sendfile“零拷贝”、mmap内存映射、DMA
KAFKA推送消息用到了sendfile,落盘技术用到了mmap,DMA贯穿其中。
DMA(Direct Memory Access)
直接存储器访问,DMA技术就是我们在主板上放⼀块独立的芯片。在进行内存和I/O设备的数据传输的时候,我们不再通过CPU来控制数据传输,而直接通过 DMA控制器(DMA Controller,简称DMAC)。这块芯片,我们可以认为它其实就是一个协处理器(Co-Processor))
为什么Kafka这么快
kafka作为MQ也好,作为存储层也好,无非是两个重要功能,一是Producer生产的数据存到broker,二是 Consumer从broker读取数据;我们把它简化成如下两个过程:
1、网络数据持久化到磁盘 (Producer 到 Broker)
2、磁盘文件通过网络发送(Broker 到 Consumer)
下面,先给出“kafka用了磁盘,还速度快”的结论
1、顺序读写
磁盘顺序读或写的速度400M/s,能够发挥磁盘最大的速度。
随机读写,磁盘速度慢的时候十几到几百K/s。这就看出了差距。
kafka将来自Producer的数据,顺序追加在partition,partition就是一个文件,以此实现顺序写入。
Consumer从broker读取数据时,因为自带了偏移量,接着上次读取的位置继续读,以此实现顺序读。
顺序读写,是kafka利用磁盘特性的一个重要体现。
2、零拷贝 sendfile(in,out)
数据直接在内核完成输入和输出,不需要拷贝到用户空间再写出去。
kafka数据写入磁盘前,数据先写到进程的内存空间。
3、mmap文件映射
虚拟映射只支持文件;
在进程 的非堆内存开辟一块内存空间,和OS内核空间的一块内存进行映射,
kafka数据写入、是写入这块内存空间,但实际这块内存和OS内核内存有映射,也就是相当于写在内核内存空间了,且这块内核空间、内核直接能够访问到,直接落入磁盘。
这里,我们需要清楚的是:内核缓冲区的数据,flush就能完成落盘。
我们来重点探究 kafka两个重要过程、以及是如何利用两个零拷贝技术sendfile和mmap的。
网络数据持久化到磁盘 (Producer 到 Broker)
传统方式实现:
先接收生产者发来的消息,再落入磁盘。
数据落盘通常都是非实时的,kafka生产者数据持久化也是如此。Kafka的数据并不是实时的写入硬盘,它充分利用了现代操作系统分页存储来利用内存提高I/O效率。
对于kafka来说,Producer生产的数据存到broker,这个过程读取到socket buffer的网络数据,其实可以直接在OS内核缓冲区,完成落盘。并没有必要将socket buffer的网络数据,读取到应用进程缓冲区;在这里应用进程缓冲区其实就是broker,broker收到生产者的数据,就是为了持久化。
在此特殊场景下:接收来自socket buffer的网络数据,应用进程不需要中间处理、直接进行持久化时。——可以使用mmap内存文件映射。
MMAP(Memory Mapped Files)
简称mmap,简单描述其作用就是:将磁盘文件映射到内存, 用户通过修改内存就能修改磁盘文件。
它的工作原理是直接利用操作系统的Page来实现文件到物理内存的直接映射。完成映射之后你对物理内存的操作会被同步到硬盘上(操作系统在适当的时候)。
通过mmap,进程像读写硬盘一样读写内存(当然是虚拟机内存),也不必关心内存的大小有虚拟内存为我们兜底。
使用这种方式可以获取很大的I/O提升,省去了用户空间到内核空间复制的开销。
mmap也有一个很明显的缺陷——不可靠,写到mmap中的数据并没有被真正的写到硬盘,操作系统会在程序主动调用flush的时候才把数据真正的写到硬盘。Kafka提供了一个参数——producer.type来控制是不是主动flush;如果Kafka写入到mmap之后就立即flush然后再返回Producer叫同步(sync);写入mmap之后立即返回Producer不调用flush叫异步(async)。
Java NIO对文件映射的支持
Java NIO,提供了一个 MappedByteBuffer 类可以用来实现内存映射。
MappedByteBuffer只能通过调用FileChannel的map()取得,再没有其他方式。
FileChannel.map()是抽象方法,具体实现是在 FileChannelImpl.c 可自行查看JDK源码,其map0()方法就是调用了Linux内核的mmap的API。
使用 MappedByteBuffer类要注意的是:mmap的文件映射,在full gc时才会进行释放。当close时,需要手动清除内存映射文件,可以反射调用sun.misc.Cleaner方法。
磁盘文件通过网络发送(Broker 到 Consumer)
传统方式实现:
先读取磁盘、再用socket发送,实际也是进过四次copy。
而 Linux 2.4+ 内核通过 sendfile 系统调用,提供了零拷贝。磁盘数据通过 DMA 拷贝到内核态 Buffer 后,直接通过 DMA 拷贝到 NIC Buffer(socket buffer),无需 CPU 拷贝。这也是零拷贝这一说法的来源。除了减少数据拷贝外,因为整个读文件 - 网络发送由一个 sendfile 调用完成,整个过程只有两次上下文切换,因此大大提高了性能。零拷贝过程如下图所示。
相比于文章开始,对传统IO 4步拷贝的分析,sendfile将第二次、第三次拷贝,一步完成。
其实这项零拷贝技术,直接从内核空间(DMA的)到内核空间(Socket的)、然后发送网卡。
应用的场景非常多,如Tomcat、Nginx、Apache等web服务器返回静态资源等,将数据用网络发送出去,都运用了sendfile。
简单理解 sendfile(in,out)就是,磁盘文件读取到操作系统内核缓冲区后、直接扔给网卡,发送网络数据。
Java NIO对sendfile的支持就是FileChannel.transferTo()/transferFrom()。
fileChannel.transferTo( position, count, socketChannel);
把磁盘文件读取OS内核缓冲区后的fileChannel,直接转给socketChannel发送;底层就是sendfile。消费者从broker读取数据,就是由此实现。
具体来看,Kafka 的数据传输通过 TransportLayer 来完成,其子类 PlaintextTransportLayer 通过Java NIO 的 FileChannel 的 transferTo 和 transferFrom 方法实现零拷贝。
注: transferTo 和 transferFrom 并不保证一定能使用零拷贝。实际上是否能使用零拷贝与操作系统相关,如果操作系统提供 sendfile 这样的零拷贝系统调用,则这两个方法会通过这样的系统调用充分利用零拷贝的优势,否则并不能通过这两个方法本身实现零拷贝。
Kafka总结
总的来说Kafka快的原因:
1、partition顺序读写,充分利用磁盘特性,这是基础;
2、Producer生产的数据持久化到broker,采用mmap文件映射,实现顺序的快速写入;
3、Customer从broker读取数据,采用sendfile,将磁盘文件读到OS内核缓冲区后,直接转到socket buffer进行网络发送。
mmap 和 sendfile总结
1、都是Linux内核提供、实现零拷贝的API;
2、sendfile 是将读到内核空间的数据,转到socket buffer,进行网络发送;
3、mmap将磁盘文件映射到内存,支持读和写,对内存的操作会反映在磁盘文件上。
RocketMQ 在消费消息时,使用了 mmap。kafka 使用了 sendFile。
关于DMA
为什么那么快?一起来看Kafka的实现原理
1、它究竟是怎么利用DMA的?
Kafka是一个用来处理实时数据的管道,我们常常用它来做一个消息队列,或者用来收集和落地海量的日志。作为一个处理实时数据和日志的管道,瓶颈自然也在I/O层面。
2、Kafka里面两种常用的海量数据传输的情况是什么?
Kafka里面会有两种常用的海量数据传输的情况。一种是从网络络中接收上游的数据,然后需要落地到本地的磁盘上,确保数据不丢失。
另一种情况呢,则是从本地磁盘上读取出来,通过网络发送出去。
我们来看一看后一种情况,从磁盘读数据发送到网络上去。如果我们自己写一个简单的程序,最直观的办法,自然是用个一件读操作,从磁盘上把数据读到内存里面来,
然后再用个Socket,把这些数据发送到网络上去。

3、我们只是要“搬运”一份数据,结果却整整搬运了四次
在这个过程中,数据一共发生了四次传输的过程。其中两次是DMA的传输,另外两次,则是通过CPU控制的传输。下面我们来具体看看这个过程。
第一次传输,是从硬盘上,读到操作系统内核的缓冲区里。这个传输是通过DMA搬运的。
第二次传输,需要从内核缓冲区里面的数据,复制到我们应用分配的内存里面。这个传输是通过CPU搬运的。
第三次传输,要从我们应用的内存里面,再写到操作系统的Socket的缓冲区里面去。这个传输,还是由CPU搬运的。
最后一次传输,需要再从Socket的缓冲区里面,写到网卡的缓冲区里面去。这个传输又是通过DMA搬运的。
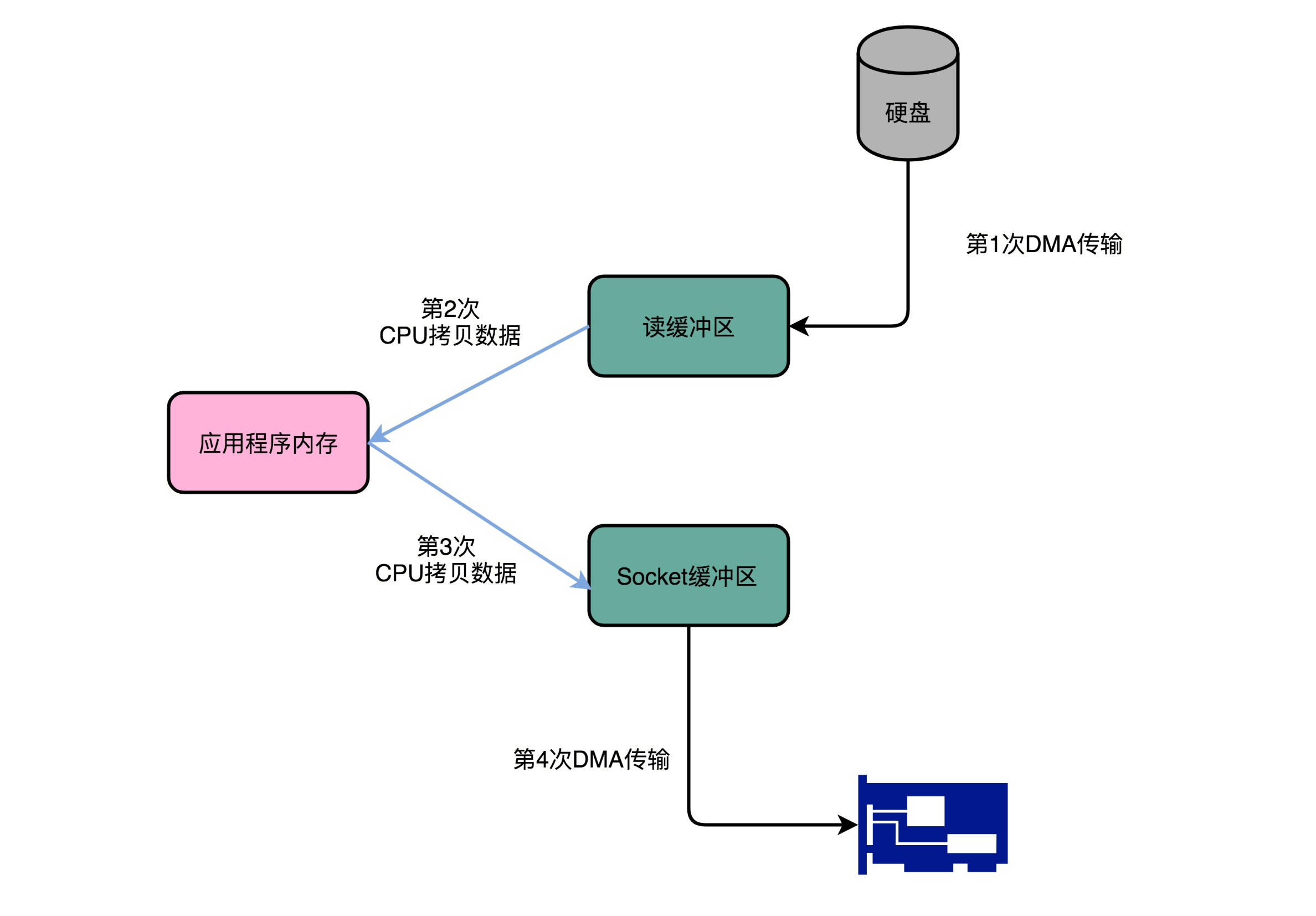
这个时候,你可以回过头看看这个过程。我们只是要“搬运”⼀份数据,结果却整整搬运了四次。而且这里面,从内核的读缓冲区传输到应用的内存里,
再从应用的内存里传输到Socket的缓冲区里,其实都是把同一份数据在内存里面搬运来搬运去,特别没有效率。
4、我们就需要尽可能地减少数据搬运的需求
像Kafka这样的应用场景,其实一部分最终利用到的硬件资源,其实又都是在干这个搬运数据的事儿。所以,我们就需要尽可能地减少数据搬运的需求。
事实上,Kafka做的事情就是,把这个数据搬运的次数,从上面的四次,变成了两次,并且只有DMA来进行数据搬运,而不需要CPU。

Kafka的代码调用了Java NIO库,具体是FileChannel里面的transferTo方法。我们的数据并没有读到中间的应用内存里面,而是直接通过Channel,写入到对应的网络设备里。
并且,对于Socket的操作,也不是写入到Socket的Buffer里面,而是直接根据描述符(Descriptor)写到到网卡的缓冲区里面。于是,在这个过程之中,我们只进行了两次数据传输。
5、同一份数据传输的次数从四次变成了两次
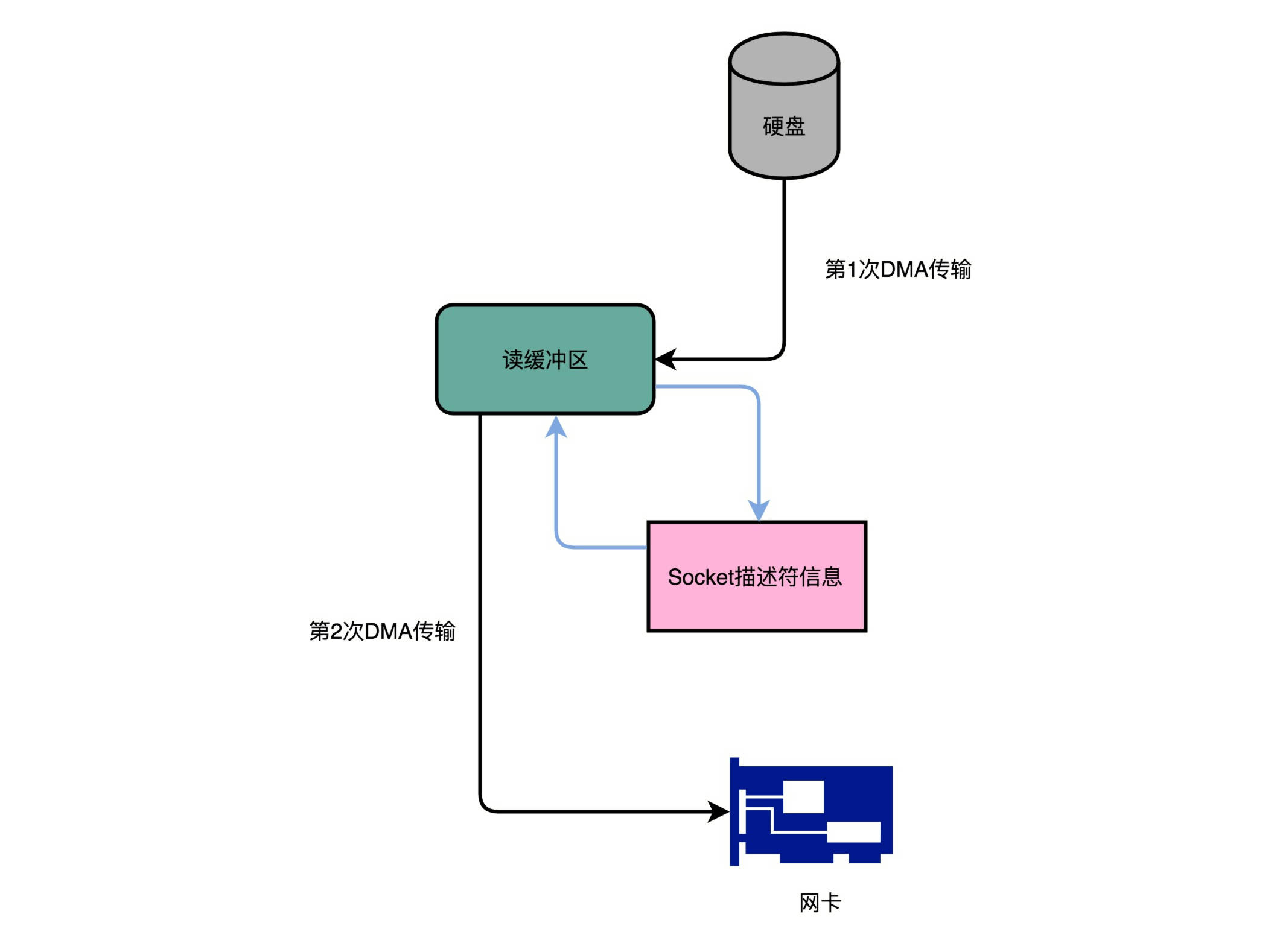
第一次,是通过DMA,从硬盘直接读到操作系统内核的读缓冲区里面。第二次,则是根据Socket的描述符信息,直接从读缓冲区里面,写入到网卡的缓冲区里面。
这样,我们同一份数据传输的次数从四次变成了两次,并且没有通过CPU来进行数据搬运,所有的数据都是通过DMA来进行传输的。
6、什么是零拷贝?
在这个方法里面,我们没有在内存层面去“复制(Copy)”数据,所以这个方法,也被称之为零拷贝(Zero-Copy)。IBM Developer Works里面有一篇文章,专们写过程序来测试过在同样的硬件下,使用零拷贝能够带来的性能提升。我在这里放上这篇文章链接。在这篇文章最后,你可以看到,无论传输数据量的大小,传输同样的数据,使用了零拷贝能够缩短65%的时间,大幅度提升了机器传输数据的吞吐量。想要深入了解零拷贝,建议你可以仔细读读读这篇文章。
DMA总结
讲到这里,相信你对DMA的原理、作用和效果都有所理解了。那么,我们⼀起来回顾总结一下。、
如果我们始终让CPU来进行各种数据传输工作,会特别浪费。一方面,我们的数据传输工作用不到多少CPU核新的“计算”功能。另一方面,CPU的运转速度也比I/O操作要快很多。
所以,我们希望能够给CPU“减负”。
于是,工程师们就在主板上放上了DMAC这样一个协处理器芯片。通过这个芯片,CPU只需要告诉DMAC,我们要传输什么数据,从哪里来,到哪里去,就可以放心离开了。
后续的实际数据传输工作,都会有DMAC来完成。随着现代计算机各种外设硬件越来越多,光一个通用的DMAC芯片不够了,我们在各个外设上都加上了DMAC芯片,
使得CPU很少再需要关注数据传输的工作了。
在我们实际的系统开发过程中,利用好DMA的数据传输机制,也可以大幅提升I/O的吞吐率。最典型的例子就是Kafka。
传统地从硬盘读取数据,然后再通过网卡上向外发送,我们需要进行四次数据传输,其中有两次是发生在内存里的缓冲区和对应的硬件设备之间,我们没法节省掉。
但是还有两次,完全是通过CPU在内存里面进行数据复制。
在Kafka里,通过Java的NIO里面FileChannel的transferTo方法调用,我们可以不用把数据复制到我们应用程序的内存里面。通过DMA的方式,
我们可以把数据从内存缓冲区直接写到网卡的缓冲区里面。在使用了这样的零拷贝的方法之后呢,我们传输同样数据的时间,可以缩减为原来的1/3,相当于提升了3倍的吞吐率。
这也是为什么,Kafka是目前实时数据传输管道的标准解决方案

 浙公网安备 33010602011771号
浙公网安备 33010602011771号