
强化学习框架RLlib教程001:Ray和RLlib介绍
目录
什么是Ray
什么是RLlib
简单的代码风格
Policies
Sample Batches
Training
Application Support
Customization
参考资料
|
什么是Ray |

Ray是一个用于构建和运行分布式应用程序的快速而简单的框架。
Ray通过以下方式完成这一任务:
1.为构建和运行分布式应用程序提供简单的单元。
2.允许终端用户并行化单个机器代码,几乎不需要更改代码。
3.在Ray Core之上包含一个大型的应用程序、库和工具生态系统,以支持复杂的应用程序。
Ray Core为应用程序构建提供了简单的单元。
在Ray Core之上有几个库用于解决机器学习中的问题:
Tune: Scalable Hyperparameter Tuning
RLlib: Scalable Reinforcement Learning
RaySGD: Distributed Training Wrappers
Ray Serve: Scalable and Programmable Serving
Ray还拥有许多其他社区贡献的函数库:
Distributed Scikit-learn / Joblib
Distributed multiprocessing.Pool
|
什么是RLlib |
RLlib是一个用于强化学习的开源库,它为各种应用程序提供了高可伸缩性(Scalable Reinforcement Learning)和统一API。RLlib本身支持TensorFlow、TensorFlow Eager和PyTorch,但它的大多数内部内容是框架无关的。
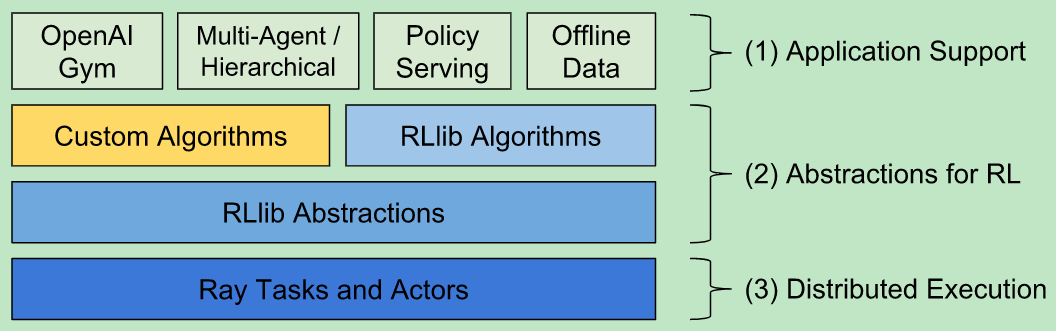
从上图可以看出,最底层的分布式计算任务是由Ray引擎支撑的。倒数第二层表明RLlib是对特定的强化学习任务进行的抽象。第二层表示面向开发者,我们可以自定义算法。最顶层是RLlib对一些应用的支持,比如:可以让智能体在离线的数据、Gym或者Unit3d的环境中进行交互等等。
RLlib之于Ray就如同MLlib之于Spark。
|
简单的代码风格 |
from ray import tune from ray.rllib.agents.ppo import PPOTrainer tune.run(PPOTrainer, config={"env": "CartPole-v0"}) # "log_level": "INFO" for verbose, # "framework": "tfe" for tf-eager, # "framework": "torch" for PyTorch
上面三行代码就可以训练一个玩平衡杆游戏的智能体。
接下来,我们将介绍RLlib中的三个关键概念:Policies, Samples, and Trainers.
|
Policies |
策略是RLlib中的核心概念。简而言之,policies是定义agent 如何在环境中工作的Python类。Rollout workers查询策略以确定agent 的动作。在gym 中,只有一个agent 和policy。在vector envs中,策略推理是针对多个代理的,在多代理中,可能有多个策略,每个策略控制一个或多个代理:

|
Sample Batches |
无论是在单个进程中运行还是在大型集群中运行,RLlib中的所有数据交换都是以批样的形式进行的。采样批次编码一个轨迹的一个或多个片段。通常,RLlib从rollout worker中收集大小为rollout_fragment_length的批,并将一个或多个批连接到大小为train_batch_size的批中,该批是SGD的输入。
一个典型的样例批处理如下所示。由于所有的值都保存在数组中,这允许有效的编码和传输的网络:
{ 'action_logp': np.ndarray((200,), dtype=float32, min=-0.701, max=-0.685, mean=-0.694),
'actions': np.ndarray((200,), dtype=int64, min=0.0, max=1.0, mean=0.495),
'dones': np.ndarray((200,), dtype=bool, min=0.0, max=1.0, mean=0.055),
'infos': np.ndarray((200,), dtype=object, head={}),
'new_obs': np.ndarray((200, 4), dtype=float32, min=-2.46, max=2.259, mean=0.018),
'obs': np.ndarray((200, 4), dtype=float32, min=-2.46, max=2.259, mean=0.016),
'rewards': np.ndarray((200,), dtype=float32, min=1.0, max=1.0, mean=1.0),
't': np.ndarray((200,), dtype=int64, min=0.0, max=34.0, mean=9.14)}
在多代理模式下,每个策略下的sample batches会被分别收集。
|
Training |
每个策略都定义了一个learn_on_batch()方法,该方法根据输入的样例批处理改进策略。对于TF和Torch策略,这是使用一个损失函数来实现的,该函数以样本批张量作为输入,并输出一个标量损失。下面是一些损失函数的例子
Simple policy gradient loss
Simple Q-function loss
Importance-weighted APPO surrogate loss
RLlib Trainer类协调分布式工作流(启动rollouts worker和策略优化)。它们利用Ray并行迭代器来实现所需的计算模式。下面的图显示了同步采样,这是这些模式中最简单的:

图中可以看出:
Trainer将数据广播给所有Workers,由他们与环境交互产生数据,经过抽样的方式返回Trainer进行训练。
RLlib使用Ray actor将训练从单个核扩展到集群中的数千个核。可以通过更改num_workers参数来配置用于培训的并行性。
|
Application Support |
除了Python中定义的环境之外,RLlib还支持离线数据集上的批处理训练,并为外部应用程序提供了各种集成策略。比如Unit3D的环境
|
Customization |
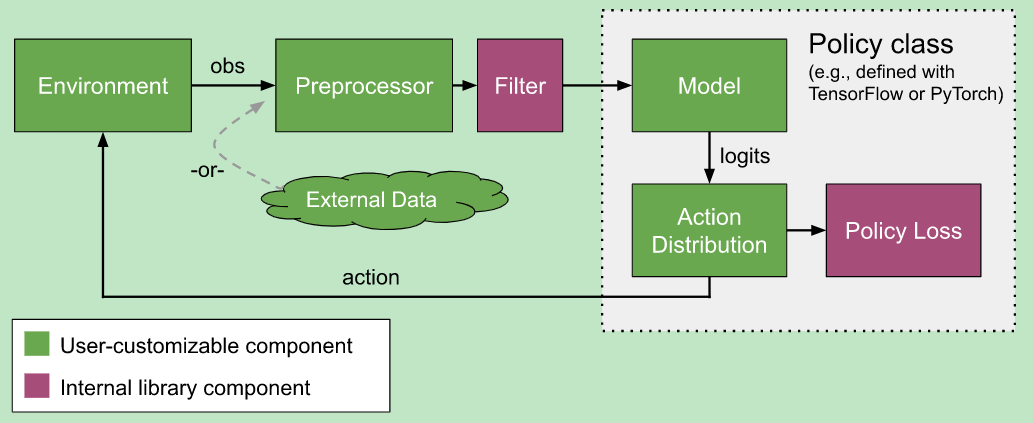
RLlib几乎提供了自定义训练过程中所有方面的方法,包括环境(environment)、神经网络模型(neural network model)、行动分布(action distribution)和策略定义(policy definitions):
|
参考资料 |
https://docs.ray.io/en/latest/rllib.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号