
国产开源流批统一的数据同步工具Chunjun入门实战
 前面我们学习过SeaTunnel这个优秀数据集成平台,今天再来研究一个与之相似开源产品ChunJun,原名为FlinkX其比SeaTunnel开源更早,本篇从了解其概况和特性;然后通过源码编译的方式部署,暂时先通过简单的Local和Standalone两种提交任务方式,通过几个示例一步步演示如何通过Json和SQL两种配置方式实现批流模式,如从MySQL数据源Sink写入HDFS、从Kafka数据源并通过关联ClickHouse表数据转换并最后Sink写入MySQL的使用。
前面我们学习过SeaTunnel这个优秀数据集成平台,今天再来研究一个与之相似开源产品ChunJun,原名为FlinkX其比SeaTunnel开源更早,本篇从了解其概况和特性;然后通过源码编译的方式部署,暂时先通过简单的Local和Standalone两种提交任务方式,通过几个示例一步步演示如何通过Json和SQL两种配置方式实现批流模式,如从MySQL数据源Sink写入HDFS、从Kafka数据源并通过关联ClickHouse表数据转换并最后Sink写入MySQL的使用。
@
概述
定义
Chunjun 官网 https://dtstack.github.io/chunjun-web/ 源码release最新版本1.12.8
Chunjun 文档地址 https://ververica.github.io/flink-cdc-connectors/master/
Chunjun 源码地址 https://github.com/DTStack/chunjun
Chunjun是一个分布式集成框架,原名是FlinkX,由袋鼠云开源,其基于Flink的批流统一打造的数据同步工具,可以实现各种异构数据源之间的数据同步和计算。
ChunJun是一个基于 Flink 提供易用、稳定、高效的批流统一的数据集成工具,可以采集静态的数据如 MySQL,HDFS 等,也可以采集实时变化的数据如 binlog,Kafka等。
特性
- 易使用:基于JSON模板和SQL脚本 快速构建数据同步任务,SQL脚本兼容Flink SQL语法;只需要关注数据源的结构信息即可, 节省了时间,专注于数据集成的开发。FlinkX既支持数据同步、实时采集,也支持SQL流与维表的Join,实现了一套插件完成数据的同步、转换与计算。
- 基于 Flink:基于flink 原生的input,output 相关接口来实现多种数据源之间的数据传输,同时可以基于 flink 扩展插件。易于扩展,高度灵活,新扩展的数据源插件可以瞬间与现有的数据源插件集成,插件开发人员无需关心其他插件的代码逻辑;
- 多种运行模式:支持分布式算子 支持 flink-standalone、yarn-session、 yarn-per job 及其他提交任务方式。支持Docker一键式部署,支持在k8s上部署和运行,支持使用native kuberentes方式以session和run-application模式提交任务。
- 关键特性
- 多种数据源之间数据传输 ,支持MySQL、Oracle、SQLServer、Hive、Kudu等20多种数据源的同步计算
- 断点续传 :配合flink检查点机制,实现断点恢复、任务容灾。比如针对断点续传主要是设置断点续传字段和断点续传字段在reader里的column的位置,当然前提任务也是得开启checkpoint。
- 部分插件支持通过Flink的checkpoint机制从失败的位置恢复任务。断点续传对数据源 ️强制要求:
- 必须包含一个升序的字段,比如主键或者日期类型的字段,同步过程中会使用checkpoint机制记录这个字段的值,任务恢复运行时使用这个字段构造查询条件过滤已经同步过的数据,如果这个字段的值不是升序的,那么任务恢复时过滤的数据就是错误的,最终导致数据的缺失或重复。
- 数据源必须支持数据过滤,如果不支持的话,任务就无法从断点处恢复运行,会导致数据重复。
- 目标数据源必须支持事务,比如关系数据库,文件类型的数据源也可以通过临时文件的方式支持。
- 部分插件支持通过Flink的checkpoint机制从失败的位置恢复任务。断点续传对数据源 ️强制要求:
- 全量与增量同步:不仅支持同步DML数据,还支持DDL同步,如'CREATE TABLE', 'ALTER COLUMN'等;比如利用增量键,数据库表中增量递增的字段,比如自增id及其开始位置。
- 实时采集:既支持离线同步计算,又兼容实时场景;实时数据还原。
- FlinkX支持二阶段提交,目前FlinkX几乎所有插件都支持二阶段提交。
- FlinkX支持数据湖 Iceberg,可以流式读取和写入Iceberg数据湖,未来也会加入Hudi支持。
- 流控管理:大数据同步时在负载高的时候有时候会给系统带来很大的压力,FlinkX使用令牌桶限流方式限速,当源端产生数据的速率达到一定阈值就不会读取数据。
- 大多数插件支持数据的并发读写,可以大大提高读写速度;
- 脏数据管理:异构系统执行大数据迁移不可避免的会有脏数据产生,脏数据会影响同步任务的执行,FlinkX的Writer插件在写数据是会把以下几种类型作为脏数据写入脏数据表里:
- 类型转换错误
- 空指针
- 主键冲突
- 其它错误
部署
安装
- 部署Flink集群(使用前面)
- 获取源码编译打包
# 最新release版本源码flink12.7,如果是下载主线master版本,目前源码默认引入flink16.1,可以通过git clone https://github.com/DTStack/chunjun.git也可以直接http下main,由于是学习可使用master版本来踩坑
wget https://github.com/DTStack/chunjun/archive/refs/tags/v1.12.8.tar.gz
tar -xvf v1.12.8.tar.gz
# 进入源码目录
cd chunjun-1.12.8/
# 编译打包执行,下面两种选一
./mvnw clean package
sh build/build.sh
在根目录下生成 chunjun-dist目录,官方提供丰富的示例程序,详细可以查看chunjun-examples目录
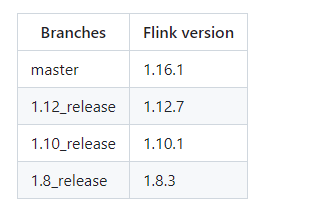
版本对应关系
下表显示了ChunJun分支与flink版本的对应关系。如果版本没有对齐,在任务中会出现'Serialization Exceptions', 'NoSuchMethod Exception'等问题。
通用配置详解
整体配置
一个完整的 ChunJun 任务脚本配置包含 content, setting 两个部分。content 用于配置任务的输入源与输出源,其中包含 reader,writer。而 setting 则配置任务整体的环境设定,其中包含 speed,errorLimit,metricPluginConf,restore,log,dirty。总体结构如下所示:
{
"job" : {
"content" :[{
"reader" : {},
"writer" : {}
}],
"setting" : {
"speed" : {},
"errorLimit" : {},
"metricPluginConf" : {},
"restore" : {},
"log" : {},
"dirty":{}
}
}
}

Content 配置
reader 用于配置数据的输入源,即数据从何而来。具体配置如下所示:
"reader" : {
"name" : "xxreader",
"parameter" : {
......
}
}
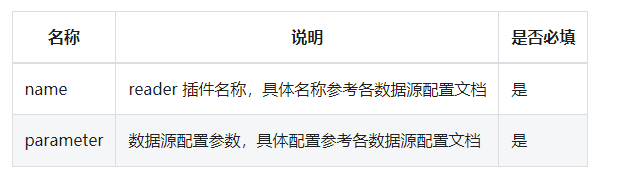
Writer 用于配置数据的输出目的地,即数据写到哪里去。具体配置如下所示:
"writer" : {
"name" : "xxwriter",
"parameter" : {
......
}
}

Setting 配置
- speed 用于配置任务并发数及速率限制。具体配置如下所示
- errorLimit 用于配置任务运行时数据读取写入的出错控制。
- metricPluginConf 用于配置 flinkx 指标相关信息。目前只应用于 Jdbc 插件中,在作业结束时将 StartLocation 和 EndLocation 指标发送到指定数据源中。目前支持 Prometheus 和 Mysql。
- restore 用于配置同步任务类型(离线同步、实时采集)和断点续传功能。
- log 用于配置 ChunJun 中定义的插件日志的保存与记录。
- dirty 用于配置脏数据的保存,通常与 ErrorLimit 联合使用。
详细使用查看官方的说明
Local提交
进入Chunjun根目录,测试脚本执行本地环境,查看stream.json
{
"job": {
"content": [
{
"reader": {
"parameter": {
"column": [
{
"name": "id",
"type": "id"
},
{
"name": "name",
"type": "string"
},
{
"name": "content",
"type": "string"
}
],
"sliceRecordCount": [
"30"
],
"permitsPerSecond": 1
},
"table": {
"tableName": "sourceTable"
},
"name": "streamreader"
},
"writer": {
"parameter": {
"column": [
{
"name": "id",
"type": "id"
},
{
"name": "name",
"type": "string"
}
],
"print": true
},
"table": {
"tableName": "sinkTable"
},
"name": "streamwriter"
},
"transformer": {
"transformSql": "select id,name from sourceTable where CHAR_LENGTH(name) < 50 and CHAR_LENGTH(content) < 50"
}
}
],
"setting": {
"errorLimit": {
"record": 100
},
"speed": {
"bytes": 0,
"channel": 1,
"readerChannel": 1,
"writerChannel": 1
}
}
}
}
bash ./bin/chunjun-local.sh -job chunjun-examples/json/stream/stream.json
Standalone提交
Json方式使用
将依赖文件复制到Flink lib目录下,这个复制操作需要在所有Flink cluster机器上执行
cp -r chunjun-dist $FLINK_HOME/lib
启动Flink Standalone环境
sh $FLINK_HOME/bin/start-cluster.sh
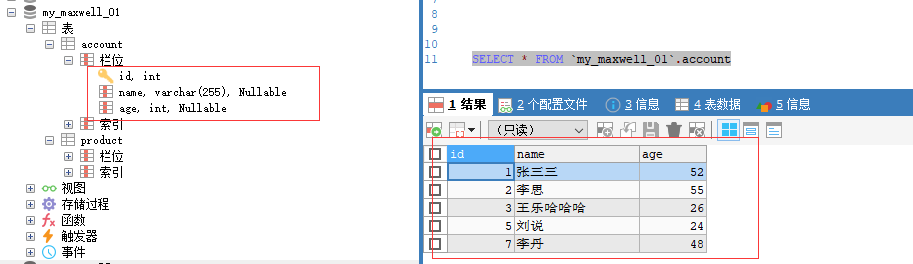
准备mysql的数据,作为读取数据源
准备job文件,创建chunjun-examples/json/mysql/mysql_hdfs_polling_my.json
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column" : [
{
"name" : "id",
"type" : "bigint"
},{
"name" : "name",
"type" : "varchar"
},{
"name" : "age",
"type" : "bigint"
}
],
"splitPk": "id",
"splitStrategy": "mod",
"increColumn": "id",
"startLocation": "1",
"username": "root",
"password": "123456",
"queryTimeOut": 2000,
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://mysqlserver:3308/my_maxwell_01?useSSL=false"
],
"table": [
"account"
]
}
],
"polling": false,
"pollingInterval": 3000
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"fileType": "text",
"path": "hdfs://myns/user/hive/warehouse/chunjun.db/kudu_txt",
"defaultFS": "hdfs://myns",
"fileName": "pt=1",
"fieldDelimiter": ",",
"encoding": "utf-8",
"writeMode": "overwrite",
"column": [
{
"name": "id",
"type": "BIGINT"
},
{
"name": "VARCHAR",
"type": "VARCHAR"
},
{
"name": "age",
"type": "BIGINT"
}
],
"hadoopConfig": {
"hadoop.user.name": "root",
"dfs.ha.namenodes.ns": "nn1,nn2",
"fs.defaultFS": "hdfs://myns",
"dfs.namenode.rpc-address.ns.nn2": "hadoop1:9000",
"dfs.client.failover.proxy.provider.ns": "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider",
"dfs.namenode.rpc-address.ns.nn1": "hadoop2:9000",
"dfs.nameservices": "myns",
"fs.hdfs.impl.disable.cache": "true",
"fs.hdfs.impl": "org.apache.hadoop.hdfs.DistributedFileSystem"
}
}
}
}
],
"setting" : {
"restore" : {
"restoreColumnName" : "id",
"restoreColumnIndex" : 0
},
"speed" : {
"bytes" : 0,
"readerChannel" : 3,
"writerChannel" : 3
}
}
}
}
启动同步任务
bash ./bin/chunjun-standalone.sh -job chunjun-examples/json/mysql/mysql_hdfs_polling_my.json
任务执行完后通过web控制台可以看到执行成功信息,查看HDFS路径数据也可以看到刚刚成功写入的数据

SQL方式使用
MySQL Sink
创建一个个Kafka的topic用于数据源读取
kafka-topics.sh --create --zookeeper zk1:2181,zk2:2181,zk3:2181 --replication-factor 3 --partitions 3 --topic my_test1
ClickHouse创建testdb数据库和sql_side_table表
CREATE DATABASE IF NOT EXISTS testdb;
CREATE TABLE if not exists sql_side_table
(
id Int64,
test1 Int64,
test2 Int64
) ENGINE = MergeTree()
PRIMARY KEY (id);
insert into sql_side_table values(1,11,101),(2,12,102),(3,13,103);
MySQL创建sql_sink_table表
CREATE TABLE `sql_sink_table` (
`id` bigint NOT NULL,
`name` varchar(100) COLLATE utf8mb4_general_ci DEFAULT NULL,
`test1` bigint DEFAULT NULL,
`test2` bigint DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci
创建sql文件chunjun-examples/sql/clickhouse/kafka_clickhouse_my.sql
CREATE TABLE source (
id BIGINT,
name STRING
) WITH (
'connector' = 'kafka-x',
'topic' = 'my_test1',
'properties.bootstrap.servers' = 'kafka1:9092',
'properties.group.id' = 'dodge',
'format' = 'json'
);
CREATE TABLE side (
id BIGINT,
test1 BIGINT,
test2 BIGINT
) WITH (
'connector' = 'clickhouse-x',
'url' = 'jdbc:clickhouse://ck1:8123/testdb',
'table-name' = 'sql_side_table',
'username' = 'default',
'lookup.cache-type' = 'lru'
);
CREATE TABLE sink (
id BIGINT,
name VARCHAR,
test1 BIGINT,
test2 BIGINT
)WITH (
'connector' = 'mysql-x',
'url' = 'jdbc:mysql://mysqlserver:3306/test',
'table-name' = 'sql_sink_table',
'username' = 'root',
'password' = '123456',
'sink.buffer-flush.max-rows' = '1024',
'sink.buffer-flush.interval' = '10000',
'sink.all-replace' = 'true'
);
INSERT INTO sink
SELECT
s1.id AS id,
s1.name AS name,
s2.test1 AS test1,
s2.test2 AS test2
FROM source s1
JOIN side s2
ON s1.id = s2.id
启动同步任务
bash ./bin/chunjun-standalone.sh -job chunjun-examples/sql/clickhouse/kafka_clickhouse_my.sql
往kafka的my_test1这个topic写入数据
./kafka-console-producer.sh --broker-list cdh1:9092 --topic my_test1
{"id":1,"name":"sunhaiyang"}
{"id":2,"name":"gulili"}
查看MySQL的sql_sink_table表已经有刚才写入消息并关联出结果的数据

Kafka Sink
创建两个Kafka的topic,一个用于数据源读取,一个用于数据源写入
kafka-topics.sh --create --zookeeper zk1:2181,zk2:2181,zk3:2181 --replication-factor 3 --partitions 3 --topic my_test3
kafka-topics.sh --create --zookeeper zk1:2181,zk2:2181,zk3:2181 --replication-factor 3 --partitions 3 --topic my_test4
创建sql文件chunjun-examples/sql/kafka/kafka_kafka_my.sql
CREATE TABLE source_test (
id INT
, name STRING
, money decimal
, datethree timestamp
, `partition` BIGINT METADATA VIRTUAL -- from Kafka connector
, `topic` STRING METADATA VIRTUAL -- from Kafka connector
, `leader-epoch` int METADATA VIRTUAL -- from Kafka connector
, `offset` BIGINT METADATA VIRTUAL -- from Kafka connector
, ts TIMESTAMP(3) METADATA FROM 'timestamp' -- from Kafka connector
, `timestamp-type` STRING METADATA VIRTUAL -- from Kafka connector
, partition_id BIGINT METADATA FROM 'partition' VIRTUAL -- from Kafka connector
, WATERMARK FOR datethree AS datethree - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka-x'
,'topic' = 'my_test3'
,'properties.bootstrap.servers' = 'kafka1:9092'
,'properties.group.id' = 'test1'
,'scan.startup.mode' = 'earliest-offset'
,'format' = 'json'
,'json.timestamp-format.standard' = 'SQL'
,'scan.parallelism' = '2'
);
CREATE TABLE sink_test
(
id INT
, name STRING
, money decimal
, datethree timestamp
, `partition` BIGINT
, `topic` STRING
, `leader-epoch` int
, `offset` BIGINT
, ts TIMESTAMP(3)
, `timestamp-type` STRING
, partition_id BIGINT
) WITH (
'connector' = 'kafka-x'
,'topic' = 'my_test4'
,'properties.bootstrap.servers' = 'kafka1:9092'
,'format' = 'json'
,'sink.parallelism' = '2'
,'json.timestamp-format.standard' = 'SQL'
);
INSERT INTO sink_test
SELECT *
from source_test;
往kafka的my_test3这个topic写入数据
kafka-console-producer.sh --broker-list cdh1:9092 --topic my_test3
{"id":100,"name":"guocai","money":243.18,"datethree":"2023-07-03 22:00:00.000"}
{"id":101,"name":"hanmeimei","money":137.32,"datethree":"2023-07-03 22:00:01.000"}
启动同步任务
bash ./bin/chunjun-standalone.sh -job chunjun-examples/sql/kafka/kafka_kafka_my.sql
查看kafka的my_test4的数据,已经收到相应数据并打上kafka元数据信息
kafka-console-consumer.sh --bootstrap-server kafka:9092 --topic my_test4 --from-beginning

- 本人博客网站IT小神 www.itxiaoshen.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号