
使用yarn安装spark集群
由于之前已经搭建好了,今天是看视频回顾下,然后做下记录。
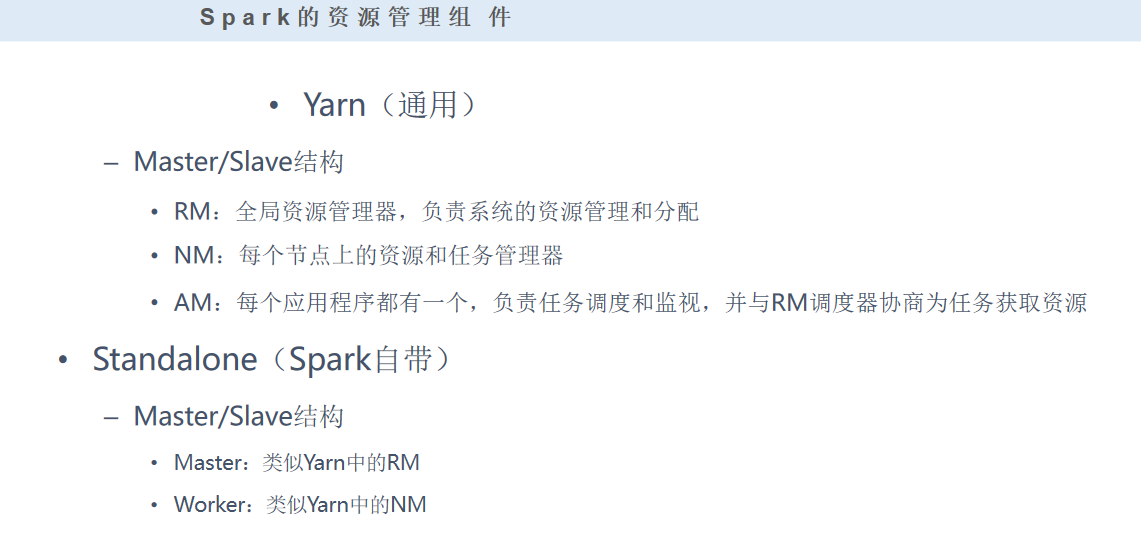
之前已经搭建好了Yarn集群,现在在Yarn集群上搭建spark。
1、安装spark
下载源码包:
wget http://mirror.bit.edu.cn/apache/spark/spark-1.3.0/spark-1.3.0.tgz
解压:
tar zxvf spark-1.3.0.tgz
配置:
解压后进去conf文件夹
cp spark-env.sh.template spark-env.sh
修改spark-env.sh文件
export SCALA_HOME=/usr/local/src/scala-2.11.4 export JAVA_HOME=/usr/local/src/jdk1.7.0_45 export HADOOP_HOME=/usr/local/src/hadoop-2.6.1 export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop SPARK_MASTER_IP=master SPARK_LOCAL_DIRS=/usr/local/src/spark-1.6.0-bin-hadoop2.6 SPARK_DRIVER_MEMORY=1G
设置从节点:
cp slaves.template slaves
修改slaves文件
slave1
slave2
设置好之后,保持每个节点都一致,将配置文件分发到每个从节点上
scp slaves root@192.168.181.12:/usr/local/src/spark-1.6.0-bin-hadoop2.6/conf scp slaves root@192.168.181.13:/usr/local/src/spark-1.6.0-bin-hadoop2.6/conf
启动spark
在master节点执行以下命令:
./sbin/start-all.sh
判断是否起送

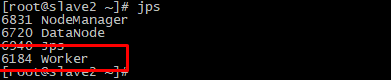
如果再master节点上执行jps后看到master,在slave节点上执行jps后看到work,基本上就可以判断是启动成功了。
验证spark
本地模式:
./bin/run-example SparkPi 10 --master local[2]
集群模式——standalone(独立集群)
# ./bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://master:7077 lib/spark-examples-1.6.0-hadoop2.6.0.jar 100 集群模式——yarn(与hadoop共享平台) 1)yarn-client:AM(driver)在本地启动并提交作业,更适合交互、调试的方便 2)yarn-cluster:AM(driver)在某一个NM启动并提交作业
# ./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn-cluster lib/sparkexamples-1.6.0-hadoop2.6.0.jar 10
AM:用来管理任务
RM:用来做资源分配
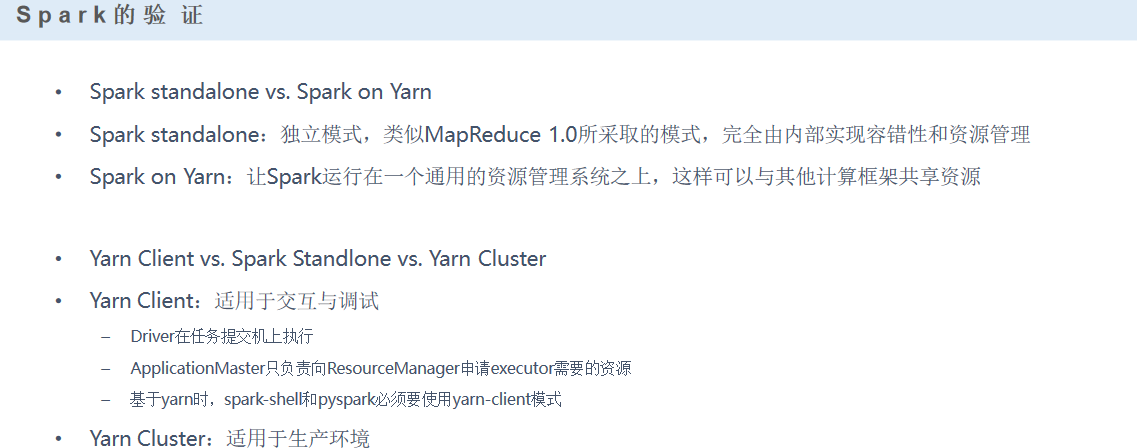
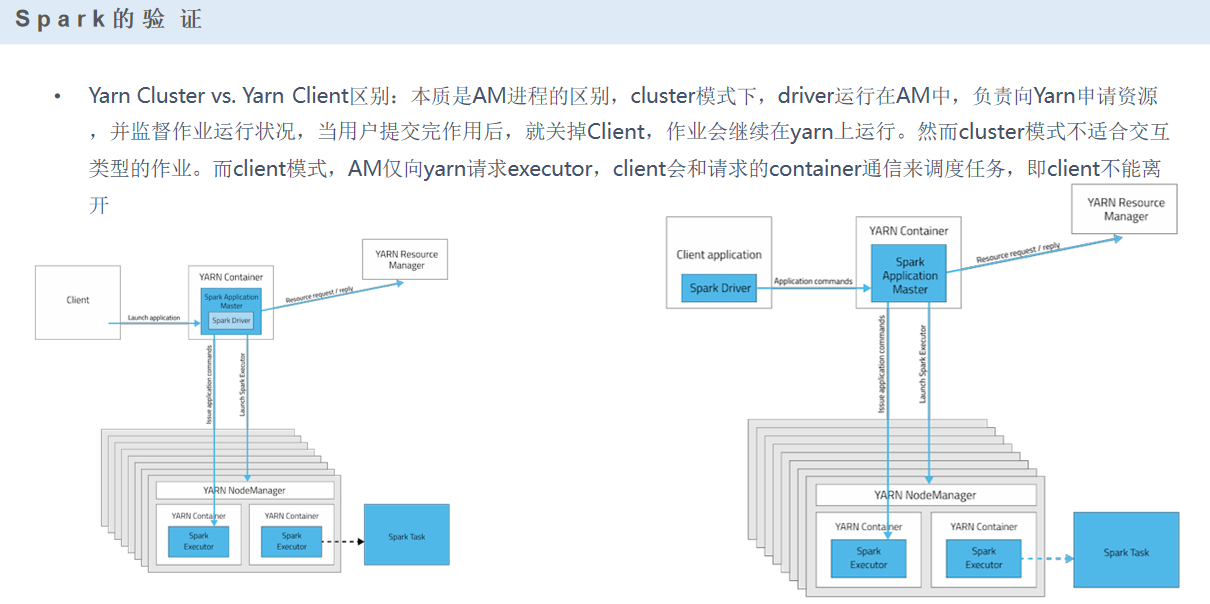
如何判断是哪种模式,就看任务在哪:
yarn-cluster模式: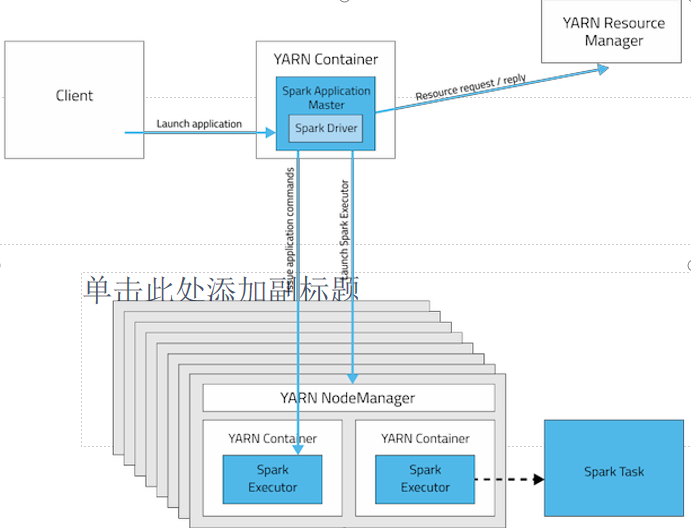
yarn-client模式: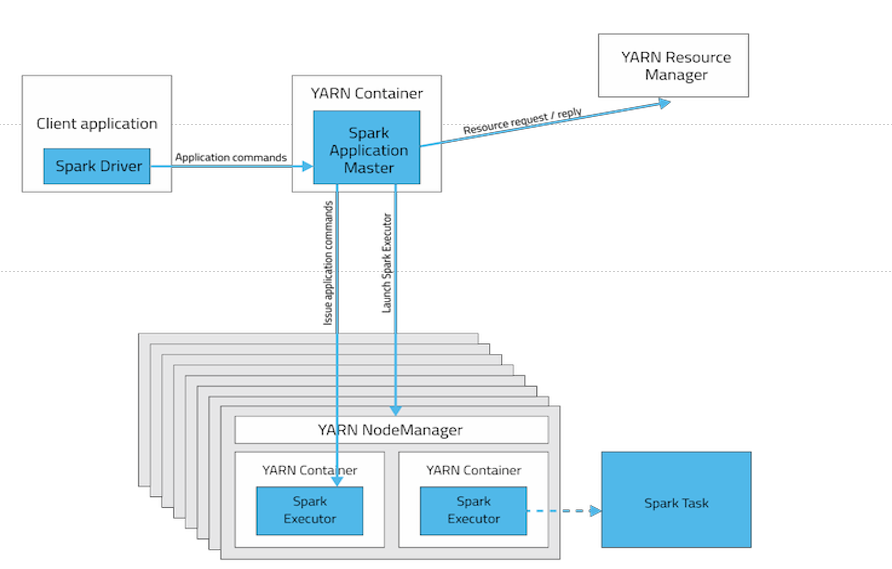
yarn-client模式更适合调试:
因为任务在本地跑,有一些log日志输出可以实时的在终端反馈。

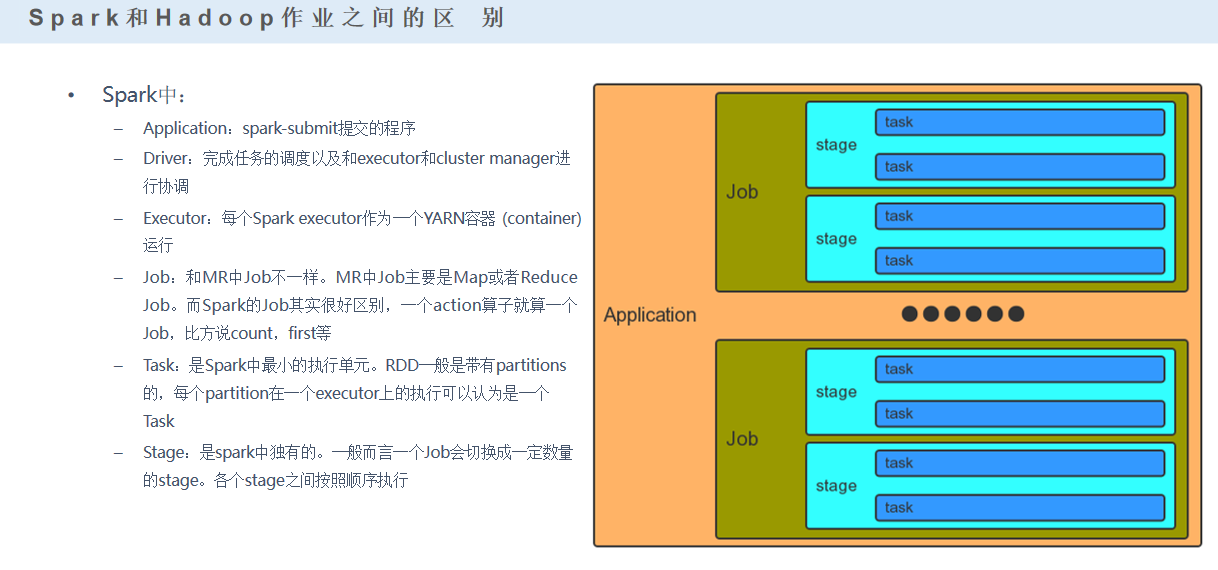
在spark的app里面,是通过action来区分不同的job的
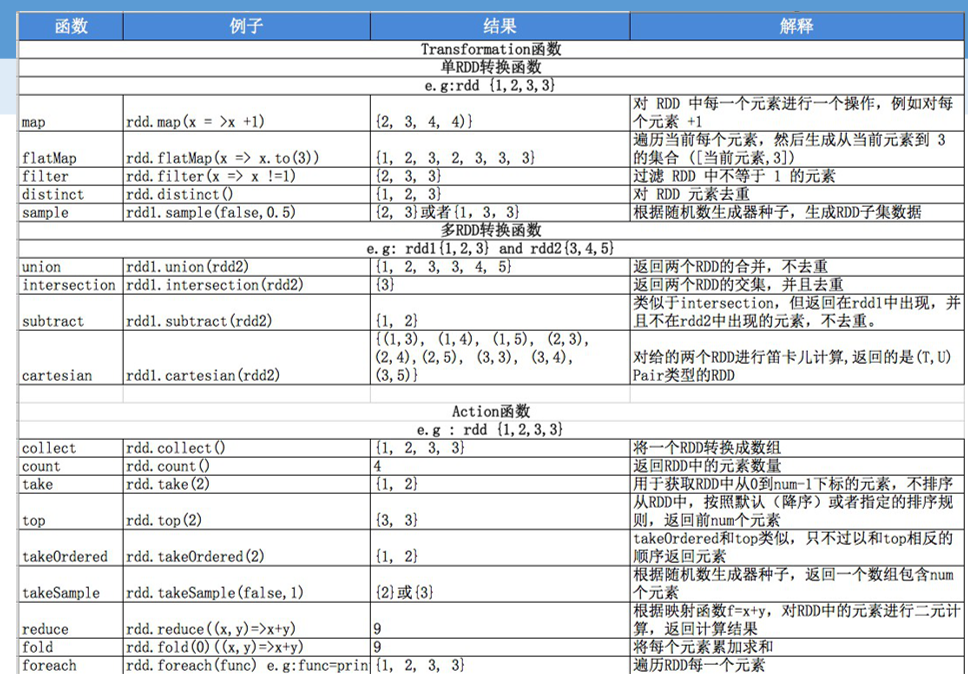
算子分为两类:action(行动算子)、transformation(转换算子)
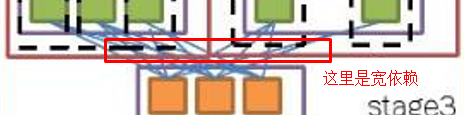
job里面stage是通过shuffle来区分的(窄依赖、宽依赖)
stage里包含多个task(线程)
spark任务是多线程模型,Mapreduce是多进程模型
用赊账来理解:中间过程就是转换,结尾就是一个action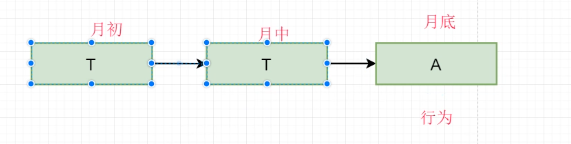

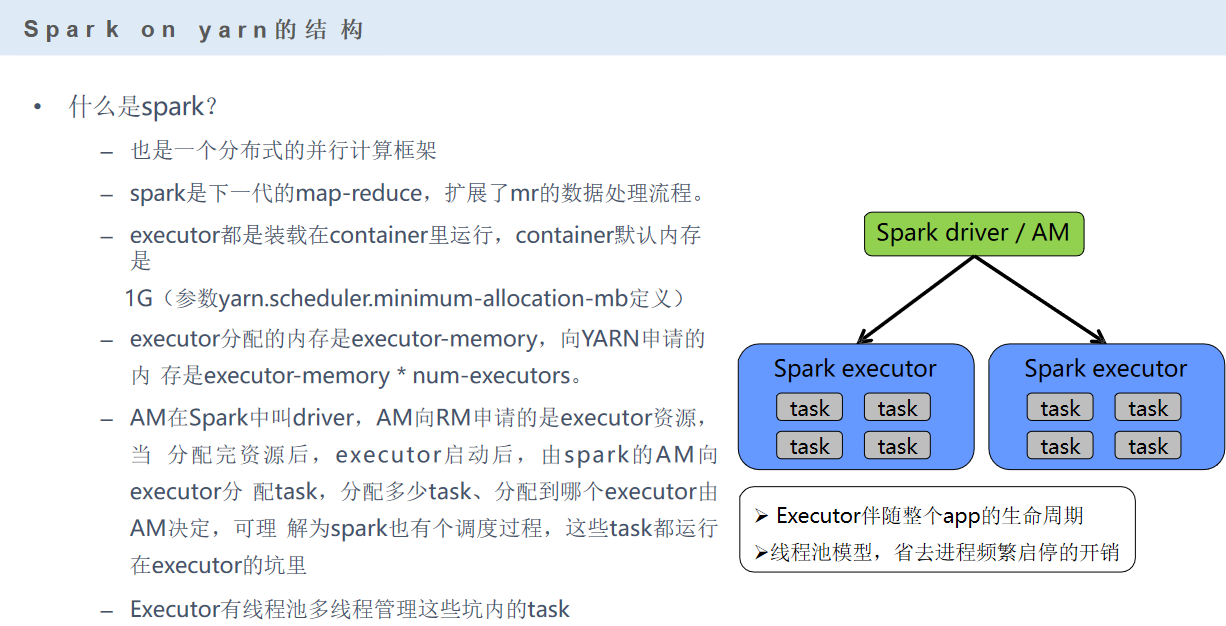
spark中task是线程,那么线程的启动就需要进程来实现,这个线程就是executor
一个executor包包含着线程池。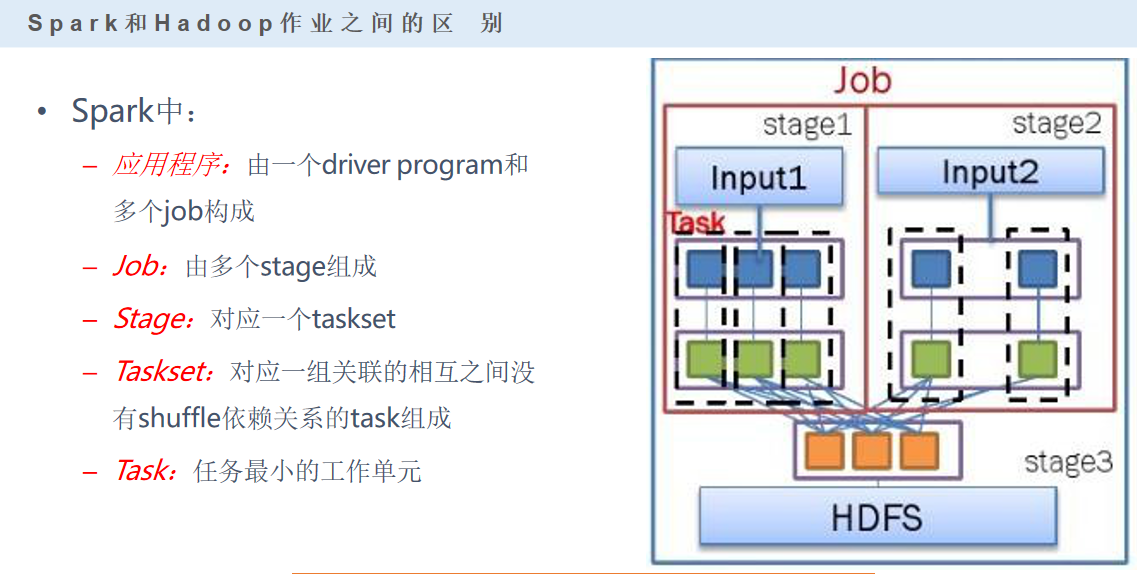

DAG是有向无环图
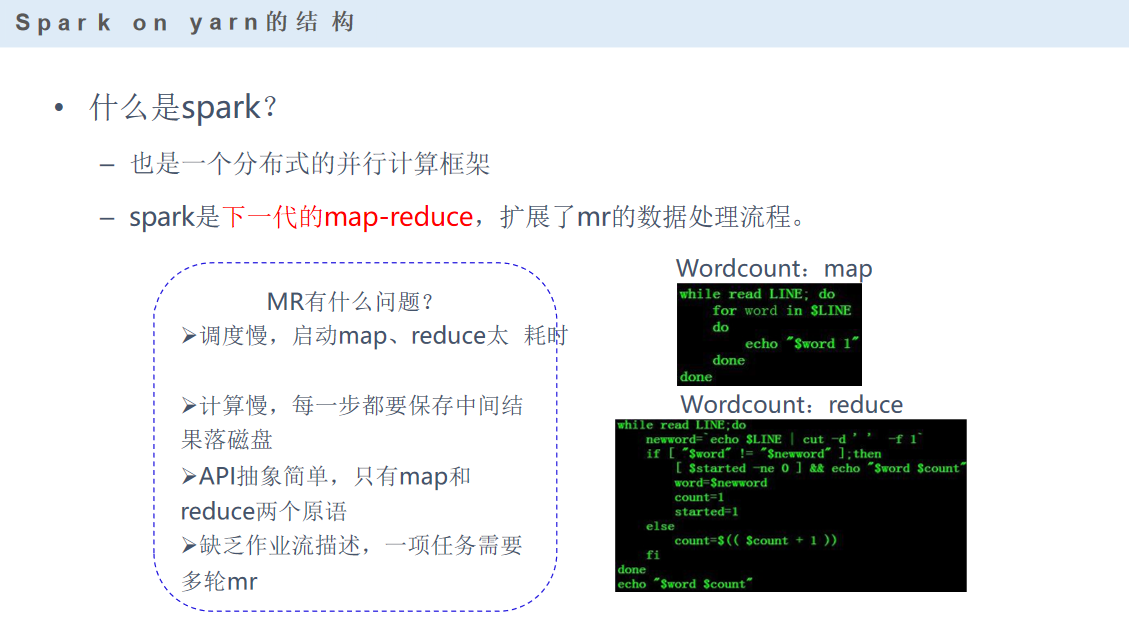
mapreduce为什么会慢,是因为在中间的环节数据会落地,具体就是在map阶段。
启动spark要涉及一些参数: executor-memory:每个executor内存多大 num-executors:多少个executor进程 executor-cores:每个exector进程,虚拟core cpu资源
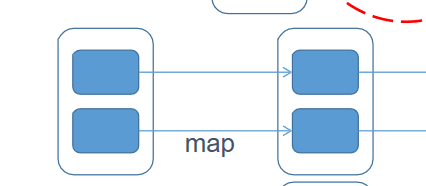
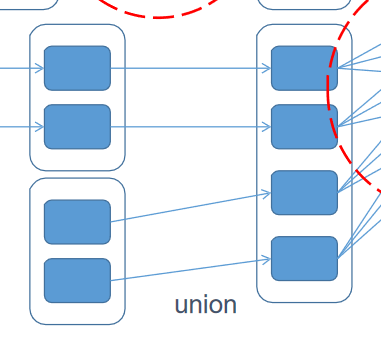
算子分为两种: (1)Transformation(转换算子)——转换并不是触发提交,完成作业中间过程处理 延迟计算——懒惰机制 算子细分: a)一对一:map、flatmap b)多对一:union、cartesian c)多对多:groupby d)输出是否是输入子集合:filter、distinct e)cache类:cache、persist(cache是persist中的一种特殊形式)
f)聚集: reduceByKey、combineByKey、PartitionBy
g)连接: join、leftOutJoin、rightOutJoin
(2)Action(行为算子)——触发(sparkcontext:sc)作业,可以将结果输出hdfs、hbase、kafka、console
a)无输出:foreach
b)有输出:saveAsTextFile
c)统计类:count、collect、take
算子细分:
一对一:
多对一:
多对多:

RDD——弹性分布式数据集 RDD是什么?(RDD不是数据,RDD也不存数据,只存储数据的分区信息和读取方法(HDFS、其他RDD)) 1)弹性: a)内存和磁盘之间会同步数据 b)RDD可以变成另一个RDD c)RDD内部存储数据类型丰富 2)依赖(向上依赖) a)顶部RDD——数据源 b)非顶部RDD:记录自己来源于谁——血统(lineage) 宽依赖、窄依赖: 窄依赖:以流水线的方式计算分区 宽依赖:必须计算好父分区的数据,然后进行shuffle 失效问题处理: 窄依赖:只需要计算丢失RDD分区的父分区,不同节点可以并行 宽依赖:单点失效了,可能导致整个RDD所有祖先丢失的分区重新计算 3)怎么读取? a)有存储级别:判断是否有缓存,缓存-磁盘 b)无存储级别:直接磁盘读



 浙公网安备 33010602011771号
浙公网安备 33010602011771号