BeautifulSoup用法详解
安装bs4
pip install bs4
BeautifulSoup
- 灵活又方便的网页解析库,处理高效,支持多种解析器。
- 利用它不用编写正则表达式即可方便地实现网页信息的提取。
BeautifulSoup解析库
| 解析器 | 使用方法 | 优势 | 劣势 |
|---|---|---|---|
| Python标准库 | BeautifulSoup(markup,"html.parser") | Python的内置标准库、执行速度适中、文档容错能力强 | Python2.7.3 or 3.2.2 前的版本中文容错能力差 |
| lxml HTML 解析器 | BeautifulSoup(markup,"lxml") | 速度快、文档容错能力强 | 需要安装C语言库 |
| lxml XML 解析器 | BeautifulSoup(markup,"xml") | 速度快、唯一支持XML的解析器需 | 要安装C语言库 |
| html5lib | BeautifulSoup(markup,"html5lib") | 最好的容错性、以浏览器的方式解析文档、生成HTML5格式的文档 | 速度慢、不依赖外部扩展 |
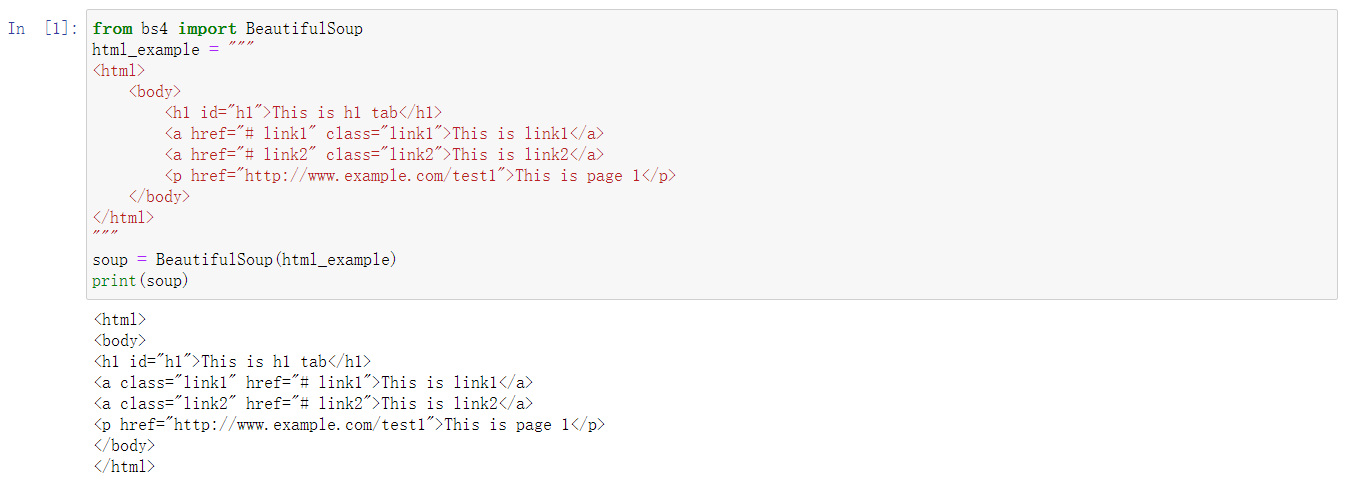
打印页面信息
常用的三种选择器(标签选择器、标准选择器、CSS选择器)
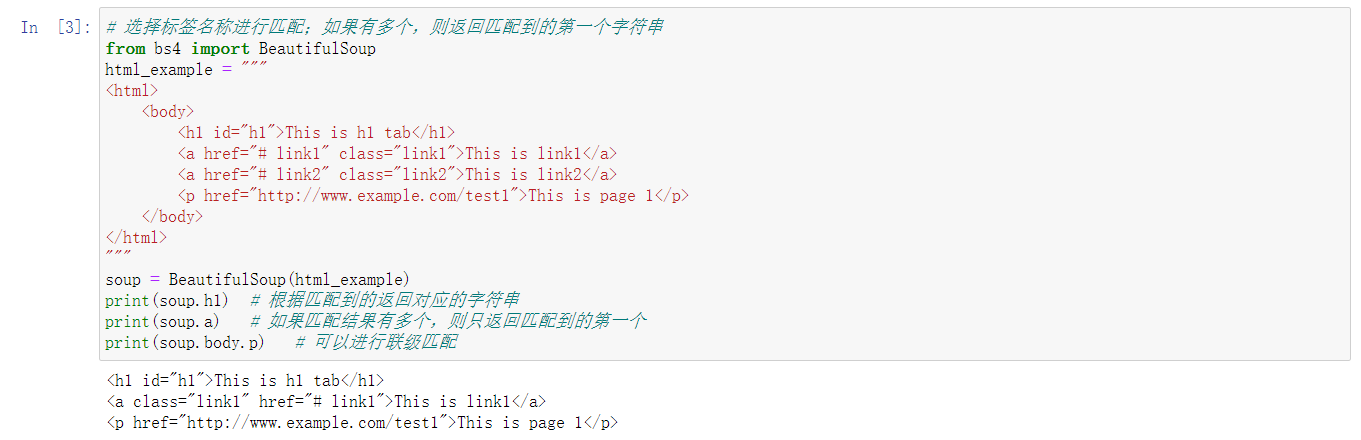
1、标签选择器
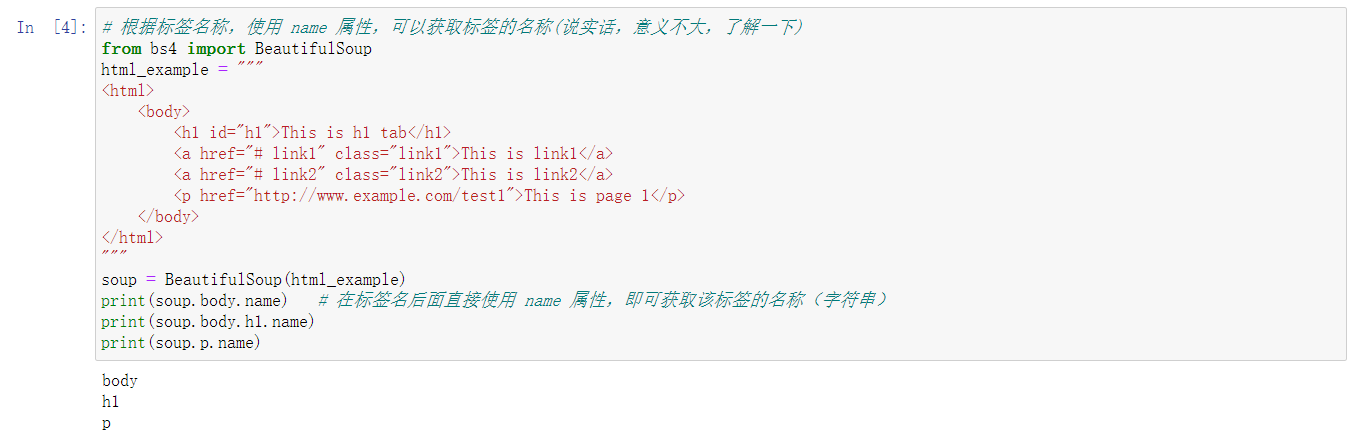



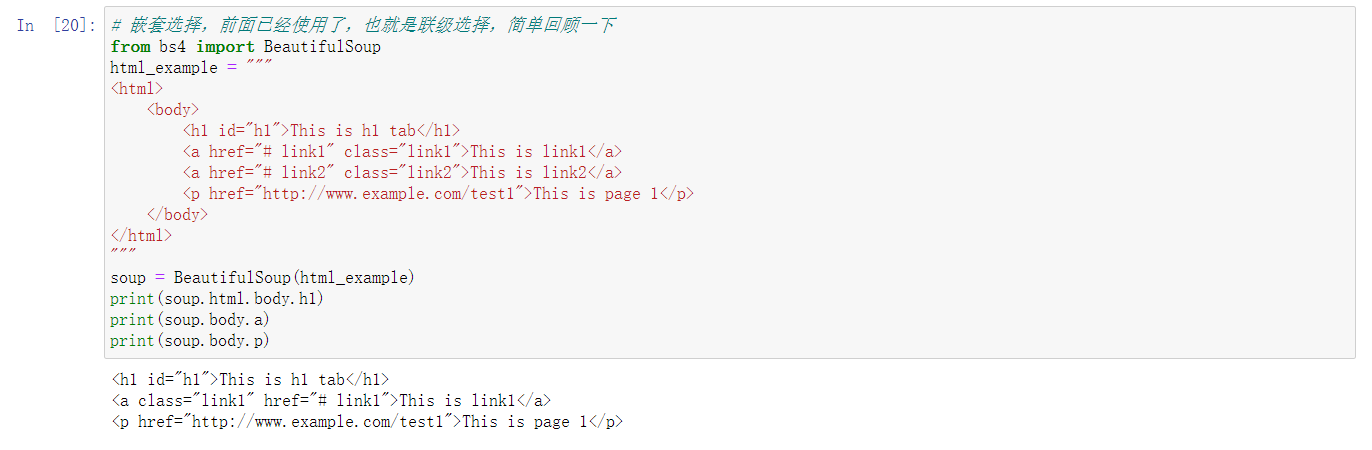
2、标准选择器
-
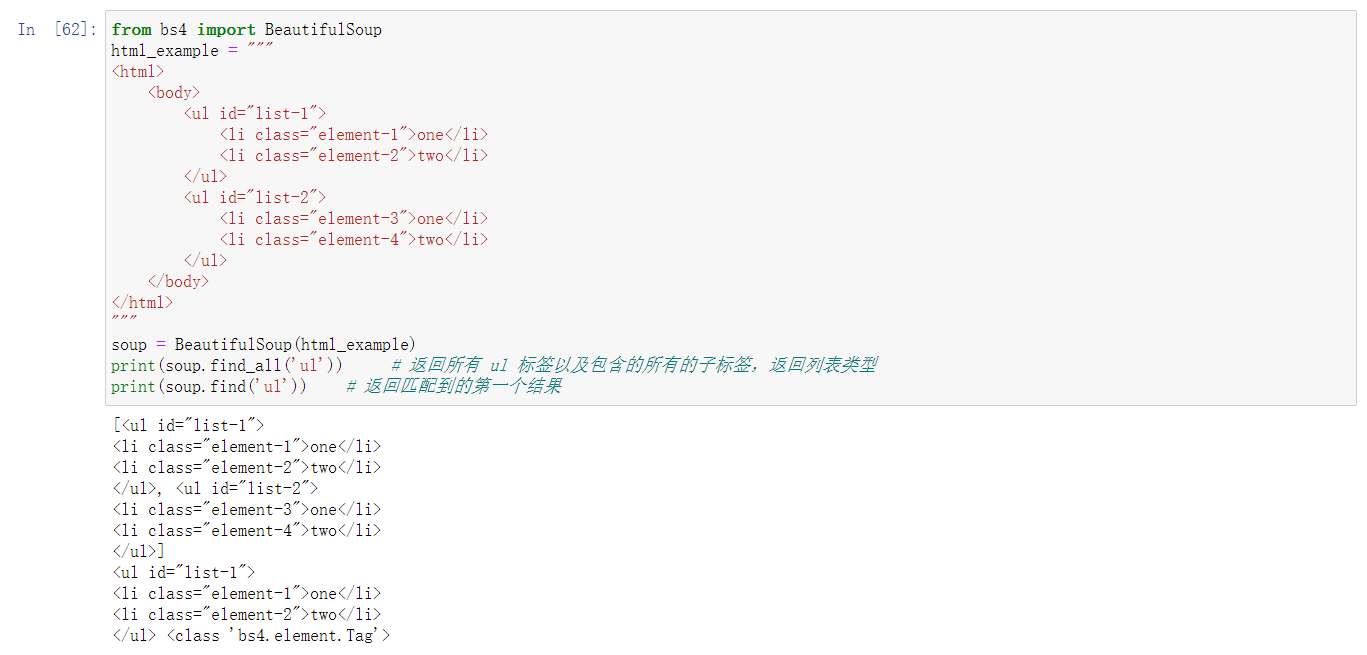
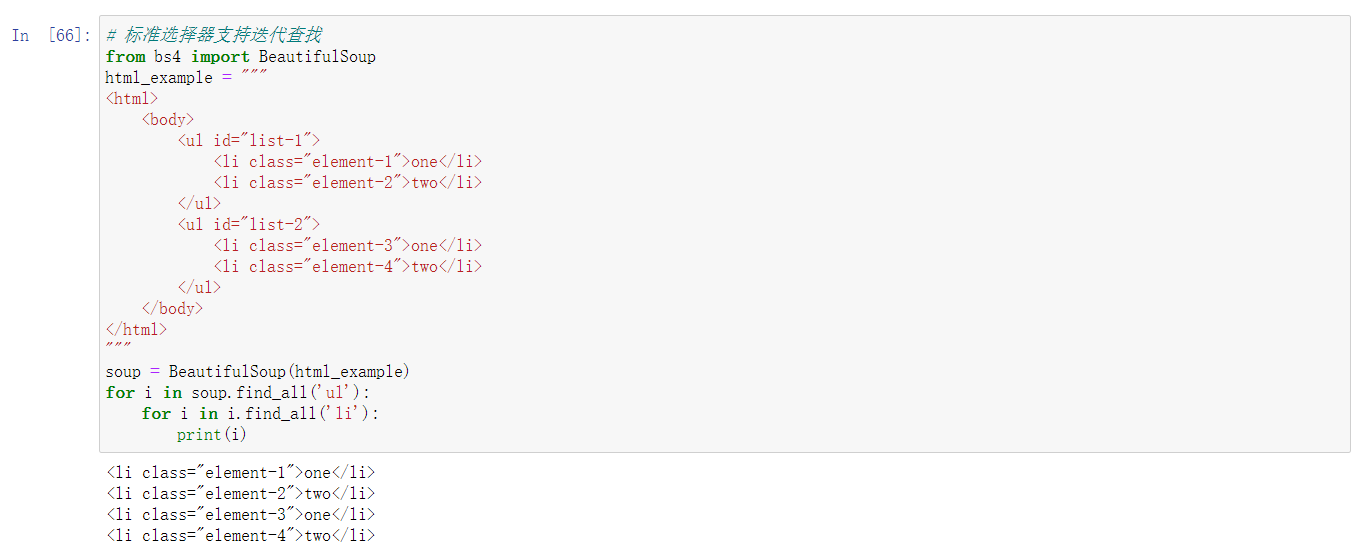
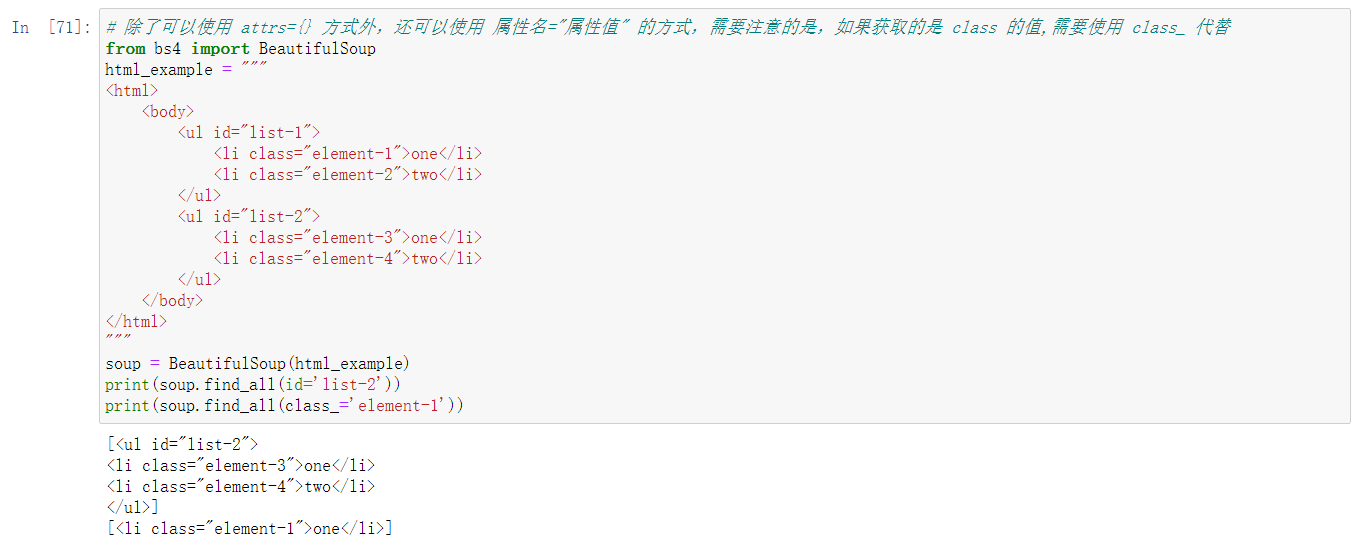
标准选择器是指:find_all 和 find
- 都可根据标签名、属性、内容查找文档
-
find_all(name, attrs, recursive, text, **kwargs),返回查找到的所有结果
-
find(name, attrs, recursive, text, **kwargs),返回查找到第一个结果

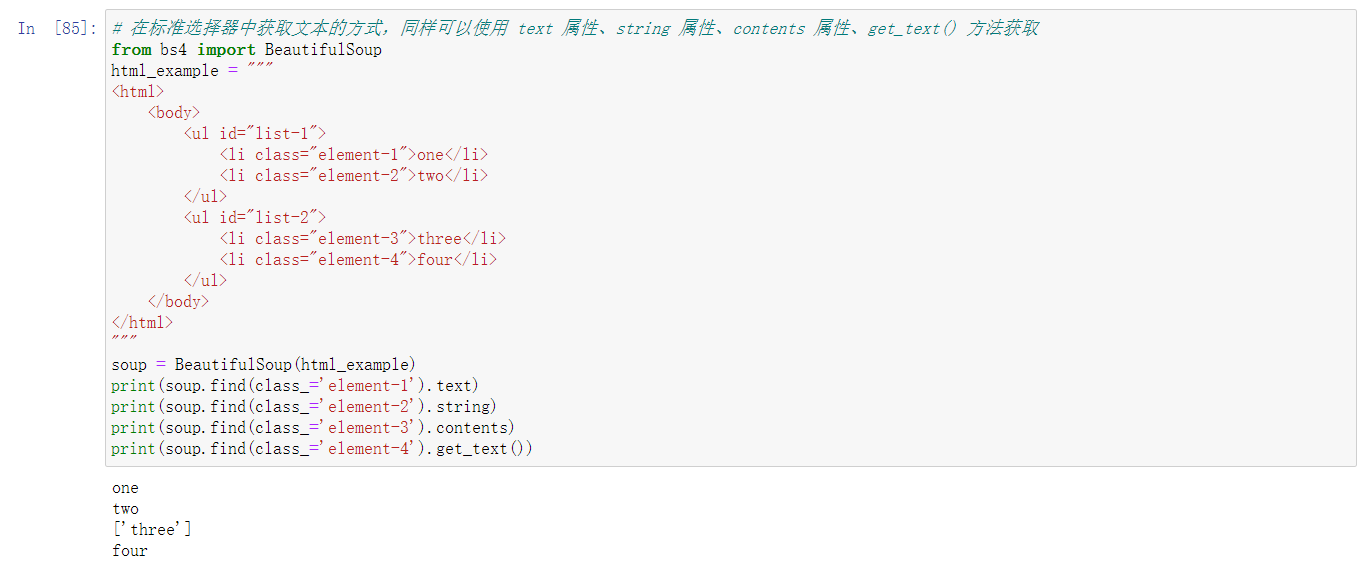
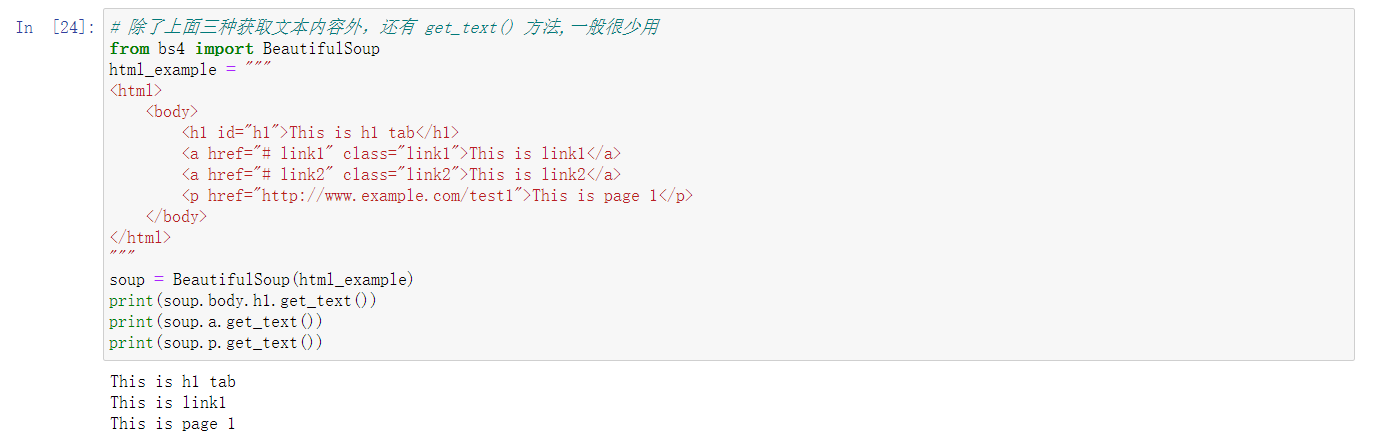
其他不常用的方法
| 方法 | 解释 |
|---|---|
| find_parents() find_parent() |
find_parents()返回所有祖先节点,find_parent0返回直接父节点 |
| find_next_siblings() find_next_sibling() |
find_next_siblings()返回后面所有兄弟节点,find_next_sibling()返回后面第一个兄弟节点。 |
| find_previous_siblings() find_previous_sibling() |
find_previous_siblings()返回前面所有兄弟节点, find_previous_sibling()返回前面第一个兄弟节点。 |
| find_all_next() find_next() |
find_all_next()返回节点后所有符合条件的节点, find_next()返回第一个符合条件的节点 |
| find_all_previous() find_previous() |
find_all_previous0返回节点后所有符合条件的节点, find_previous()返回第一个符合条件的节点 |
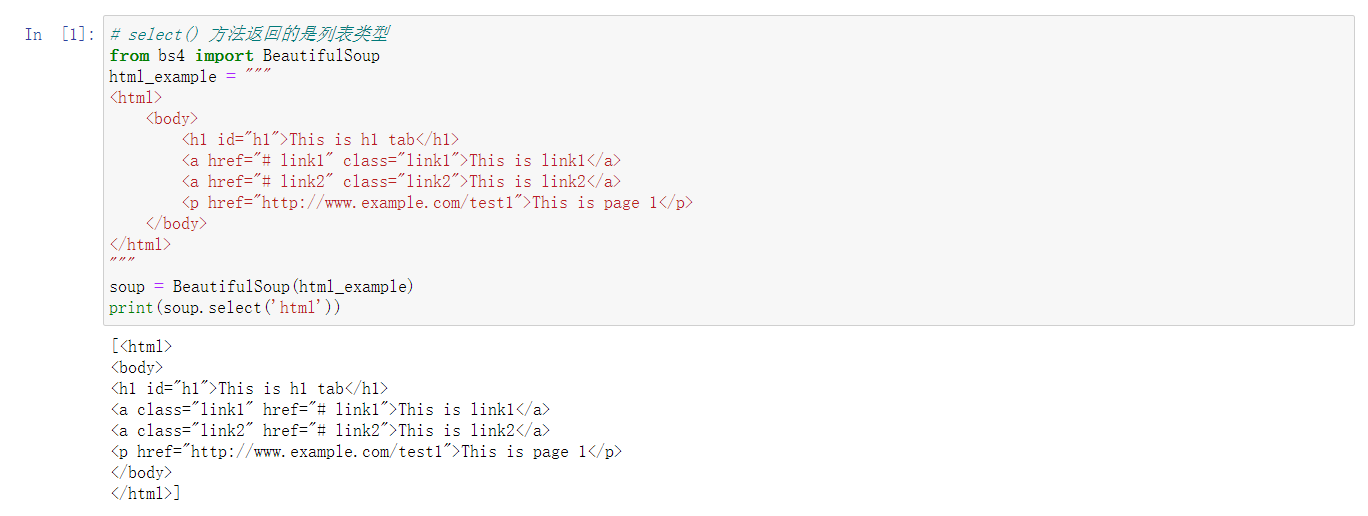
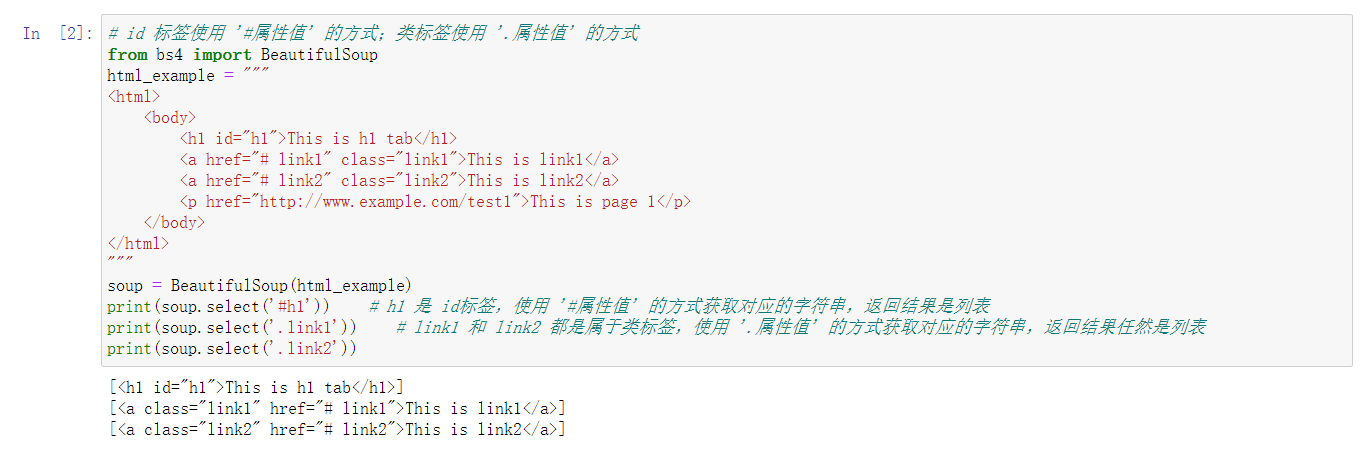
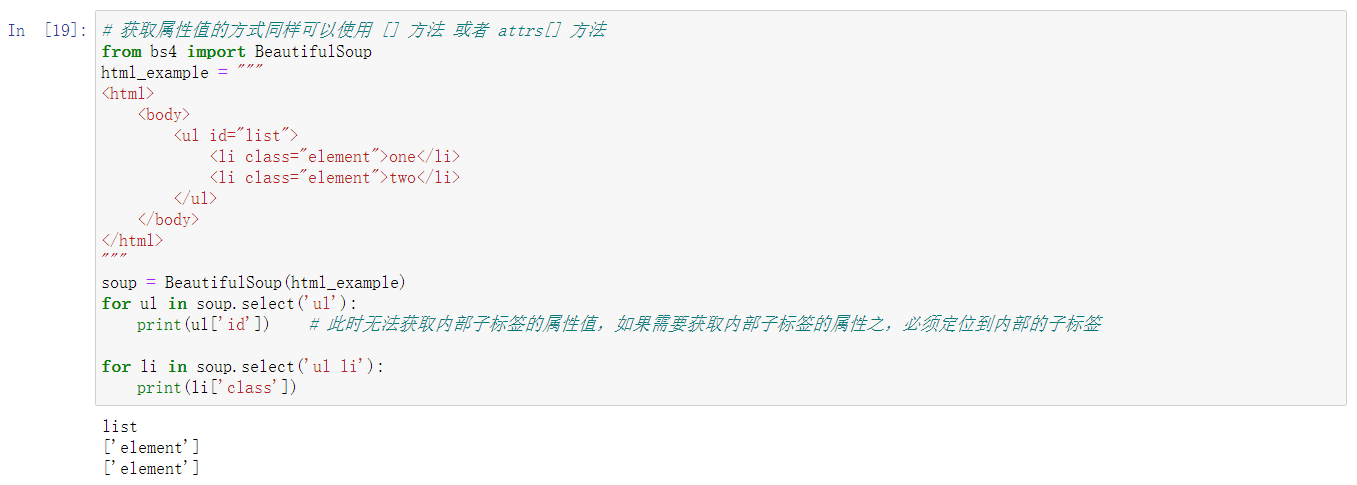
3、CSS选择器
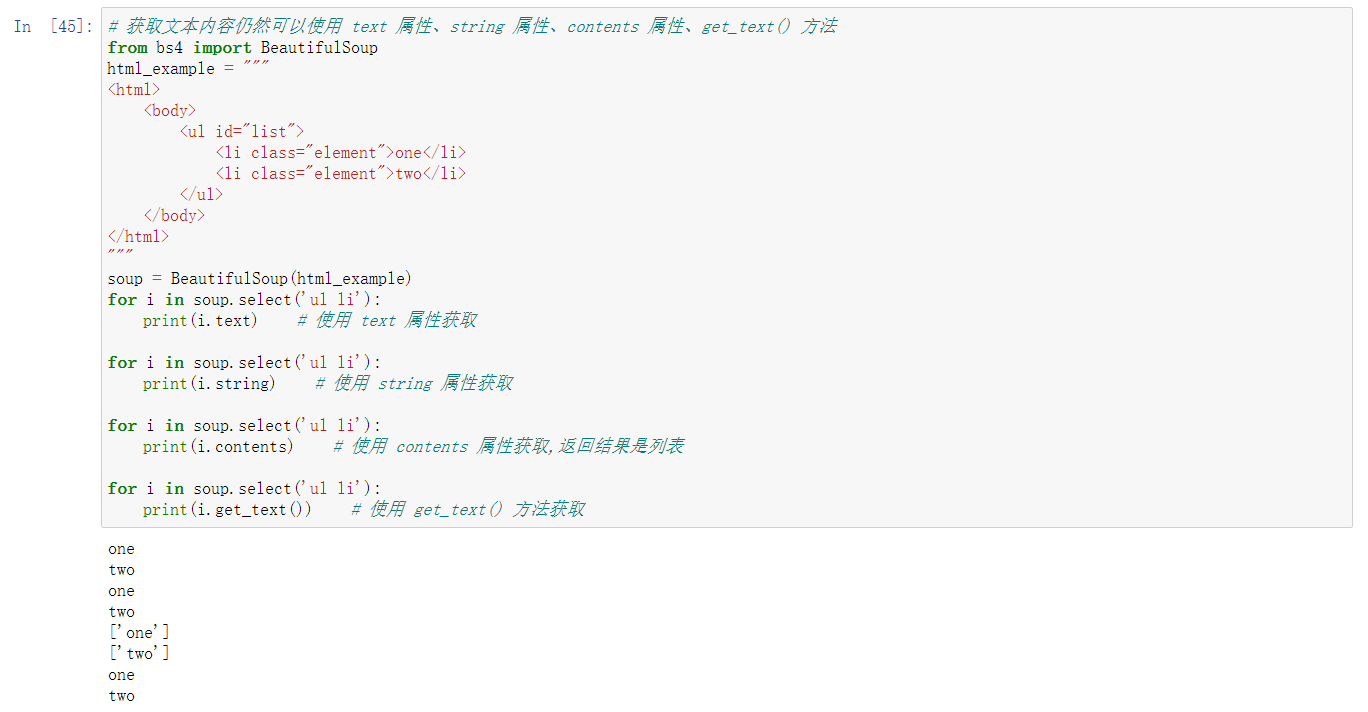
- 通过 select() 方法直接传入对应的标签、属性名即可完成选择,返回的结果是列表类型




 浙公网安备 33010602011771号
浙公网安备 33010602011771号