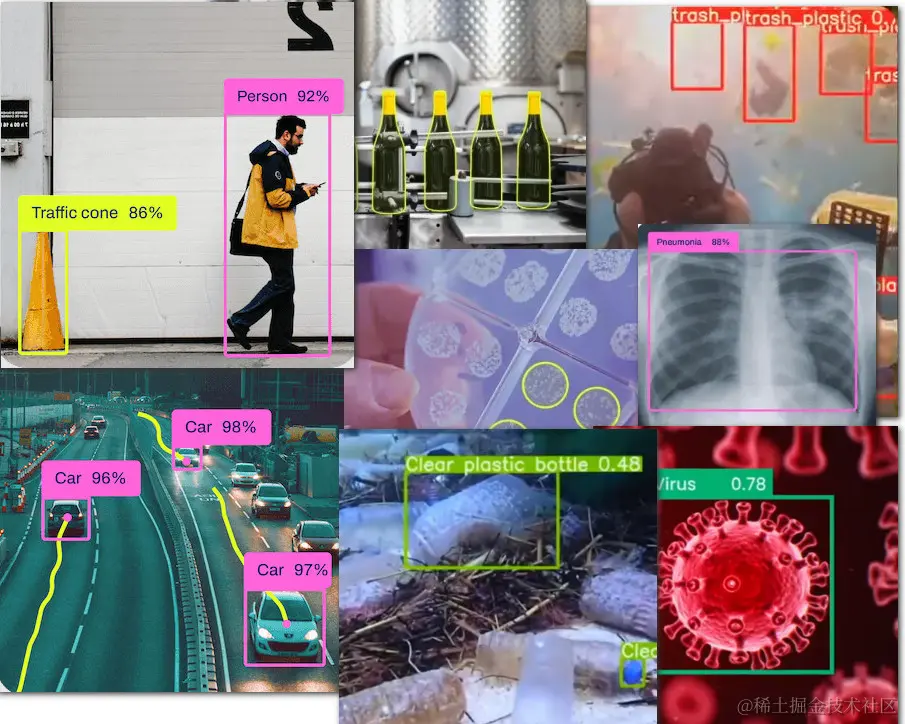
对于外行人,不管是做交通、医疗、环保还是机械行业的,他们往往会认为每一个场景都是一项技术。我接触过一个读者,他说要给我130多个AI项目做。我问都是什么项目?他告诉我,检测道路积水、检测流动摊贩、检测门前脏乱、检测违规撑伞……
我说,停停停!从我看来,这就是一个项目,都是针对某个目标进行检测。我说你有这么多需要检测的场景,咱别一个项目一个项目的走,不如做一个通用的检测平台,一招解决所以问题。

不管是检测路上的杂物,还是检测车船,看着有上百种要识别的场景。其实用到的技术都是目标检测算法。一般是用YOLO算法。
这里面最难的就是获取训练数据。这么多场景,对数据量的要求很大。因为每做一类,都要对数据进行标记。即便是现在大厂做的模型,也仅仅是通用模型,没这么细致。所谓通用就是一些生活中常见的事物,比如人啊,汽车呀。他没有细致到具体车的反光镜,化妆镜,还是后视镜。你想要搞这么细,你得找个几千张图片,然后挨个标记,交给模型去训练,训练完之后他才能进行识别。
举个例子,比方说我们想识别下图中的①和②,得先有训练素材,然后标记成训练集,最后去训练。

有些人确实是这么做了。其实,能迈出这一步的人,已经很不错了。因为多数人都望而却步,说一句:都说AI方便,什么破技术,这么费劲巴拉!
有些先驱们,前期耗费了一些人力物力,搞了一些训练集,但是最终发现还是没有获得好的效果。于是就对检测技术产生了怀疑。
我搜了搜,网上都在讲YOLO平台,还没有人专门讲过它训练参数的配置。如果配置不好参数,无异于高速上挂S档跑长途,很难获得预期的效果。
那么,YOLO进行训练时,它有哪些参数可以设置呢?又会起到什么作用呢?
以YOLOv8举例,我们可以去一个地方查询,那就是安装目录下的
ultralytics\cfg\default.yaml文件。
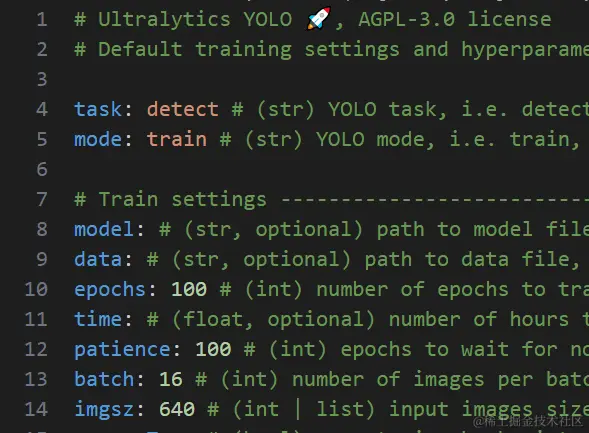
# Ultralytics YOLO 馃殌, AGPL-3.0 license
# 默认的训练设置和超参数,用于中等增强的 COCO 训练
task: detect # (str) YOLO 任务,例如检测、分割、分类、姿态
mode: train # (str) YOLO 模式,例如训练、验证、预测、导出、跟踪、基准测试
# 训练设置 --------------------------------------------------------------------------------
model: # (str, optional)模型文件的路径,例如 yolov8n.pt, yolov8n.yaml
data: # (str, optional) 数据文件的路径,例如 coco128.yaml
epochs: 100 # (int) 训练的周期数
patience: 50 # (int) 如果没有可观察到的改进,则等待周期数以提前停止训练
batch: 16 # (int) 每个批次的图像数(-1 表示自动批次)
imgsz: 640 # (int | list) 训练和验证模式下的输入图像尺寸(整数),或预测和导出模式下的列表[w,h]
save: True # (bool) 保存训练检查点和预测结果
save_period: -1 # (int) 每 x 个周期保存一次检查点(如果小于 1 则禁用)
cache: False # (bool) True/ram, disk 或 False。用于数据加载的缓存
device: # (int | str | list, optional) 运行的设备,例如 cuda device=0 或 device=0,1,2,3 或 device=cpu
workers: 8 # (int) 数据加载的工作线程数(如果是 DDP,则每个 RANK)
project: # (str, optional可选) 项目名称
name: # (str, optional) 实验名称,结果保存到 '项目/名称' 目录
exist_ok: False # (bool) 是否覆盖现有实验
pretrained: True # (bool | str) 是否使用预训练模型(bool)或从哪个模型加载权重(str)
optimizer: auto # (str) 使用的优化器,选项=[SGD, Adam, Adamax, AdamW, NAdam, RAdam, RMSProp, auto]
verbose: True # (bool) 是否打印详细输出
seed: 0 # (int) 用于可重复性的随机种子
deterministic: True # (bool) 是否启用确定性模式
single_cls: False # (bool) 将多类数据作为单类训练
rect: False # (bool) 如果模式='train' 则矩形训练,如果模式='val' 则矩形验证
cos_lr: False # (bool) 使用余弦学习率调度器
close_mosaic: 10 # (int)最后几个周期禁用马赛克增强(0 表示禁用)
resume: False # (bool) 从最后一个检查点恢复训练
amp: True # (bool) 自动混合精度 (AMP) 训练,选项=[True, False],True 运行 AMP 检查
fraction: 1.0 # (float) 训练的数据集分数(默认为 1.0,训练集中的所有图像)
profile: False # (bool) 在训练期间对 ONNX 和 TensorRT 速度进行分析以供记录器使用
freeze: None # (int | list, optional) 在训练期间冻结前 n 层,或冻结层索引列表
# Segmentation 分割
overlap_mask: True # (bool) 在训练期间(仅分割训练)掩码应重叠
mask_ratio: 4 # (int) 掩码下采样比率(仅分割训练)
# Classification 分类
dropout: 0.0 # (float) 使用 dropout 正则化(仅分类训练)
# Val/Test settings --------------------------------------------------------------------
val: True # (bool) 在训练期间进行验证/测试
split: val # (str) 用于验证的数据集分割,例如 'val', 'test' 或 'train'
save_json: False # (bool) 将结果保存为 JSON 文件
save_hybrid: False # (bool) 保存标签的混合版本(标签 + 额外预测)
conf: # (float, optional) 检测的对象置信度阈值(默认预测为 0.25,验证为 0.001)
iou: 0.7 # (float) 用于 NMS 的交集超过并集 (IoU) 阈值
max_det: 300 # (int) 每张图片的最大检测数
half: False # (bool) 使用半精度 (FP16)
dnn: False # (bool) 使用 OpenCV DNN 进行 ONNX 推理
plots: True # (bool) 在训练/验证期间保存绘图
# 预测设置 -------------------------------------------------------------------------------
source: # (str, optional) 图像或视频的源目录
show: False # (bool) 如果可能,显示结果
save_txt: False # (bool) 将结果保存为 .txt 文件
save_conf: False # (bool) 保存带有置信度分数的结果
save_crop: False # (bool) 保存带有结果的裁剪图像
show_labels: True # (bool) 在绘图中显示对象标签
show_conf: True # (bool) 在绘图中显示对象置信度分数
vid_stride: 1 # (int) 视频帧率步幅
stream_buffer: False # (bool) 缓冲所有流式传输帧(True)或返回最近帧(False)
line_width: # (int, optional) 边界框的线宽,缺失时自动
visualize: False # (bool) 可视化模型特征
augment: False # (bool) 对预测源应用图像增强
agnostic_nms: False # (bool) 类别不可知的 NMS
classes: # (int | list[int], optional) 通过类别过滤结果,例如 classes=0, 或 classes=[0,2,3]
retina_masks: False # (bool) 使用高分辨率分割掩码
boxes: True # (bool) 在分割预测中显示盒子
# Export settings 导出设置 ----------------------------------------------------------------
format: torchscript # (str) 导出的格式,选项在 https://docs.ultralytics.com/modes/export/#export-formats
keras: False # (bool) 使用 Kera=s
optimize: False # (bool) TorchScript: 针对移动设备优化
int8: False # (bool) CoreML/TF INT8 量化
dynamic: False # (bool) ONNX/TF/TensorRT: dynamic axes
simplify: False # (bool) ONNX: 简化模型
opset: # (int, optional) ONNX: opset 版本
workspace: 4 # (int) TensorRT: 工作区大小 (GB)
nms: False # (bool) CoreML: 添加 NMS
# Hyperparameters ------------------------------------------------------------------------------------------------------
lr0: 0.01 # (float) 初始学习率(例如 SGD=1E-2, Adam=1E-3)
lrf: 0.01 # (float) 最终学习率(lr0 * lrf)
momentum: 0.937 # (float) 动量/Adam beta1
weight_decay: 0.0005 # (float) 优化器权重衰减 5e-4
warmup_epochs: 3.0 # (float) 预热周期(可以是小数)
warmup_momentum: 0.8 # (float) 预热初始动量
warmup_bias_lr: 0.1 # (float) 预热初始偏置 lr
box: 7.5 # (float) 盒子损失增益
cls: 0.5 # (float) cls分类损失增益(按像素缩放)
dfl: 1.5 # (float) dfl 损失增益
pose: 12.0 # (float) 姿态损失增益
kobj: 1.0 # (float) 关键点对象损失增益
label_smoothing: 0.0 # (float) 标签平滑(分数)
nbs: 64 # (int) 名义批次大小
hsv_h: 0.015 # (float) 图像 HSV-色调增强(分数)
hsv_s: 0.7 # (float) 图像 HSV-饱和度增强(分数)
hsv_v: 0.4 # (float) 图像 HSV-值增强(分数)
degrees: 0.0 # (float) 图像旋转(+/- 度)
translate: 0.1 # (float) 图像翻译 (+/- fraction)
scale: 0.5 # (float) 图像缩放 (+/- gain)
shear: 0.0 # (float) 图像剪切 (+/- deg)
perspective: 0.0 # (float) 图像透视 (+/- fraction), range 0-0.001
flipud: 0.0 # (float) 图像上下翻转(概率)
fliplr: 0.5 # (float) 图像左右翻转(概率)
mosaic: 1.0 # (float) 图像马赛克(概率)
mixup: 0.0 # (float) 图像混合(概率)
copy_paste: 0.0 # (float) 段落复制粘贴(概率)
# Custom config.yaml --------------------------------------------------------------------
cfg: # (str, optional) for overriding defaults.yaml
# Tracker settings 跟踪器设置 -------------------------------------------------------------
tracker: botsort.yaml # (str)跟踪器类型, 选项=[botsort.yaml, bytetrack.yaml]
这里面有100多项参数配置。为了方便使用,多数它都默认了一个通用的数值。这个通用一词,它又出现了。
英文阅读有困难的,我提供了一个中文版。
它包含了任务模式设置、训练设置、分割设置、分类设置、测试设置、预测设置、可视化设置、导出设置、超参数设置等几大类设置
我先说几个常见的、重要的,主要是提醒大伙儿了解配置的重要性。
就拿我这个数字标号的检测来说,如果我正常标记,不改配置直接训练的话,效果可能不会太好。

为啥?常规操作不都是这样吗?标记数据,形成训练集,然后训练。
我们超参数设置下的一个配置,就是下图中的fliplr:
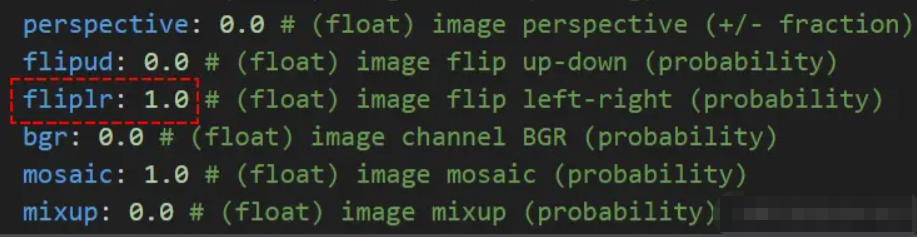
这项设置的作用是:图像左右翻转的概率。它默认是1.0,也就是说100%会进行左右翻转。
训练的过程中,处理流程会有记录,我们在runs/detect/train目录下,可看到具体效果:

放大图片,发现了没有?我们正常的图片被镜面翻转了。也就是图片发生了flip left-right。为什么会这样?
其实对于AI来说,它需要很多数据,越多越好。但是,我们往往提供不足。因此,AI框架会想办法在合理范围内自己造数据。这一步操作叫“图片增强”。
大家看,这是一张狗的图片!

那么问题来了!下面这些图片,你看还是不是狗?

依然是狗。即便经过翻转、旋转、改变透明度,甚至放大、缩小、尺寸压缩变形,更过分的话,裁掉一部分。我们打眼一看,它就很狗!
我和AI一起过日子,我很了解,AI真正想要的是这类素材。AI说,既然你们人类说这些都是,那为什么不交给我训练?人类没有说话。因此,这才有了“图片增强”!
YOLOv8中,关于图片增强常用的设置有如下几个:
degrees: 图像旋转角度(+/- 度数)。translate: 图像平移(+/- 比例)。scale: 图像缩放(+/- 增益)。shear: 图像剪切(+/- 度数)。perspective: 图像透视(+/- 比例),范围0-0.001。flipud: 图像上下翻转(概率)。fliplr: 图像左右翻转(概率)。bgr: 图像通道BGR(概率)。mosaic: 图像马赛克(概率)。mixup: 图像混合(概率)。copy_paste: 分割拷贝粘贴(概率)。
上面说了,它都有一个通用的默认设置。我们是可以修改的。它默认的数值,不一定就适合我们的场景。
举个例子,如果默认进行翻转。那么这一点,对我检测数字的场景就不合适。看下图,2水平翻转后就是5,而6和9也只差一个旋转。
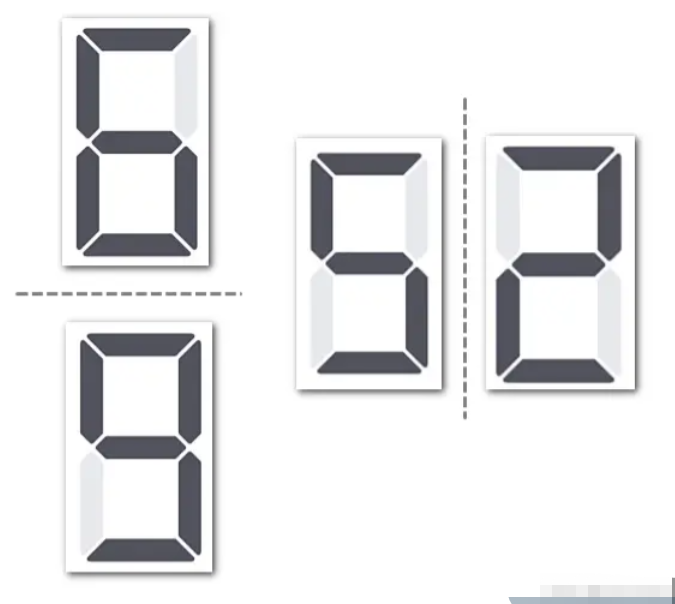
这时候你标记了大量的数字2,但是经过数据增强后,数据其实是5,但是标记依然是2。这就造成2、5不分。
拿数字举例子虽然深刻,但多少有些抬杠。换一个生活中的物体。比如检测车辆行驶。如果轮胎在下面,那么就是正常行驶。如果轮胎朝天,那就是翻车了。
因此这些图片增强,要根据你的实际场景进行开启和关闭。
再讲一个重要的参数。网上没有人讲过,不知道是大家不知道,还是故意保密。就是mosaic这个参数,它是图像马赛克的控制。这项设置也是默认100%应用。
很多人对这一项不了解。我们看看开启和关闭有什么区别。
当mosaic为0.0,也就是完全不开启的时候,我们的训练数据就是标注的那样。

当mosaic为1.0,表示100%的图像都开启马赛克效果,那么训练数据会在标注的基础上做如下效果的处理。

它的工作原理如下:
- 图像拼接:从数据集中随机选择四张图像,将它们分别放置在拼接图像的四个象限中。这四张图像的大小会根据拼接图像的大小进行调整。
- 随机裁剪和缩放:在拼接过程中,图像可能会被随机裁剪和缩放,以生成具有不同尺寸和内容的新的组合图像。
- 标签调整:每张原始图像中的目标标签(如边界框)也会相应地调整,以适应新的拼接图像的位置和大小。
通过将多张图像组合在一起,增加了训练样本的多样性,有助于模型更好地适应不同的视角和尺度,从而提高模型在不同场景下的鲁棒性。
在配置文件中,可以将这个值设置为0到1之间的一个小数。例如,mosaic: 0.5表示每张图像有50%的概率应用 Mosaic数据增强。
从算法角度看,这是一件好事。但是,是否打开也取决于你的具体的场景。
这种增强虽然好,但是由于对裁剪拼接的数据进行了训练。它会破坏检测的完整性。也就是说,如果你的检测画面中存在目标的一小部分,它也会检测出来。有时候,可能我们并不想这样。拿检测汽车来说,如果你希望只检测出完整的汽车,那么mosaic这个开关要关掉。
诸如此类的配置,还有很多。希望大家根据自己的情况自行调整。千万不要拿到训练集不思考,直接一条命令就训练。
上面说的参数配置会影响模型训练的准确率。那么下面说的一些参数,则会影响训练的时间效率。
在train settings也就是训练设置中,有两项参数batch和workers。
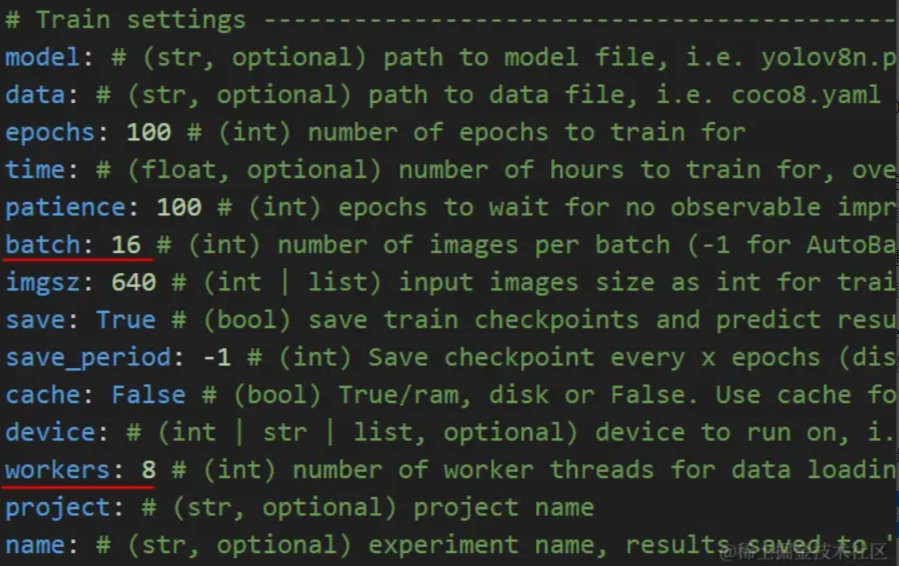
这个batch是一次训练多少张图片。我们在runs文件下经常看到如下的图片。

他们名称都带batch,而且都是4行4列共16格子的图片。因为这里默认的batch就是16。
batch该设置多少,跟你的训练设备配置有关。这就相当于你吃饭的饭量。有人一筷子能夹起4个藕片,有人则一下吃16个。吃多吃少,都要与自身匹配。
该如何设置数值呢?
如果你用CPU进行训练,batch的大小影响的是RAM,也就是内存。如果你用GPU训练,那么批次大小影响的是显存。
批次越大,显存/内存消耗越多。如果显存/内存不足,训练可能会失败或变得非常缓慢。如果批次太小,那么利用率又会太低,很多资源都会闲置着。
我们可以从一个较小的批次大小开始,如8或16。然后逐步增加,直到显存/内存耗尽,或着发现模型性能开始下降。
如果你嫌麻烦,也可以使用自动批次大小:在配置文件中,可以将批次大小设置为-1。这样YOLO会自动根据你的GPU显存选择合适的批次大小。
再说一下workers参数。这个参数是设置数据加载时的工作线程数,也就是并行加载数据的进程数。一般workers可以是任何正整数,并不一定非要是2的倍数。选择适当的workers数量,要根据系统的CPU核心数量和任务负载进行调整。
每个worker线程会占用一个CPU核心,因此设置的workers数量应该与系统的CPU核心数量相匹配。如果系统有8个CPU核心,设置workers: 8是合理的。如果workers数量过多,可能会导致CPU资源争用,反而降低数据加载的效率。
实际实践中,也是从较小值开始。比如从系统CPU核心数量的一半开始设置。然后逐步增加,观察数据加载效率和系统负载情况,直到找到一个最佳值。
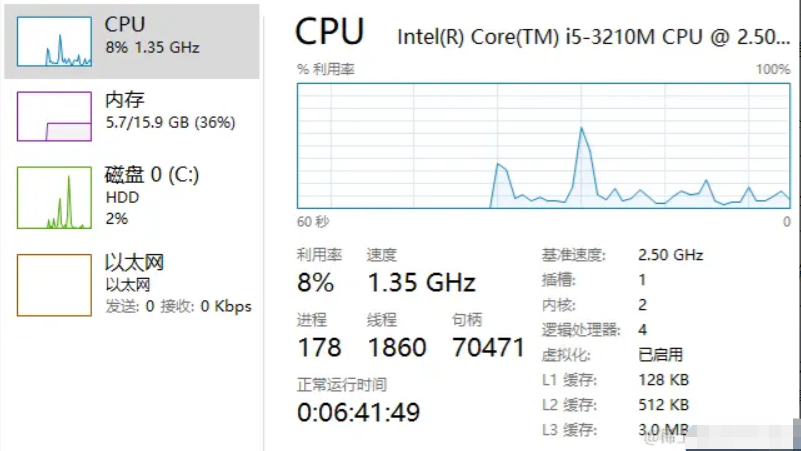
我都是看两者的占用情况。如果CPU占用率只有40%,那我就增加workers数量,以充分利用CPU资源。如果内存还有很大空余,那么就增加batch数量。batch相当于原料入口的供应,workers相当于加工的吞吐性能,两者要找到一个平衡点。
对于GPU设备,workers的设置应考虑数据加载速度与GPU计算速度的平衡。一般情况下,可以设置为GPU数量的4倍到8倍。具体可以从workers为8或16开始,然后根据GPU利用率和数据加载速度进行调整。
batch: 32 # 初始batch size
workers: 8 # 初始workers数量
device: 0 # 指定使用GPU 0
cache: ram # 使用内存缓存数据,加快数据加载速度
做人工智能应用嘛!又不是让你研发AI芯片或者创建全新的算法框架。主要工作可不就是调来调去的,根据参数调效果。我认为它是一门以实践为主的科学。如果知道了怎么调,仍然连调不愿调就说不好用,那就太懒喽!
- 下一篇:如何从各种
result数据,看YOLO的训练效果。类似于从血常规化验单看身体状况。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号