
Mysql语法入门与进阶
0. 若你控制台输入 mysql -v
若你已经安装了mysql,还是显示:'mysql' 不是内部或外部命令,也不是可运行的程序或批处理文件。
说明有可能是你没有配置mysql的环境,应该去环境变量里面配置。
1. Mysql语法分类
-
DDL:对表结构的:create(创建),alter(修改),drop(删除),TRUNCATE(截断),RENAME(重命名)....;
-
DML:delete(删除),update(更新),insert(新增)...;
-
DQL:select(查询);
2. 数据表操作
2.1 修改表名
alter table 旧表名 rename to 新表名;
2.2 增加一列
alter table 表名 add 新列名 字段类型 [字段选项];
2.3 删除一列
alter table 表名 drop 字段名;
2.4 修改列类型
alter table 表名 modify 字段名 新的字段类型 [新的字段选项];
2.5 修改列名称
alter table 表名 change 原字段名 新字段名 新的字段类型 [新的字段选项];
2.6 查看创建表的语句
show create table 表名
3. 数据操作
SQL完整语法:select * from user where group by having order by limit
3.1 ifnull
注意:只要有null参与的运算,结果一定为null
select name,(sal+comm)*12 as yearsql from emp;
# 解决办法:ifnull()空处理函数
select name,(sal+ifnull(comm,0))*12 as yearsql from emp;
3.2 count(id)与count(*)与count(1)
- count(*):对行的数据进行计算,包含NULL
- count(1):和上述一样
- count(column):对特定列进行计算,不包含NULL
3.3 where后面不能用聚合函数
4. 关于group by,having
分组函数:按照某个字段或某些字段进行分组。
having:对分组之后的数据进行再次过滤。
如:找出每个工作岗位的最高薪资
1. select XXXXXX from emp group by job; /* 先分组 */
2. select max(sal) from emp group by job; /* 查询出来的只要最高工资,不知道最高工资属于谁*/
3. 注意:当一条sql语句有group by的时候。select 后面只能跟分组字段,或聚合函数(max,avg..) 否则查询出来的结果毫无意义0
如:select ename, max(sal), job from emp group by job; /* 虽然查出来了人,但是数据有问题,ename是从该job分组里面取的一个人的enma,不一定恰好就是最高工资那个人的名字 */
/* 总之,当 SQL 语句中包含 GROUP BY 子句时,SELECT 子句中只能包含分组字段和聚合函数,否则查询结果可能毫无意义。*/
有的情况能用where代替having
#如:找出每个部门的最高薪资,要求只显示薪资大于3000的数据
# 效率低
select max(sal),detptno from emp group by deptno having max(sal) > 3000;
# 效率高
select max(sal),deptno from emp where sal > 3000 group by deptno;
确定不能用where代替having的情况
如:找出每个部门的平均薪资,要求只显示薪资大于3000的数据
select deptno,avg(sal) from emp group by deptno having avg(sal) > 3000
5. 关于between and
它是左闭右闭的。
select * from emp where sal between 100 and 900;
等同于
select * from emp where sal >=100 and sal <= 900;
使用between查询时间的时候需要注意:
https://www.cnblogs.com/lj312/p/7238211.html
另外一种时间范围查询的方法如下:分别设定开始时间和结束时间:
<if test="endTime!=null and !"".equals(endTime.trim())">
AND m.endTime < #{endTime}
</if>
<if test="startTime!=null and !"".equals(startTime.trim())">
AND m.startTime > #{startTime}
</if>
6. 一对多查询
对于一对多的关系,通常将外键放在多的一方的表中,以便于保证数据的一致性。
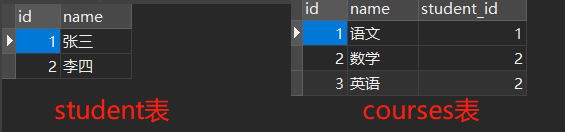
////////////////////////假如:一个学生可以选修多门课程,但每门课程只能由一个学生选修。////////////////////////
/*查询选修了课程ID 为 1 的课程的学生信息*/
SELEC
students.*
FROM
students
INNER JOIN courses ON students.id = courses.student_id
WHERE
courses.id = 1;
6. 多对多查询

////////////////////////假如:一个学生可以选择多个课程,一个课程也可以被多个学生选择。////////////////////////
/*检索学生张三所选的所有课程*/
SELECT
course.NAME
FROM
course
INNER JOIN student_course ON course.id = student_course.course_id
INNER JOIN student ON student.id = student_course.student_id
WHERE
student.NAME = '张三';
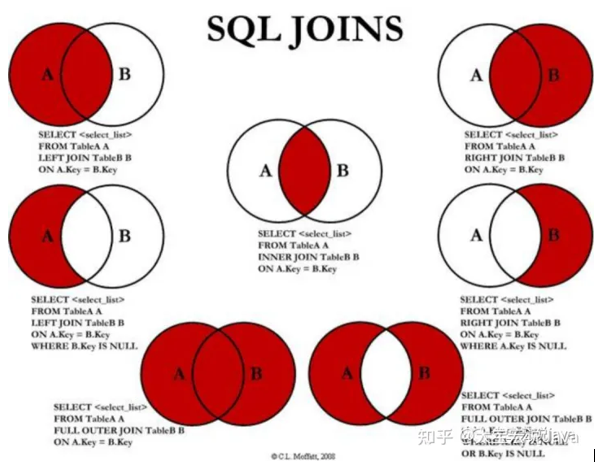
7. inner join与 left join 的选择
inner join会返回两表的交集,而left join会返回左表的全部记录。
INNER JOIN:只返回两个表之间匹配的行,如果左表中的行没有与右表中的行匹配,则不会包括在结果集中。
LEFT JOIN:返回左表中所有的行,同时返回与右表匹配的行。如果左表中的行没有与右表中的行匹配,则返回NULL值。
8. delete与truncate区别
delete:删除表中所有记录,有多少删多少,不会改变表结构。若:id为自增,则自增不会变为0。
truncate:删除表,自动重新创建一个一摸一样的表。若:id为自增,则自增会变为0。
9. varchar与char区别
varchar:可变字符串,最多放65532个长度。
varchar(50):最多存放50个字符。
char:定长字符串,长度不可变,你设置它多长,若他达不到,则会以空格进行填补。
char(11):必须存11个字符,一般我们设置表的时候,可以将手机号设置为char(11)。存取快。【总的来说,只要你能很确定,这个字段存字符的大小,就可以优先考虑用char】
10. mysql的事务
事务:就是针对数据库的一组操作。只要程序在执行过程中有一条SQL执行失败,则其他语句都不会执行。
事务的四个基本特性:
A-原子性:事务中的sql要么同时成功,要么同时失败。
C-一致性:事务前后,数据总量保持不变。
I-隔离性:各个事务相互隔离,互不干扰【当一个事务在执行时,不会受到其他事务的影响,保证了未完成事务的所有操作与数据库系统的隔离,直到事务完成为止,才能看到事务的执行结果】
D-持久性:事务成功提交后,数据会永久性的保存下来。
11. 事务的隔离级别
隔离级别:Mysql允许多线程并发访问,隔离级别时为了保证这些事务之间不受影响而存在的。
事务的四个隔离级别:
读未提交:【脏读,幻读,不可重复读】
读已提交:【幻读,不可重复读】
可重复读(默认):【幻读】
串行化:事务的最高隔离级别,会在每个读的数据上加锁,解决了所有问题。由于加锁,导致性能低。
脏读:一个事务可以读取到另一个事务还没提交的数据。
幻读:一个事务内的两次查询数据不一致。 幻读:由于其他事务做了插入记录的操作。
不可重复读:一个事务内的多次查询结果不一致。 不可重复读:是由于查询过程中数据被其他事务进行了修改。
12. mysql的存储引擎
存储引擎:可以看作是数据表存储数据的一种格式,不同的格式具有的特性也不相同。
MyISAM:Mysql5.7版本中被指定为默认的存储引擎,支持事务。
MyISAM:Mysql5.5以前的版本的默认存储引擎,不支持事务。
13. mysql的锁机制
在Mysql中,根据存储引擎的不同,分为如下锁类型:
- 行级锁:仅锁定用户操作所涉及的记录行。【InnoDB采用】
行锁是指在数据表中的每一行记录上设置锁,当一个事务需要修改某一行记录时,只会锁定需要修改的那一行,而不是锁定整个表或数据块。
- 表级锁:锁定用户操作行所在的整个数据表。【MyISAM采用】
当一个事务需要对整个数据表进行修改操作时,MySQL 数据库会自动对该表加上表锁,避免其他事务同时对该表进行修改操作。
14. mysql实现乐观锁与悲观锁
乐观锁:很乐观,每次拿数据都认为别人不会修改数据,不会上锁。在更新的时候再去判断在此期间别人是否更新了这个数据。
实现方式:
在表中加一个version字段,查询数据时得到它的值,更新时加上这个条件。
悲观锁:很悲观,每次拿数据都任务别人肯定会修改数据,会上锁。在他拿到数据操作完之前,别人不能来操作数据。
实现方式:
关闭事务的自动提交功能
在查询数据时加上“for update”
15. 索引
索引:一种特殊的数据结构,用于将表中某些字段与记录的位置建立一个对应关系,加快定位数据位置的时间。
索引大大提高了查询速度。实际上索引也是一张表,所以索引列也是要占空间的。
explain:SQL分析语句,该关键字用于分析SQL语句的执行情况。判断是否用到索引。
mysql中的explain命令可以用来查看sql语句是否使用了索引,用了什么索引,有没有做全表扫描。
key:sql语句实际执行时使用的索引列
type:访问类型,表示数据库引擎查找表的方式
索引的分类:
-
普通索引:可以创建多个,可以为NULL值,可以重复。
-
唯一索引:可以创建多个,最多一个NULL值,但是创建的字段必须具有唯一约束。
-
主键索引:只能拥有一个,不能为NULL值。一般不需要我们主动创建,只要在建表时指定了主建。
-
复合索引:指在表中多个字段上创建一个索引,且只有在查询条件中使用了这些字段中的第一个字段时,该索引才会被使用
复合索引:需要复合`最左匹配`原则。
最左匹配,以最左边的为起点任何连续的索引都能匹配上。同时遇到范围查询(>、<、between、like)就会停止匹配。
(例如:b = 2 如果建立(a,b)顺序的索引,是匹配不到(a,b)索引的;但是如果查询条件是:a = 1 and b = 2 或 a=1 或 b = 2 and a = 1)就可以。因为优化器会自动调整a,b的顺序。)
(比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,因为c字段是一个范围查询,它之后的字段会停止匹配。所以,abc会用到复合索引)
如:对name,age,address字段建立复合索引,就相当于建立了 (a),(a,b),(a,b,c)三个索引,在查询时,只有第一个字段被使用时,该复合索引才会被使用。
【多个字段的设置顺序要遵循“最左前缀原则”,就是把最频繁使用的字段放在最左边,然后依次类推】
比如索引 abc_index:(a,b,c)
以下三种情况却会走索引:
select * from table where a = '1';
select * from table where a = '1' and b = '2';
select * from table where a = '1' and b = '2' and c='3';
注意:
查询的语句是 where and b = '2' and a = '1' and c='3';
理论上索引对顺序是敏感的,但是由于 MySQL 的查询优化器会自动调整 where 子句的条件顺序以使用适合的索引,所以 MySQL 不存在 where 子句的顺序问题而造成索引失效。
查询的语句是 where and a = '1' and c = '2';
只走a字段索引,不会走 c 字段。
-
全文索引:目前只有MyISAM引擎支持。主要是作用在数据类型为CHAR、VARCHAR、TEXT的列上,用于长文本的字符串搜索加速。
-
空间索引:目前只有MyISAM引擎支持。空间索引主要是针对空间数据类型的列建立的。
索引的使用原则:
-
查询条件中频繁使用的字段才适合建立索引
-
比起字符串类型的字段,数字型的字段更适合建立索引
-
比起存储空间大的字段,存储空间较小的字段更适合建立索引
-
重复值字段高的字段不适合建立索引
-
更新频繁的字段不适合建立索引
索引失效的情况:
-
mysql估计使用全表扫描比使用索引快时
-
模糊查询中通配符的使用
在模糊查询时,若匹配模式中的最左侧含有通配符(%),会导致全表扫描。如:select name from user where namke like "%飞";
like "飞%"; 会走索引
- or条件查询
在使用or查询时,只有or两边的字段都有索引,才会触发索引。
- 查询时保证字段的独立
对于建立索引的字段,在查询时要保证该字段在关系运算符(如:=,>等)的一侧独立,不能是表达式的一部分或函数的参数。
如:select id from user where id+1 > 3;
如:select name from user where ASB(id) = 1;
- 列类型为字符串
比如列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不使用索引。
- 最左前缀原则
复合索引没有使用最左前缀原则,则不会触发复合索引。
- 在索引字段上使用not,<>,!=,is null,is not null,in,not in

16. SQL优化
SQL优化,我们可以从数据表优化和sql语句优化入手。
数据表优化:
-
选择合适的存储引擎。
-
列的字段能小就小,比如:年龄字段,可以设为thyint。以达到节省空间,提高查询效率。
-
不能为null的列,尽可能设置为不为NULL。只要列中包含有NULL值都将不会被包含在索引中。
-
如果确认该字段是定长,用char。比如:手机号。
-
一个表字段不要太多,可以拆分成多张表。
sql语句优化:
-
不要使用select * 。阿里开发手册也这样说了的。尽量不要返回用不到的任何字段。不然会增加不必要的消耗(内存,CPU,宽带)
-
只需要查询一条数据是,可使用limit 1 提高查询。
-
要避免索引失效问题的出现。
-
避免联合查询,能改成单表查询,改成单表查询。
-
对于连续的数值,用between比用in效率高。能用between就不用in。
-
应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号