029.Kubernetes核心组件-Controller Manager
一 Controller Manager原理
1.1 Controller Manager概述
一般来说,智能系统和自动系统通常会通过一个“控制系统”来不断修正系统的工作状态。在Kubernetes集群中,每个Controller都是这样的一个“控制系统”,它们通过API Server提供的(List-Watch)接口实时监控集群中特定资源的状态变化,当发生各种故障导致某资源对象的状态发生变化时,Controller会尝试将其状态调整为期望的状态。
比如当某个Node意外宕机时,Node Controller会及时发现此故障并执行自动化修复流程,确保集群始终处于预期的工作状态。Controller Manager是Kubernetes中各种Controller的管理者,是集群内部的管理控制中心,也是Kubernetes自动化功能的核心。
Controller Manager内部包含Replication Controller、Node Controller、ResourceQuota Controller、Namespace Controller、ServiceAccount Controller、Token Controller、Service Controller及Endpoint Controller这8种Controller,每种Controller都负责一种特定资源的控制流程,而Controller Manager正是这些Controller的核心管理者。
提示:ServiceAccount Controller与Token Controller是与安全相关的两个控制器,并且与ServiceAccount、Token密切相关。

提示:在Kubernetes集群中与Controller Manager协调的另一个组件是Kubernetes Scheduler,它的作用是将待调度的Pod(包括通过API Server新创建的Pod及RC为补足副本而创建的Pod等)通过一些复杂的调度流程计算出最佳目标节点,然后绑定到该节点上。
二 Replication Controller
2.1 Replication Controller(副本控制器)作用
Replication Controller的核心作用是确保在任何时候集群中某个RC关联的Pod副本数量都保持预设值。如果发现Pod的副本数量超过预期值,则Replication Controller会销毁一些Pod副本;反之,Replication Controller会自动创建新的Pod副本,直到符合条件的Pod副本数量达到预设值。
注意:只有当Pod的重启策略是Always时(RestartPolicy=Always),Replication Controller才会管理该Pod的操作(例如创建、销毁、重启等)。
在通常情况下,Pod对象被成功创建后不会消失,唯一的例外是当Pod处于succeeded或failed状态的时间过长(超时参数由系统设定)时,该Pod会被系统自动回收,管理该Pod的副本控制器将在其他工作节点上重新创建、运行该Pod副本。
RC中的Pod模板就像一个模具,模具制作出来的东西一旦离开模具,它们之间就再也没关系了。同样,一旦Pod被创建完毕,无论模板如何变化,甚至换成一个新的模板,也不会影响到已经创建的Pod了。
此外,Pod可以通过修改它的标签来脱离RC的管控。该方法可以用于将Pod从集群中迁移、数据修复等调试。
对于被迁移走的Pod,RC会自动创建一个新的副本替换被迁移的副本。
注意:删除一个RC不会影响它所创建的Pod。
如果想删除一个被RC所控制的Pod,则需要将该RC的副本数(Replicas)属性设置为0,这样所有的Pod副本就都会被自动删除。
提示:建议不要越过RC直接创建Pod,因为Replication Controller会通过RC管理Pod副本,实现自动创建、补足、替换、删除Pod副本,这样能提高系统的容灾能力,减少由于节点崩溃等意外状况造成的损失。即使应用程序只用到一个Pod副本,也强烈建议使用RC来定义Pod。
Replication Controller的作用总结如下:
- 确保在当前集群中有且仅有N个Pod实例,N是在RC中定义的Pod副本数量。
- 通过调整RC的spec.replicas属性值来实现系统扩容或者缩容。
- 通过改变RC中的Pod模板(主要是镜像版本)来实现系统的滚动升级。
2.2 Replication Controller(副本控制器)场景
Replication Controller的典型使用场景通常有如下几种:
- 重新调度(Rescheduling):不管想运行1个副本还是1000个副本,副本控制器都能确保指定数量的副本存在于集群中,即使发生节点故障或Pod副本被终止运行等意外状况。
- 弹性伸缩(Scaling):手动或者通过自动扩容代理修改副本控制器的spec.replicas属性值,非常容易实现增加或减少副本的数量。
- 滚动更新(RollingUpdates):副本控制器被设计成通过逐个替换Pod的方式来辅助服务的滚动更新。推荐的方式是创建一个只有一个副本的新RC,若新RC副本数量加1,则旧RC的副本数量减1,直到这个旧RC的副本数量为0,然后删除该旧RC。通过上述模式,即使在滚动更新的过程中发生了不可预料的错误,Pod集合的更新也都在可控范围内。在理想情况下,滚动更新控制器需要将准备就绪的应用考虑在内,并保证在集群中任何时刻都有足够数量的可用Pod。
三 Node Controller
3.1 Node Controller作用
kubelet进程在启动时通过API Server注册自身的节点信息,并定时向API Server汇报状态信息,API Server在接收到这些信息后,会将这些信息更新到etcd中。在etcd中存储的节点信息包括节点健康状况、节点资源、节点名称、节点地址信息、操作系统版本、Docker版本、kubelet版本等。
节点健康状况包含“就绪”(True)“未就绪”(False)和“未知”(Unknown)三种。
3.2 Node Controller工作流程
Node Controller通过API Server实时获取Node的相关信息,实现管理和监控集群中的各个Node的相关控制功能。

Node Controller的核心工作流程:
- ControllerM anager在启动时如果设置了--cluster-cidr参数,那么为每个没有设置Spec.PodCIDR的Node都生成一个CIDR地址,并用该CIDR地址设置节点的Spec.PodCIDR属性,这样做的目的是防止不同节点的CIDR地址发生冲突。
- 逐个读取Node信息,多次尝试修改nodeStatusMap中的节点状态信息,将该节点信息和Node Controller的nodeStatusMap中保存的节点信息做比较。如果判断出没有收到kubelet发送的节点信息、第1次收到节点kubelet发送的节点信息,或在该处理过程中节点状态变成非“健康”状态,则在nodeStatusMap中保存该节点的状态信息,并用Node Controller所在节点的系统时间作为探测时间和节点状态变化时间。如果判断出在指定时间内收到新的节点信息,且节点状态发生变化,则在nodeStatusMap中保存该节点的状态信息,并用Node Controller所在节点的系统时间作为探测时间和节点状态变化时间。如果判断出在指定时间内收到新的节点信息,但节点状态没发生变化,则在nodeStatusMap中保存该节点的状态信息,并用Node Controller所在节点的系统时间作为探测时间,将上次节点信息中的节点状态变化时间作为该节点的状态变化时间。如果判断出在某段时间(gracePeriod)内没有收到节点状态信息,则设置节点状态为“未知”,并且通过API Server保存节点状态。
- 逐个读取节点信息,如果节点状态变为非“就绪”状态,则将节点加入待删除队列,否则将节点从该队列中删除。如果节点状态为非“就绪”状态,且系统指定了CloudProvider,则Node Controller调用CloudProvider查看节点,若发现节点故障,则删除etcd中的节点信息,并删除和该节点相关的Pod等资源的信息。
四 ResourceQuota Controller
4.1 ResourceQuota Controller作用
ResourceQuota Controller,即资源配额管理,资源配额管理确保了指定的资源对象在任何时候都不会超量占用系统物理资源,避免了由于某些业务进程的设计或实现的缺陷导致整个系统运行紊乱甚至意外宕机,对整个集群的平稳运行和稳定性有非常重要的作用。
目前Kubernetes支持如下三个层次的资源配额管理。
- 容器级别,可以对CPU和Memory进行限制。
- Pod级别,可以对一个Pod内所有容器的可用资源进行限制。
- Namespace级别,为Namespace(多租户)级别的资源限制,包括:
- Pod数量;
- Replication Controller数量;
- Service数量;
- ResourceQuota数量;
- Secret数量;
- 可持有的PV数量。
Kubernetes的配额管理是通过Admission Control(准入控制)来控制的,Admission Control当前提供了两种方式的配额约束,分别是LimitRanger与ResourceQuota。
其中LimitRanger作用于Pod和Container,ResourceQuota则作用于Namespace,限定一个Namespace里的各类资源的使用总额。
4.2 ResourceQuota Controller工作流程

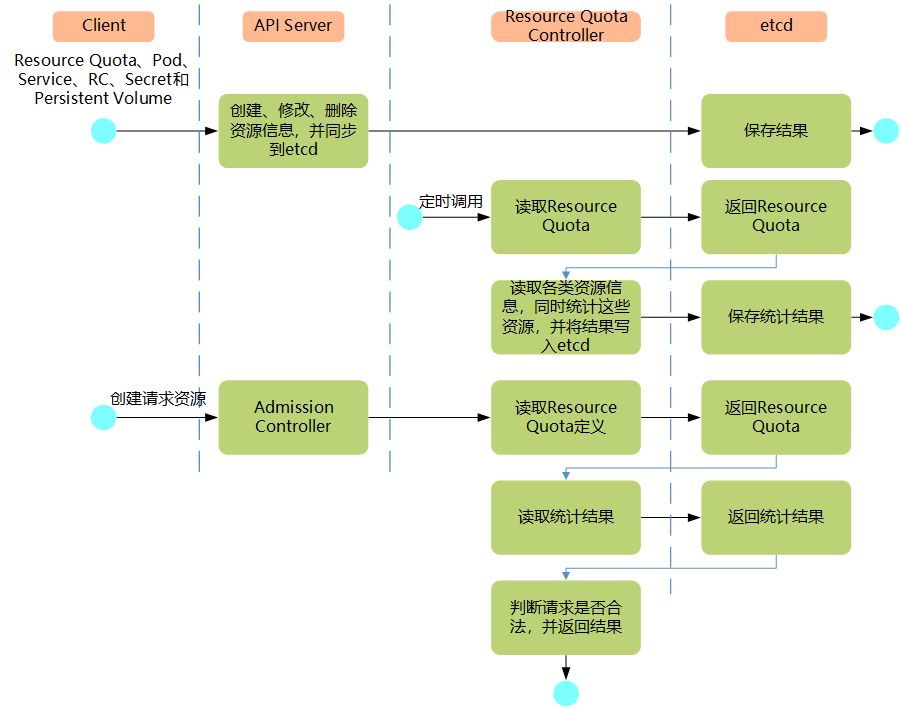
如图所示,如果在Pod定义中同时声明了LimitRanger,则用户通过API Server请求创建或修改资源时,Admission Control会计算当前配额的使用情况,如果不符合配额约束,则创建对象失败。
对于定义了ResourceQuota的Namespace,ResourceQuota Controller组件则负责定期统计和生成该Namespace下的各类对象的资源使用总量,统计结果包括Pod、Service、RC、Secret和PersistentVolume等对象实例个数,以及该Namespace下所有Container实例所使用的资源量(目前包括CPU和内存),然后将这些统计结果写入etcd的resourceQuotaStatusStorage目录(resourceQuotas/status)下。写入resourceQuotaStatusStorage的内容包含Resource名称、配额值(ResourceQuota对象中spec.hard域下包含的资源的值)、当前使用值(ResourceQuota Controller统计出来的值)。随后这些统计信息被Admission Control使用,以确保相关Namespace下的资源配额总量不会超过ResourceQuota中的限定值。
五 Namespace Controller
5.1 Namespace Controller作用
用户通过API Server可以创建新的Namespace并将其保存在etcd中,Namespace Controller定时通过API Server读取这些Namespace的信息。如果Namespace被API标识为优雅删除(通过设置删除期限实现,即设置DeletionTimestamp属性),则将该NameSpace的状态设置成Terminating并保存到etcd中。同时Namespace Controller删除该Namespace下的ServiceAccount、RC、Pod、Secret、PersistentVolume、ListRange、ResourceQuota和Event等资源对象。
在Namespace的状态被设置成Terminating后,由Admission Controller的NamespaceLifecycle插件来阻止为该Namespace创建新的资源。同时,在Namespace Controller删除该Namespace中的所有资源对象后,Namespace Controller对该Namespace执行finalize操作,删除Namespace的spec.finalizers域中的信息。如果Namespace Controller观察到Namespace设置了删除期限,同时Namespace的spec.finalizers域值是空的,那么Namespace Controller将通过API Server删除该Namespace资源。
六 Service Controller与Endpoints Controller
6.1 Service Controller与Endpoints Controller作用
如下所示为Service、Endpoints与Pod的关系。

Endpoints表示一个Service对应的所有Pod副本的访问地址,Endpoints Controller就是负责生成和维护所有Endpoints对象的控制器。
Endpoints Controller负责监听Service和对应的Pod副本的变化,如果监测到Service被删除,则删除和该Service同名的Endpoints对象。如果监测到新的Service被创建或者修改,则根据该Service信息获得相关的Pod列表,然后创建或者更新Service对应的Endpoints对象。如果监测到Pod的事件,则更新它所对应的Service的Endpoints对象(增加、删除或者修改对应的Endpoint条目)。
每个Node的kube-proxy进程会使用Endpoints对象,kube-proxy进程获取每个Service的Endpoints,实现了Service的负载均衡功能。
因此Service Controller的作用,它其实是属于Kubernetes集群与外部的云平台之间的一个接口控制器。Service Controller监听Service的变化,如果该Service是一个LoadBalancer类型的Service(externalLoadBalancers=true),则Service Controller确保在外部的云平台上该Service对应的LoadBalancer实例被相应地创建、删除及更新路由转发表(根据Endpoints的条目)。
七 Admission Control
7.1 Admission Control概述
Admission Control配备了一个准入控制器的插件列表,发送给API Server的任何请求都需要通过列表中每个准入控制器的检查,检查不通过,则API Server拒绝此调用请求。此外,准入控制器插件能够修改请求参数以完成一些自动化任务,比如ServiceAccount这个控制器插件。
7.2 可配置创建列表
当前可配置的准入控制器插件如下。
- AlwaysAdmit:已弃用,允许所有请求。
- AlwaysPullImages:在启动容器之前总是尝试重新下载镜像。这对于多租户共享一个集群的场景非常有用,系统在启动容器之前可以保证总是使用租户的密钥去下载镜像。如果不设置这个控制器,则在Node上下载的镜像的安全性将被削弱,只要知道该镜像的名称,任何人便都可以使用它们了。
- AlwaysDeny:已弃用,禁止所有请求,用于测试。
- DefaultStorageClass:会关注PersistentVolumeClaim资源对象的创建,如果其中没有包含任何针对特定Storage class的请求,则为其指派指定的Storage class。在这种情况下,用户无须在PVC中设置任何特定的Storage class就能完成PVC的创建了。如果没有设置默认的Storage class,该控制器就不会进行任何操作;如果设置了超过一个的默认Storage class,该控制器就会拒绝所有PVC对象的创建申请,并返回错误信息。因此需要确保Storage class对象的配置只有一个默认值。
注意:该控制器仅关注PVC的创建过程,对更新过程无效。
- DefaultTolerationSeconds:针对没有设置容忍node.kubernetes.io/not-ready:NoExecute或者node.alpha.kubernetes.io/unreachable:NoExecute的Pod,设置5min的默认容忍时间。
- DenyExecOnPrivileged:已弃用,拦截所有想在Privileged Container上执行命令的请求。如果你的集群支持Privileged Container,又希望限制用户在这些Privileged Container上执行命令,那么强烈推荐使用它。其功能已被合并到DenyEscalatingExec中。
- DenyEscalatingExec:拦截所有exec和attach到具有特权的Pod上的请求。如果你的集群支持运行有escalated privilege权限的容器,又希望限制用户在这些容器内执行命令,那么强烈推荐使用它。
- EventReateLimit:Alpha版本,用于应对事件密集情况下对API Server造成的洪水攻击。
- ExtendedResourceToleration:如果需要创建带有特定资源(例如GPU、FPGA等)的独立节点,则可能会对节点进行Taint处理来进行特别配置。该控制器能够自动为申请这些特别资源的Pod加入Toleration定义,无须人工干预。
- ImagePolicyWebhook:这个插件将允许后端的一个Webhook程序来完成Admission Controller的功能。ImagePolicyWebhook需要使用一个配置文件(通过kube-API Server的启动参数--admission-control-config-file设置)定义后端Webhook的参数。目前是Alpha版本的功能。
- Initializers:Alpha。用于为动态准入控制提供支持,通过修改待创建资源的元数据来完成对该资源的修改。LimitPodHardAntiAffinityTopology:该插件启用了Pod的反亲和性调度策略设置,在设置亲和性策略参数requiredDuringSchedulingRequiredDuringExecution时要求将topologyKey的值设置为“kubernetes.io/hostname”,否则Pod会被拒绝创建。
- LimitRanger:这个插件会监控进入的请求,确保请求的内容符合在Namespace中定义的LimitRange对象里的资源限制。如果要在Kubernetes集群中使用LimitRange对象,则必须启用该插件才能实施这一限制。LimitRanger还能用于为没有设置资源请求的Pod自动设置默认的资源请求,该插件会为default命名空间中的所有Pod设置0.1CPU的资源请求。
- MutatingAdmissionWebhook:Beta。这一插件会变更符合要求的请求的内容,Webhook以串行的方式顺序执行。
- NamespaceAutoProvision:这一插件会检测所有进入的具备命名空间的资源请求,如果其中引用的命名空间不存在,就会自动创建命名空间。
- NamespaceExists:这一插件会检测所有进入的具备命名空间的资源请求,如果其中引用的命名空间不存在,就会拒绝这一创建过程。
- NamespaceLifecycle:如果尝试在一个不存在的Namespace中创建资源对象,则该创建请求将被拒绝。当删除一个Namespace时,系统将会删除该Namespace中的所有对象,包括Pod、Service等,并阻止删除default、kube-system和kube-public这三个命名空间。
- NodeRestriction:该插件会限制kubelet对Node和Pod的修改行为。为了实现这一限制,kubelet必须使用system:nodes组中用户名为system:node:<nodeName>的Token来运行。符合条件的kubelet只能修改自己的Node对象,也只能修改分配到各自Node上的Pod对象。在Kubernetes1.11以后的版本中,kubelet无法修改或者更新自身Node的taint属性。在Kubernetes1.13以后,这一插件还会阻止kubelet删除自己的Node资源,并限制对有kubernetes.io/或k8s.io/前缀的标签的修改。
- OnwerReferencesPermissionEnforcement:在该插件启用后,一个用户要想修改对象的metadata.ownerReferences,就必须具备delete权限。该插件还会保护对象的metadata.ownerReferences[x].blockOwnerDeletion字段,用户只有在对finalizers子资源拥有update权限的时候才能进行修改。
- PersistentVolumeLabel:弃用。这一插件自动根据云供应商(例如GCE或AWS)的定义,为PersistentVolume对象加入region或zone标签,以此来保障PersistentVolume和Pod同处一区。如果插件不为PV自动设置标签,则需要用户手动保证Pod和其加载卷的相对位置。该插件正在被Cloudcontrollermanager替换,从Kubernetes1.11版本开始默认被禁止。
- PodNodeSelector:该插件会读取命名空间的annotation字段及全局配置,来对一个命名空间中对象的节点选择器设置默认值或限制其取值。
- PersistentVolumeClaimResize:该插件实现了对PersistentVolumeClaim发起的resize请求的额外校验。
- PodPreset:该插件会使用PodSelector选择Pod,为符合条件的Pod进行注入。
- PodSecurityPolicy:在创建或修改Pod时决定是否根据Pod的securitycontext和可用的PodSecurityPolicy对Pod的安全策略进行控制。
- PodTolerationRestriction:该插件首先会在Pod和其命名空间的Toleration中进行冲突检测,如果其中存在冲突,则拒绝该Pod的创建。它会把命名空间和Pod的Toleration进行合并,然后将合并的结果与命名空间中的白名单进行比较,如果合并的结果不在白名单内,则拒绝创建。如果不存在命名空间级的默认Toleration和白名单,则会采用集群级别的默认Toleration和白名单。
- Priority:这一插件使用priorityClassName字段来确定优先级,如果没有找到对应的PriorityClass,该Pod就会被拒绝。
- ResourceQuota:用于资源配额管理目的,作用于Namespace。该插件拦截所有请求,以确保在Namespace上的资源配额使用不会超标。推荐在Admission Control参数列表中将这个插件排最后一个,以免可能被其他插件拒绝的Pod被过早分配资源。
- SecurityContextDeny:这个插件将在Pod中定义的SecurityContext选项全部失效。SecurityContext在Container中定义了操作系统级别的安全设定(uid、gid、capabilities、SELinux等)。在未设置PodSecurityPolicy的集群中建议启用该插件,以禁用容器设置的非安全访问权限。
- ServiceAccount:这个插件将ServiceAccount实现了自动化,如果想使用ServiceAccount对象,那么强烈推荐使用它。
- StorageObjectInUseProtection:这一插件会在新创建的PVC或PV中加入kubernetes.io/pvc-protection或kubernetes.io/pv-protection的finalizer。如果想要删除PVC或者PV,则直到所有finalizer的工作都完成,删除动作才会执行。
- ValidatingAdmissionWebhook:在Kubernetes1.8中为Alpha版本,在Kubernetes1.9中为Beta版本。该插件会针对符合其选择要求的请求调用校验Webhook。目标Webhook会以并行方式运行;如果其中任何一个Webhook拒绝了该请求,该请求就会失败。
在API Server上设置参数即可定制我们需要的准入控制链,如果启用多种准入控制选项,则建议设置:在Kubernetes1.9及之前的版本中使用的参数是--admission-control,并且其中的内容是顺序相关的;在Kubernetes1.10及之后的版本中,该参数为--enable-admission-plugins,并且与顺序无关。
对Kubernetes 1.10及以上版本设置如下:
1 --enable-admission-plugins=NamespaceLifecycle,LimitRanger,ServiceAccount,DefaultsStorageClass,DefaultTolerationSeconds,MutatingAdmissionWebhook,ValidatingAdmissionWebhook,ResourceQuota
对Kubernetes 1.9及以下版本设置如下:
1 --enable-admission-plugins=NamespaceLifecycle,LimitRanger,ServiceAccount,DefaultStorageClass,DefaultTolerationSeconds,MutatingAdmissionWebhook,CalidatingAdmissionWebhook,ResourceQuota
作者:木二
出处:http://www.cnblogs.com/itzgr/
关于作者:云计算、虚拟化,Linux,多多交流!
本文版权归作者所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接!如有其他问题,可邮件(xhy@itzgr.com)咨询。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号{kind=link}
{kind=link}