数据治理之关键环节元数据管理开源项目datahub探索
 元数据管理在数据治理中非常关键的部分,本篇分享一个现代化元数据管理开源项目datahub,了解其核心功能和概念,进一步理解器其架构和组件,然后从0到1的搭建和使用官方的数据样例演示,最后通过摄取MySQL和ClickHouse的示例打开其探索之门。
元数据管理在数据治理中非常关键的部分,本篇分享一个现代化元数据管理开源项目datahub,了解其核心功能和概念,进一步理解器其架构和组件,然后从0到1的搭建和使用官方的数据样例演示,最后通过摄取MySQL和ClickHouse的示例打开其探索之门。
@
概述
定义
datahub 官网地址 https://datahubproject.io/ 最新版本v0.10.2
datahub 官网文档地址 https://datahubproject.io/docs/
datahub 源码地址 https://github.com/datahub-project/datahub
DataHub是一个面向现代数据栈的开源元数据平台,依赖于元数据管理的现代方法。其前身是LinkedIn为了提高数据团队的工作效率,开发并开源的WhereHows;DataHub的可扩展元数据平台支持数据发现、数据可观察性和联合治理,有助于控制数据生态系统的复杂性。
DataHub是一个现代数据目录,旨在实现端到端数据发现、数据可观察性和数据治理。这个可扩展的元数据平台是为开发人员构建的,以控制其快速发展的数据生态系统的复杂性,并为数据从业者利用其组织内数据的总价值。
元数据是开启数据治理的探索之路的关键环节。
在DAMA-DMBOK2中描述元数据最常见的定义是“关于数据的数据”。这个定义非常简单,但也容易引起误解。可以归类为元数据的信息范围很广,不仅包括技术和业务流程、数据规则和约束,还包括逻辑数据结构与物理数据结构等。它描述了数据本身(如数据库、数据元素、数据模型),数据表示的概念(如业务流程、应用系统、软件代码、技术基础设施),数据与概念之间的联系(关系)。元数据可以帮助组织理解其自身的数据、系统和流程,同时帮助用户评估数据质量,对数据库与其他应用程序的管理来说是不可或缺的。它有助于处理、维护、集成、保护和治理其他数据。
- 如果没有可靠的元数据,组织就不知道它拥有什么数据、数据表示什么、数据来自何处、它如何在系统中流转,谁有权访问它,或者对于数据保持高质量的意义。
- 如果没有元数据,组织就不能将其数据作为资产进行管理。
- 实际上,如果没有元数据,组织可能根本无法管理其数据
简而言之,元数据是“ 提供有关其他数据的信息的数据,元数据也是数据,元数据管理是为了对数据资产进行有效的组织。它使用元数据来帮助管理他们的数据。它还可以帮助数据专业人员收集、组织、访问和丰富元数据,以支持数据治理。
DataHub有巨大的生态系统,预构建集成包括Kafka, Airflow, MySQL, SQL Server, Postgres, LDAP, Snowflake, Hive, BigQuery等等;且社区正在不断添加更多的集成。
核心功能
- 搜索和发现
- 搜索数据堆栈的所有角落:DataHub的统一搜索体验显示了跨数据库、数据湖、BI平台、ML功能商店、编排工具等的搜索结果。
- 跟踪端到端沿袭:通过跟踪跨平台、数据集、ETL/ELT管道、图表、仪表板等的沿袭,快速了解数据的端到端旅程。
- 理解中断变更对下游依赖关系的影响:使用影响分析主动识别哪些实体可能受到破坏性更改的影响。
- “元数据360”概览:结合技术和逻辑元数据,提供数据实体的360º视图。生成数据集统计以了解数据的形状和分布。
- 从Great Expectations等工具获取历史数据验证结果。
- 利用DataHub的Schema Version History跟踪数据物理结构随时间的变化。
- 现代数据治理
- 实时治理:action框架支持以下实时用例
- 通知:在DataHub上进行更改时生成特定于组织的通知。例如,当向任何数据资产添加“PII”标记时,向治理团队发送电子邮件。
- 工作流集成:将DataHub集成到组织的内部工作流中。例如,当在数据集上提出特定的标签或术语时,创建Jira票据。
- 同步:将DataHub中的更改同步到第三方系统。例如,将DataHub中的标记添加反映到Snowflake中。
- 审计:随着时间的推移,审计谁对DataHub进行了哪些更改。
- 管理实体所有权:快速方便地为用户和用户组分配实体所有权。
- 使用标签、术语表和域进行管理:授权数据所有者通过以下方式管理其数据实体
- 标签:非正式的,松散控制的标签,作为搜索和发现的工具。没有正式的中央管理。
- 术语表术语:具有可选层次结构的受控词汇表,通常用于描述核心业务概念和度量。
- 域:精心策划的顶级文件夹或类别,广泛用于数据网格中,按部门(如财务、营销)或数据产品组织实体。
- DataHub管理
- 创建用户、组和访问策略:DataHub管理员可以创建policy来定义谁可以对哪些资源执行哪些操作。当您创建一个新的策略时,您将能够定义以下内容
- 策略类型—平台(顶级DataHub平台特权,即管理用户、组和策略)或元数据(操纵所有权、标记、文档等的能力)
- 资源类型——指定资源的类型,如数据集、仪表板、管道等
- 特权-选择一组权限,如编辑所有者、编辑文档、编辑链接
- 用户及/或群组-分配相关的用户及群组;您还可以将策略分配给资源所有者,而不管他们属于哪个组
- 从UI中摄取元数据:使用DataHub用户界面创建、配置、调度和执行批处理元数据摄取。通过最小化操作定制集成管道所需的开销,这使得将元数据放入DataHub变得更加容易。
- 创建用户、组和访问策略:DataHub管理员可以创建policy来定义谁可以对哪些资源执行哪些操作。当您创建一个新的策略时,您将能够定义以下内容
- 元数据管理的现代方法
- 自动元数据摄取:基于推送的摄取可以使用预构建的发射器,也可以使用我们的框架发出自定义事件。基于拉的摄取抓取元数据源。我们已经与Kafka, MySQL, MS SQL, Postgres, LDAP, Snowflake, Hive, BigQuery等进行了预构建集成。摄取可以自动使用我们的气流集成或其他调度选择。
- 发现可信数据:浏览和搜索不断更新的数据集、仪表板、图表、ML模型等目录。
- 理解数据背景:DataHub是文档、模式、所有权、沿袭、管道、数据质量、使用信息等方面的一站式商店。
- 实时治理:action框架支持以下实时用例
概念
- 通用概念
- 统一资源名称URN (Uniform Resource Name):是用来唯一定义DataHub中任何资源的URI方案。格式 urn:
: : - 策略:DataHub中的访问策略定义谁可以对哪些资源做什么。
- 角色:DataHub提供了使用角色来管理权限的功能。
- 访问令牌(个人访问令牌):个人访问令牌(Personal Access Tokens,简称pat)允许用户在代码中表示自己,并在关注安全性的部署中以编程方式使用DataHub的api。PATs与启用身份验证的元数据服务一起使用,为DataHub增加了一层保护,只有授权用户才能以自动化的方式执行操作。
- 视图:允许您保存和共享过滤器集,以便在浏览DataHub时重用。视图可以是公共的,也可以是个人的。
- 弃用:是指示实体弃用状态的方面,通常它表示为布尔值。
- 摄入来源:指的是我们从中提取元数据的数据系统。例如有BigQuery、Looker、Tableau和其他许多数据源。
- 容器:相关数据资产的容器。
- 数据平台:是包含数据集、仪表板、图表和元数据图中建模的所有其他类型数据资产的系统或工具。
- 数据集:代表了通常在数据库中以表或视图表示的数据集合(例如BigQuery, Snowflake, Redshift等),流处理环境中的流(Kafka, Pulsar等),数据湖系统(S3, ADLS等)中以文件或文件夹形式存在的数据束。
- 图表:从数据集派生的单个数据可视化。单个图表可以是多个仪表板的一部分。图表可以附带标签、所有者、链接、术语表和描述。例子包括超集或观察者图。
- 指示板:用于可视化的图表集合。仪表板可以附加标签、所有者、链接、术语表和描述。例子包括Superset或Mode Dashboard。
- 数据工作:处理数据资产的可执行作业,其中“处理”意味着使用数据、生成数据或两者兼而有之。在编排系统中,这有时被称为“DAG”中的单个“任务”。例如Airflow任务。
- 数据流:具有依赖关系的数据作业的可执行集合,或DAG。有时被称为“管道”。例如AirflowDAG。
- 术语表术语:数据生态系统中的共享词汇表。
- 术语组:类似于一个文件夹,包含术语甚至其他术语组,以允许嵌套结构。
- 标签:是非正式的,松散控制的标签,有助于搜索和发现。可以将它们添加到数据集、数据集模式或容器中,以一种简单的方式对实体进行标记或分类,而不必将它们与更广泛的业务术语表或词汇表关联。
- 域:是精心策划的顶级文件夹或类别,相关资产可以在其中显式分组。
- 所有者:是指对实体具有所有权的用户或组。例如,所有者可以访问数据集或列。
- 用户(主体):CorpUser表示企业中个人(或帐户)的身份。
- 组(CorpGroup):表示企业中一组用户的身份。
- 统一资源名称URN (Uniform Resource Name):是用来唯一定义DataHub中任何资源的URI方案。格式 urn:
- 元数据模型
- 实体:是元数据图中的主节点。例如数据集或CorpUser的实例是一个实体。
- 方面:是描述实体的特定切面的属性集合。方面可以在实体之间共享,例如,“所有权”是一个可以在所有拥有所有者的实体之间重用的方面。
- 关系:表示两个实体之间的命名边。它们是通过切面中的外键属性以及自定义注释(@Relationship)声明的。
元数据应用
元数据管理一般具备如下功能:
- 搜索和发现:数据表、字段、标签、使用信息
- 访问控制:访问控制组、用户、策略
- 数据血缘:管道执行、查询
- 合规性:数据隐私/合规性注释类型的分类
- 数据管理:数据源配置、摄取配置、保留配置、数据清除策略
- AI 可解释性、再现性:特征定义、模型定义、训练运行执行、问题陈述
- 数据操作:管道执行、处理的数据分区、数据统计
- 数据质量:数据质量规则定义、规则执行结果、数据统计
其他开源
Apache Atlas 官网地址 https://atlas.apache.org/ 最新版本2.3.0
Apache Atlas 源码地址 https://github.com/apache/atlas
Apache Atlas是一套可扩展的核心基础治理服务,使企业能够有效地满足Hadoop中的合规要求,并允许与整个企业数据生态系统集成;Apache Atlas为组织提供开放的元数据管理和治理功能,以构建数据资产的目录,对这些资产进行分类和治理,并为数据科学家、分析师和数据治理团队提供围绕这些数据资产的协作功能。有官方文档,部署比较重
Amundsen 官网地址 https://www.amundsen.io/amundsen/ 最新版本4.1.1
Amundsen 源码地址 https://github.com/amundsen-io/amundsen
Amundsen是一个开源数据发现和元数据引擎,用于提高数据分析师、数据科学家和工程师在与数据交互时的生产力。今天,它通过索引数据资源(表、仪表板、流等)和基于使用模式的页面级搜索来实现这一点(例如,查询次数多的表比查询次数少的表显示得早)。可以把它想象成谷歌数据搜索;有官方文档
Marquez 官网地址 https://marquezproject.ai/ 最新版本0.33.0
Marquez 源码地址 https://github.com/MarquezProject/marquez
Marquez是一个开源元数据服务,用于收集、聚合和可视化数据生态系统的元数据。它维护数据集如何被消费和产生的来源,提供作业运行时和数据集访问频率的全局可见性,数据集生命周期管理的集中化等;Marquez是由WeWork发布并开源的。有官方文档
Metacat 源码地址 https://github.com/Netflix/metacat 最新版本1.2.2
Metacat是一个统一的元数据探索API服务。可以探索Hive, RDS, Teradata, Redshift, S3和Cassandra。Metacat提供有哪些数据、数据位于何处以及如何处理这些数据的信息。没有官方文档,且2019年后没有发布新的release版本
架构
概览
DataHub是第三代元数据平台,支持为现代数据栈构建的数据发现、协作、治理和端到端可观察性。DataHub采用模型优先的理念,专注于解锁不同工具和系统之间的互操作性。
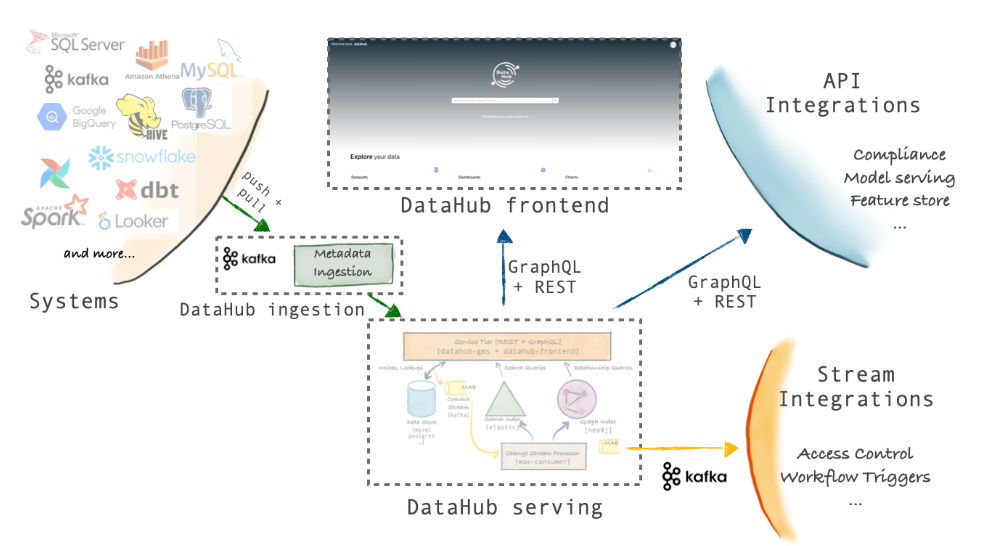
DataHub的架构有三个主要亮点
- 模式优先的元数据建模方法:DataHub的元数据模型使用与序列化无关的语言进行描述。它支持REST和GraphQL api。此外,DataHub支持基于avro的API,通过Kafka来通信和订阅元数据更改。
- 基于流的实时元数据平台:DataHub的元数据基础设施是面向流的,这使得元数据的变化可以在几秒钟内在平台内进行通信和反映。可以订阅DataHub元数据中发生的变化,从而构建实时的元数据驱动系统。例如可以构建一个访问控制系统,该系统可以通过添加包含PII的新模式字段来观察以前的世界可读数据集,并锁定该数据集以进行访问控制检查。
- 联邦元数据服务:DataHub附带了一个元数据服务(gms),作为开源存储库的一部分。然而,它也支持联合元数据服务,这些服务可以由不同的团队拥有和运营——事实上,这就是LinkedIn内部运行DataHub的方式。联邦服务使用Kafka与中央搜索索引和图形通信,以支持全局搜索和发现,同时仍然支持元数据的去耦所有权。这种架构非常适合实现数据网格的公司。
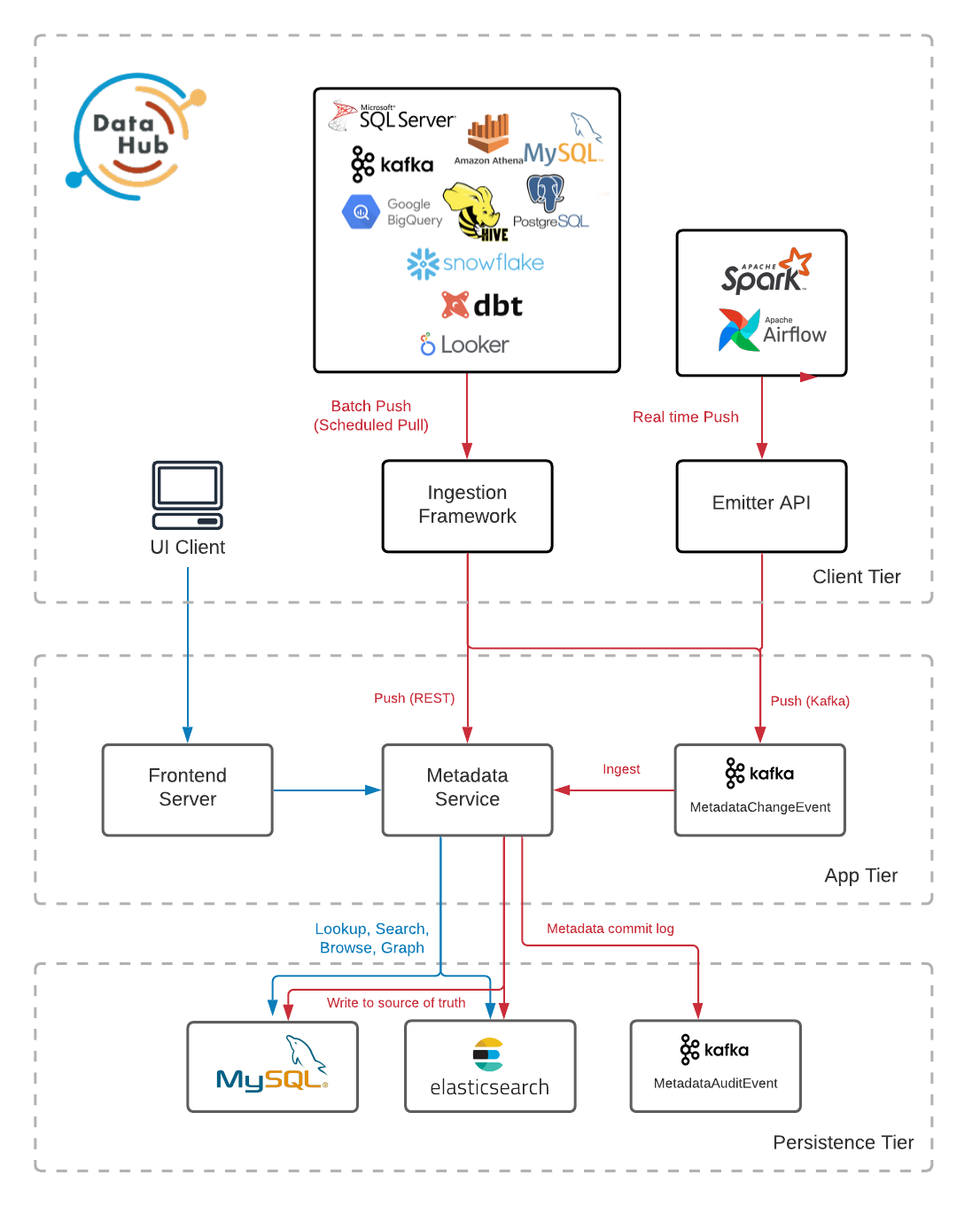
组件
DataHub平台由如下图所示的组件组成
- 元数据存储:负责存储组成元数据图的实体和方面。这包括公开用于摄取元数据、按主键获取元数据、搜索实体和获取实体之间关系的API。它由一个Spring Java Service托管一组Rest组成。li API端点,以及MySQL, Elasticsearch和Kafka用于主存储和索引。
- 元数据模型:是定义组成元数据图的实体和方面的形状以及它们之间的关系的模式。它们是使用PDL定义的,PDL是一种建模语言,在形式上与Protobuf非常相似,同时序列化为JSON。实体表示元数据资产的特定类,如数据集、仪表板、数据管道等。实体的每个实例由一个称为urn的唯一标识符标识。方面表示附加到实体实例的相关数据束,例如其描述、标记等。
- 摄入框架:是一个模块化的,可扩展的Python库,用于从外部源系统(如Snowflake, Looker, MySQL, Kafka)提取元数据,将其转换为DataHub的元数据模型,并通过Kafka或直接使用元数据存储Rest api将其写入DataHub。DataHub支持广泛的源连接器列表可供选择,以及一系列功能,包括模式提取、表和列分析、使用信息提取等。
- GraphQL API:提供了一个强类型的、面向实体的API,使得与组成元数据图的实体的交互变得简单,包括用于添加和删除标签、所有者、链接和更多元数据实体的API ,用户界面也是使用该API来实现搜索和发现、治理、可观察性等功能。
- 用户接口:DataHub带有一个React UI,其中包括一组不断发展的功能,使发现,管理和调试数据资产变得轻松愉快。
元数据摄取架构
DataHub支持极其灵活的摄取架构,可以支持推、拉、异步和同步模型。
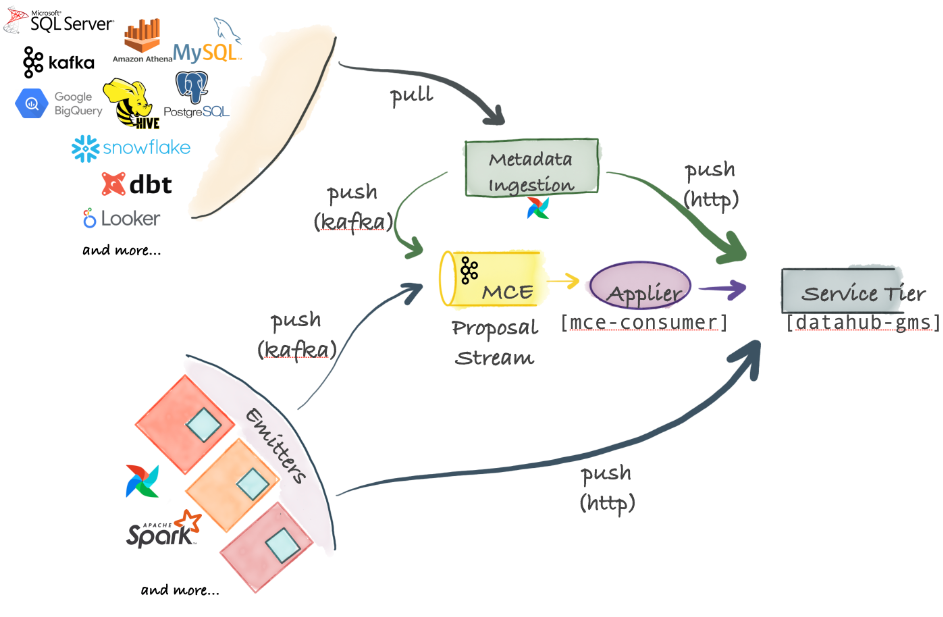
- 元数据更改建议-中心部分:摄取的中心部分是元数据更改建议,它表示对组织的元数据图进行元数据更改的请求。元数据变更建议可以通过Kafka发送,用于从源系统进行高度可扩展的异步发布。它们还可以直接发送到DataHub服务层公开的HTTP端点,以获得同步的成功/失败响应。
- 基于拉集成:DataHub附带了一个基于Python的元数据摄取系统,该系统可以连接到不同的源以从中提取元数据。这些元数据然后通过Kafka或HTTP推送到DataHub存储层。元数据摄取管道可以与AirFlow集成,以设置预定的摄取或捕获沿袭。如果找不到已经支持的源代码,那么编写自己的源代码也是非常容易的。
- 基于推集成:只要可以向Kafka发出一个元数据更改建议(Metadata Change Proposal, MCP)事件,或者通过HTTP进行一个REST调用,就可以将任何系统与DataHub集成。为方便起见,DataHub还提供了简单的Python发射器,可以将其集成到系统中,从而在源点发出元数据更改(MCP-s)。
- 内部组件:将元数据更改建议应用于DataHub元数据服务(mce-consumer-job);DataHub附带了一个Spring作业mce-consumer-job,该作业使用元数据更改建议并使用/ingest端点将其写入DataHub元数据服务(DataHub -gms)。
服务体系结构
DataHub服务层的高级系统关系图如下:
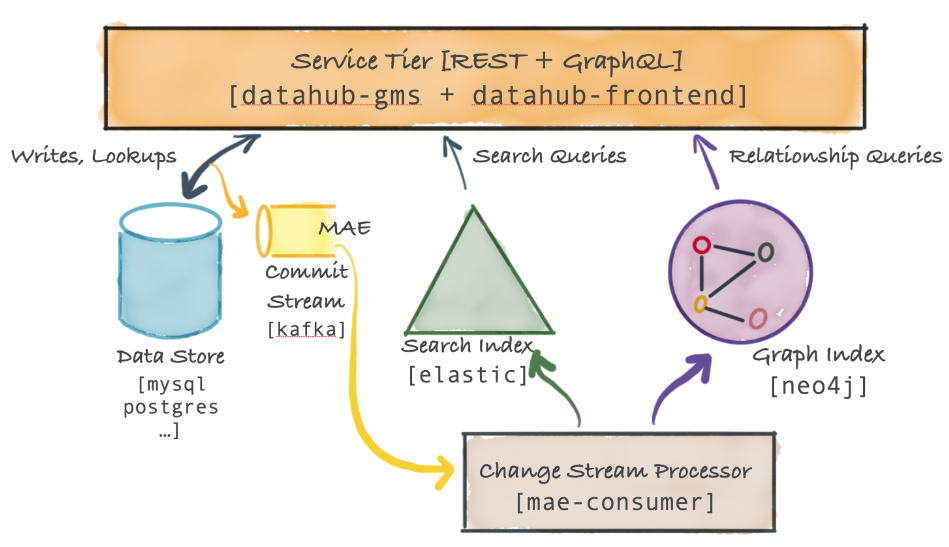
主组件称为元数据服务,它公开了一个REST API和一个GraphQL API,用于对元数据执行CRUD操作。该服务还公开了搜索和图形查询api,以支持二级索引样式的查询、全文搜索查询以及血缘等关系查询。此外数据中心前端服务在元数据图之上公开GraphQL API。DataHub服务层组件:
- 元数据存储:DataHub元数据服务将元数据保存在文档存储中(如MySQL、Postgres或Cassandra等RDBMS)。
- 元数据变更日志流(MCL):当元数据更改成功提交到持久存储时,DataHub服务层还会发出提交事件元数据更改日志。该事件通过Kafka发送。MCL流是一个公共API,可以由外部系统(例如Actions Framework)订阅,提供了一种非常强大的方式来实时响应元数据中发生的变化。例如可以构建一个访问控制强制器,对元数据的变化做出反应(例如,以前的世界可读数据集现在有一个pii字段),以立即锁定有问题的数据集。注意并非所有mcp都会导致MCL,因为DataHub服务层将忽略对元数据的任何重复更改。
- 元数据索引应用程序(mae-consumer-job):元数据更改日志由另一个Spring作业mae-consumer-job使用,该作业将相应的更改应用于图和搜索索引。该作业与实体无关,并将执行相应的图形和搜索索引构建器,当特定的元数据方面发生更改时,作业将调用该构建器。构建器应该指导作业如何根据元数据更改更新图和搜索索引。为了确保按正确的时间顺序处理元数据更改,mcl由实体URN进行键控——这意味着一个特定实体的所有mae将由单个线程依次处理。
- 元数据查询服务:基于主键的元数据读取(例如基于dataset-urn获取数据集的模式元数据)被路由到文档存储。基于二级索引对元数据的读取被路由到搜索索引(或者也可以使用这里描述的强一致性二级索引支持)。全文和高级搜索查询被路由到搜索索引。复杂的图查询(如沿袭)被路由到图索引。
本地部署
环境要求
- Docker
- Docker Compose v2
- Python 3.7+
安装
# 安装DataHub命令行
python3 -m pip install --upgrade pip wheel setuptools
python3 -m pip install --upgrade acryl-datahub
datahub version

# 本地部署DataHub实例,使用docker-compose部署一个DataHub实例
datahub docker quickstart
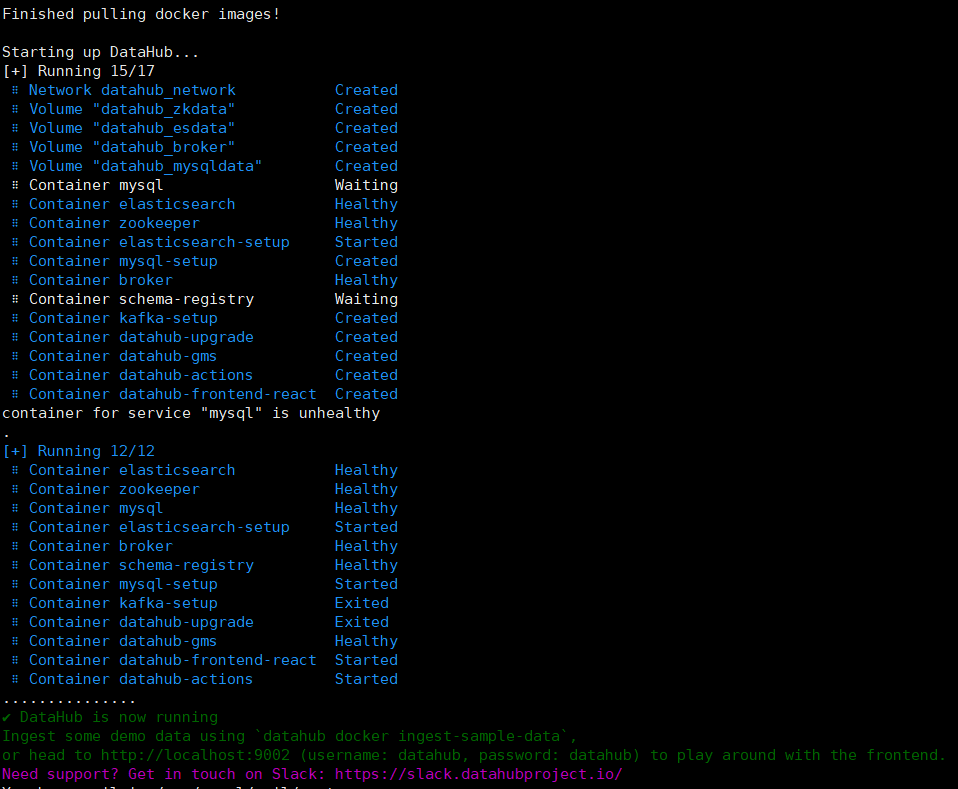
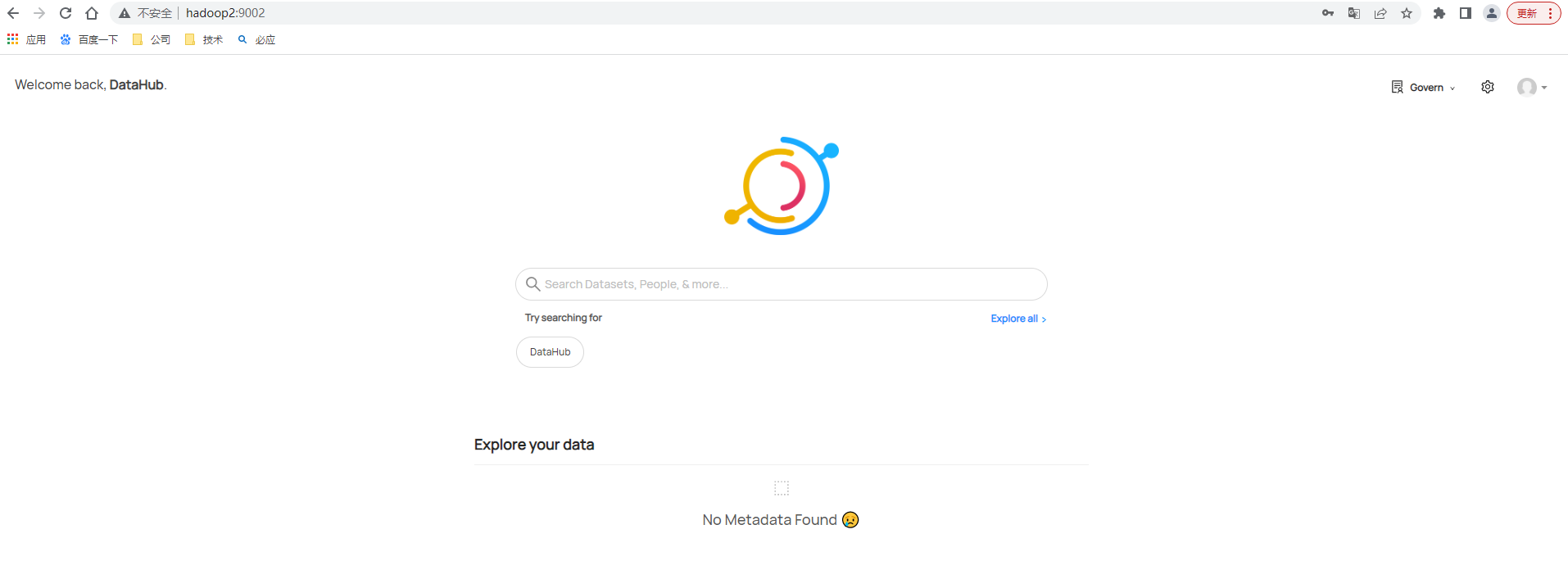
成功启动后则可以直接访问DataHub UI (http://hadoop2:9002),登录用户名和密码为datahub/datahub,登录后主页如下
# 也可以直接下载https://raw.githubusercontent.com/datahub-project/datahub/master/docker/quickstart/docker-compose-without-neo4j-m1.quickstart.yml这个文件,也可以下载指定版本的https://github.com/datahub-project/datahub/archive/refs/tags/v0.10.2.tar.gz,最后找到相应docker-compose文件然后通过docker-compose启动
docker-compose -f docker-compose-without-neo4j-m1.quickstart.yml up -d
# 如要停止DataHub的快速启动,可以发出以下命令。
datahub docker quickstart --stop
# 重置DataHub,要清除DataHub的所有状态(例如,在摄取自己的状态之前),可以使用CLI的nuke命令
datahub docker nuke
摄取样例
# 摄取样例元数据可以使用下面命令,执行命令后可以查看摄取数据
datahub docker ingest-sample-data
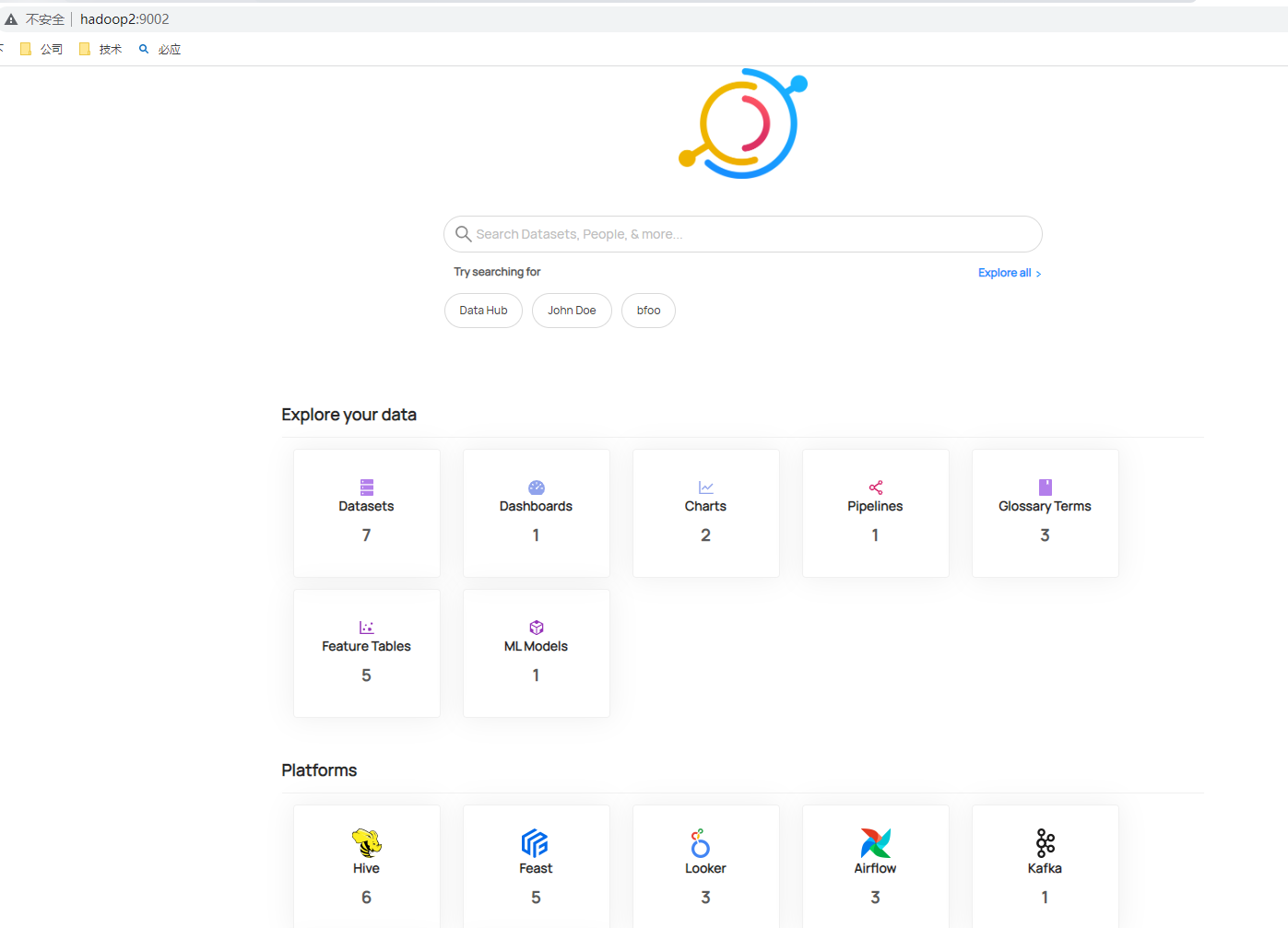
查看具体元数据信息
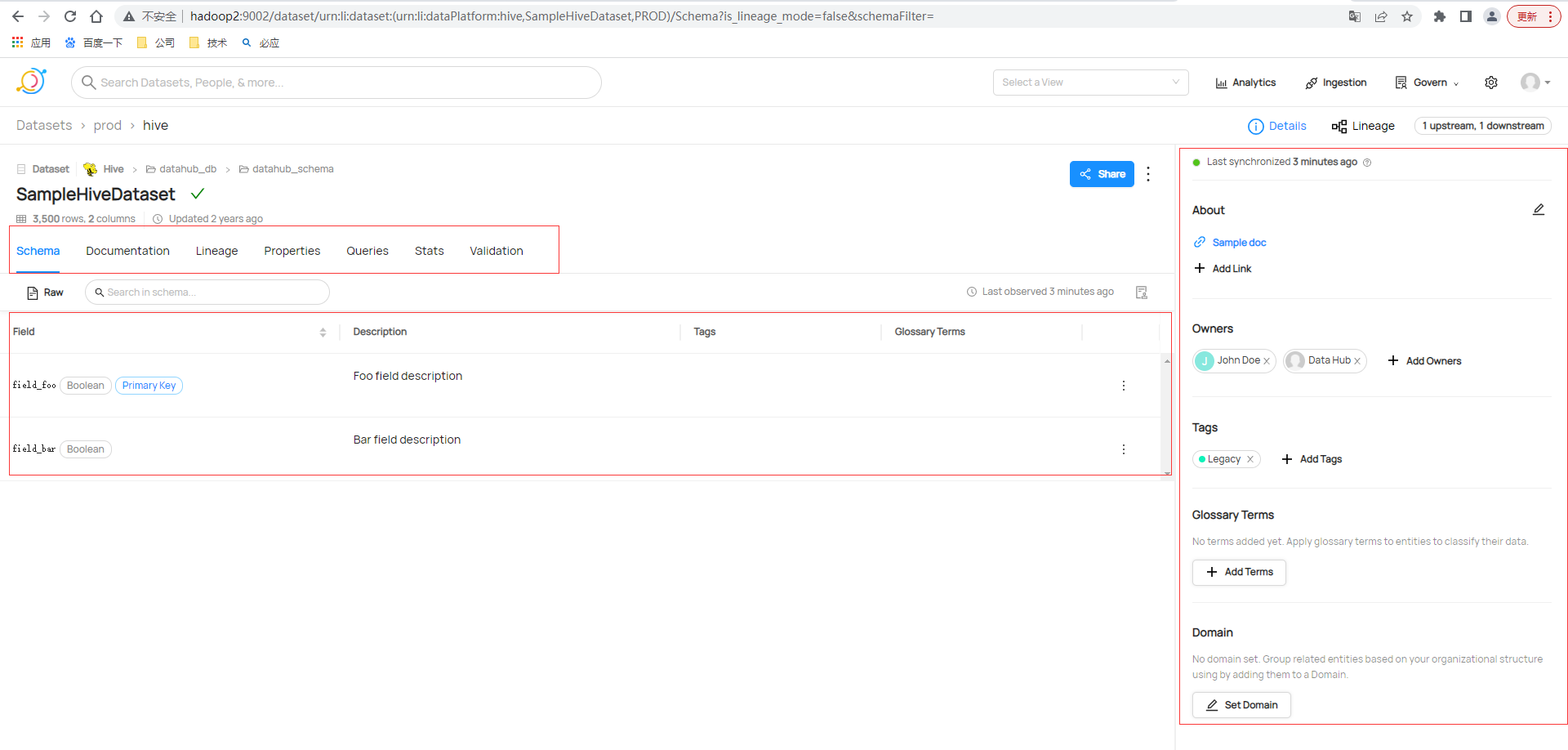
还支持查看谱系或者沿袭,也即是常说血缘关系
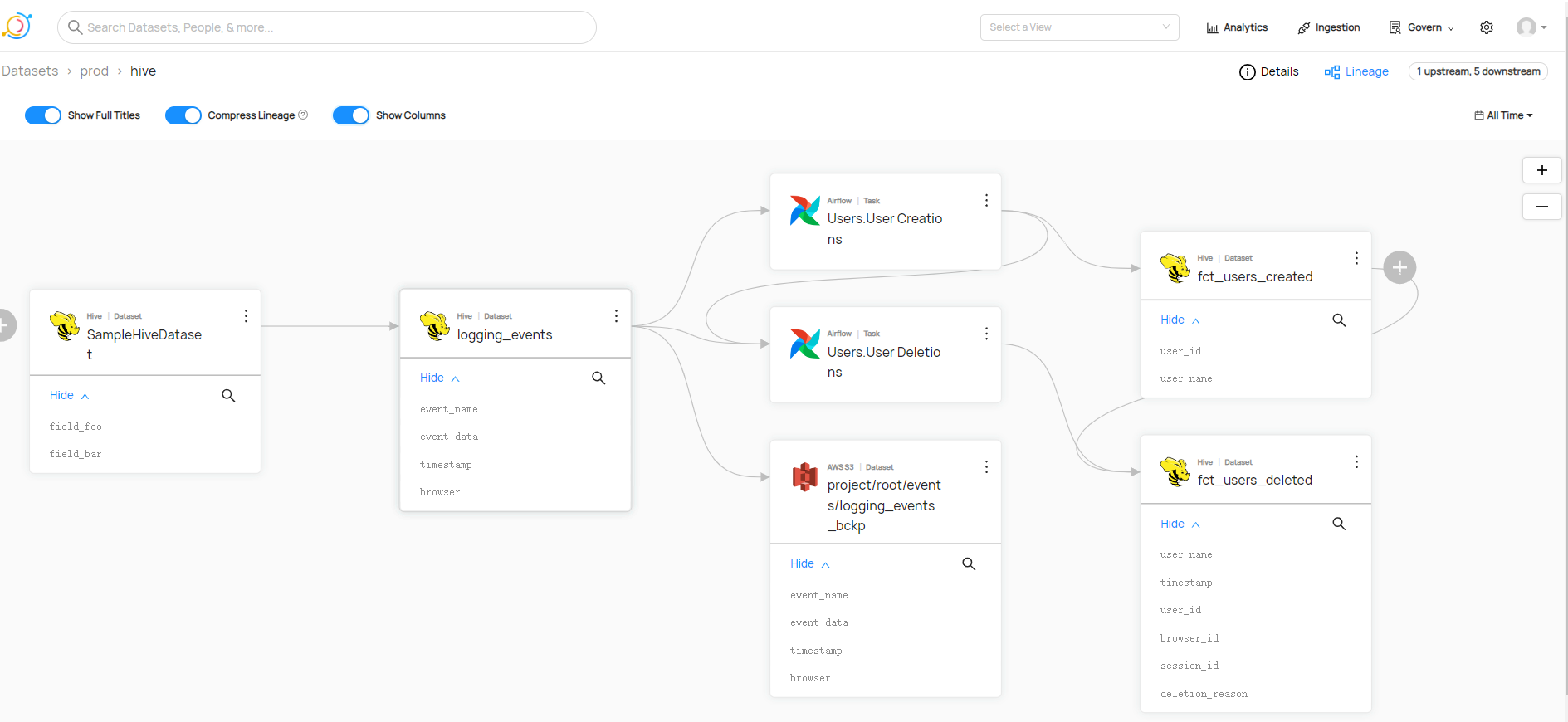
摄取入门
介绍
DataHub支持基于推和基于拉的元数据集成。
- 基于推送的集成允许在元数据更改时直接从数据系统发出元数据,而基于拉的集成允许通过连接到数据系统并以批处理或增量批处理的方式提取元数据,从而从数据系统“抓取”或“摄取”元数据。支持这两种机制意味着可以以最灵活的方式与所有系统集成。
- 内置在DataHub中的基于拉的元数据摄取系统,该系统可以轻松地与数据堆栈中的各种数据源集成。
核心概念
-
数据源:从中提取元数据的数据系统称为数据源。摄取元数据的所有源例如BigQuery、Looker、Tableau等其他许多数据源,目前官方上有55个。
-
接收器:是元数据的目的地。在为DataHub配置摄取时,可能会通过REST (DataHub -sink)或Kafka (DataHub - Kafka)接收器将元数据发送到DataHub。在某些情况下,文件接收器还有助于在调试期间存储元数据的持久脱机副本。大多数摄取系统和指南假设的默认接收器是数据中心休息接收器,但是您也应该能够为其他接收器调整所有接收器!
-
食谱:配方是将所有这些组合在一起的主要配置文件。它告诉我们的摄取脚本从哪里提取数据(源),在哪里放置数据(接收)。
-
处理食谱中的敏感信息:自动扩展配置中的环境变量(例如${MSSQL_PASSWORD}),类似于GNU bash或docker-compose文件中的变量替换。应该使用这种环境变量替换来掩盖配方文件中的敏感信息。只要您可以安全地将环境变量获取到摄取过程中,就不需要在配方中存储敏感信息。
-
转换:如果希望在数据到达摄取接收器之前对其进行修改——例如添加额外的所有者或标记——可以使用转换器编写自己的模块,并将其与DataHub集成。
命令行MySQL摄取示例
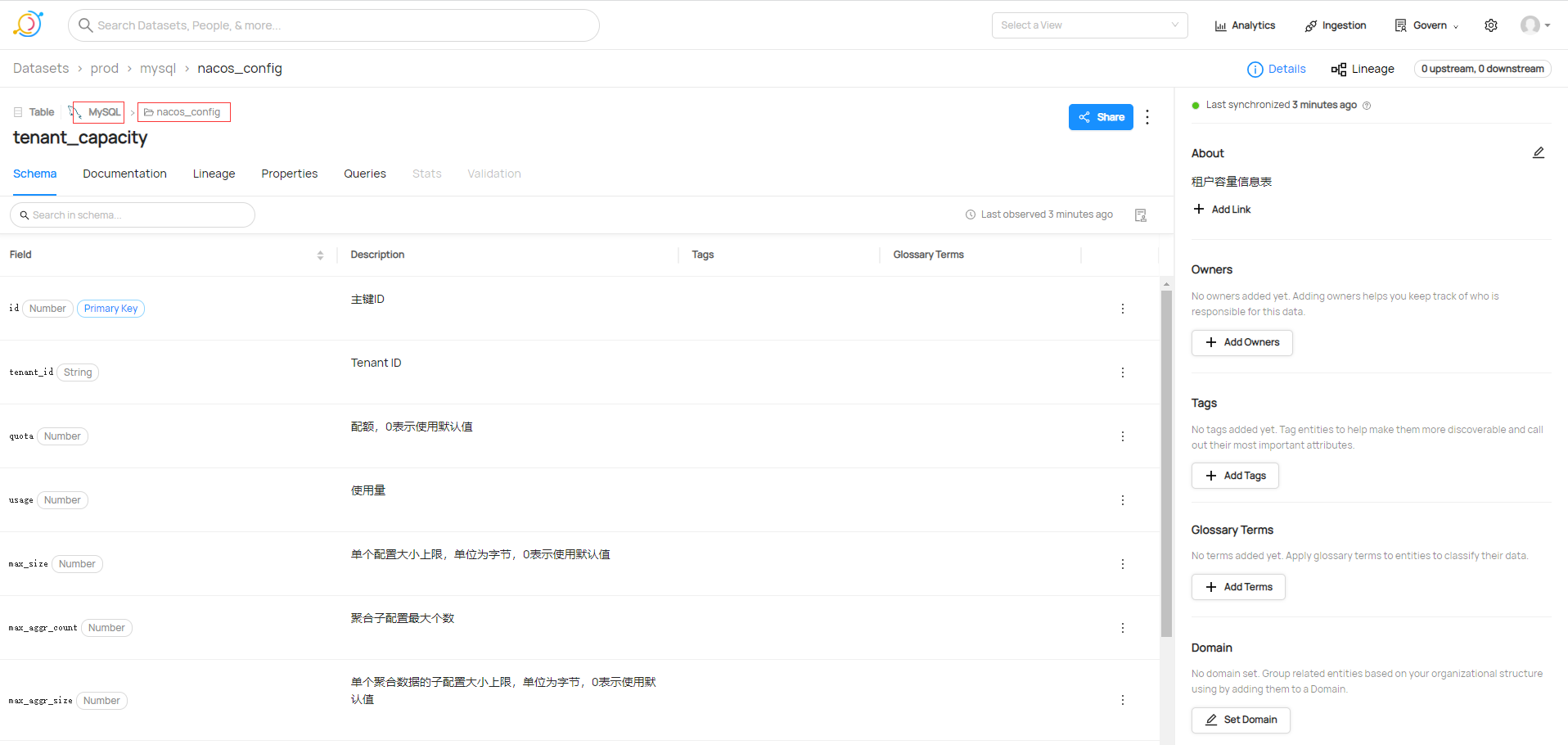
在获取数据源的时候,只需要编写简单的yml文件就可以完成元数据的获取。这里采集MySQL数据库名为nacos_config

先检查是否有datahub的mysql和datahub-rest插件
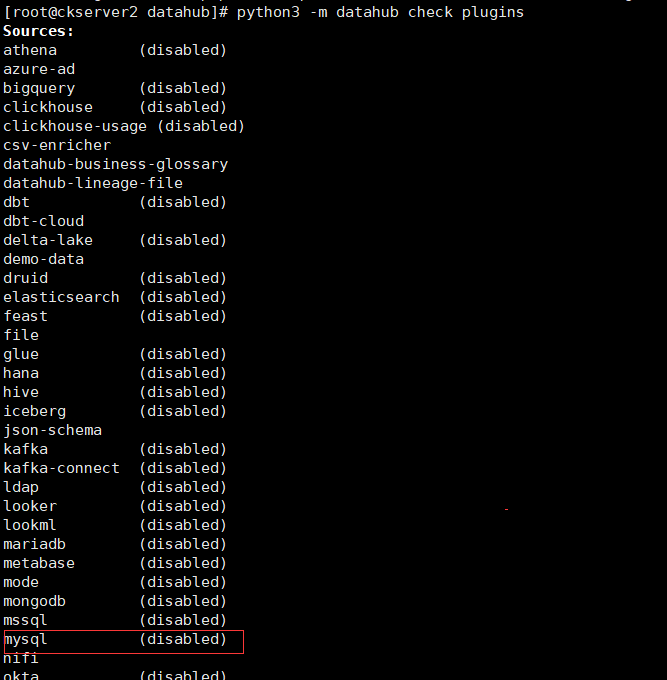
# 安装datahub mysql插件
pip install 'acryl-datahub[mysql]'
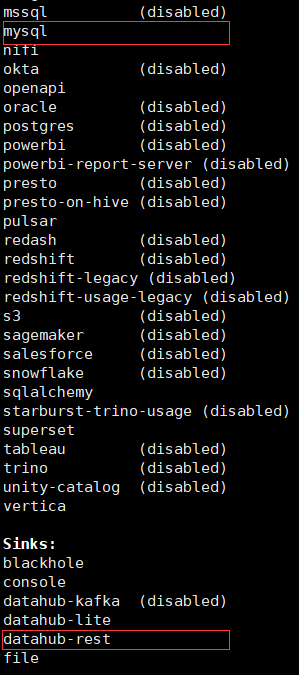
# 查看datahub 插件列表
python3 -m datahub check plugins
编写摄取文件,vim mysql_to_datahub_rest.yml
source:
type: mysql
config:
# Coordinates
host_port: mysqlserver8:3306
database: nacos_config
# Credentials
username: root
password: 123456
sink:
type: "datahub-rest"
config:
server: "http://localhost:8080"
通过命令执行摄取
datahub ingest -c mysql_to_datahub_rest.yml
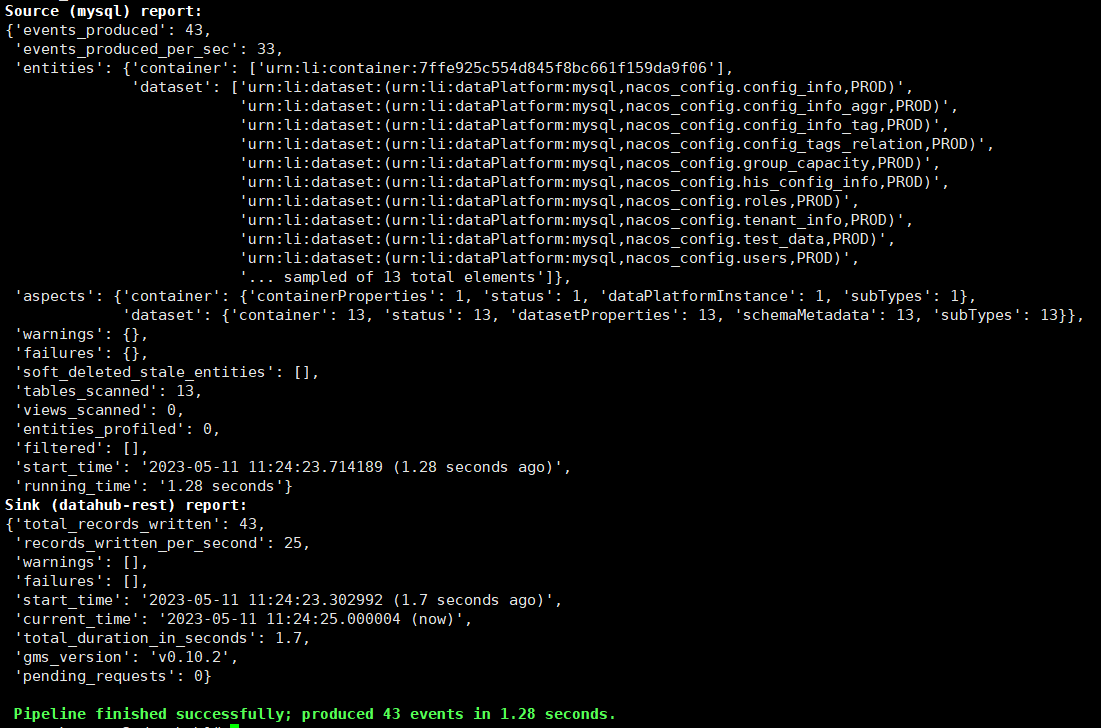
通过UI页面也可以查看摄取记录
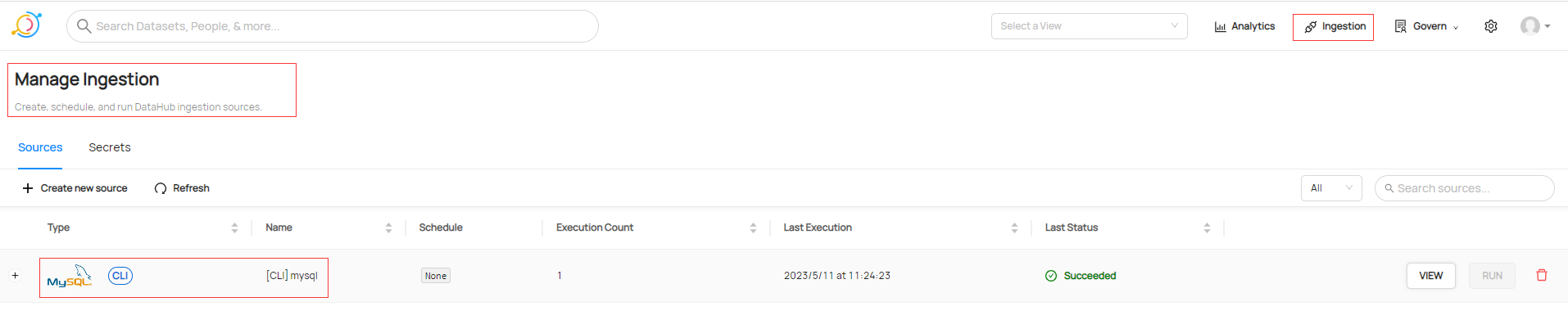
查看刚刚添加数据库集
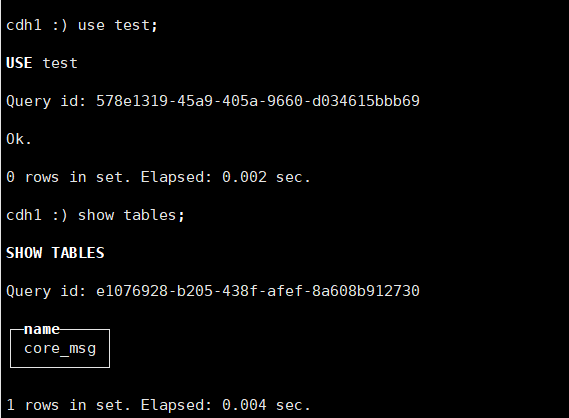
配置ClickHouse摄取示例
这里建立ClickHouse的测试数据库名为test
# 安装clickhouse驱动
pip install 'acryl-datahub[clickhouse]'
编写摄取文件,vim clickhouse_to_datahub_rest.yml
source:
type: clickhouse
config:
host_port: clickhouse-server:8123
protocol: http
# Credentials
username: default
password: 123456
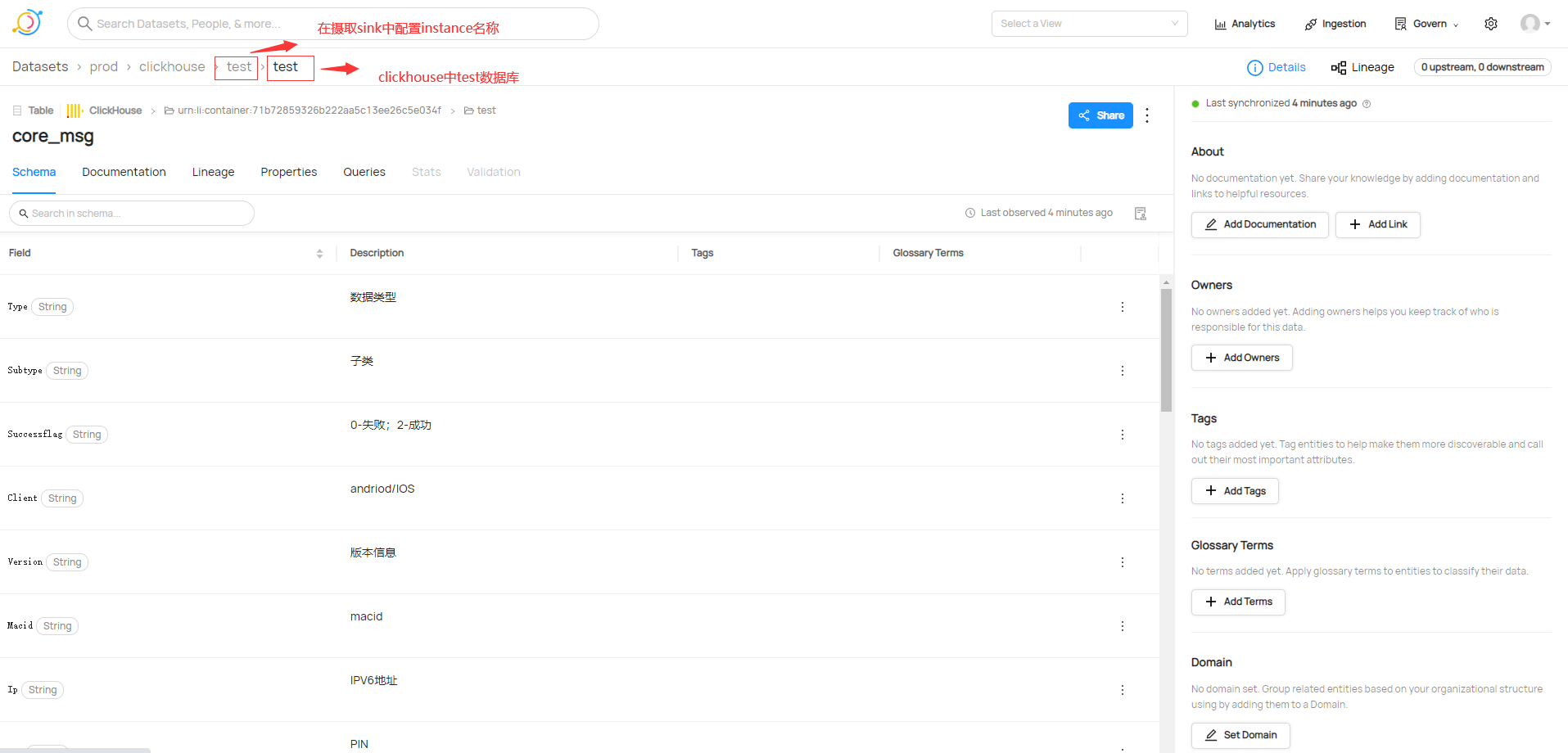
# Options,在datahub UI采集元数据显示的名称
platform_instance: test
include_views: True # whether to include views, defaults to True
include_tables: True # whether to include views, defaults to True
sink:
type: "datahub-rest"
config:
server: "http://localhost:8080"
通过命令执行摄取
datahub ingest -c clickhouse_to_datahub_rest.yml
- 本人博客网站IT小神 www.itxiaoshen.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号