
SpringCloud Alibaba-10-分布式事务
1. 什么是分布式事务
1.1 事务
严格意义上的事务实现应该是具备原子性、一致性、隔离性和持久性,简称 ACID。通俗意义上来说,事务就是为了使得一些更新等操作要么都成功,要么都失败。
-
原子性(Atomicity):可以理解为一个事务内的所有操作要么都执行,要么都不执行。
-
一致性(Consistency):在一个事务执行之前和执行之后数据库都必须处于一致性状态,比如你账上有400,我账上有100,你给我打200块,此时你账上的钱应该是200,我
账上的钱应该是300,不会存在我账上钱加了,你账上钱没扣的中间状态。 -
隔离性(Isolation):指的是多个事务并发执行的时候不会互相干扰,即一个事务内部的数据对于其他事务来说是隔离的。
-
持久性(Durability):指的是一个事务完成了之后数据就被永远保存下来,之后的其他操作或故障都不会对事务的结果产生影响。
其中,原子性和持久性就是靠undo和redo日志来实现的。在Mysql中,有许多日志文件,这2个文件就是与事务有关的。
1.2 undo日志
undo日志:用于保证事务的原子性。
原理:
- 在操作任何数据之前,先将数据备份到Undo Log。
- 然后进行数据的修改。
- 若出现了错误或用户执行了ROLLBACK语句,系统就可以利用Undo Log中的备份数据恢复到事务开始之前的状态。
流程举例:
- 事务开始
- 记录A=1到undo log
- 修改A=3
- 记录B=2到undo log
- 修改B=4
- 将undo log写到磁盘
- 将数据写到磁盘
- 事务提交
1.3 redo日志
redo日志:用于保证事务的持久性
原理:
- redo log与undo log 相反,redo log记录的是新数据的备份,undo log记录的是旧数据的备份
- 在事务提交前只需要将redo log持久化即可。
流程举例:
- 事务开始
- 记录A=1到undo log
- 修改A=3
- 记录A=3到redo log
- 记录B=2到undo log
- 修改B=4
- 记录B=4到redo log
- 将undo log写到磁盘
- 将redo log写入磁盘
- 事务提交
1.4 分布式事务
分布式事务:顾名思义就是要在分布式系统中实现事务,它其实是由多个本地事务组合而成。
会产生分布式事务的情况:
-
跨服务的分布式事务
-
跨数据源的分布式事务 【当数据库单表一年产生的数据超过1000W,就考虑分库分表,如果一个操作既要访问01库,又要访问02库,且要保证数据的一致性,就要用分布式事务】
-
综合情况
什么是跨数据源
随着业务数据规模的快速发展,数据量越来越大,单库单表已经到瓶颈,不能满足我们的需求。此时我们就会对数据库进行水平拆分,将原本的单库单表拆分成多库多表。所以就出现了跨数据源事务问题。
分库分表的入门理解:https://www.cnblogs.com/itlihao/p/14803807.html
什么是跨服务
在分布式项目里面,我们都是拆分了服务的,各个服务在不同的JVM里面,各个JVM里面都有自己的Spring管理的事务。所以就出现了跨服务的事务问题。
2. 分布式理论
前言:为什么要讲分布式理论? 因为:分布式事务的解决就是基于这些理论思想而实现的,一个分布式事务具有CAP三个指标。
2.1 CAP理论
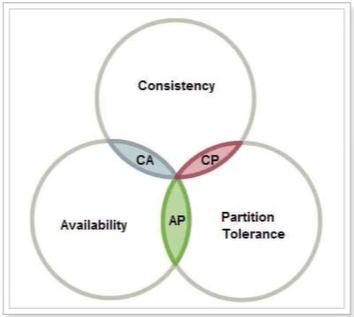
CAP理论:由1998年,加州大学计算机科学家提出,他指出分布式系统有三个指标,我们在设计分布式系统的时候就要考虑这些指标,尽量避免这些问题。
- C:强一致性,多服务节点情况下,要保证多个服务的数据是一样的。
- A:可用性,节点们只要收到请求,要保证立马能处理并给回响应结果。
- P:分区容错性,分区后,可能导致各个区之间因为网络波动问题而无法通信。分区:分布式系统都分布在多个子网络,每个子网络这里就叫它为一个区。比如一台服务在北京,另一台服务在上海。
2.1.1 P:分区容错性(无法避免)
分区:大多数分布式系统都分布在多个子网络,每个子网络这里就叫它为一个区。比如一台服务在北京,另一台服务在上海。
分区容错性:就是指系统进行分区后,可能导致各个区之间因为网络波动问题而无法通信。
注意:只要是分布式系统,分区容错性是不可避免会遇到的问题。 因此可以认为 CAP 的 P 总是成立。
2.1.2 C:一致性
一致性:多服务节点(数据库)情况下,要保证多个服务的数据是一样的。
数据不一致:因为在分布式系统里面,因为我们会部署多服务集群(这里的多服务集群可以理解成多个数据库集群),所以就会出现多服务数据不一致的问题。
举例:
1. 有多台服务节点,他们数据现在是一致的。比如定义了 a = 1;
2. 用户现在要修改a的值,由于负载均衡,他被带来到服务节点1,修改了a = 2;
3. 用户现在要看a的最新值,由于负载均衡,此时他被带来到服务节点2,得出a的值为1;
这就是数据不一致的问题。
如何解决不一致:
当用户在服务节点1修改a = 2时,它发一条消息给其他节点,让其他节点也跟它一样将a改为2。如此一来,就能保证数据的一致性。
2.1.3 A:可用性
这里的可用性是指:只要接收到用户请求,就立马告诉用户结果。
回顾上述的一致性,当我们在修改a=2时,他需要发送一条信息给其他节点,从而达到各个服务节点数据一致,那么在发送信息给其他节点这段时间或其他节点收到消息还没改a的值时,其他节点恰好接收到了请求,怎么办?
所以,就出现了矛盾:
如果要满足一致性【某个节点更新a的值后要其他节点也同样更新(每个事务都成功,没成功前查数据就获取不到)】,那么就不能满足可用性。
如果满足可用性【不管其他节点更没更新a的值,只要用户一发请求,就把当前值告诉用户】,那么就不能满足一致性。
2.1.4 如何取舍CAP
什么时候满足CP?
对一致性要求高的场景。例如:Zookeper
什么时候满足AP?
对高可用要求较高的场景。例如:Eureka
2.1.5 分布式事务看中的是什么?
分布式事务最看重的就是数据一致性。
2.2 BASE理论
BASE是三个单词的缩写:
- B 基本可用
- S 软状态
- E 最终一致性
BASE 理论:是对 CAP 中一致性和可用性权衡的结果,是CAP 理论中AP 方案的延伸。其来源于对大型互联网分布式 实践 的总结,是基于 CAP 定理逐步演化而来的。
2.2.1 最终一致性
把告诉其他节点所耗费的那段时间尽可能减少,减少到可接收范围。
在没将其他节点同步数据完成前,其他节点还是提供服务,虽然那段时间来的请求可能得到数据不一致的情况,但是能通过弥补措施恢复数据,只要最终能保证消息一致性。
2.2.2 基本可用
因为告诉其他节点所耗费的那段时间尽可能减少了,所以只有那一点点时间其他节点不可用而已,所以就称为基本可用。
2.2.3 软状态
允许系统中的数据存在中间状态,并认为该状态不影响系统的整体可用性,即允许系统在多个不同节点的数据副本存在数据延时。
强一致性:系统写入了什么,读出来的就是什么。
弱一致性:不一定可以读取到最新写入的值,也不保证多少时间之后读取到的数据是最新的,只是会尽量保证某个时刻达到数据一致的状态。
最终一致性:弱一致性的升级版,系统会保证在一定时间内达到数据一致的状态。
2.2.4 BASE理论与CAP理论总结
-
CAP 是分布式系统设计理论,BASE 是 CAP 理论中 AP 方案的延伸。
-
CAP理论严格来讲不是三选二,而是CP、AP二选一,因为通常P(分区容错性)是必须得到保证的。
-
BASE理论面向的是大型高可用、可扩展的分布式系统。与传统ACID特性相反,不是强一致性模型,BASE提出通过牺牲强一致性来获得可用性,并允许数据一段时间内的不一致,但是最终需要达到一致状态。
3. 分布式事务的解决方案
基于分布式事务理论思想,衍生出了很多的分布式事务解决方案:
- 基于XA协议的两段提交
- TCC
- 可靠消息最终一致性
- AT模式
DTP:1994年由X/OPEN组织定义的用于处理分布式事务的DTP模型,该模型由如下几个角色
应用程序(AP) 我们的微服务
事务管理器(TM) 全局事务管理者
资源管理器(RM) 数据库
通信资源管理器(CRM) TM与RM之间的通信中间件,用于通知各个本地事务
实现思路:
在该模型中,一个分布式事务将被拆分成多个本地事务,运行在不同的AP和RM上。
一个分布式事务的成功实现,要求拆分成的所有本地事务全实现成功。
因为在本地上,所以本地事务的ACID就能很好解决与实现。
但是分布式事务是要求所有本地事务同时执行成功,若有一个失败,则全部回滚。
但是各个本地事务间如何知道其他事务是否执行完毕呢?
因此,需要一个CRM来通知各个本地事务,事务的状态。
想让CRM来做这个事,那么你就得按照CRM的要求来,按照人家的规范来开启你的本地事务。不然你A服务你搞个mysql,B服务你搞个Oracle,大家没有统一的规范,CRM就帮我们实现不了这个事。
XA:就是CRM与TM之间联系的接口规范。定义了用于 通知事务开始,提交,终止,回滚等接口。各个数据库厂商都必须实现这些接口。
3.1 基于XA的两阶段提交2PC方案【基于CAP理论】
基于XA协议的两段提交:就是基于DTP这种思想衍生出来的,将全局事务拆分成两个阶段执行。整个过程中,需要一个协调者,用于协调本地事物。
- 阶段一:准备阶段,各个本地事务完成本地事务的准备工作。【去执行一次,但不真正提交,将能否成功执行本地事务的结果反馈给协调者(TC)】
- 阶段二:执行阶段,根据上一阶段执行结果,通知各个本地事务进行提交还是回滚。
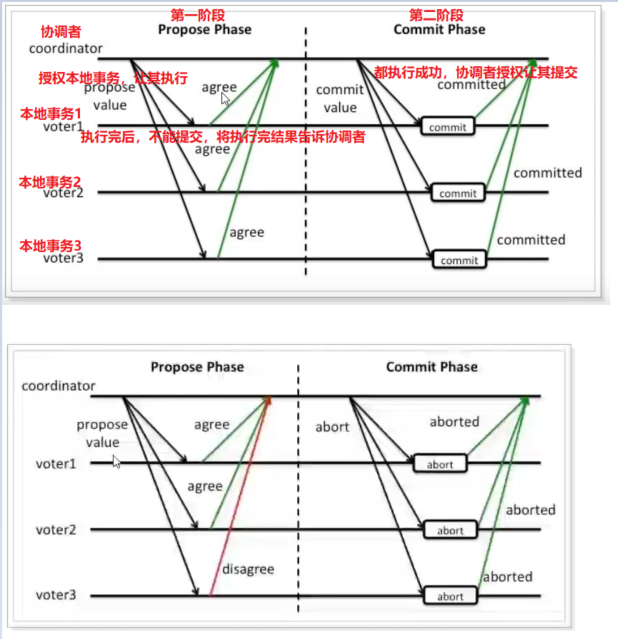
缺点:
- 单点故障问题:第一阶段成功,此时协调者挂了,还没告诉二阶段该怎么做。
- 数据阻塞问题:各个本地事务开启的时候,都要对数据加锁。此时不能对数据进行操作,包括查询操作。若某个本地事务先执行完,还得等其他事务执行完毕,得到最终结果看是否全部本地事务执行完毕,待协调者第二阶段的处理。
3.2 TCC方案【基于BASE理论】
TCC:相当于是两阶段的一个升级,它还是用的两段提交。但是可以解决基于AX的两阶段提交资源锁定和阻塞的问题。他就像Base理论。两阶段提交那种做法,要求的是强一致性。TCC呢,它达到的效果是最终一致性。
TCC是三个单词的缩写:
- Try:资源的检测和预留
- Confirm:执行的业务的提交
- Cancel:补偿
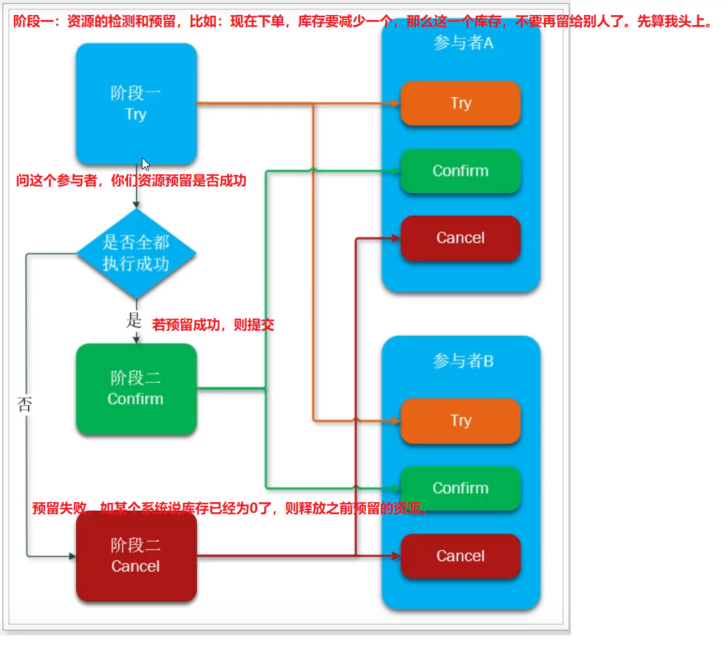
执行阶段:
- 准备阶段(try):资源的检测和预留
- 执行阶段(confirm/cancel):根据上一步的结果,判断下面执行的方法,若上一步都成功,则confirm。反之,则concel。
实现原理:
我们以下单业务中的扣减余额为例,来看下面3个方法的编写。假设账户A原本余额为100,需要余额扣减30元。

阶段一:余额检查,并冻结部分用户金额,此阶段执行完毕,事务已经提交。
- 检查用户余额是否充足,若充足,再冻结部分金额(要扣减的金额)
- 在账户表中新增冻结金额字段,值为30,余额不变100。此时查询来了余额应该告诉他是70。
阶段二:根据第一阶段的执行情况,执行二阶段的提交或回滚。
- 提交(confirm):真正的扣款,把冻结金额从余额里面扣除,冻结金额清空【将冻结金额值改为0,将余额改为70】
- 补偿(cancel):释放之前冻结的余额【真正的余额不变,将冻结金额的值改为0】
优点与缺点:
- 优点:
- TCC模式执行的每个阶段都会提交事务并释放资源,不需要等待其他事务的执行结果。
- 若其他事务执行失败,不需要回滚事务,而是执行补偿操作。如此一来,避免了锁资源与等待其他事务时的时间消耗。
- 缺点:
- 代码侵入太严重,需要人为去实现各个阶段,如:一阶段的try功能,二阶段的confirm与cancel功能。
- 开发成本高,本来一个业务现在要去编写这么多复杂业务。
- 还要考虑安全问题,万一补偿的时候发生异常失败了呢。
3.3 可靠消息最终一致性【BASE理论】
它是利用消息中间件来实现的,本质还是将一个分布式事务拆分成多个本地事务。
基本原理:
- 当事务发起者A服务开启事务,先执行本地事务,如转账案例,本地事务先减100。
- 然后通过MQ发送消息,B服务接收到消息,B服务加100。
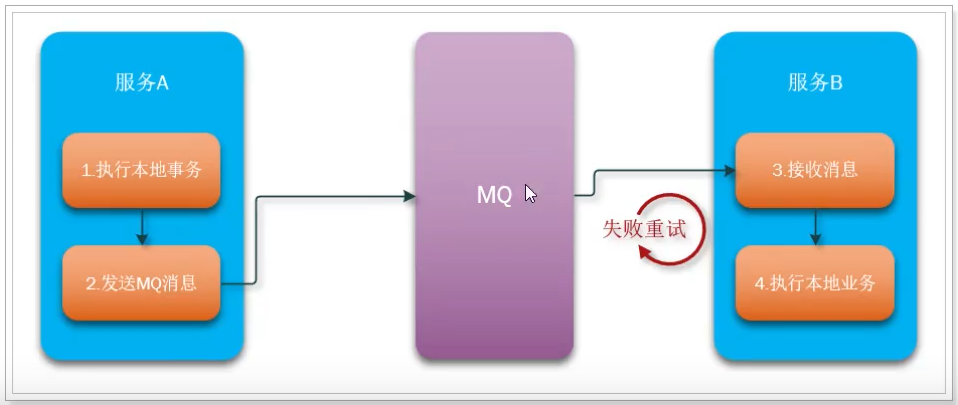
看基本原理,看着挺简单的。需要注意以下几点:
- 事务发起者A必须确保本地事务成功后,消息一定发送成功
- MQ必须保证消息正确投递和持久化
- 事务参与者B必须确保消息最终一定能消费,如果失败要多次重试
总之,就是要保证MQ的消息可靠性!!!!

缺点:
- 代码侵入较高
- 依赖于MQ的高可靠性
3.4 AT模式
2019年,Seata开源了一种解决分布式事务的模式,该模式就是AT模式。Seata框架就是基于AT模式这种思想做出来的用于解决分布式事务的组件。
AT模式:是一种无侵入的分布式事务解决方案,可以看作是对TCC模型的一种优化,将TCC模式第二阶段那些操作由Seata框架帮我们实现,解决了TCC代码侵入,编码复杂等问题。
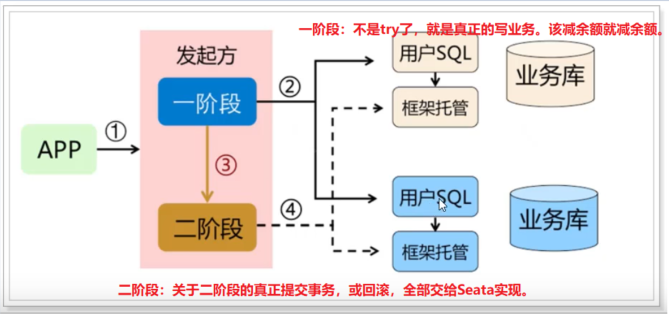
Seata中的几个基本概念:
-
TC - 事务协调者
维护全局事务,分支事务的状态,决定全局事务的提交或回滚。需要独立部署 -
TM - 事务管理器
定义全局事务的范围:开始全局事务,提交或回滚全局事务。 -
RM - 资源管理器
管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
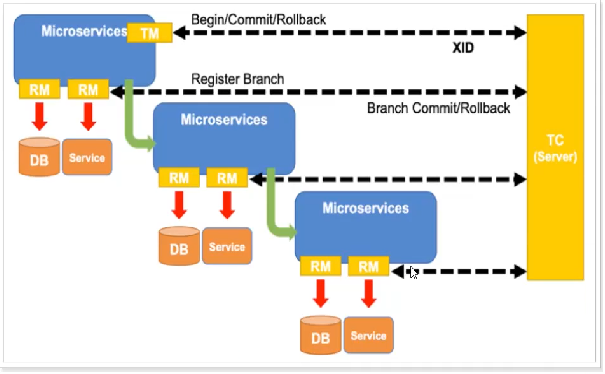
Seata一阶段原理:
- TM事务发起者发起事务时,由于方法上具有@GlobalTransacational注解,该TM会向TC发起全局事务,生成唯一的XID。
- RM事务参与者写表,undo_log记录当前数据,操作完成之后,通知TC事务协调者操作结果
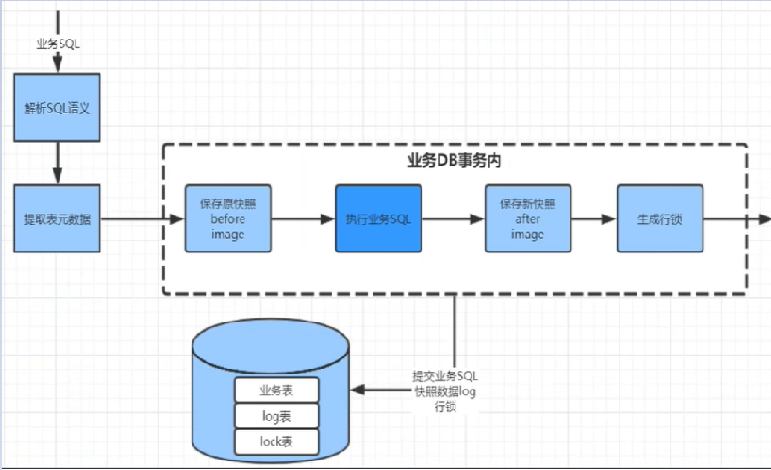
- 在写表之前,Seata会拦截SQL,解析SQL的语义,找到该SQL要更新的业务数据,在该数据被更新前,将其保存成before image,然后才执行SQL更新数据。
- 在写表之后,再将其保存成after image,最后生成行锁(为了防止其他事务再来操作该条数据)。
下图中:log表就是用来保存快照的,lock表就是用来保存行锁的。
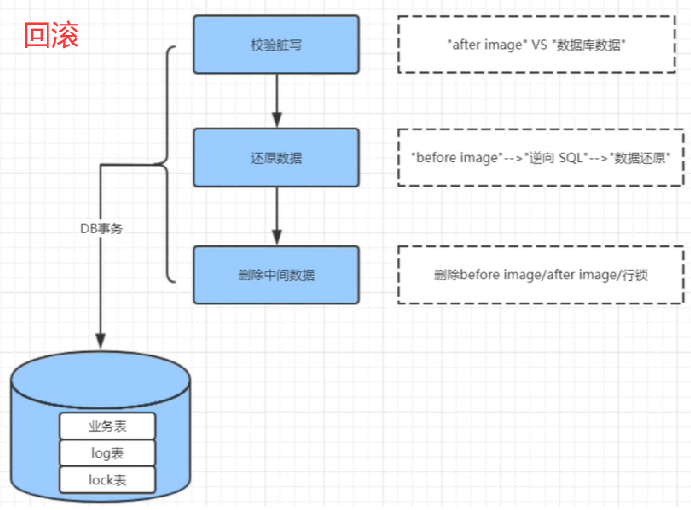
Seata二阶段原理:
-
如果一阶段各个事务都没问题,那么二阶段就会将一阶段保存的快照数据删除,行锁也删除。
-
如果一阶段有问题,那么二阶段就需要回滚一阶段已经执行的SQL。
先判断当前数据库业务数据和after image数据是否一致。
若一致,就说明没有脏写。就使用before image还原业务数据,还原数据后自动删除快照和行锁。
若不一致,就说明有脏写。就需要转人工处理。
【比如:我要扣款,原本100元,执行事务减去20,现在还剩80。结果事务出错了,Seata帮我建了一个after image,里面存的是我还剩80,现在事务执行失败,我和Seata里面存的结果都是一样80,那么Seata就能利用before image帮我回滚】

4. SpringBoot集成Seata【注册中心和配置中心采用nacos,基于最常用的AT模式】

请参考大佬原文:https://www.it235.com/高级框架/SpringCloudAlibaba/seata.html#编写at模式代码
大佬B站视频(我就是跟着他学的):https://www.bilibili.com/video/BV1BK411K792?p=15
还参考了B站视频:https://www.bilibili.com/video/BV1n7411R7WQ?p=13
seata中文官网:http://seata.io/zh-cn/index.html
4.0 先去下载seata
Seata中的几个基本概念:
-
TC - 事务协调者
维护全局事务,分支事务的状态,决定全局事务的提交或回滚。需要独立部署 -
TM - 事务管理器
定义全局事务的范围:开始全局事务,提交或回滚全局事务。 -
RM - 资源管理器
管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
现在我们就去官网搞一个TC-事务协调者,下载下来解压。https://github.com/seata/seata/releases
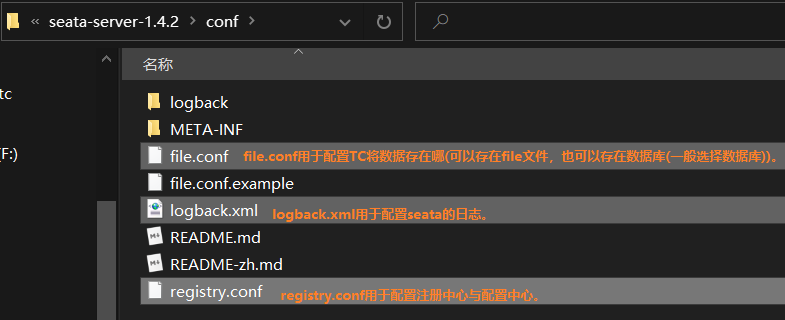
4.1 修改file.conf,将分布式事务相关数据保存到数据库
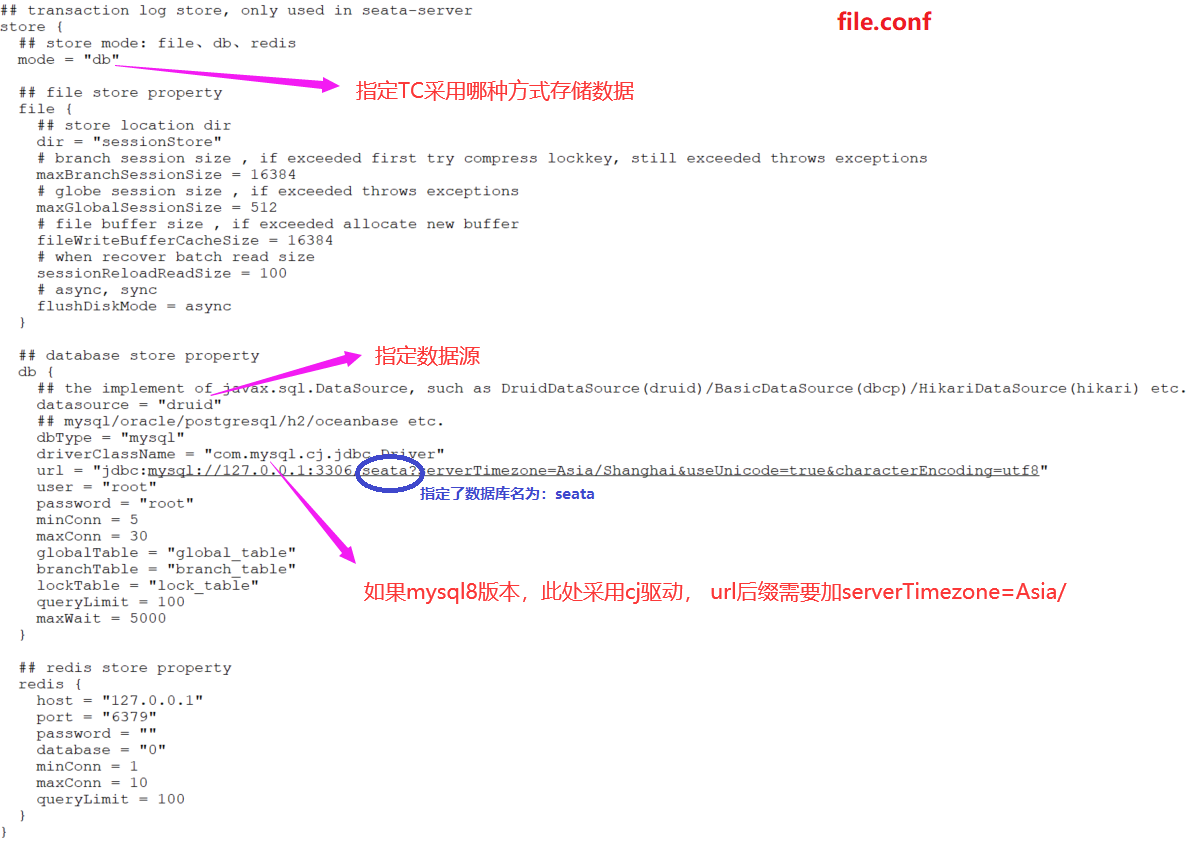
4.2 去把TC(事务协调者)要用的表建起来
先去建个数据库,名字可以随便取,但是最好叫seata。因为后面要该我们的配置,默认它就叫seata,你不叫seata的话,后面配置的时候就得跟着改。
-- the table to store GlobalSession data
drop table if exists `global_table`;
create table `global_table` (
`xid` varchar(128) not null,
`transaction_id` bigint,
`status` tinyint not null,
`application_id` varchar(32),
`transaction_service_group` varchar(32),
`transaction_name` varchar(128),
`timeout` int,
`begin_time` bigint,
`application_data` varchar(2000),
`gmt_create` datetime,
`gmt_modified` datetime,
primary key (`xid`),
key `idx_gmt_modified_status` (`gmt_modified`, `status`),
key `idx_transaction_id` (`transaction_id`)
);
-- the table to store BranchSession data
drop table if exists `branch_table`;
create table `branch_table` (
`branch_id` bigint not null,
`xid` varchar(128) not null,
`transaction_id` bigint ,
`resource_group_id` varchar(32),
`resource_id` varchar(256) ,
`lock_key` varchar(128) ,
`branch_type` varchar(8) ,
`status` tinyint,
`client_id` varchar(64),
`application_data` varchar(2000),
`gmt_create` datetime,
`gmt_modified` datetime,
primary key (`branch_id`),
key `idx_xid` (`xid`)
);
-- the table to store lock data
drop table if exists `lock_table`;
create table `lock_table` (
`row_key` varchar(128) not null,
`xid` varchar(96),
`transaction_id` long ,
`branch_id` long,
`resource_id` varchar(256) ,
`table_name` varchar(32) ,
`pk` varchar(36) ,
`gmt_create` datetime ,
`gmt_modified` datetime,
primary key(`row_key`)
);
-- the table to store seata xid data
-- 0.7.0+ add context
-- you must to init this sql for you business databese. the seata server not need it.
-- 此脚本必须初始化在你当前的业务数据库中,用于AT 模式XID记录。与server端无关(注:业务数据库)
-- 注意此处0.3.0+ 增加唯一索引 ux_undo_log
drop table `undo_log`;
CREATE TABLE `undo_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`branch_id` bigint(20) NOT NULL,
`xid` varchar(100) NOT NULL,
`context` varchar(128) NOT NULL,
`rollback_info` longblob NOT NULL,
`log_status` int(11) NOT NULL,
`log_created` datetime NOT NULL,
`log_modified` datetime NOT NULL,
`ext` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
4.3 修改registry.conf,指定nacos为我们的注册中心
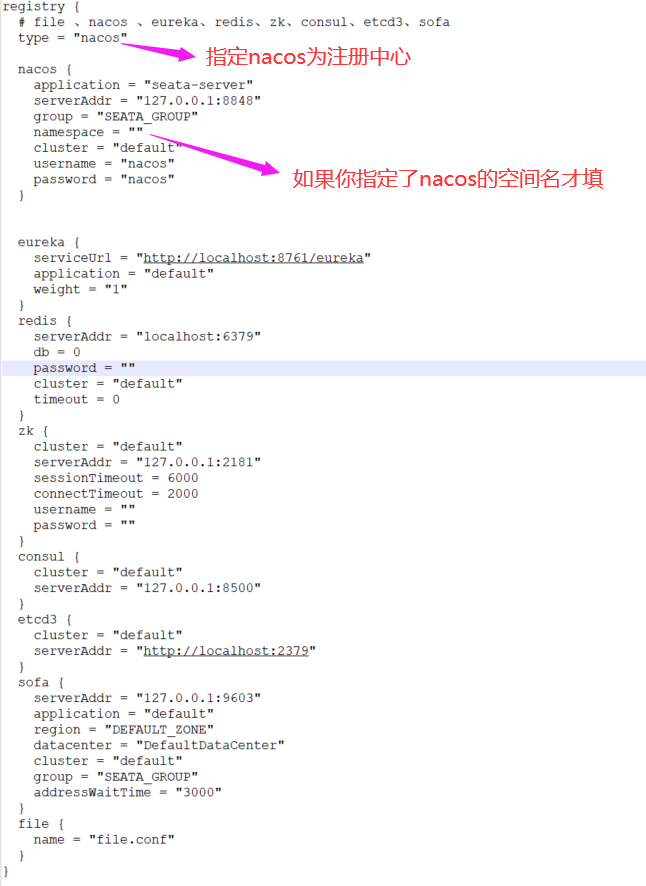
4.4 修改registry.conf,指定nacos为我们的配置中心

4.5 将nacos的配置文件批量推到nacos配置中心
前言:我们已经指定了配置中心,那么就需要把nacos的配置文件放到配置中心去。
但是因为nacos的配置文件贼多,nacos为我们提供了一个工具,方便我们快速的把配置文件批量推到nacos配置中心去。
步骤如下:
1. 下载config.txt。它是一个脚本文件,我们需要执行它,实现快速将配置文件批量推到nacos配置中心去。https://github.com/seata/seata/tree/develop/script/config-center
2. 下载nacos-config.sh,用于执行推送脚本。https://github.com/seata/seata/tree/develop/script/config-center/nacos
3. 修改config.txt
1. 修改store.mode 值为db
2. 根据自己的数据库配置修改 store.db.xxxx 这块的配置
3. 修改 service.vgroupMapping.default_tx_group=default 这块内容
语法为: service.vgroup_mapping.${your-service-gruop}=default ,中间的${your-service-gruop} 为自己定义的服务组名称, 这个名称到时候配置文件.yml中用得到。
4. 执行nacos-config.sh。
# -h 主机
# -p 端口号
# -t 命名空间ID
# -u 用户名
# -p 密码
$ sh nacos-config.sh -h localhost -p 8848 -g SEATA_GROUP -u nacos -w nacos
# 当你运行成功后,你会发现你的nacos配置列表多了很多seata的配置文件,他们属于SEATA_GROUP配置组。

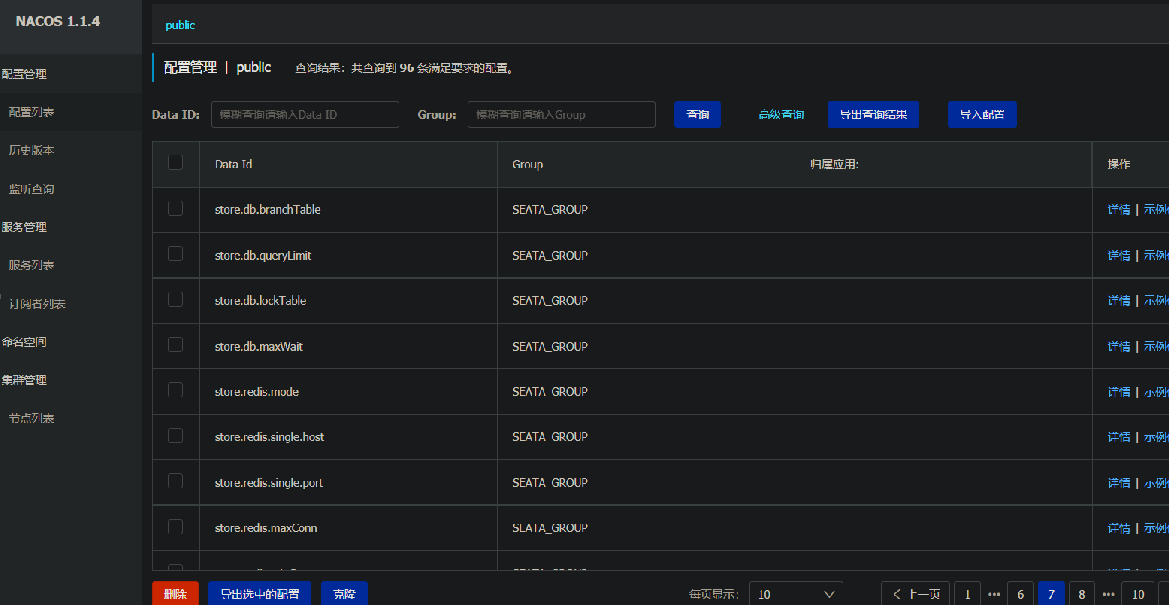
4.6 开发我们的RM-事务参与者
案例需求:下单减库存。
4.6.1 开发我们的RM-事务参与者-下订单服务
-- 库存服务DB执行
CREATE TABLE `tab_storage` (
`id` bigint(11) NOT NULL AUTO_INCREMENT,
`product_id` bigint(11) DEFAULT NULL COMMENT '产品id',
`total` int(11) DEFAULT NULL COMMENT '总库存',
`used` int(11) DEFAULT NULL COMMENT '已用库存',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
INSERT INTO `tab_storage` (`product_id`, `total`,`used`)VALUES ('1', '96', '4');
INSERT INTO `tab_storage` (`product_id`, `total`,`used`)VALUES ('2', '100','0');
-- 订单服务DB执行
CREATE TABLE `tab_order` (
`id` bigint(11) NOT NULL AUTO_INCREMENT,
`user_id` bigint(11) DEFAULT NULL COMMENT '用户id',
`product_id` bigint(11) DEFAULT NULL COMMENT '产品id',
`count` int(11) DEFAULT NULL COMMENT '数量',
`money` decimal(11,0) DEFAULT NULL COMMENT '金额',
`status` int(1) DEFAULT NULL COMMENT '订单状态:0:创建中;1:已完成',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
server:
port: 6770
spring:
application:
name: order-service
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: root
url: jdbc:mysql://localhost:3306/seata_tb_order?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf8&rewriteBatchedStatements=true
cloud:
nacos:
discovery:
server-addr: 127.0.0.1:8848
register-enabled: true
config:
server-addr: 127.0.0.1:8848
enabled: true
file-extension: yaml
seata:
enabled: true
application-id: ${spring.application.name}
# 事务群组(可以每个应用独立取名,也可以使用相同的名字),要与服务端nacos-config.txt中service.vgroup_mapping的后缀对应
tx-service-group: my_test_tx_group
config:
type: nacos
# 需要和server在同一个注册中心下
nacos:
serverAddr: 127.0.0.1:8848
# 需要server端(registry和config)、nacos配置client端(registry和config)保持一致
group: SEATA_GROUP
username: nacos
password: nacos
registry:
type: nacos
nacos:
# 需要和server端保持一致,即server在nacos中的名称,默认为seata-server
application: seata-server
server-addr: 127.0.0.1:8848
group: SEATA_GROUP
username: nacos
password: nacos
mybatis:
mapperLocations: classpath:mapper/*.xml
4.6.2 开发我们的RM-事务参与者-减库存服务
server:
port: 6780
spring:
application:
name: storage-service
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: root
url: jdbc:mysql://localhost:3306/seata_tb_storage?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf8&rewriteBatchedStatements=true
cloud:
nacos:
discovery:
server-addr: localhost:8848
register-enabled: true
config:
server-addr: localhost:8848
enabled: true
file-extension: yaml
seata:
enabled: true
application-id: ${spring.application.name}
# 事务群组(可以每个应用独立取名,也可以使用相同的名字),要与服务端nacos-config.txt中service.vgroup_mapping的后缀对应
tx-service-group: my_test_tx_group
config:
type: nacos
# 需要和server在同一个注册中心下
nacos:
serverAddr: localhost:8848
# 需要server端(registry和config)、nacos配置client端(registry和config)保持一致
group: SEATA_GROUP
username: nacos
password: nacos
registry:
type: nacos
nacos:
# 需要和server端保持一致,即server在nacos中的名称,默认为seata-server
application: seata-server
server-addr: localhost:8848
group: SEATA_GROUP
username: nacos
password: nacos
mybatis:
mapperLocations: classpath:mapper/*.xml
4.6.2 开发我们的TM-事务发起者-调用下订单减库存服务
server:
port: 6760
spring:
application:
name: business-service
cloud:
nacos:
discovery:
server-addr: 127.0.0.1:8848
register-enabled: true
config:
server-addr: 127.0.0.1:8848
enabled: true
file-extension: yaml
seata:
enabled: true
application-id: ${spring.application.name}
# 事务群组(可以每个应用独立取名,也可以使用相同的名字),要与服务端nacos-config.txt中service.vgroup_mapping的后缀对应
tx-service-group: my_test_tx_group
config:
type: nacos
# 需要和server在同一个注册中心下
nacos:
serverAddr: 127.0.0.1:8848
# 需要server端(registry和config)、nacos配置client端(registry和config)保持一致
group: SEATA_GROUP
username: nacos
password: nacos
registry:
type: nacos
nacos:
# 需要和server端保持一致,即server在nacos中的名称,默认为seata-server
application: seata-server
server-addr: 127.0.0.1:8848
group: SEATA_GROUP
username: nacos
password: nacos
mybatis:
mapperLocations: classpath:mapper/*.xml
# feign组件超时设置
feign:
client:
config:
default:
connect-timeout: 30000
read-timeout: 30000
@Autowired
private OrderClient orderClient;
@Autowired
private StorageClient storageClient;
@GetMapping("buy")
@GlobalTransactional
public String buy(long userId , long productId){
// 创建订单
orderClient.create(userId , productId);
// 扣减库存
int a = 1/0;
storageClient.changeStorage(userId , 1);
return "ok";
}
如此一来,就成功实现了分布式事务,其实我搭建过LCN,感觉LCN比Seata真是简单多少倍了
5. 聊聊原理
5.1 事务协调者-TC相关表
global_table:全局事务,每当有一个全局事务发起后,就会在该表中记录全局事务的ID
branch_table:分支事务,记录每一个分支事务的ID,分支事务操作的哪个数据库等信息
lock_table:全局锁

 浙公网安备 33010602011771号
浙公网安备 33010602011771号