

Base64算法
简单概念理解:
Base64算法使用了单表置换算法的思想。Base64使用一个由64个字符组成的映射表,见Base64字符映射表,然后其他的所有符号都根据这个映射表转换成对应的字符。
注意:Base64是在给定字符编码(如:gbk,utf-8)的基础上进行的,因为经过这些字符编码的编码之后,已经转换成该编码的二进制字节码了
这样Base64才能使用它的64字符进行转换
Base64的实现原理:
1)将给定的字符串转换成对应的字符编码(如:GBK、UTF-8)
2)将获得该字符编码转换成二进制码
3)对获得的二进制码进行分组操作
第一步:每3个字节(8位二进制)为一组,一共24个二进制位
第二步:将这个24个二进制位分成4组,每个组有6个二进制位,不足6位的,后面补0。
第三步:在每个组前面加两个0,这样每个组就又变成了8位,即每个组一个字节,4个组就4个字节了。
第四步:根据Base64的转码表找到每个字节对应的符号,这个符号就是Base64的编码值
Base64编码表
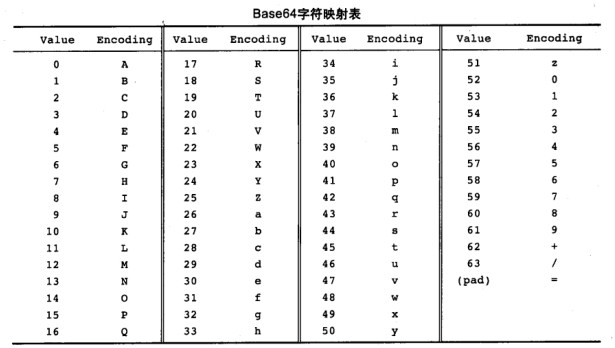
Value指二进制对应的十进制编码,Encoding指Base64的编码值
Base64编码规则:
经过Base64编码后的字符串的字符数一定是4的整数倍。在使用Base64编码时,如果得到的字符数不为4的整数倍,则后面使用等号 ‘=’补足
举例说明:
举一个具体的实例,演示英语单词Man如何转成Base64编码。
| Text content | M | a | n | |||||||||||||||||||||
| ASCII | 77 | 97 | 110 | |||||||||||||||||||||
| Bit pattern | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 0 |
| Index | 19 | 22 | 5 | 46 | ||||||||||||||||||||
| Base64-Encoded | T | W | F | u | ||||||||||||||||||||
第一步,"M"、"a"、"n"的ASCII值分别是77、97、110,对应的二进制值是01001101、01100001、01101110,将它们连成一个24位的二进制字符串010011010110000101101110。
第二步,将这个24位的二进制字符串分成4组,每组6个二进制位:010011、010110、000101、101110。
第三步,在每组前面加两个00,扩展成32个二进制位,即四个字节:00010011、00010110、00000101、00101110。它们的十进制值分别是19、22、5、46。
第四步,根据上表,得到每个值对应Base64编码,即T、W、F、u。
因此,Man的Base64编码就是TWFu。
如果字节数不足三,则这样处理:
a)二个字节的情况:将这二个字节的一共16个二进制位,按照上面的规则,转成三组,最后一组除了前面加两个0以外,后面也要加两个0。这样得到一个三位的Base64编码,再在末尾补上一个"="号。
比如,"Ma"这个字符串是两个字节,可以转化成三组00010011、00010110、00010000以后,对应Base64值分别为T、W、E,再补上一个"="号,因此"Ma"的Base64编码就是TWE=。
b)一个字节的情况:将这一个字节的8个二进制位,按照上面的规则转成二组,最后一组除了前面加二个0以外,后面再加4个0。这样得到一个二位的Base64编码,再在末尾补上两个"="号。
比如,"M"这个字母是一个字节,可以转化为二组00010011、00010000,对应的Base64值分别为T、Q,再补上二个"="号,因此"M"的Base64编码就是TQ==。
再举一个中文的例子,汉字"严"如何转化成Base64编码?
这里需要注意,汉字本身可以有多种编码,比如gb2312、utf-8、gbk等等,每一种编码的Base64对应值都不一样。下面的例子以utf-8为例。
首先,"严"的utf-8编码为E4B8A5,写成二进制就是三字节的"11100100 10111000 10100101"。将这个24位的二进制字符串,按照第3节中的规则,转换成四组 一共32位的二进制值"00111001 00001011 00100010 00100101",相应的十进制数为57、11、34、37,它们对应的Base64值就为5、L、i、l。
所以,汉字"严"(utf-8编码)的Base64值就是5Lil。
这里需要注意,汉字本身可以有多种编码,比如gb2312、utf-8、gbk等等,每一种编码的Base64对应值都不一样。下面的例子以utf-8为例。
首先,"严"的utf-8编码为E4B8A5,写成二进制就是三字节的"11100100 10111000 10100101"。将这个24位的二进制字符串,按照第3节中的规则,转换成四组 一共32位的二进制值"00111001 00001011 00100010 00100101",相应的十进制数为57、11、34、37,它们对应的Base64值就为5、L、i、l。
所以,汉字"严"(utf-8编码)的Base64值就是5Lil。
Java版Base64编码和解码实现:
方案一:使用Apache的org.apache.commons.codec.binary.Base64类
//Base64编码
/*String str = new String(Base64.encodeBase64("中国".getBytes("gbk")) ,"gbk");
System.out.println(str);*/
//Base64编码,对输出结果中,每76个字符追加一个回车换行符
String str = new String(Base64.encodeBase64("中国".getBytes("gbk") ,true) ,"gbk");
System.out.println(str);
//Base64解码
String str2 = new String(Base64.decodeBase64(str.getBytes("gbk")) ,"GBK");
System.out.println(str2);
方案二:使用sun内部使用类
sun.misc.BASE64Encoder、sun.misc.BASE64Decoder
//Base64编码
BASE64Encoder encoder = new BASE64Encoder();
String encodeStr = encoder.encode("中国".getBytes("gbk"));
System.out.println(encodeStr);
//Base64解码
BASE64Decoder decoder = new BASE64Decoder();
String str = new String(decoder.decodeBuffer(encodeStr) ,"gbk");
System.out.println(str);
