
深度学习面试题38:LSTM如何解决梯度消失问题
目录
回顾简单RNN的梯度消失问题
LSTM如何解决梯度消失
遗忘门对梯度消失的影响
遗忘门的初始化技巧
参考资料
|
回顾简单RNN的梯度消失问题 |
在简单RNN的前向传播过程中,输入的数据循环地与隐藏层里的权重W(都是很小的数)做乘法运算,那么损失函数对较长时间步前的W的梯度就会很小(因为W会累乘,激活函数大多也是小数),详细内容见【深度学习面试题35:RNN梯度消失问题(vanishing gradient)】。
|
LSTM如何解决梯度消失 |

在【深度学习面试题35:RNN梯度消失问题(vanishing gradient)】中有一个结论,即简单RNN越早的时间步梯度消失的问题越严重;而这一现象在LSTM不太会发生(注意这里的用词,是不太会)。下面来分析原理。
以上图为例,我们假设有三个时间步,最后一个时间步产生输出,并且遗忘门、输入门和输出门的输出都是1,那么整个前馈过程的计算如图所示。
下面以最复杂的输入门为例,演示为什么梯度不太会消失。反向求导结果如下
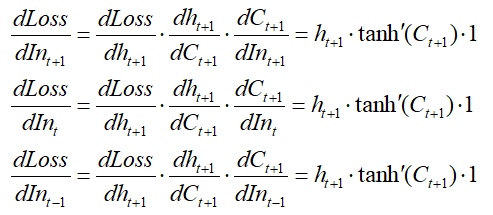
可以看到,损失函数对每个时间步的梯度都是一样的,然后根据链式求导发展,每个时间步继续对输入门里的参数求梯度,结果可想而知,每个时间步下的输入门的梯度都比较大,所以就没有简单RNN梯度消失的问题。
遗忘门和输出门同理。
|
遗忘门对梯度消失的影响 |
在上一节我们假设了遗忘门的输出为1。
如果遗忘门的输出为1,也就是不对记忆细胞C进行遗忘。
如果遗忘门的输出小于1,那么,越早的时间步的梯度就会越小,可能出现梯度消失。
|
遗忘门的初始化技巧 |
一般而言为了避免训练LSTM因梯度消失而训练缓慢的问题,可以将输入门的偏置初始化大一些,这样就可以保证遗忘门的输出接近于1,就可以高效地训练网络了。
|
参考资料 |
https://www.bilibili.com/video/BV15b411g7Wd?p=44

 浙公网安备 33010602011771号
浙公网安备 33010602011771号