

redis基础数据结构详解
一. redis为什么快
- 基于内存的存储
- 虽然是单线程,但是采取了多路复用,可以高效的处理网络并发
- 良好的数据结构设计
二.redis基础数据结构
redis有五种基础的数据结构 string,list,set,zset,hash
redis所有的数据结构的key都是string类型,我们所说的数据结构都是指value的数据结构
1. 字符串
redis中的字符串并没有采用C语言的字符串,而是对其进行了重新设计,redis中的字符串叫做SDS(Simple Dynamic String)
SDS的数据结构如下
struct sdshdr{
//记录buf数组中已使用字节的数量
int len;
//记录buf数组中未使用字节的数量
int free;
//字节数组,用于保存字符串
char buf [];
}
C字符串和SDS之间的区别:
- C语言字符串返回一个字符串长度需要从头到尾遍历,时间复杂度为O(N),SDS因为有len属性,所以可以直接返回len即可
- C语言字符串不能很好得防止缓冲区溢出,需要程序员手动判断一下,例如C字符串修改/拼接的时候,SDS字符串进行类似操作时,会先判断内存是否足够操作使用,如果不够使用,会先对SDS进行扩容
- C语言字符串对字符串进行修改必须重新对内存进行分配,SDS修改字符串时候并不一定会对内存进行重新分配,主要是因为采取了以下策略:
a. 空间预分配,当SDS扩容的时候,除了分配SDS所将要使用的内存空间外,还会分配和字符串内存相同的大小的内存空间
b. 惰性空间释放,当SDS释放内存空间时,并不会立刻释放内存空间,只需要使用free记录下即可 - SDS是安全的字符串,可以保存图片,音频等数据
SDS不同编码
int 当字符串对象值为整型,redis会直接用一个整数值来表示字符串对象
embstr
raw
以下为三种编码方式的内存布局
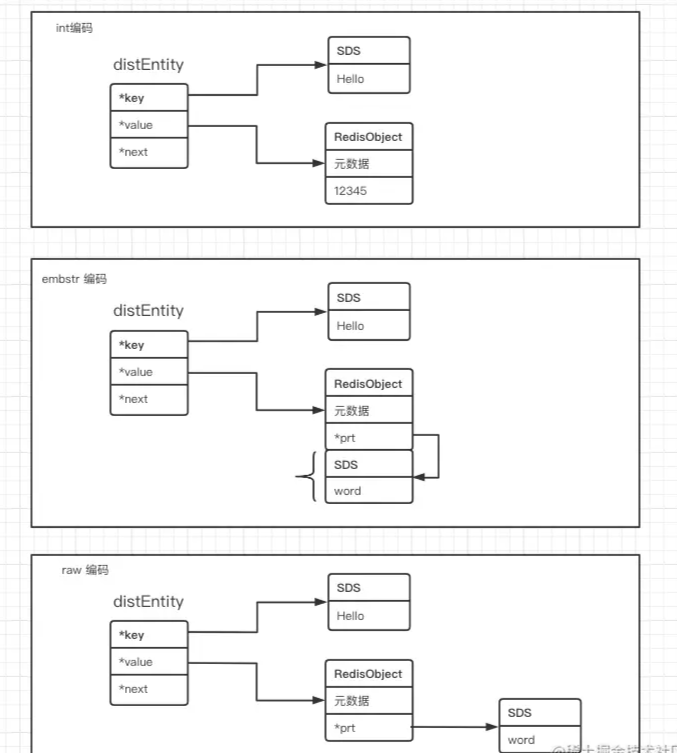
embstr:
一次预分配空间,只读,修改后自动转换为raw编码模式
增长超过44字节自动转换为raw编码模式
raw编码模式不可回退到embstr编码模式
只适合长点较小的字符串,小于44字节
raw编码模式
需要两次分配内存空间(分别为redisObject和sds分配内存空间)
保存大于44字节的字符串
embstr到raw的转换
在redis中,所有的存储都是以KV键值对的形式存储的,K是字符串类型,就是SDS;V 可能是字符串、list、hash等(Redis支持的数据结构),V并没有直接定成具体的类型,而是用redisObject封装了一层;实际存储的数据结构是由ptr指针具体指向。
并且,redis为了更好的节省空间,ptr指针也有不同方式的存储,一方面,当保存的是 Long 类型整数时,RedisObject 中的指针就直接赋值为整数数据了,这样就不用额外的指针再指向整数了,节省了指针的空间开销。另一方面,当保存的是字符串数据,并且字符串小于等于 44 字节时,RedisObject 中的元数据、指针和 SDS 是一块连续的内存区域,这样就可以避免内存碎片。这种布局方式也被称为 embstr 编码方式。当然,当字符串大于 44 字节时,SDS 的数据量就开始变多了,Redis 就不再把 SDS 和 RedisObject 布局在一起了,而是会给 SDS 分配独立的空间,并用指针指向 SDS 结构。这种布局方式被称为 raw 编码模式。
扩容:SDS在1M以下时,每次扩容会把当前容量扩大一倍,到了1M以后,每次扩容会增加1M容量
2. list
redis老版本采用ziplist和linkedlist表达list,但是由于linkedlist过于浪费内存,采用quicklist表达list,quicklist采用了ziplist和linkedlist的方式进行结合,quicklistnode结构包含ziplist,组成双向链表。ziplist默认超过8k就新开ziplist
quicklist的数据结构如下
struct ziplist {
...
}
struct ziplist_compressed {
int32 size;
byte[] compressed_data;
}
struct quicklistNode {
quicklistNode* prev;
quicklistNode* next;
ziplist* zl; // 指向压缩列表
int32 size; // ziplist 的字节总数
int16 count; // ziplist 中的元素数量
int2 encoding; // 存储形式 2bit,原生字节数组还是 LZF 压缩存储
...
}
struct quicklist {
quicklistNode* head;
quicklistNode* tail;
long count; // 元素总数
int nodes; // ziplist 节点的个数
int compressDepth; // LZF 算法压缩深度
...
}
3.hash
hash有两种数据结构
- ziplist
- dict
4.zset
zset底层两种数据结构
- ziplist
- hash+skiplist
5. set
hashtable(key为set里面的值,value为null)
inset(有序数组)
