037.Kubernetes集群网络-Docker网络实现
一 Docker网络
1.1 Docker网络类型
标准的Docker支持以下4类网络模式:
- host模式:使用--net=host指定。
- container模式:使用--net=container:NAME_or_ID指定。
- none模式:使用--net=none指定。
- bridge模式:使用--net=bridge指定,为默认设置。
在Kubernetes管理模式下通常只会使用bridge模式,如下介绍在bridge模式下Docker是如何支持网络的。
提示:更多Docker网络参考《006.Docker网络管理》。
二 bridge模式
2.1 bridge模型
在bridge模式下,Docker Daemon第1次启动时会创建一个虚拟的网桥,默认的名称是docker0,然后在私有网络空间中给这个网桥分配一个子网。针对由Docker创建的每一个容器,都会创建一个虚拟的以太网设备(Veth设备对),其中一端关联到网桥上,另一端使用Linux的网络命名空间技术,映射到容器内的eth0设备,然后从网桥的地址段内给eth0接口分配一个IP地址。
如图所示为Docker的默认桥接网络模型:

其中ip1是网桥的IP地址,Docker Daemon会在几个备选地址段里给它选一个地址,通常是以172开头的一个地址。这个地址和主机的IP地址是不重叠的。ip2是Docker在启动容器时,在这个地址段选择的一个没有使用的IP地址分配给容器。相应的MAC地址也根据这个IP地址,在02:42:ac:11:00:00和02:42:ac:11:ff:ff的范围内生成,这样做可以确保不会有ARP冲突。
启动后,Docker还将Veth对的名称映射到eth0网络接口。ip3就是主机的网卡地址。
通常,ip1、ip2和ip3是不同的IP段,所以在默认不做任何特殊配置的情况下,在外部是看不到ip1和ip2的。
这样做的结果就是,在同一台机器内的容器之间可以相互通信,不同主机上的容器不能相互通信,实际上它们甚至有可能在相同的网络地址范围内(不同主机上的docker0的地址段可能是一样的)。
为了让它们跨节点互相通信,就必须在主机的地址上分配端口,然后通过这个端口路由或代理到容器上。这种做法显然意味着一定要在容器之间小心谨慎地协调好端口的分配,或者使用动态端口的分配技术。
在不同应用之间协调好端口分配是十分困难的事情,特别是集群水平扩展时。而动态的端口分配也会带来高度复杂性,例如:每个应用程序都只能将端口看作一个符号(因为是动态分配的,所以无法提前设置)。
而且API Server要在分配完后,将动态端口插入配置的合适位置,服务也必须能互相找到对方等。这些都是Docker的网络模型在跨主机访问时面临的问题。
注意:更多跨主机的Docker通信方案,可参考《006.Docker网络管理》。
2.2 网络规则
- 查看Docker启动后的系统情况
Docker网络中,在bridge模式下Docker Daemon启动时创建docker0网桥,并在网桥使用的网段为容器分配IP。
Docker Daemon刚启动并且还没有启动任何容器时,网络协议栈的配置情况如下:
[root@docker ~]# ip addr
[root@docker ~]# iptables-save


Docker创建了docker0网桥,并添加了iptables规则。docker0网桥和iptables规则都处于root命名空间中。对这些规则的说明如下:
- 在NAT表中有3条记录,前两条匹配生效后,都会继续执行DOCKER链,而此时DOCKER链为空,所以前两条只是做了一个框架,并没有实际效果。
- NAT表第3条的含义是,若本地发出的数据包不是发往docker0的,即是发往主机之外的设备的,则都需要进行动态地址修改(MASQUERADE),将源地址从容器的地址(172段)修改为宿主机网卡的IP地址,之后就可以发送给外面的网络了。
- 在FILTER表中,第1条也是一个框架,因为后继的DOCKER链是空的。
- 在FILTER表中,第3条是说,docker0发出的包,如果需要Forward到非docker0的本地IP地址的设备,则是允许的。这样,docker0设备的包就可以根据路由规则中转到宿主机的网卡设备,从而访问外面的网络。
- FILTER表中,第4条是说,docker0的包还可以被中转给docker0本身,即连接在docker0网桥上的不同容器之间的通信也是允许的。
- FILTER表中,第2条是说,如果接收到的数据包属于以前已经建立好的连接,那么允许直接通过。这样接收到的数据包自然又走回docker0,并中转到相应的容器。
除了如上Netfilter的设置,Linux的ip_forward功能也被Docker Daemon打开了:
[root@docker ~]# cat /proc/sys/net/ipv4/ip_forward
1
[root@docker ~]# ip route
default via 172.24.9.1 dev eth0
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1 linkdown
172.24.9.0/24 dev eth0 proto kernel scope link src 172.24.9.138
- 查看容器启动后的情况(容器无端口映射)
首先启动一个容器,如Registry容器(不使用任何端口镜像参数),看一下网络堆栈部分相关的变化:
[root@docker ~]# docker run --name register -d registry #运行容器
[root@docker ~]# ip addr
[root@docker ~]# iptables-save
[root@docker ~]# ip route

- 宿主机器上的Netfilter和路由表都没有变化,说明在不进行端口映射时,Docker的默认网络是没有特殊处理的。相关的NAT和FILTER这两个Netfilter链还是空的。
- 宿主机上的Veth对已经建立,并连接到容器内。
[root@docker ~]# docker exec -ti register /bin/sh #容器内查看相关信息
/ # ip route
/ # ip addr

如上默认停止的回环设备lo已经被启动,外面宿主机连接进来的Veth设备也被命名成了eth0,并且已经配置了地址172.17.0.2。路由信息表包含一条到docker0的子网路由和一条到docker0的默认路由。
查看容器启动后的情况(容器有端口映射)
[root@docker ~]# docker run --name register -d -p 1180:5000 registry #带端口映射启动registry
[root@docker ~]# iptables-save

如上新增的规则可以看出,Docker服务在NAT和FILTER两个表内添加的两个DOCKER子链都是给端口映射用的。在本例中我们需要把外面宿主机的1180端口映射到容器的5000端口。
通过分析可知,无论是宿主机接收到的还是宿主机本地协议栈发出的,目标地址是本地IP地址的包都会经过NAT表中的DOCKER子链。Docker为每一个端口映射都在这个链上增加了到实际容器目标地址和目标端口的转换。经过这个DNAT的规则修改后的IP包,会重新经过路由模块的判断进行转发。由于目标地址和端口已经是容器的地址和端口,所以数据自然就被转发到docker0上,从而被转发到对应的容器内部。
当然在Forward时,也需要在DOCKER子链中添加一条规则,如果目标端口和地址是指定容器的数据,则允许通过。在Docker按照端口映射的方式启动容器时,主要的不同就是上述iptables部分。而容器内部的路由和网络设备,都和不做端口映射时一样,没有任何变化。
三 Docker网络局限
3.1 Docker的网络局限
从Docker对Linux网络协议栈的示例可知,Docker一开始没有考虑到多主机互联的网络解决方案。Docker一直以来的理念都是“简单为美”。通常,虚拟化技术中最为复杂的部分就是虚拟化网络技术。
多主机互联相关方案有Libnetwork,Libnetwork针对目前Docker的网络实现,Docker使用的Libnetwork组件只是将Docker平台中的网络子系统模块化为一个独立库的简单尝试,离成熟和完善还有一段距离。
提示:更多Docker网络实现方案参考:《007.基于Docker的Etcd分布式部署》、《008.Docker Flannel+Etcd分布式网络部署》。
作者:木二
出处:http://www.cnblogs.com/itzgr/
关于作者:云计算、虚拟化,Linux,多多交流!
本文版权归作者所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接!如有其他问题,可邮件(xhy@itzgr.com)咨询。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号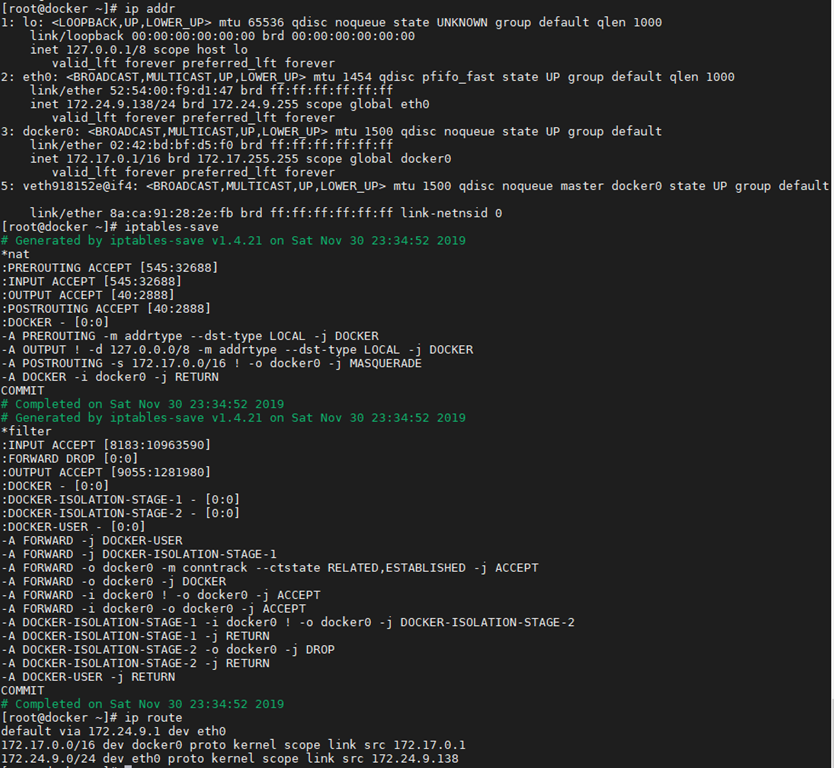{kind=link}