
juicefs元数据及数据存储方式
环境
文件系统使用juicefs,元数据存储使用postgresql,数据存储使用minio
问题?
通过juicefs写入一个文件,元数据在postgresql中是如何存储的?数据在minio中又是如何存储的?
新建 file1、dir1/file1、dir1/file2三个文件,大小分别为4B 9B 13B
在postgresql中
jfs_node表中记录着文件元数据信息

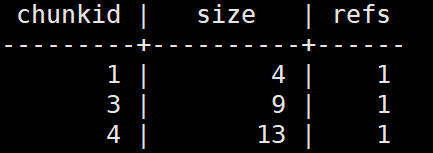
jfs_chunk表中记录着文件分片信息

slices中可以看到存着一堆16进制代码,看看juicefs源码里slices的定义
type Slice struct {
Pos uint32 // offset of the Slice in the Chunk
ID uint64 // ID of the Slice, globally unique
Size uint32 // size of the Slice
Off uint32 // offset of valid data in this Slice
Len uint32 // size of valid data in this Slice
}
在二进制存储中,每2个十六进制字符代表1个字节
以slices \x0000000000000000000000040000000d000000000000000d举例
00000000 Slice 在 Chunk 中的偏移位置为0
0000000000000004 Slice 的 ID,全局唯一(chunkid)转换为10进制数为4,
0000000d slice 的总大小为13
00000000 有效数据在此 Slice 中的偏移位置
0000000d 有效数据在此 Slice 中的大小为13
由上可解析出slice的各部分信息,跟以下chunk_ref表中的数据也能够一一对应
jfs_chunk_ref表中记录着文件分片补充信息
在minio中
可以看到具体的数据已经按照一定的层级存储到了minio中

目录层级关系和名字看着很陌生,是以什么规则进行的呢?层级中的
chunks/0/0/是怎么来的?对象名字4_0_13是怎么来的?
查看源码得知,在juicefs/pkg/chunk/cached_store.go中
func (s *rSlice) key(indx int) string {
if s.store.conf.HashPrefix {
return fmt.Sprintf("chunks/%02X/%v/%v_%v_%v", s.id%256, s.id/1000/1000, s.id, indx, s.blockSize(indx))
}
return fmt.Sprintf("chunks/%v/%v/%v_%v_%v", s.id/1000/1000, s.id/1000, s.id, indx, s.blockSize(indx))
}
传入一个index字段,最终生成一个字符串类型的路径,HashPrefix是一个配置项,以chunk表中id为3的数据为例,slice解析后的id为4,index为0,所以会返回chunks/0/0/,4_0_13,也能够跟minio中的数据一一对应
至此已基本了解文件到对象的元数据集数据的存储方式

 浙公网安备 33010602011771号
浙公网安备 33010602011771号