PyTorch基础学习笔记
一、初识
pytorch读取数据设计两个类:Dataset 和Dataloader
DataSet:提供一种方式,获取其中需要的数据及其对应的真实label值,并完成编号。主要实现功能:
- 如何获取每一个数据和label
- 告诉我们共有多少的数据
Dataloader:打包,为后面的神经网络提供不同的数据形式
1. Dataset实战
Dataset是一个抽象类,所有数据集都需要继承这个类,所有子类要重写__getitem__的方法,这个方法根据idx,返回获取每个数据集及其对应label。
读取图片的两种方式
- 使用opencv得到narray类型图片
import cv2
img_path = "dataset/train/1.jpg"
cv_img = cv2.imread(img_path)
- 使用PIL得到pil类型图片
from PIL import Image
img= Image.open(img_path)
img.show()
完整代码:
from torch.utils.data import Dataset
from PIL import Image
import os
#创建一个class 继承Dataset
class MyData(Dataset):
def __init__(self,root_dir,label_dir):
self.root_dir=root_dir
self.label_dir=label_dir
self.img_path = os.path.join(root_dir,label_dir)
self.img_list=os.listdir(self.img_path)
def __getitem__(self, idx):
img_name = self.img_list[idx]
img_item_path = os.path.join(self.root_dir,self.label_dir,img_name)
img = Image.open(img_item_path)
label = self.label_dir
return img,label
def __len__(self):
return len(self.img_list)
ants_dataset = MyData("dataset/train","ants")
img,label=ants_dataset[0]
2. TensorBoard的使用
from torch.utils.tensorboard import SummaryWriter
使用方法:
- 导包
- 实例化 writer = SummaryWriter("文件夹")
- 写入 writer.add_image/scalar/images
- 关闭 writer.close()
运行后,在terminal中输入,tensorboard --logdir=文件夹名 --port=~
add_scalar()方法使用

添加标量数据到Summary,需要参数
- tag: 标题
- scalar_value:需要保存的数值 (y轴)
- global_step: 训练到多少步 (x轴)
from torch.utils.tensorboard import SummaryWriter
#创建实例
writer=SummaryWriter("logs") #把对应的事件文件存储到logs文件夹下
for i in range(100):
writer.add_scalar("y=2x",2*i,i) # 标题、y轴、x轴
writer.close()
add_image()方法使用

- tag:标题
- img_tensor:图像的数据,类型需为torch.Tensor或numpy.array类型
- global_step:训练步骤
from torch.utils.tensorboard import SummaryWriter #导入SummaryWriter类
import numpy as np
from PIL import Image
#创建实例
writer=SummaryWriter("logs") #把对应的事件文件存储到logs文件夹下
image_path="data/train/ants_image/0013035.jpg"
img_PIL=Image.open(image_path)
img_array=np.array(img_PIL)
print(type(img_array))
print(img_array.shape) #(512,768,3) 即(H,W,C)(高度,宽度,通道)
writer.add_image("test",img_array,1, dataformats='HWC') # 第1步
writer.close()
3.torchvision中的transforms的使用
from torchvision import transforms
transforms.py (工具箱)有很多class文件(工具),将特定的图片经过工具处理后,就会输出想要的图片变换结果。
- Compose类,结合不同的transforms
- ToTensor类,把一个PIL或Numpy类型图片转换为tensor
- Normalize类,正则归一化
- CenterCrop类:中新裁剪
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img) #因为工具类有__call__函数所以直接传入调用
4.torchvision中的datasets使用
以CIFAR-10为例
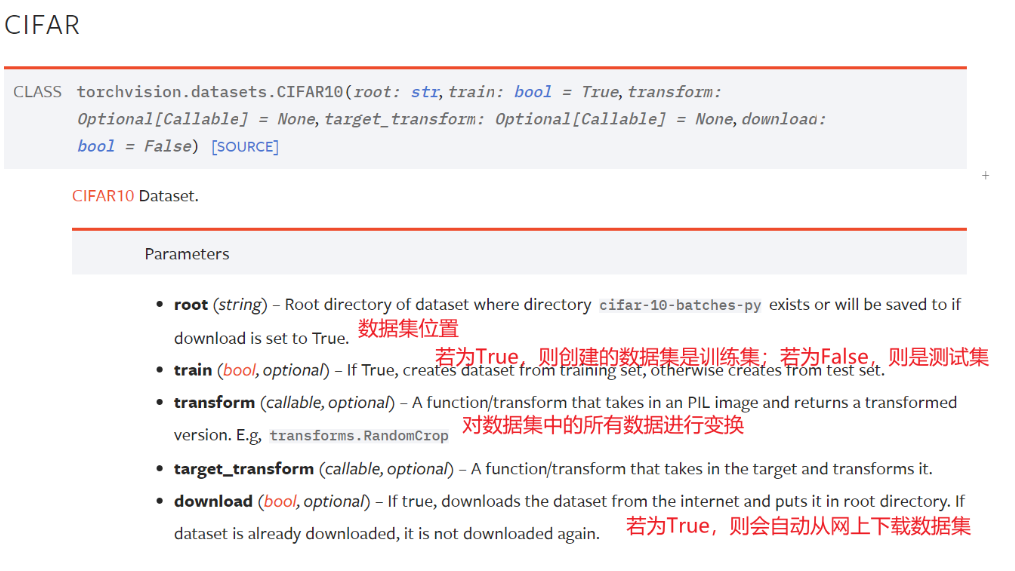
使用方法:
- 导包 improt torchvision
- 下载数据 torchviso.datasets.CIFAR10(root,trin,dowload,transform)
- 查看数据,
testset[0]查看第一个测试集数据,是一个元组(img,target)
testset.classes查看target分类列表
import torchvision
from torch.utils.tensorboard import SummaryWriter
#把dataset_transform运用到数据集中的每一张图片,都转为tensor数据类型
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
train_set=torchvision.datasets.CIFAR10(root="./dataset",train=True,transform=dataset_transform,download=True) #root使用相对路径,会在该.py所在位置创建一个叫dataset的文件夹,同时把数据保存进去
test_set=torchvision.datasets.CIFAR10(root="./dataset",train=False,transform=dataset_transform,download=True)
# print(test_set[0])
writer = SummaryWriter("p10")
#显示测试数据集中的前10张图片
for i in range(10):
img,target = test_set[i]
writer.add_image("test_set",img,i) # img已经转成了tensor类型
writer.close()
5. DataLoader的使用
想象dataset是一叠扑克牌,dataloader是抓牌的动作。

- num_workers:采用多少个进程,windows>0可能出错。默认为0
- shuffle:一轮后下次抓取是否与上一轮一样。(是否打完后洗牌)
对dataloader的遍历使用 for data in loader:
test_data= torchvision.datasets.CIFAR10("dataset2",train=False,transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_data,batch_size=24,shuffle=True,num_workers=0,drop_last=False)
writer = SummaryWriter("logs")
index=0
for data in test_loader: #data是loader的数据
imgs,targets = data
writer.add_images("dataloader2",imgs,index)
index+=1
writer.close()
6. 神经网络基本骨架 nn.module的使用
torch.nn下包含如下的一些层次。

Containers中包含如下6个模块,其中Module最常用,为所有神经网络提供基本骨架

用法:
- 导包 from torch import nn
- 建立类继承 nn.Module (搭建model都必须继承)
- 重写初始化,调用父类初始化,可再加入一些模型
- 重写前向传播函数 forward(self,x) ,这里对输入处理得到输出
class Tudui(nn.Module):
def __init__(self):
super().__init__()
def forward(self,x):
x+=1
return x
tudui = Tudui() #获取实例
x=torch.tensor(1.0) # 获取tensor类型数据
print(tudui(x)) #tensor(2.)
7. 卷积层 以nn.functional.Conv2d为例的使用
nn.Conv2d参数如下

nn.function.Conv2d参数如下

二者的区别在于
- nn.Conv2d 是一个类,而 nn.functional.conv2d是一个函数。
- 调用方式不同:调用 nn.xxx 时要先在里面传入超参数,然后再将数据以函数调用的方式传入 nn.xxx
- n.xxx 能够放在 nn.Sequential里,而 nn.functional.xxx 就不行
- nn.functional.xxx 需要自己定义 weight,每次调用时都需要手动传入 weight,而 nn.xxx 则不用,因为它里面的权重都是需要学习的参数,没有办法自行定义。因此自定义卷积核时,之只能用nn.functional.xxx
stride步幅的含义
卷积核同输入图像进行各位相乘并相加得到一个值
- 步幅为几则输入图像的框向右移动几格
![image]()
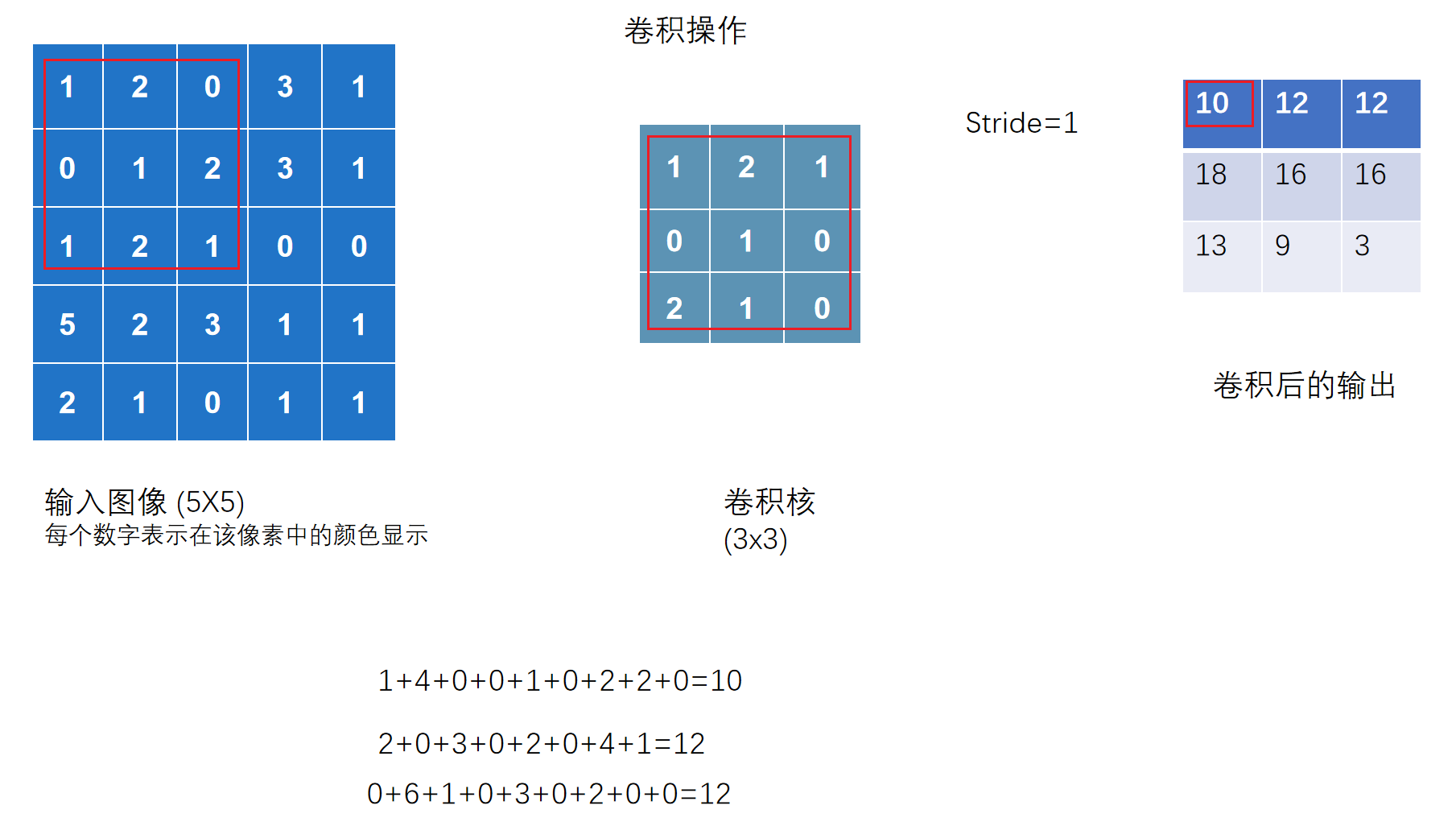
# 验证是否与上图相符
import torch
import torch.nn.functional as F
input = torch.tensor([ #输入的二维矩阵
[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]
],dtype=float)
kernel = torch.tensor([ #卷积内核
[1,2,1],
[0,1,0],
[2,1,0]
],dtype=float)
print(input.shape) #torch.Size([5,5])
print(kernel.shape) #torch.Size([3,3])
#为了将其纳入卷积,需要变换为 N,C,W,H
input = torch.reshape(input,(1,1,5,5))
kernel = torch.reshape(kernel,(1,1,3,3))
print(input.shape) #torch.Size([1, 1, 5, 5])
output = F.conv2d(input,kernel,stride =1)
print(output)
# tensor([[[[10., 12., 12.],
# [18., 16., 16.],
# [13., 9., 3.]]]]
padding填充的含义
在输入图像两边进行填充,若padding=1,则将图像左右上下均扩展一个像素,默认为0.
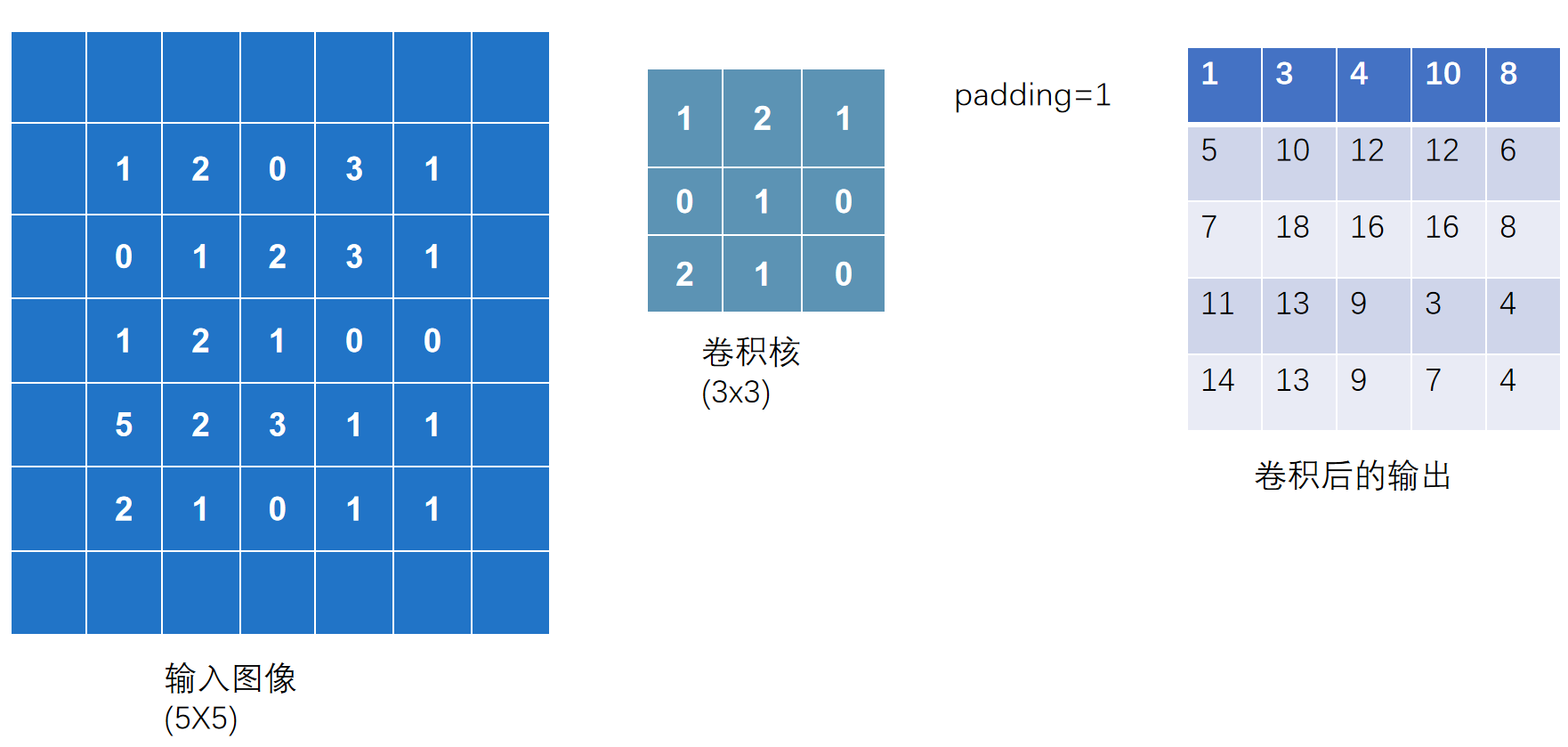
8. 神经网络-卷积层 nn.Conv2d
以CIFAR10数据集为例
import torch
import torchvision
from torch.utils.tensorboard import SummaryWriter
from torch.nn import Conv2d
from torch import nn
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("../dataset2",train=False,transform=torchvision.transforms.ToTensor(),download=False)
dataloader = DataLoader(dataset,batch_size=64)
#搭建神经网路 Tudui
class Tudui(nn.Module):
def __init__(self) -> None:
super().__init__()
self.conv1 = Conv2d(in_channels=3,out_channels=6,kernel_size=3)
def forward(self,input):
output = self.conv1(input)
return output
# 初始化网络
tudui = Tudui()
# 打印网络结构
print(tudui) #Tudui( (conv1): Conv2d(3, 6, kernel_size=(3, 3), stride=(1, 1)))
#写入tensorBoard
writer = SummaryWriter("log")
step=0
for data in dataloader:
imgs,targets=data
output = tudui(imgs)
#print(imgs.shape) #torch.Size([16, 3, 32, 32])
#print(output.shape) #torch.Size([16, 6, 30, 30]),经过卷积后通道增加,所以原始图像减小
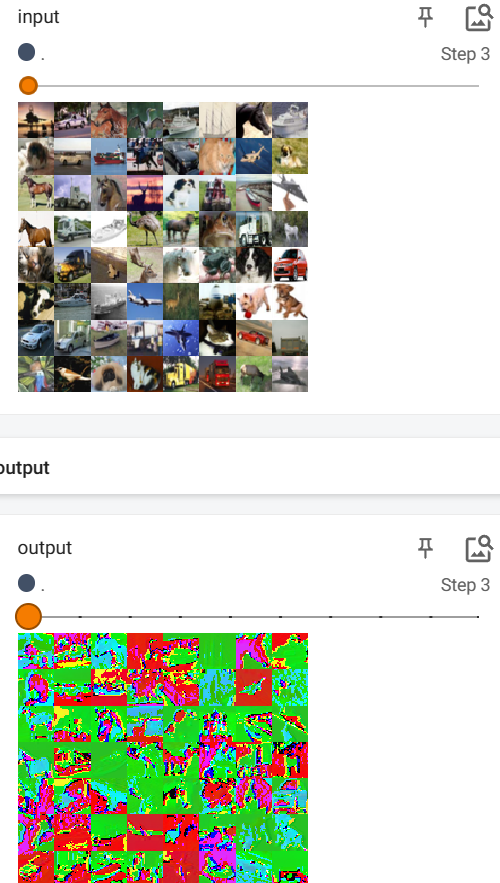
writer.add_images("input",imgs,step)
#因为add_imgs不能展示6通道,修改,-1表示自己根据后面的计算
output=torch.reshape(output,(-1,3,30,30))
writer.add_images("output",output,step)
step+=1
6改3通道数不变的效果图:
卷积后的长宽计算公式

9. 池化层,以最大池化为例 MaxPool
池化层分类,常用最大池化层

torch.nn.MaxPool2d(~)的参数如下

最大池化是取池化核与输入图形覆盖的最大值
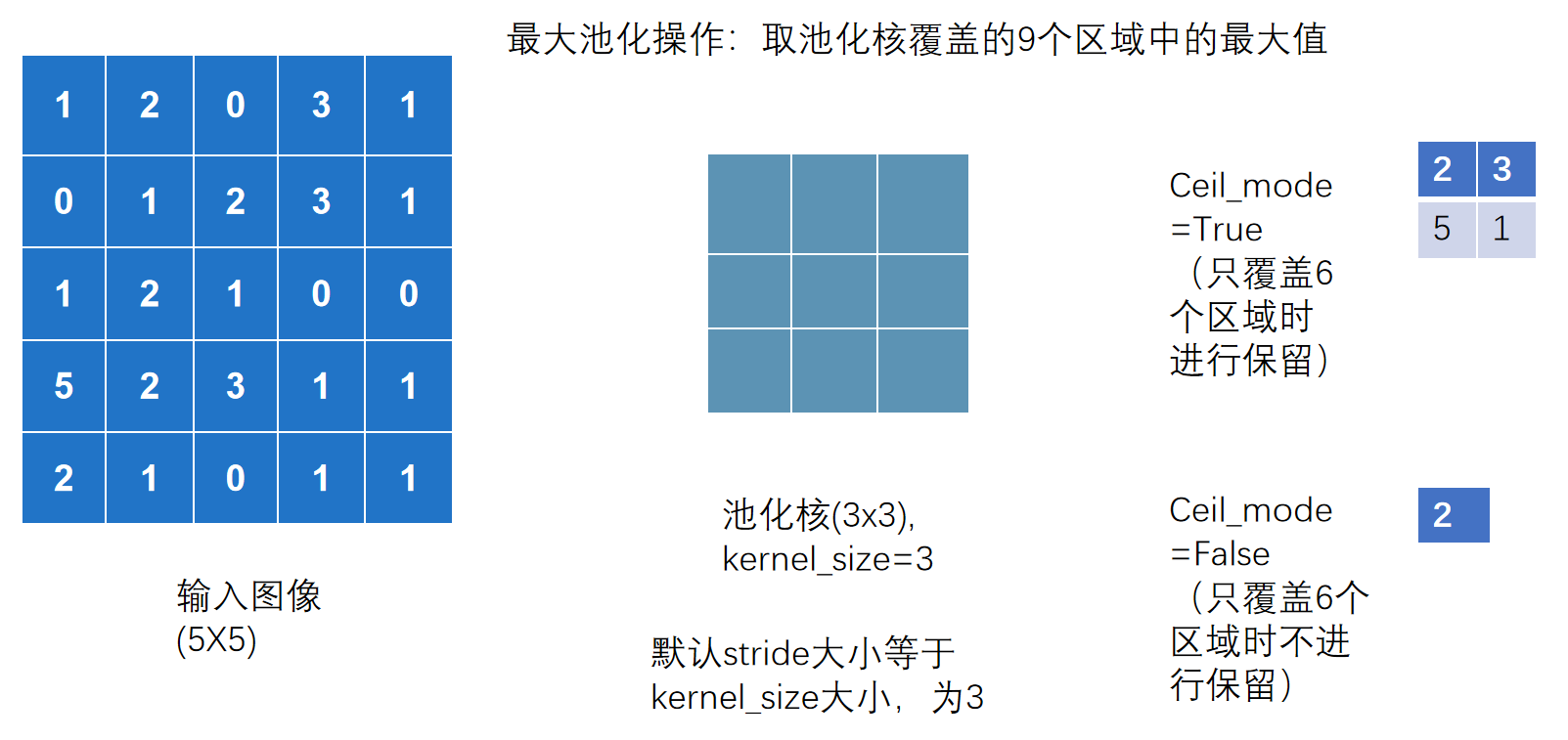
输出图像的长宽计算公式

最大池化的作用:
最大池化的作用是 保留输入特征,同时把数据量减小。好处是计算的参数变少,会训练的更快
池化一般跟在卷积后,卷积层是用来提取特征的,一般有相应特征的位置是比较大的数字,最大池化可以提取这一部分有相应特征的信息。
池化不影响通道数,池化后一般再进行非线性激活
#以CIFAR10为例
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.nn import MaxPool2d
from torch.utils.tensorboard import SummaryWriter
dataset =torchvision.datasets.CIFAR10(root="../dataset2",transform=torchvision.transforms.ToTensor(),train=False,download=False)
dataloader =DataLoader(dataset,batch_size=64)
#搭建神经网络
class Mymodel(nn.Module):
def __init__(self) -> None:
super().__init__()
self.maxpool= MaxPool2d(kernel_size=3,ceil_mode=True)
def forward(self,x):
x= self.maxpool(x)
return x
#实例化
mymodel=Mymodel()
writer = SummaryWriter("log")
step=0
for data in dataloader:
imgs,targets=data
output=mymodel(imgs)
writer.add_images("input",imgs,step)
writer.add_images("output",output,step)
step+=1
writer.close()
效果图
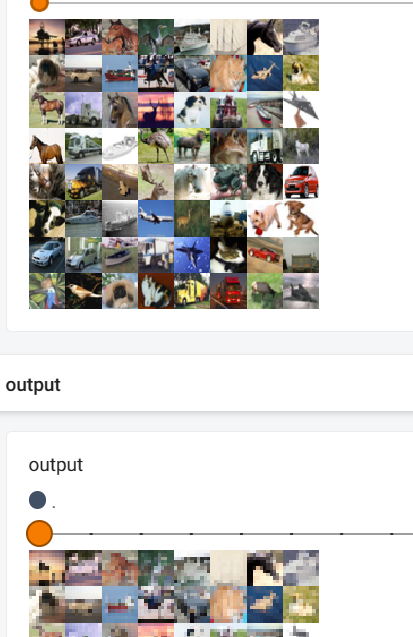
10. 非线性激活 以RELU为例
非线性越多,才能训练出符合各种曲线或特征的模型(提高泛化能力)
RELU:

参数inplace表示是否将原值替换,默认为False

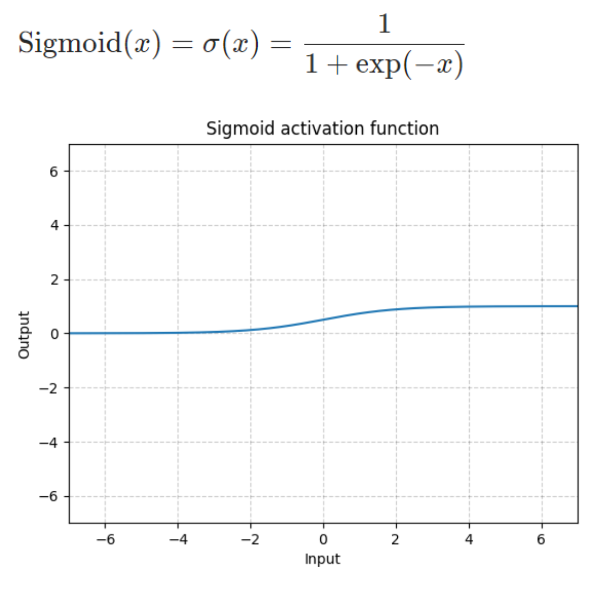
Sigmoid:
11. 线性层 Linear
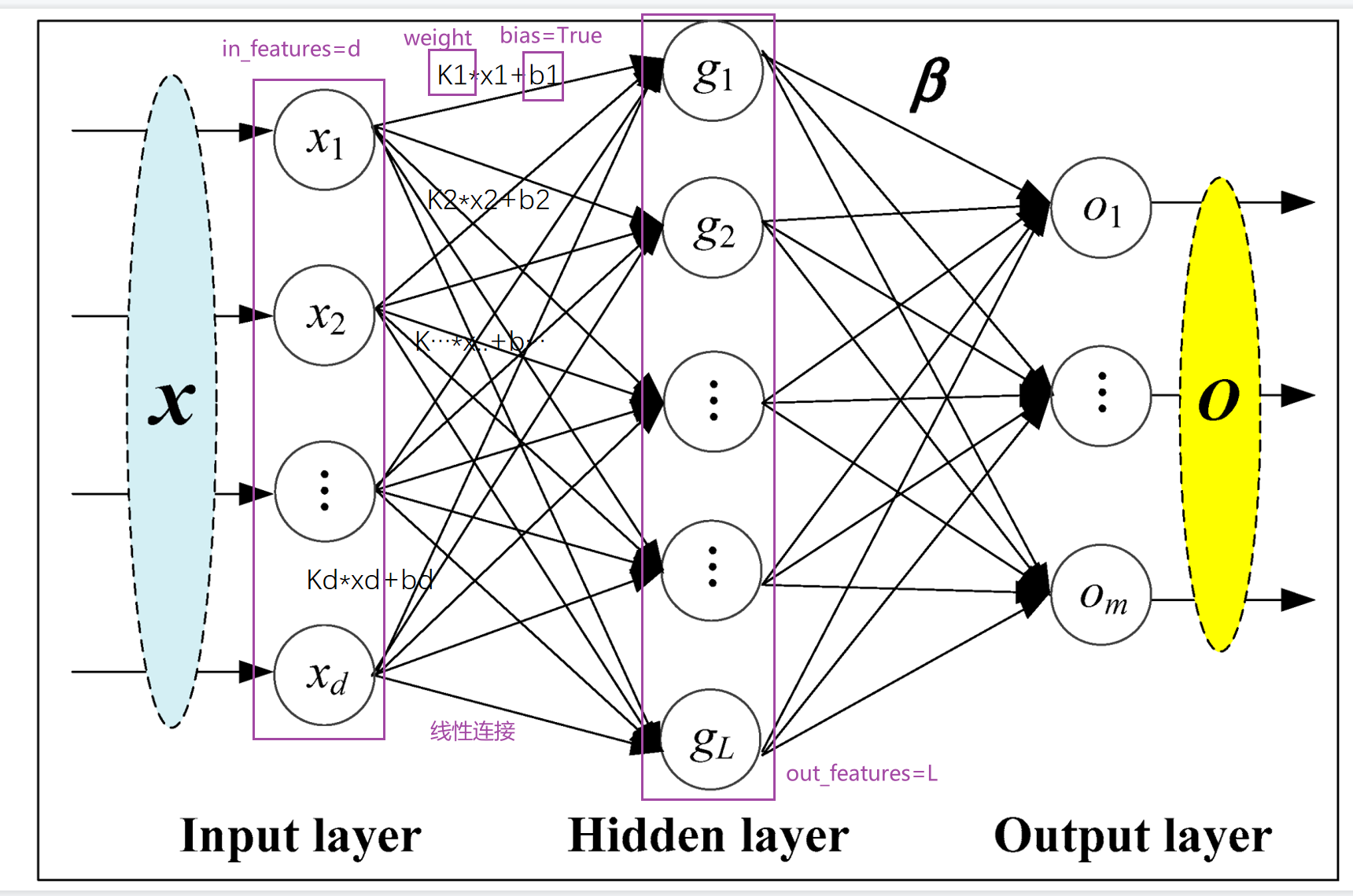
具体的权重是在学习过程中变化

12. 摊平 flatten


#实验上面的过程
dataset = torchvision.datasets.CIFAR10("../dataset2",train=False,transform=torchvision.transforms.ToTensor(),download=False)
dataloader = DataLoader(dataset,batch_size=64,drop_last=True)
class Tudui(nn.Module):
def __init__(self) -> None:
super().__init__()
self.linear = Linear(196608,10) #64*3*32*32=196608
def forward(self,x):
x = self.linear(x)
return x
tudui = Tudui()
for data in dataloader:
imgs,targets=data
output = torch.flatten(imgs)
print(output.shape) #torch.Size([196608])
output = tudui(output)
print(output.shape) #torch.Size([10])
13. 搭建小实战和Sequential使用
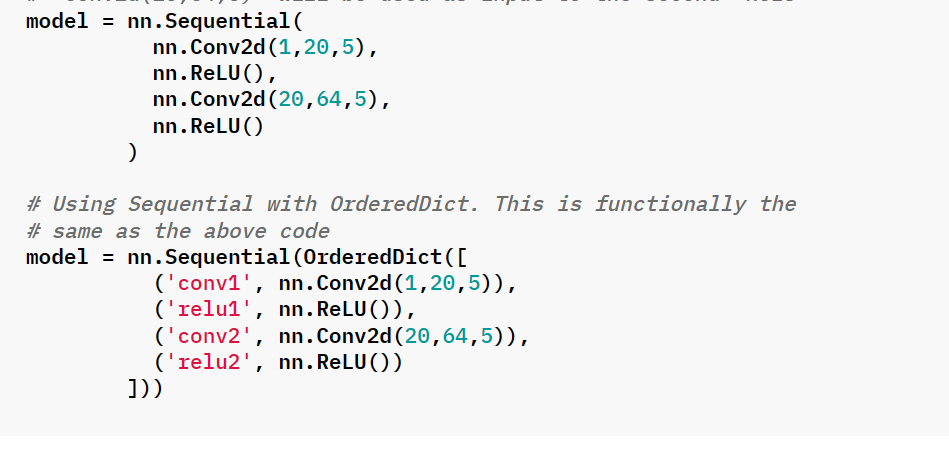
对CIFAR10进行分类的简单神经网络
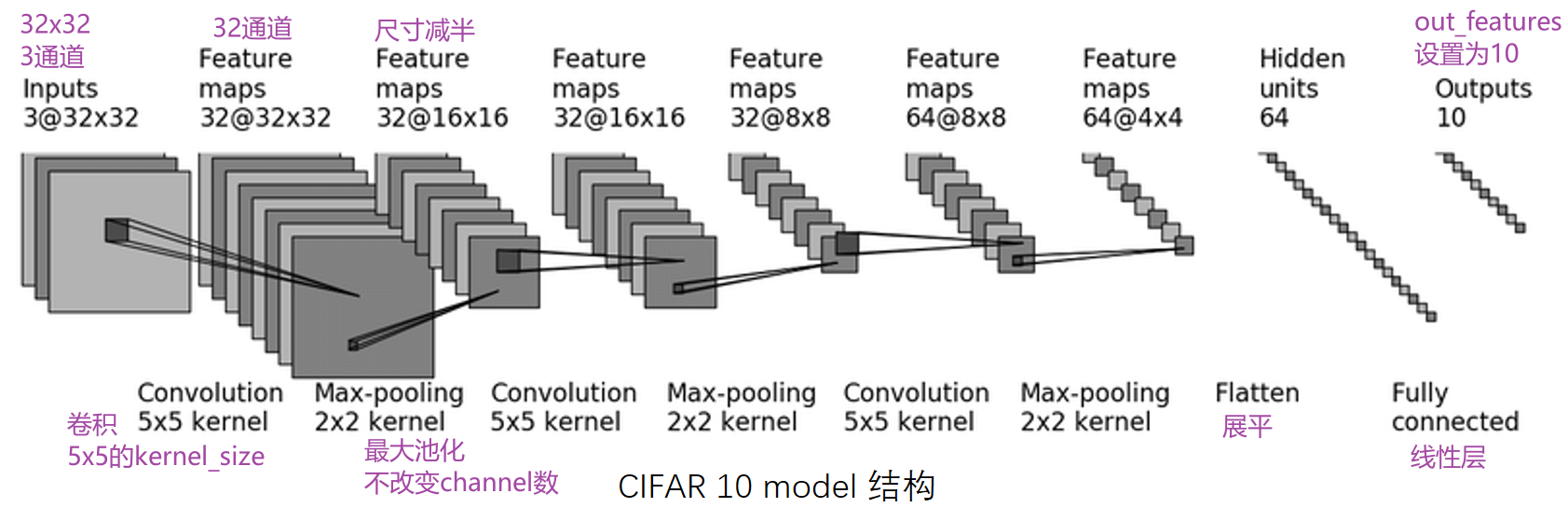
第一步卷积根据已知Hout,kernelsize,Hin求 padding,stride,得padding=2,stride=1.
对于卷积的理解:
- 几个卷积核就是几通道,在计算时一个卷积核作用在RGB通道后会把得到的三个矩阵对应值相加。
- 为保持变化后的尺寸不变,padding设置为卷积核大小一半(公式推的 p =(k-1)/2)
- 通道变化是通过调整卷积核的个数来实现的
- 不同kernel内容不同,可理解为不同的特征抓取

class Tudui(nn.Module):
def __init__(self) -> None:
super().__init__()
self.model = nn.Sequential(
nn.Conv2d(3,32,5,padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32,32,5,padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32,64,5,padding=2),
nn.MaxPool2d(2),
nn.Flatten(), #注意和torch.flatten区别。
#nn.Flatten默认start_dim=1,torch.~默认start——dim=0,另外一个是类,一个是函数
nn.Linear(1024,10)
)
def forward(self,x):
x=self.model(x)
return x
tudui = Tudui()
print(tudui)
看到网络结构:
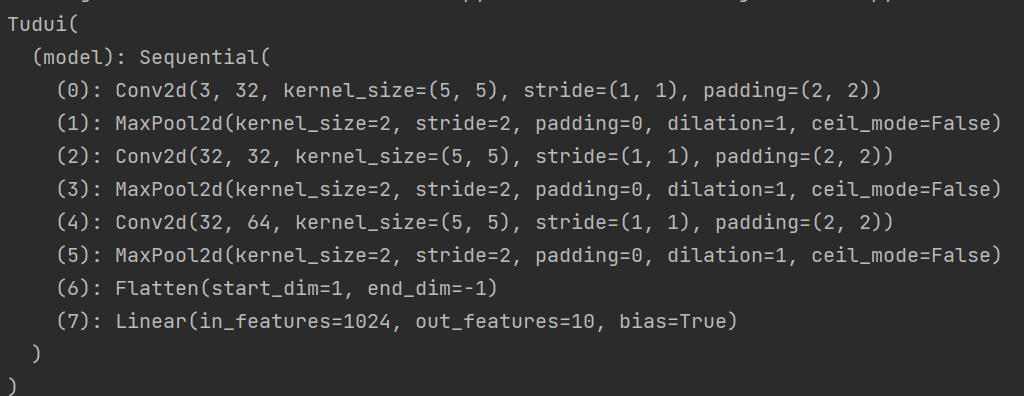
检查网络的正确性
tudui = Tudui()
input =torch.ones((64,3,32,32))
output=tudui(input)
print(output.shape) #torch.Size([64, 10])
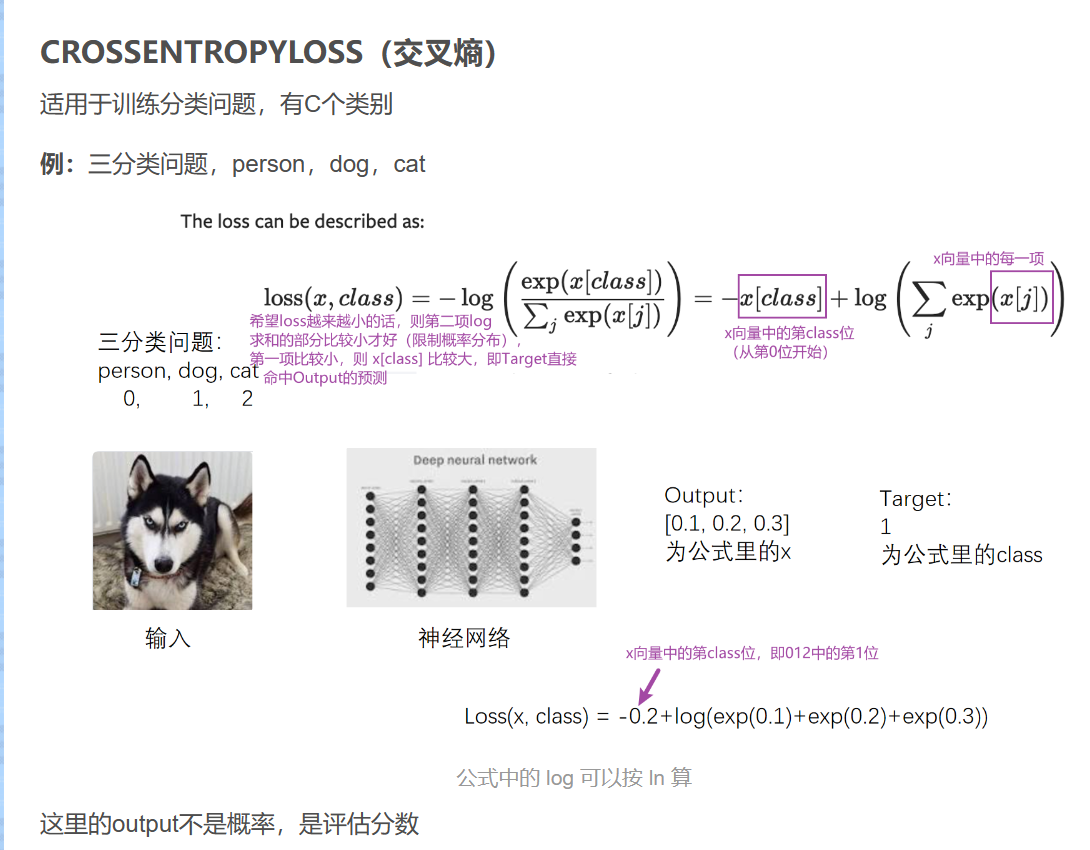
13. 损失函数与反向传播
torch.nn 里的 loss function 衡量误差,只需注意输入和输出形状
loss衡量的是实际神经网络输出output,和真实结果target的差距,越小越好




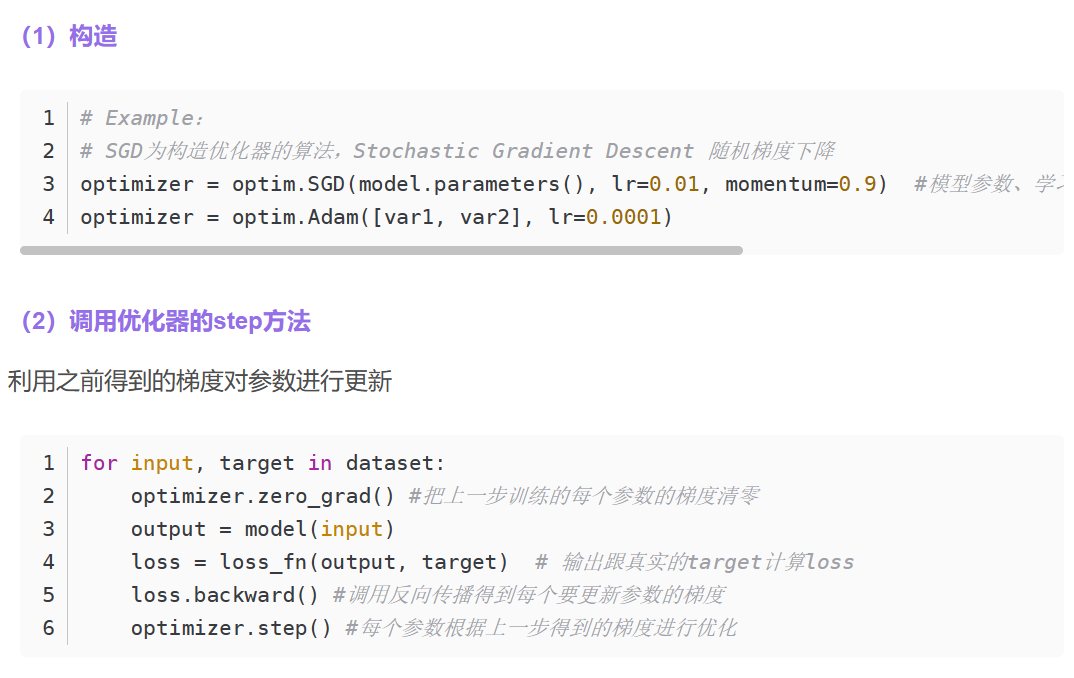
14. 优化器
import torch
import torchvision.datasets
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
# 加载数据集并转为tensor数据类型
dataset = torchvision.datasets.CIFAR10("../data",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset,batch_size=1)
# 创建网络名叫Tudui
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = Sequential(
Conv2d(3,32,5,padding=2),
MaxPool2d(2),
Conv2d(32,32,5,padding=2),
MaxPool2d(2),
Conv2d(32,64,5,padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024,64),
Linear(64,10)
)
def forward(self,x): # x为input,forward前向传播
x = self.model1(x)
return x
# 计算loss
loss = nn.CrossEntropyLoss()
# 搭建网络
tudui = Tudui()
# 设置优化器
optim = torch.optim.SGD(tudui.parameters(),lr=0.01) # SGD随机梯度下降法
for epoch in range(20):
running_loss = 0.0 # 在每一轮开始前将loss设置为0
for data in dataloader: # 该循环相当于只对数据进行了一轮学习
imgs,targets = data # imgs为输入,放入神经网络中
outputs = tudui(imgs) # outputs为输入通过神经网络得到的输出,targets为实际输出
result_loss = loss(outputs,targets)
optim.zero_grad() # 把网络模型中每一个可以调节的参数对应梯度设置为0
result_loss.backward() # backward反向传播求出每一个节点的梯度,是对result_loss,而不是对loss
optim.step() # 对每个参数进行调优
running_loss = running_loss + result_loss # 每一轮所有loss的和
print(running_loss)
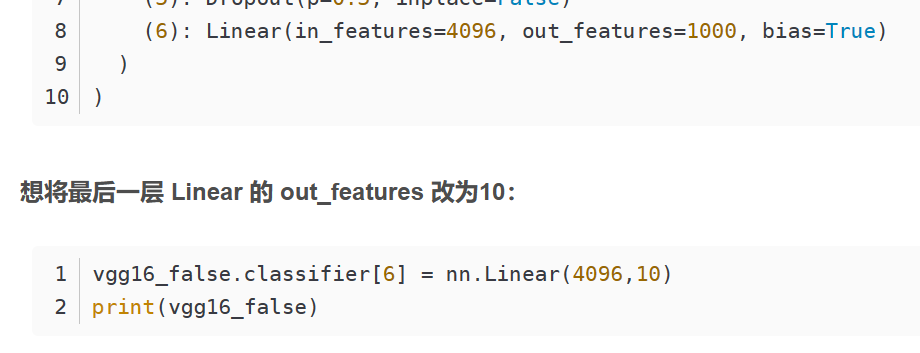
15. 现有模型的使用和修改

修改结构适应CIFAR10


16. 网络模型的保存和读取
保存:
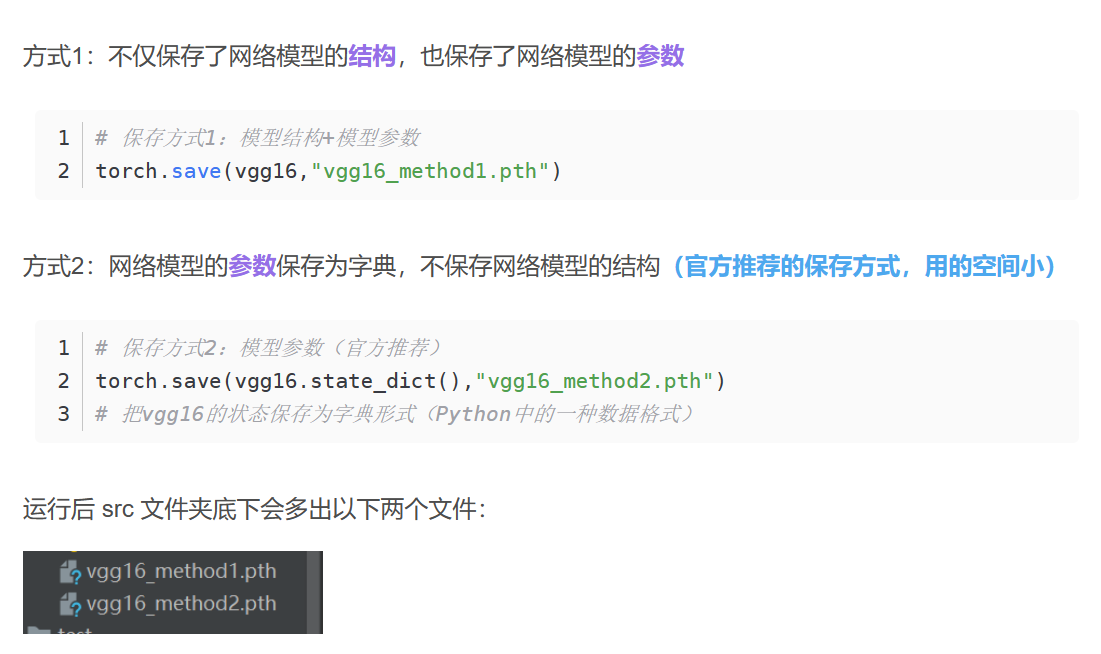
加载:
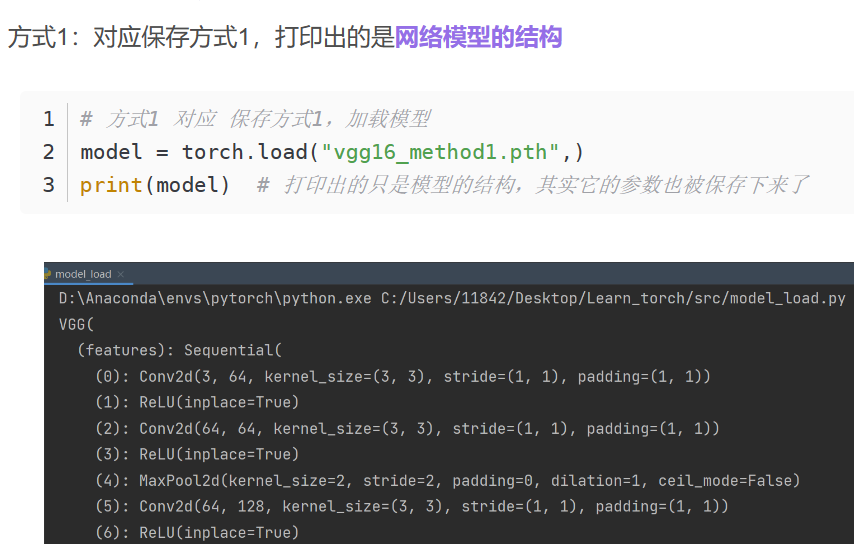
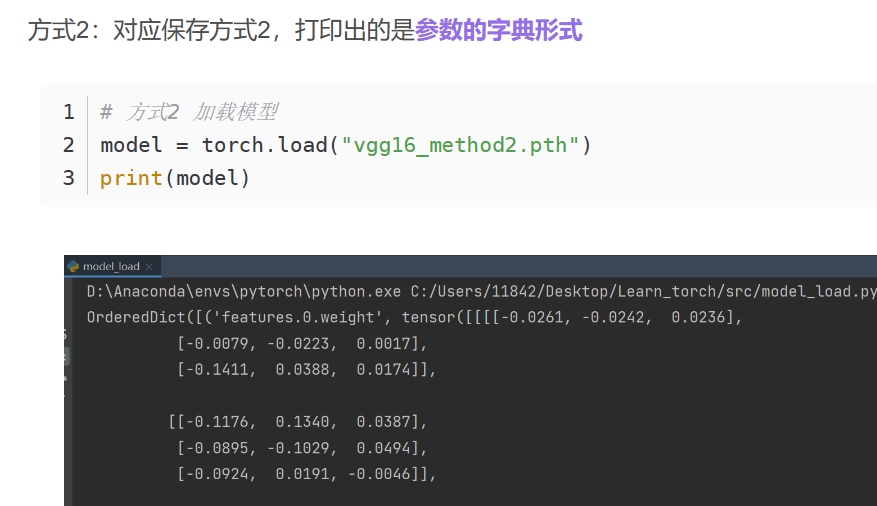
只保存了参数的模型如何恢复?
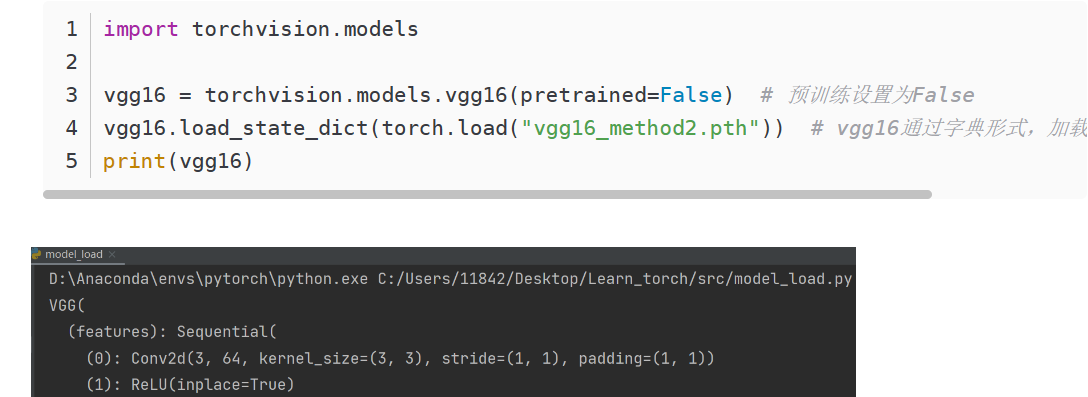
自定义网络结构时,第一种加载需要让程序访问到定义模型的方式
#保存模型
from torch import nn
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.conv = nn.Conv2d(3,64,kernel_size=3)
def forward(self,x): # x为输入
x = self.conv(x)
return x
tudui = Tudui() # 有一个卷积层和一些初始化的参数
torch.save(tudui,"tudui_method1.pth")
# 加载模型
class Tudui(nn.Module): #没有这个类会报错
def __init__(self):
super(Tudui, self).__init__()
self.conv = nn.Conv2d(3,64,kernel_size=3)
def forward(self,x): # x为输入
x = self.conv(x)
return x
model = torch.load("tudui_method1.pth")
print(model)
实际写项目过程中,直接定义在一个单独的文件中(如model_save.py),再在 model_load.py 中:
from model_save import *
17. 完整的模型训练套路
- 每轮训练完就在测试集上使用损失或正确率评估模型
- 与tensorboard结合,可视化过程
- 保存每一轮的训练模型
- 对分类问题的正确率实现
在model.py
import torch
from torch import nn
#搭建十分类的网络
class Tudui(nn.Module):
def __init__(self) -> None:
super().__init__()
self.model=nn.Sequential(
nn.Conv2d(3, 32, 5, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, padding=2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024, 10)
)
def forward(self,x):
x=self.model(x)
return x
if __name__ == '__main__':
#测试网络正确性
tudui = Tudui()
input = torch.ones((64,3,32,32))
output = tudui(input)
print(output.shape)
在train.py
import torch
import torchvision
from model import Tudui
from torch import nn
from torch.utils.data import DataLoader
#准备数据集
train_data = torchvision.datasets.CIFAR10(root="../dataset2",train=True,transform=torchvision.transforms.ToTensor(),download=False)
test_data = torchvision.datasets.CIFAR10(root="../dataset2",train=False,transform=torchvision.transforms.ToTensor(),download=False)
#获取数据集长度
train_data_size = len(train_data)
test_data_size = len(test_data)
#加载数据
train_dataloader = DataLoader(train_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)
#创建网络模型、损失函数、优化器
tudui = Tudui()
loss_func = nn.CrossEntropyLoss()
optim = torch.optim.SGD(tudui.parameters(),lr=0.01)
#设置训练网络的一些参数
train_step =0
test_step = 0
epcho = 10
for i in range(epcho):
print("==========第{}轮训练开始==========".format(i+1))
for data in train_dataloader:
imgs,targets = data
outputs = tudui(imgs)
loss = loss_func(outputs,targets)
#优化 梯度清0,反向传播,参数优化
optim.zero_grad()
loss.backward()
optim.step()
train_step+=1
if(train_step%100==0): #逢百打印记录
print("训练次数:{},Loss:{}".format(train_step,loss.item()))
print("---训练完成第{}轮---".format(i+1))
#每一轮训练完成需要使用测试集来评估模型,该过程不需要调优
total_test_loss=0
with torch.no_grad():
for data in test_dataloader:
imgs,targets=data
outputs=tudui(imgs)
loss = loss_func(outputs,targets)
total_test_loss+=loss.item() #loss为tensor,toatl~为普通数字,转换
print("测试上的Loss:{}".format(total_test_loss))
得到结果:
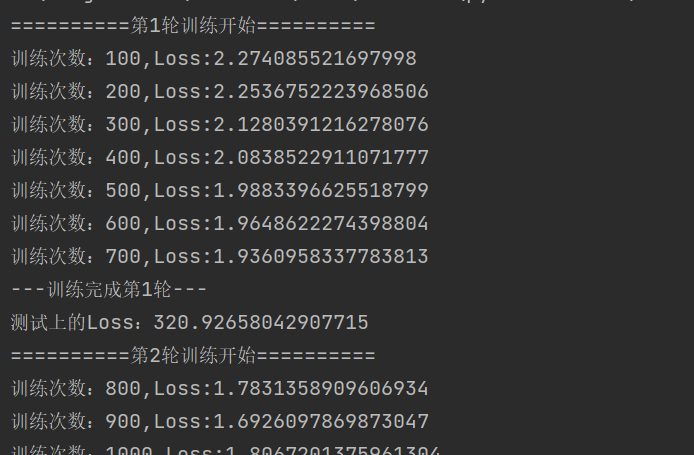
与tensorboard结合后
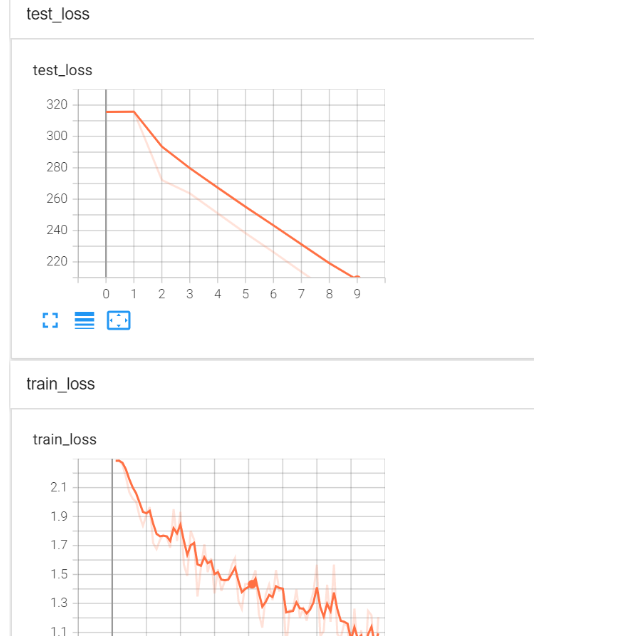
保存每一次训练的模型

正确率的实现:

- 通过argmx找到下标
- 通过sum(?==?).sum()得到tensor类型的位置相等个数
output.argmax(0/1),1表示横向比较,找到较大的下标
通过sum计算得到匹配正确的位置有几个
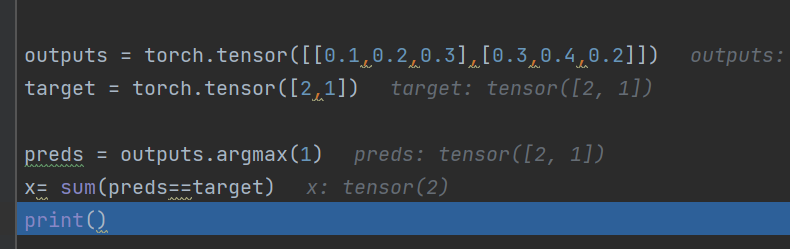
total_accuracy=0
with torch.no_grad():
for data in test_dataloader:
imgs,targets=data
outputs=tudui(imgs)
loss = loss_func(outputs,targets)
total_test_loss+=loss.item()
total_accuracy+=sum(outputs.argmax(1)==targets)
print("测试上的Loss:{}".format(total_test_loss))
print("测试上的正确率:{}".format(total_accuracy/test_data_size))
若网络中有Dropout 层或 BatchNorm 层,则须在训练时调用model(tudui).train()
验证时调用model(tudui).eval()
18. 利用GPU进行训练
第一种方式
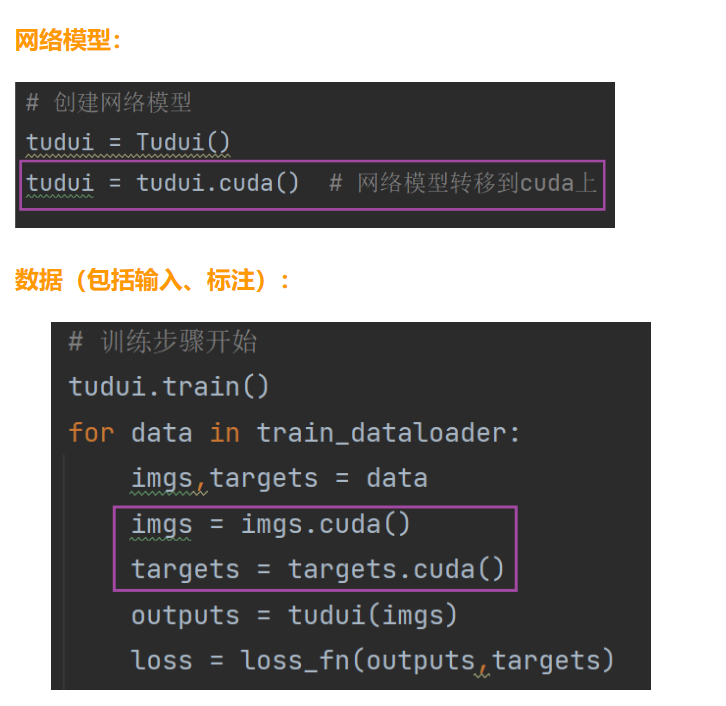
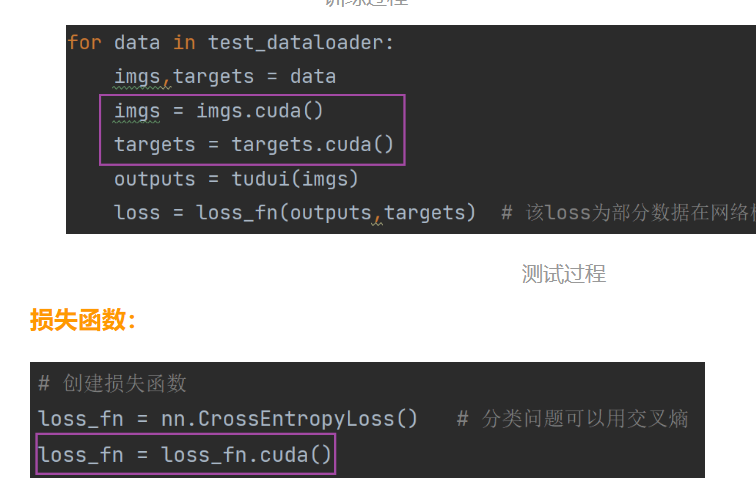
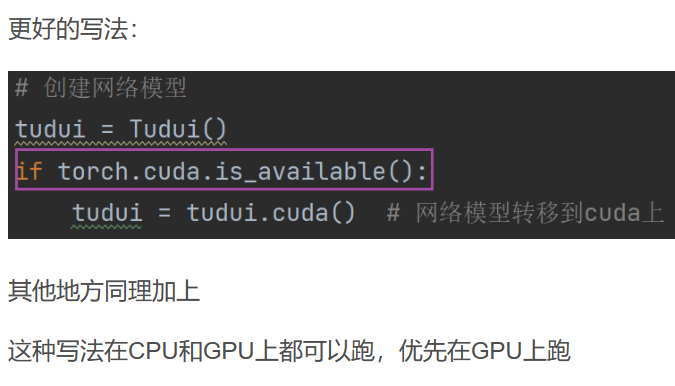
第二种方式(更常用)

语法糖
device = torch.device("cuda" if torch.cuda.isavailable() else "cpu")
19. 网上找图验证
import torch
import torchvision
from PIL import Image
from torch import nn
from model import Tudui
img_path = "th.jpg"
img = Image.open(img_path)
print(img)
transform = torchvision.transforms.Compose([
torchvision.transforms.Resize((32,32)),
torchvision.transforms.ToTensor()
])
img = transform(img)
img = torch.reshape(img,(1,3,32,32))
img=img.cuda()
print(img.shape)
#加载网络模型
model = torch.load("tudui9.pth")
print(model)
output = model(img)
print(output.argmax(1)) #tensor(5) 也就是dog

 浙公网安备 33010602011771号
浙公网安备 33010602011771号