Hibernate4教程六:性能提升和二级缓存
抓取策略(fetching strategy)是指:当应用程序需要在(Hibernate实体对象图的)关联关系间进行导航的时候,Hibernate如何获取关联对象的策略。抓取策略可以在O/R映射的元数据中声明,也可以在特定的HQL或条件查询(Criteria Query)中重载声明。 Hibernate4 定义了如下几种抓取策略:
1:连接抓取(Join fetching) - Hibernate通过 在SELECT语句使用OUTER JOIN(外连接)来 获得对象的关联实例或者关联集合。
2:查询抓取(Select fetching) - 另外发送一条 SELECT语句抓取当前对象的关联实体或集合。除非你显式的指定lazy="false"禁止 延迟抓取,否则只有当真正访问关联关系的时候,才会执行第二条select语句。
3:子查询抓取(Subselect fetching) - 另外发送一条SELECT语句抓取在前面查询到(或者抓取到)的所有实体对象的关联集合。除非你显式的指定lazy="false" 禁止延迟抓取否则只有当你真正访问关联关系的时候,才会执行第二条select语句。
4:批量抓取(Batch fetching) - 对查询抓取的优化方案, 通过指定一个主键或外键列表,Hibernate使用单条SELECT语句获取一批对象实例或集合。
映射文档中定义的抓取策略将会对以下列表条目产生影响:
(1)通过 get() 或 load() 方法取得数据。
(2)只有在关联之间进行导航时,才会隐式的取得数据。
(3)条件查询
(4)使用了subselect 抓取的 HQL 查询
通常情况下,我们并不使用映射文档进行抓取策略的定制。更多的是,保持其默认值,然后在特定的事务中, 使用 HQL 的左连接抓取(left join fetch) 对其进行重载。这将通知 Hibernate在第一次查询中使用外部关联(outer join),直接得到其关联数据。
条件查询API 中,应该调用 setFetchMode语句,例如:
java代码:
- User user = (User) session.createCriteria(User.class)
- .setFetchMode("permissions", FetchMode.JOIN)
- .add( Restrictions.idEq(userId) )
- .uniqueResult();
Hibernate会区分下列各种情况:
1:Immediate fetching,立即抓取
- 当宿主被加载时,关联、集合或属性被立即抓取。
2:Lazy collection fetching,延迟集合抓取- 直到应用程序对集合进行了一次操作时,集合才被抓取。(对集合而言这是默认行为。)
3:"Extra-lazy" collection fetching,"Extra-lazy"集合抓取
-对集合类中的每个元素而言,都是直到需要时才去访问数据库。除非绝对必要,Hibernate不会试图去把整个集合都抓取到内存里来(适用于非常大的集合)。
4:Proxy fetching,代理抓取
- 对返回单值的关联而言,当其某个方法被调用,而非对其关键字进行get操作时才抓取。
5:"No-proxy" fetching,非代理抓取
- 对返回单值的关联而言,当实例变量被访问的时候进行抓取。与上面的代理抓取相比,这种方法没有那么“延迟”得厉害(就算只访问标识符,也会导致关联抓取)但是更加透明,因为对应用程序来说,不再看到proxy。这种方法需要在编译期间进行字节码增强操作,因此很少需要用到。
6:Lazy attribute fetching,属性延迟加载
- 对属性或返回单值的关联而言,当其实例变量被访问的时候进行抓取。需要编译期字节码强化,因此这一方法很少用到。
何时实例化集合和代理
既然Hibernate会采取代理来延迟集合的实例化,那么何时实例化这个集合呢?因为如果session关闭了,再访问未初始化的集合活代理的话,将会抛出LazyInitializationException 异常。
常见的解决方法,如下:
在session打开期间去访问集合的数据
这是一种不好的做法,就是没有什么用的去访问集合的数据,触发其实例化
使用Hibernate.initialized()方法
静态方法 Hibernate.initialized() 为你的应用程序提供了一个便捷的途径来延迟加载集合或代理。 只要它的Session 处于open 状态,Hibernate.initialize(cat) 将会为cat 强制对代理实例化。同样,Hibernate.initialize(cat.getKittens())对kittens的集合具有同样的功能。
保持Session一直处于open状态,直到集合被实例化
通常又有两种方法:
Open Session in View模式
![]()
![]()
http://sishuok.com/forum/blogPost/list/2482.html
在一个基于Web的应用中,可以利用过滤器,在用户请求时打开Hibernate的session、页面生成结束时关闭 Session,示例如下:
java代码:
- public class HibernateSessionRequestFilter implements Filter {
- private SessionFactory sf;
- public void doFilter(...)throws...{
- sf.getCurrentSession().beginTransaction();
- chain.doFilter(request, response);
- sf.getCurrentSession().getTransaction().commit();
- }
- public void init(FilterConfig filterConfig) throws ServletException {
- sf = new Configuration().configure().buildSessionFactory();
- }
- public void destroy() {}
- }
在逻辑层为表现层准备数据的时候,在session打开的情况下,实例化好所有需要的数据。
要完全理解Hibernate各种集合的关系结构和性能特点,必须同时考虑“用于Hibernate更新或删除集合行数据的主键的结构”。 因此得到了如下的分类:
有序集合类、集合(sets)、包(bags): 可以重复且没有顺序的一种集合
所有的有序集合类(maps, lists, arrays)都拥有一个由<key>和<index>组成的主键。 这种情况下集合类的更新是非常高效的——主键已经被有效的索引,因此当Hibernate试图更新或删除一行时,可以迅速找到该行数据
集合(sets)的主键由<key>和其他元素组成。对于有些元素来说,这很低效,特别是组合元素,大文本或二进制数据。但是对于一对多或者多对多,set也可以达到同样的高效性能
Bag是最差的。因为bag允许重复的元素值,也没有索引字段,因此不可能定义主键。 Hibernate无法判断出重复的行。当这种集合被更改时,Hibernate将会先完整地移除 (通过一个(in a single DELETE))整个集合,然后再重新创建整个集合。 因此Bag是非常低效的。
Lists, maps 和sets用于更新效率最高
1:有序集合类型和大多数set都可以在增加、删除、修改元素中拥有最好的性能。
2:在多对多中,set性能不如有序集合类型
3:Hibernate中,set应该是最通用的集合类型
Bag和list是反向集合类(也就是指定了inverse=true的集合类)中效率最高的
在一种情况下,bag的性能(包括list)要比set高得多: 对于指明了inverse="true"的集合类(比如说,标准的双向的一对多关联), 我们可以在未初始化(fetch)包元素的情况下直接向bag或list添加新元素! 这是因为Collection.add())或者Collection.addAll() 方法 对bag或者List总是返回true(这点与与Set不同)。因此对于下面的相同代码来说,速度会快得多。
java代码:
- Parent p = (Parent) sess.load(Parent.class, id);
- Child c = new Child();
- c.setParent(p);
- p.getChildren().add(c); //不用抓取集合
- sess.flush();
SessionFactory里面带着监测性能的数据,就是Statistics
首先需要在cfg.xml中打开统计功能,将 hibernate.generate_statistics 设置为 true。在运行期间,则可以可以通过 sf.getStatistics().setStatisticsEnabled(true) 或hibernateStatsBean.setStatisticsEnabled(true)来打开统计功能
所有的测量值都可以由 Statistics 接口 API 进行访问,主要分为三类:
1:使用 Session 的普通数据记录,例如打开的 Session 的个数、取得的 JDBC 的连接数等;
2:实体、集合、查询、缓存等内容的统一数据记录。
3:和具体实体、集合、查询、缓存相关的详细数据记录
Hibernate的Session在事务级别进行持久化数据的缓存操作,也就是前边所讲的一级缓存
当然,也可以分别为每个类(或集合),配置集群、或JVM级别(SessionFactory级别)的缓存(二级缓存)
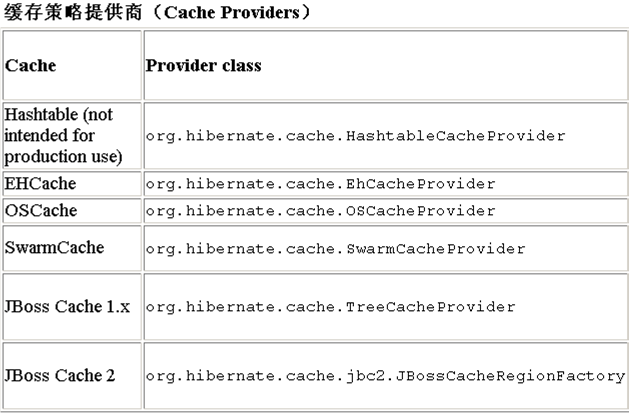
在Hibernate4以前的版本:通过在hibernate.cache.provider_class属性中指定org.hibernate.cache.CacheProvider的某个实现的类名,你可以选择让Hibernate使用哪个缓存实现。注意,在3.2版本之前,默认使用EhCache 作为缓存实现,但从3.2起就不再这样了。如:<property name="cache.provider_class">org.hibernate.cache.EhCacheProvider</property>
在Hibernate4的版本中:通过在cache.region.factory_classs指定相应的缓存区域的实现,如:
java代码:
- <property name="cache.region.factory_class">org.hibernate.cache.EhCacheRegionFactory</property>
缓存映射,类或者集合映射的“<cache>元素”可以有下列形式:
java代码:
- <cache
- usage="transactional|read-write|nonstrict-read-write|read-only" (1)
- region="RegionName" (2)
- include="all|non-lazy" (3) />
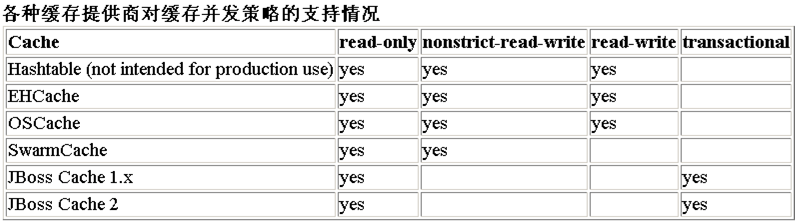
(1)usage(必须)说明了缓存的策略: transactional、 read-write、 nonstrict-read-write或 read-only。
(2) region (可选, 默认为类或者集合的名字) 指定第二级缓存的区域名
(3) include (可选,默认为 all) non-lazy 当属性级延迟抓取打开时, 标记为lazy="true"的实体的属性可能无法被缓存
可以在hibernate.cfg.xml 中指定<class-cache>和<collection-cache>元素
策略:只读缓存
如果你的应用程序只需读取一个持久化类的实例,而无需对其修改, 那么就可以对其进行只读 缓存。这是最简单,也是实用性最好的方法。甚至在集群中,它也能完美地运作。示例如下:
java代码:
- <class name="eg.Immutable" mutable="false">
- <cache usage="read-only"/>
- ....
- </class>
策略:读写缓存
如果应用程序需要更新数据,那么使用读/写缓存 比较合适。 如果应用程序要求
“serializable”的隔离级别,那么就决不能使用这种缓存策略。 如果在JTA环境中使用缓
存,必须指定hibernate.transaction.manager_lookup_class属性的值, 通过它,Hibernate
才能知道该应用程序中JTA的TransactionManager的具体策略。 在其它环境中,你必须保证在
Session.close()、或Session.disconnect()调用前, 整个事务已经结束。 如果你想在集群
环境中使用此策略,你必须保证底层的缓存实现支持锁定(locking)。Hibernate内置的缓存策
略并不支持锁定功能。
java代码:
- <class name="eg.Cat" .... >
- <cache usage="read-write"/>
- <set name="kittens" ... >
- <cache usage="read-write"/>
- ....
- </set>
- </class>
策略:非严格读写缓存Strategy: nonstrict read/write)
如果应用程序只偶尔需要更新数据(也就是说,两个事务同时更新同一记录的情
况很不常见),也不需要十分严格的事务隔离, 那么比较适合使用非严格读/写缓
存策略。如果在JTA环境中使用该策略, 你必须为其指定
hibernate.transaction.manager_lookup_class属性的值, 在其它环境中,你必须
保证在Session.close()、或Session.disconnect()调用前, 整个事务已经结束
策略:事务缓存
Hibernate的事务缓存策略提供了全事务的缓存支持, 例如对JBoss TreeCache
的支持。这样的缓存只能用于JTA环境中,你必须指定 为其
hibernate.transaction.manager_lookup_class属性
管理缓存
1:无论何时,当你给save()、update()或 saveOrUpdate()方法传递一个对象时,或使用load()、 get()、list()、iterate() 或scroll()方法获得一个对象时, 该对象都将被加入到Session的内部缓存中。
2:当随后flush()方法被调用时,对象的状态会和数据库取得同步。如果你不希望此同步操作发生,或者你正处理大量对象、需要对有效管理内存时,你可以调用evict() 方法,从一级缓存中去掉这些对象及其集合,如下示例:
ScrollableResult cats = sess.createQuery(“from Cat as cat”).scroll(); //很大的结果集,可滚动的结果集
while ( cats.next() ) {
Cat cat = (Cat) cats.get(0);
doSomethingWithACat(cat);
sess.evict(cat);
}
3:Session还提供了一个contains()方法,用来判断某个实例是否处于当前session的缓存中。
4:如若要把所有的对象从session缓存中彻底清除,则需要调用Session.clear()。
5:对于二级缓存来说,在SessionFactory中定义了许多方法,清除缓存中实例、整个类、集合实例或者整个集合。
java代码:
- sessionFactory.evict(Cat.class, catId); //evict a particular Cat
- sessionFactory.evict(Cat.class); //evict all Cats
- sessionFactory.evictCollection(“Cat.kittens”, catId); //evict a particular collection of kittens
- sessionFactory.evictCollection(“Cat.kittens”); //evict all kitten
6:collections CacheMode参数用于控制具体的Session如何与二级缓存进行交互。
(1)CacheMode.NORMAL - 从二级缓存中读、写数据。
(2)CacheMode.GET - 从二级缓存读取数据,仅在数据更新时对二级缓存写数据。
(3)CacheMode.PUT - 仅向二级缓存写数据,但不从二级缓存中读数据。
(4)CacheMode.REFRESH - 仅向二级缓存写数据,但不从二级缓存中读数据。通过hibernate.cache.use_minimal_puts的设置,强制二级缓存从数据库中读取数据,刷新缓存内容。
查询缓存:查询的结果集也可以被缓存。只有当经常使用同样的参数进行查询时,这才会有些用处
1:要使用查询缓存,首先你必须打开hibernate.cache.use_query_cache为true.
2:该设置将会创建两个缓存区域 - 一个用于保存查询结果集(org.hibernate.cache.StandardQueryCache); 另一个则用于保存最近查询的一系列表的时间戳(org.hibernate.cache.UpdateTimestampsCache)。 请注意:在查询缓存中,它并不缓存结果集中所包含的实体的确切状态;它只缓存这些实体的标识符属性的值、以及各值类型的结果。 所以查询缓存通常会和二级缓存一起使用。
3:绝大多数的查询并不能从查询缓存中受益,所以Hibernate默认是不进行查询缓存的。如若需要进行缓存,请调用 Query.setCacheable(true)方法。这个调用会让查询在执行过程中时先从缓存中查找结果,并将自己的结果集放到缓存中去
以EHCache为例来说明二级缓存的配置
第一步:配置ehcache.xml,放置到classpath下面,配置如下:
java代码:
- <?xml version="1.0" encoding="UTF-8"?>
- <ehcache>
- <diskStore path="java.io.tmpdir"/>
- <defaultCache
- maxElementsInMemory="10000"
- eternal="false"
- timeToIdleSeconds="120"
- timeToLiveSeconds="120"
- overflowToDisk="true"
- />
- </ehcache>
配置说明:
maxElementsInMemory :缓存最大数目
eternal :缓存是否持久
overflowToDisk : 是否保存到磁盘,当系统当机时
timeToIdleSeconds :当缓存闲置n秒后销毁
timeToLiveSeconds :当缓存存活n秒后销毁
第二步:在hibernate.cfg.xml中设置:
Hibernate4以前的版本:
java代码:
- <property name="hibernate.cache.use_second_level_cache">true</property>
- <property name="cache.provider_class">org.hibernate.cache.EhCacheProvider</property>
- <property name="cache.use_query_cache">false</property>
Hibernate4的版本:
java代码:
- <property name="cache.use_query_cache">false</property>
- <property name="cache.use_second_level_cache">true</property>
- <property name="cache.region.factory_class">org.hibernate.cache.EhCacheRegionFactory</property>
第三步:在hibernate.cfg.xml中设置需要缓存的类,还有缓存策略.
<class-cache class="cn.javass.h3.hello.UserModel" usage="read-only"/>
在测试文件中,如下:
java代码:
- s = sf.openSession();
- t = s.beginTransaction();
- UserModel um1 = (UserModel)s.load(UserModel.class, "1");
- System.out.println("um1=="+um1);
- t.commit();
- s = sf.openSession();
- t = s.beginTransaction();
- UserModel um2 = (UserModel)s.load(UserModel.class, "1");
- System.out.println("um2=="+um2);
- t.commit();
- s = sf.openSession();
- t = s.beginTransaction();
- UserModel um3 = (UserModel)s.load(UserModel.class, "1");
- System.out.println("um3=="+um3);
- t.commit();
然后就可以运行测试文件,看看输出的sql语句,一共有多少条?一条查询语句才是正确的,因为缓存起了作用。尝试去掉缓存的配置,测试文件不动,再次运行,看看输出的sql语句,一共有多少条?应该是三条了。
说明:如果不设置“查询缓存”,那么hibernate只会缓存使用load()方法获得的单个持久化对象,如果想缓存使用findall()、list()、Iterator()、createCriteria()、createQuery()等方法获得的数据结果集的话,就需要设置hibernate.cache.use_query_cache true才行。
下面看看查询缓存的示例
第一步:配置ehcache.xml,跟前面相同
第二步:配置hibernate.cfg.xml,在前面配置的基础上,添加:
配置是否使用查询缓存为true
<property name="hibernate.cache.use_query_cache">true</property>
第三步:在写程序的时候,还要设置Query的setCacheable(
true);
测试文件如下,运行一下看看,然后再去掉缓存配置运行一下看看:
java代码:
- s = sf.openSession();
- t = s.beginTransaction();
- Query query1 =s.createQuery("select Object(o) from UserModel o");
- query1.setCacheable(true);
- List list1 = query1.list();
- System.out.println("list1=="+list1);
- t.commit();
- s = sf.openSession();
- t = s.beginTransaction();
- Query query2 =s.createQuery("select Object(o) from UserModel o");
- query2.setCacheable(true);
- List list2 = query2.list();
- System.out.println("list2=="+list2);
- t.commit();
- s = sf.openSession();
- t = s.beginTransaction();
- Query query3 =s.createQuery("select Object(o) from UserModel o");
- query3.setCacheable(true);
- List list3 = query3.list();
- System.out.println("list3=="+list3);
- t.commit();
http://sishuok.com/forum/blogPost/list/2482.html
关于检索方式的文章:(比较详细)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号