Python3爬取百度百科(配合PHP)
用PHP写了一个网页,可以获取百度百科词条。

那么通过Python来爬取,只需要不断向这个网页POST数据,获取返回值就可以了。由于是我自己的网页,保存返回值我也让PHP在服务器端来完成了,所以Python的任务只需要不断向服务器POST数据。
那么POST什么数据呢?暂时找到了一个名词大全的网页。http://cidian.911cha.com/cixing_mingci.html

足足20页的名词,足够作为名词POST数据的来源了。
下面是获取各种名词的python代码:
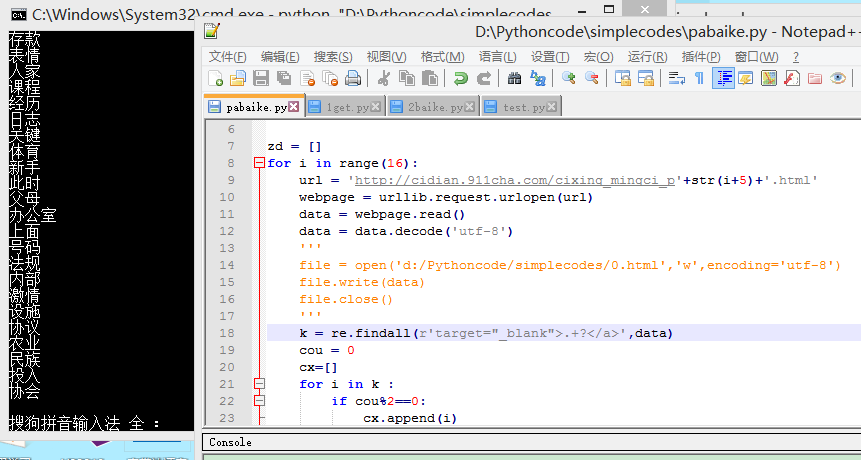
zd = [] for i in range(20): url = 'http://cidian.911cha.com/cixing_mingci_p'+str(i+1)+'.html' webpage = urllib.request.urlopen(url) data = webpage.read() data = data.decode('utf-8') ''' file = open('d:/Pythoncode/simplecodes/0.html','w',encoding='utf-8') file.write(data) file.close() ''' k = re.findall(r'target="_blank">.+?</a>',data) cou = 0 cx=[] for i in k : if cou%2==0: cx.append(i) cou= cou+1 for it in cx: m = re.search(r'target="_blank">(.*?)</a>',it) iturl = m.group(1) zd.append(iturl)
现在字典里已经保存了足足20页的名词,下一步就是要向服务器POST数据,保存词条内容了。
for i in zd : s=i print(i) s=urllib.parse.quote(s) url = "http://www.selflink.cn/xiaobaike/?name=%s"%(s) try: urllib.request.urlopen(url,timeout=5) except Exception as e: pass
python开始运行了……
最后爬到了1902个词条内容0.0
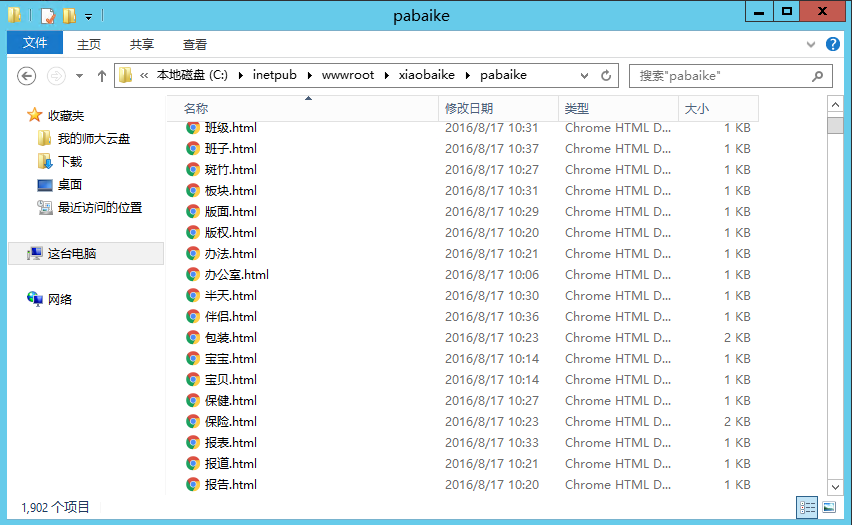
获取了这么多词条有什么用呢?……我也不知道,不过,获取知识也许是人工智能的开始吧^_^

 浙公网安备 33010602011771号
浙公网安备 33010602011771号