
Python数据类型
一.数字类型
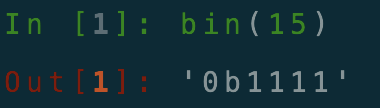
1.bin()函数将十进制转换为二进制
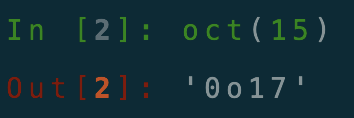
2.oct()函数将十进制转换为八进制
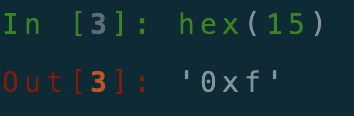
3.hex()函数将十进制转换成十六进制
4.数字类型的特性:
1)只能存放一个值
2)一经定义,不可更改
3)直接访问
分类:整型,布尔,浮点,复数
二.字符串类型
1.引号包含的都是字符串类型
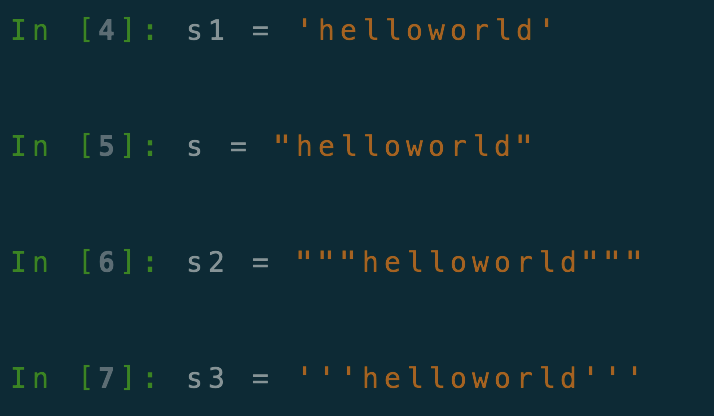
2.单引双引没有区别

3.字符串的常用操作:
1 # name='egon' #name=str('egon') 2 # print(type(name)) 3 4 5 #优先掌握 6 #1.移除空白strip 7 # msg=' hello ' 8 # print(msg) 9 # print(msg.strip()) 10 # 移除‘*’ 11 # msg='***hello*********' 12 # msg=msg.strip('*') 13 # print(msg) 14 #移除左边的 15 # print(msg.lstrip('*')) 16 #移除右边的 17 # print(msg.rstrip('*')) 18 19 #用处 20 while True: 21 name=input('user: ').strip() 22 password=input('password: ').strip() 23 if name == 'egon' and password == '123': 24 print('login successfull') 25 26 27 28 #切分split 29 # info='root:x:0:0::/root:/bin/bash' 30 # print(info[0]+info[1]+info[2]+info[3]) 31 32 # user_l=info.split(':') 33 # print(user_l[0]) 34 35 # msg='hello world egon say hahah' 36 # print(msg.split()) #默认以空格作为分隔符 37 38 #cmd='download|xhp.mov|3000' 39 # cmd_l=cmd.split('|') 40 # print(cmd_l[1]) 41 # print(cmd_l[0]) 42 # print(cmd.split('|',1)) 43 44 #用处 45 while True: 46 cmd=input('>>: ').strip() 47 if len(cmd) == 0:continue 48 cmd_l=cmd.split() 49 print('命令是:%s 命令的参数是:%s' %(cmd_l[0],cmd_l[1])) 50 51 52 53 54 55 #长度len 56 # print(len('hell 123')) 57 58 59 #索引 60 # 切片:切出子字符串 61 # msg='hello world' 62 # print(msg[1:3]) #1 2 63 # print(msg[1:4]) #1 2 3 64 65 66 67 # 掌握部分 68 oldboy_age=84 69 while True: 70 age=input('>>: ').strip() 71 if len(age) == 0: 72 continue 73 if age.isdigit(): 74 age=int(age) 75 else: 76 print('must be int') 77 78 79 80 81 82 #startswith,endswith 83 # name='alex_SB' 84 # print(name.endswith('SB')) 85 # print(name.startswith('alex')) 86 87 88 #replace 89 # name='alex say :i have one tesla,my name is alex' 90 # print(name.replace('alex','SB',1)) 91 92 # print('my name is %s my age is %s my sex is %s' %('egon',18,'male')) 93 # print('my name is {} my age is {} my sex is {}'.format('egon',18,'male')) 94 # print('my name is {0} my age is {1} my sex is {0}: 95 {2}'.format('egon',18,'male')) 96 # print('my name is {name} my age is {age} my sex is {sex}'.format( 97 # sex='male', 98 # age=18, 99 # name='egon')) 100 101 102 # name='goee say hello' 103 # # print(name.find('S',1,3)) #顾头不顾尾,找不到则返回-1不会报错,找到了则显示索引 104 # # print(name.index('S')) #同上,但是找不到会报错 105 # 106 # print(name.count('S',1,5)) #顾头不顾尾,如果不指定范围则查找所有 107 108 109 #join 110 # info='root:x:0:0::/root:/bin/bash' 111 # print(info.split(':')) 112 113 # l=['root', 'x', '0', '0', '', '/root', '/bin/bash'] 114 # print(':'.join(l)) 115 116 117 #lower,upper 118 # name='eGon' 119 # print(name.lower()) 120 # print(name.upper()) 121 122 123 #了解部分 124 #expandtabs 125 # name='egon\thello' 126 # print(name) 127 # print(name.expandtabs(1)) 128 129 130 #center,ljust,rjust,zfill 131 # name='egon' 132 # # print(name.center(30,'-')) 133 # print(name.ljust(30,'*')) 134 # print(name.rjust(30,'*')) 135 # print(name.zfill(50)) #用0填充 136 137 138 #captalize,swapcase,title 139 # name='eGon' 140 # print(name.capitalize()) #首字母大写,其余部分小写 141 # print(name.swapcase()) #大小写翻转 142 # msg='egon say hi' 143 # print(msg.title()) #每个单词的首字母大写 144 145 146 #在python3中 147 num0='4' 148 num1=b'4' #bytes 149 num2=u'4' #unicode,python3中无需加u就是unicode 150 num3='四' #中文数字 151 num4='Ⅳ' #罗马数字 152 153 154 #isdigt:str,bytes,unicode 155 # print(num0.isdigit()) 156 # print(num1.isdigit()) 157 # print(num2.isdigit()) 158 # print(num3.isdigit()) 159 # print(num4.isdigit()) 160 161 #isdecimal:str,unicode 162 # num0='4' 163 # num1=b'4' #bytes 164 # num2=u'4' #unicode,python3中无需加u就是unicode 165 # num3='四' #中文数字 166 # num4='Ⅳ' #罗马数字 167 # print(num0.isdecimal()) 168 # # print(num1.) 169 # print(num2.isdecimal()) 170 # print(num3.isdecimal()) 171 # print(num4.isdecimal()) 172 173 #isnumeric:str,unicode,中文,罗马 174 # num0='4' 175 # num1=b'4' #bytes 176 # num2=u'4' #unicode,python3中无需加u就是unicode 177 # num3='四' #中文数字 178 # num4='Ⅳ' #罗马数字 179 # 180 # print(num0.isnumeric()) 181 # # print(num1) 182 # print(num2.isnumeric()) 183 # print(num3.isnumeric()) 184 # print(num4.isnumeric()) 185 186 187 188 189 #is其他 190 # name='egon123' 191 # print(name.isalnum()) #字符串由字母和数字组成 192 # name='asdfasdfa sdf' 193 # print(name.isalpha()) #字符串只由字母组成 194 # 195 196 # name='asdfor123' 197 # print(name.isidentifier()) 198 name='egGon' 199 print(name.islower()) 200 # print(name.isupper()) 201 # print(name.isspace()) 202 name='Egon say' 203 print(name.istitle()) 204 205
strip()移除空白,也可以去除其他的字符
slipt()分割,默认以空格分割。也可以以其他的字符分割
len()长度 切片:如print(x[1:3])也是顾头不顾尾
print(x[0:5:2])#0 2 4
capitalize()首字母大写
center()居中显示例如:x='hello' print(x.center(30,'#'))
count():计数,顾头不顾尾,统计某个字符的个数,空格也算一个字符
endswith()以什么结尾
satrtswith()以什么开头
find()查找字符的索引位置,如果是负数,代表查找失败
index()索引
format()字符串格式化
1.msg='name:{},age:{},sex:{}'
print(msg.format('lin',18,'男'))
2.msg='name:{0},age:{1},sex:{0}'
print(msg.format('aaaaaa','bbbbbb'))
3.msg='name:{x},age:{y},sex:{z}'
print(msg.format(x='lin',y='18',z='男'))
isdigit()判断是否是数字
islower()判断是否是全部小写
isupper()判断是否是全部大写
lower()全部转换为小写
upper()全部转换为大写
isspace()判断是否是全都是空格
istitle()判断是否是标题(首字母大写)
swapcase()大小写字母翻转
join()连接
repalce()替换
msg='hello alex'
print(msg.replace('e'),'A',1)
print(msg.replace('e'),'A',2)
ljust()左对齐
X='ABC' print(x.ljust(10,'*'))
4.字符串格式化说明
%s既能接受字符串,也能接受数字
%d只能接受数字
5.字符串的切片
切片操作(slice)可以从一个字符串中获取子字符串(字符串的一部分)。我们使用一对方括号、起始偏移量start、终止偏移量end 以及可选的步长step 来定义一个分片。
格式: [start:end:step]
- [:] 提取从开头(默认位置0)到结尾(默认位置-1)的整个字符串
- [start:] 从start 提取到结尾
- [:end] 从开头提取到end - 1
- [start:end] 从start 提取到end - 1
- [start:end:step] 从start 提取到end - 1,每step 个字符提取一个
- 左侧第一个字符的位置/偏移量为0,右侧最后一个字符的位置/偏移量为-1
举例:
输入一个字符串,返回倒序排序的结果,:如:‘abcdef’ 返回:'fedcba'
1 #方式一:将字符串翻转,步长设为-1 2 def re_sort(): 3 s = input('请输入一串字符串:>>') 4 return s[::-1] #从开头到结尾步长为-1 5 # obj = re_sort() 6 # print(obj) 7 8 #方式二:借助列表进行翻转 9 def re_sort2(): 10 s = input('请输入一串字符串:>>') 11 li = [] 12 for i in s: 13 li.append(i) 14 li.reverse() #将列表反转 15 return ''.join(li) #将列表转化成字符串 16 obj2 = re_sort2() 17 print(obj2)
三.列表
1 l=[1,2,3] #l=list([1,2,3]) 2 # print(type(l)) 3 4 #pat1===》优先掌握部分 5 # 索引:l=[1,2,3,4,5] 6 print(l[0]) 7 # 切片 7 l=['a','b','c','d','e','f'] 8 9 # print(l[1:5]) 10 # print(l[1:5:2]) 11 # print(l[2:5]) 12 # print(l[-1]) 13 14 15 #了解 16 # print(l[-1:-4]) 17 # print(l[-4:]) 18 # l=['a','b','c','d','e','f'] 19 # print(l[-2:]) 20 21 # 追加 22 # hobbies=['play','eat','sleep','study'] 23 # hobbies.append('girls') 24 # print(hobbies) 25 26 # 删除 27 hobbies=['play','eat','sleep','study'] 28 # x=hobbies.pop(1) #不是单纯的删除,是删除并且把删除的元素返回,我们可以用一个变量名去接收该返回值 29 # print(x) 30 # print(hobbies) 31 32 # x=hobbies.pop(0) 33 # print(x) 34 # 35 # x=hobbies.pop(0) 36 # print(x) 37 38 #队列:先进先出 39 queue_l=[] 40 #入队 41 # queue_l.append('first') 42 # queue_l.append('second') 43 # queue_l.append('third') 44 # print(queue_l) 45 #出队 46 # print(queue_l.pop(0)) 47 # print(queue_l.pop(0)) 48 # print(queue_l.pop(0)) 49 50 51 #堆栈:先进后出,后进先出 52 # l=[] 53 # #入栈 54 # l.append('first') 55 # l.append('second') 56 # l.append('third') 57 # #出栈 58 # print(l) 59 # print(l.pop()) 60 # print(l.pop()) 61 # print(l.pop()) 62 63 #了解 64 # del hobbies[1] #单纯的删除 65 # hobbies.remove('eat') #单纯的删除,并且是指定元素去删除 66 67 68 # 长度 69 # hobbies=['play','eat','sleep','study'] 70 # print(len(hobbies)) 71 72 # 包含in 73 # hobbies=['play','eat','sleep','study'] 74 # print('sleep' in hobbies) 75 76 # msg='hello world egon' 77 # print('egon' in msg) 78 79 80 ##pat2===》掌握部分 81 hobbies=['play','eat','sleep','study','eat','eat'] 82 # hobbies.insert(1,'walk') 83 # hobbies.insert(1,['walk1','walk2','walk3']) 84 # print(hobbies) 85 86 # print(hobbies.count('eat')) 87 # print(hobbies) 88 # hobbies.extend(['walk1','walk2','walk3']) 89 # print(hobbies) 90 91 hobbies=['play','eat','sleep','study','eat','eat'] 92 # print(hobbies.index('eat')) 93 94 95 #pat3===》了解部分 96 hobbies=['play','eat','sleep','study','eat','eat'] 97 # hobbies.clear() 98 # print(hobbies) 99 100 # l=hobbies.copy() 101 # print(l) 102 103 # l=[1,2,3,4,5] 104 # l.reverse() 105 # print(l) 106 107 l=[100,9,-2,11,32] 108 l.sort(reverse=True) 109 print(l)
四.元祖
1 #为何要有元组,存放多个值,元组不可变,更多的是用来做查询 2 t=(1,[1,3],'sss',(1,2)) #t=tuple((1,[1,3],'sss',(1,2))) 3 # print(type(t)) 4 5 6 # #元组可以作为字典的key 7 # d={(1,2,3):'egon'} 8 # print(d,type(d),d[(1,2,3)]) 9 10 11 12 13 # 切片 14 # goods=('iphone','lenovo','sanxing','suoyi') 15 # print(goods[1:3]) 16 17 18 19 # 长度 20 21 #in: 22 #字符串:子字符串 23 #列表:元素 24 #元组:元素 25 #字典:key 26 27 # goods=('iphone','lenovo','sanxing','suoyi') 28 # print('iphone' in goods)看的是里面的元素在不在里面 29 30 # d={'a':1,'b':2,'c':3} 31 # print('b' in d) 看的是key在不在d里面 32 33 34 35 #掌握 36 # goods=('iphone','lenovo','sanxing','suoyi') 37 # print(goods.index('iphone')) 38 # print(goods.count('iphone')) 39 40 41 #补充:元组本身是不可变的,但是内部的元素可以是可变类型 42 t=(1,['a','b'],'sss',(1,2)) #t=tuple((1,[1,3],'sss',(1,2))) 43 44 # t[1][0]='A' 45 # print(t) 46 # t[1]='aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa'
五.字典
1 # 字典的表示方法: 2 info_dic={'name':'lin','age':18,'sex':'male'} 3 # 常用操作: 4 # 5 1.存/取 6 info_dic={'name':'egon','age':18,'sex':'male'} 7 print(info_dic['name11111111'])#找不到则报错了 8 print(info_dic.get('name',None)) 9 print(info_dic.get('name222222',None))#get方法找不到不报错,可以自己设定默认值 10 11 #pop:key存在则弹出值,不存在则返回默认值,如果没有默认值则报错 12 # print(info_dic.pop('nam123123123123123123e',None)) 13 # print(info_dic) 14 15 # print(info_dic.popitem()) 16 # print(info_dic) 17 18 # info_dic['level']=10 19 # print(info_dic) 20 21 # 22 # 删除 23 info_dic={'name':'egon','age':18,'sex':'male'} 24 # info_dic.pop() 25 # info_dic.popitem() 26 27 # del info_dic['name'] 28 29 30 # 31 # 键s,值s,键值对 32 info_dic={'name':'egon','age':18,'sex':'male'} 33 # print(info_dic.keys()) 34 # print(info_dic.values()) 35 # print(info_dic.items()) 36 37 # for k in info_dic: 38 # # print(k,info_dic[k]) 39 # print(k) 40 41 # print('========>') 42 # for k in info_dic.keys(): 43 # print(k) 44 45 # for val in info_dic.values(): 46 # print(val) 47 48 # for k,v in info_dic.items(): #k,v=('name', 'egon') 49 # print(k,v) 50 51 52 53 # 长度 54 # info_dic={'name':'egon','age':18,'sex':'male'} 55 # print(len(info_dic)) 56 # 57 # 循环 58 # 59 # 包含in 60 61 # info_dic={'name':'egon','age':18,'sex':'male'} 62 # print('name' in info_dic) 63 # print('name' in info_dic.keys()) 64 # print('egon' in info_dic.values()) 65 # print(('name','egon') in info_dic.items()) 66 67 68 69 #掌握 70 info_dic={'name':'egon','age':18,'sex':'male'} 71 # info_dic.update({'a':1,'name':'Egon'}) 72 # print(info_dic) 73 74 # info_dic['hobbies']=[] 75 # info_dic['hobbies'].append('study') 76 # info_dic['hobbies'].append('read') 77 # print(info_dic) 78 79 #setdefault:key不存在则设置默认值,并且放回值默认值 80 #key存在则不设置默认,并且返回已经有的值 81 82 # info_dic.setdefault('hobbies',[1,2]) 83 # print(info_dic) 84 # info_dic.setdefault('hobbies',[1,2,3,4,5]) 85 # print(info_dic) 86 87 # info_dic={'name':'haiyan','age':18,'sex':'male'} 88 89 # {'name':'egon','age':18,'sex':'male','hobbies':['study']} 90 # info_dic.setdefault('hobbies',[]).append('study') 91 92 # {'name':'egon','age':18,'sex':'male','hobbies':['study','read']} 93 # info_dic.setdefault('hobbies',[]).append('read') 94 95 # {'name':'egon','age':18,'sex':'male','hobbies':['study','read','sleep']} 96 # info_dic.setdefault('hobbies',[]).append('sleep') 97 # l=info_dic.setdefault('hobbies',[]) 98 # print(l,id(l)) 99 # print(id(info_dic['hobbies'])) 100 101 # print(info_dic) 102 103 104 105 #了解 106 # d=info_dic.copy() 107 # print(d) 108 # info_dic.clear() 109 # print(info_dic) 110 111 112 # d=info_dic.fromkeys(('name','age','sex'),None) 113 # print(d) 114 # d1=dict.fromkeys(('name','age','sex'),None) 115 # d2=dict.fromkeys(('name','age','sex'),('egon',18,'male')) 116 # print(d1) 117 # print(d2) 118 119 120 121 122 # info=dict(name='haiyan',age=18,sex='male') 123 # print(info) 124 125 # 126 # info=dict([('name','haiyan'),('age',18)]) 127 # print(info)
六.集合
作用:去重,关系运算
定义:可以包含多个元素,用逗号分割,集合的元素遵循三个原则:
1.每个元素必须是不可变类型(可hash,可作为字典的key)
2.没有重复的元素
3.无序
注意集合的目的是将不同的值存放在一起,不同的集合间用来做关系运算,无需纠结集合中的单个值

in 和 not in
|并集(print(pythons.union(linuxs)))
&交集(print(pythons.intersection(linuxs)))
-差集(print(pythons.difference(linuxs)))
^对称差集(print(pythons.symmetric_difference(linuxs)))
==
>,>= ,<,<= 父集(issuperset),子集(issuberset)
1 # ========掌握部分======= 2 linuxs={'six','wu','dabao'} 3 linuxs.add('xiaoxiao')#说明set类型的集合是可变类型 4 linuxs.add([1,2,3])#报错,只能添加不可变类型 5 print(linuxs) 6 7 # 2. 8 linuxs={'six','wu','dabao'} 9 res=linuxs.pop() #不用指定参数,随机删除,并且会有返回值 10 print(res) 11 # 3. 12 res=linuxs.remove('wupeiqi')#指定元素删除,元素不存在则报错,单纯的删除,没有返回值, 13 print(res) 14 # 4. 15 res=linuxs.discard('egon1111111111') #指定元素删除,元素不存在不报错,单纯的删除,没有返回值, 16 # =========了解部分========= 17 linuxs={'wupeiqi','egon','susan','hiayan'} 18 new_set={'xxx','fenxixi'} 19 linuxs.update(new_set) 20 print(linuxs) 21 linuxs.copy() 22 linuxs.clear() 23 24 25 26 #解压 27 28 a,*_={'zzz','sss','xxxx','cccc','vvv','qqq'} 29 print(a)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号