
mybatis-plus多租户的使用
1. 什么是多租户,怎么理解多租户
多租户:多租户技术或称多重租赁技术,简称SaaS,是一种软件架构技术。它支持一个实例服务多个用户,每一个用户被称之为租户,且保证租户间数据隔离,并且保证每个用户的数据对其他租户不可见。它能给予租户可以对系统进行部分定制的能力,如:用户界面颜色或业务规则,但是他们不能定制修改软件的代码。
单租户:从多租户的定义可以看出,多租户下无法实现用户的定制化操作。单租户就可以。单租户是为每个客户单独创建各自的软件应用和支撑环境。单租户SaaS被广泛引用在客户需要支持定制化的应用场合,而这种定制或者是因为地域或他们需要更高的安全控制。在单租户的模式,每个客户都可以有一份分别放在独立的服务器上的数据库和操作系统,或者使用强的安全措施进行隔离的虚拟网络环境中。
2. 多租户的实现方案
方案一 独立数据库
一个租户一个数据库,这种方案的用户数据隔离级别最高,安全性最好,但成本较高。
- 优点:为不同的租户提供独立的数据库,有助于简化数据模型的扩展设计,满足不同租户的独特需求;如果出现故障,恢复数据比较简单。
- 缺点: 增多了数据库的安装数量,随之带来维护成本和购置成本的增加。
这种方案与传统的一个客户、一套数据、一套部署类似,差别只在于软件统一部署在运营商那里。如果面对的是银行、医院等需要非常高数据隔离级别的租户,可以选择这种模式,提高租用的定价。如果定价较低,产品走低价路线,这种方案一般对运营商来说是无法承受的。
方案二 共享数据库 独立数据架构
多个或所有租户共享Database,但是每个租户一个Schema(也可叫做一个user)。底层库比如是:DB2、ORACLE等,一个数据库下可以有多个SCHEMA。
- 优点: 为安全性要求较高的租户提供了一定程度的逻辑数据隔离,并不是完全隔离;每个数据库可支持更多的租户数量。
- 缺点: 如果出现故障,数据恢复比较困难,因为恢复数据库将牵涉到其他租户的数据; 如果需要跨租户统计数据,存在一定困难。
方案三 共享数据库,共享数据架构,共享数据表
租户共享同一个Database、同一个Schema,但在表中增加多租户ID的数据字段。这是共享程度最高、隔离级别最低的模式。即每插入一条数据时都需要有一个客户的标识。这样才能在同一张表中区分出不同客户的数据。
比如:我们现在要做一个社区多租户SaaS项目,每个社区的数据独立,那么我们设计表的时候大多数表可能都要有社区id字段用来区分不同的社区。
- 优点:三种方案比较,第三种方案的维护和购置成本最低,允许每个数据库支持的租户数量最多。
- 缺点: 隔离级别最低,安全性最低,需要在设计开发时加大对安全的开发量; 数据备份和恢复最困难,需要逐表逐条备份和还原。
3. 基于Mybatis-plus多租户实战落地
前言:不用多租户的架构,采用原始的方式也是可行的,只是原始的方式是在每一个接口都添加租户标识参数,这种方法虽然能够实现,但是造成了一定量的代码冗余。
参考:
https://blog.csdn.net/weixin_38111957/article/details/101161660
https://blog.csdn.net/qq_34936541/article/details/100048199?utm_term=springboot多租户实现&utm_medium=distribute.pc_aggpage_search_result.none-task-blog-2allsobaiduweb~default-4-100048199&spm=3001.4430
MP提供了一种多租户的解决方案,实现方式是基于分页插件进行实现的。
// 多租户配置类
@Configuration
public class MybatisPlusTenantConfig {
// 定义当前的多租户标识字段
private static final String SYSTEM_TENANT_ID = "shop_id";
// 定义当前有哪些表要忽略多租户的操作
private static final List<String> IGNORE_TENANT_TABLES = new ArrayList<String>();
// 创建PaginationInterceptor拦截器 其实实现方式是基于分页插件进行实现的
@Bean
public PaginationInterceptor paginationInterceptor() {
// 创建租户SQL解析器
PaginationInterceptor paginationInterceptor = new PaginationInterceptor();
// 创建SQL解析器,会对sql进行拦截处理。
TenantSqlParser tenantSqlParser = new TenantSqlParser();
tenantSqlParser.setTenantHandler(new TenantHandler() {
// 用于设置租户id的值
@Override
public Expression getTenantId(boolean where) {
// 暂时写死租户id的值,用于测试
String shopIdValue = "test";
return new StringValue(shopIdValue);
}
// 设置租户id所对应的 表字段
@Override
public String getTenantIdColumn() {
return "shop_id";
}
// 设置表级过滤器 用于设置哪些表不需要这个多租户操作,即操作sql的时候,不带shopId
@Override
public boolean doTableFilter(String tableName) {
// 忽略掉一些表:如租户表(provider)本身不需要执行这样的处理。
return IGNORE_TENANT_TABLES.stream().anyMatch((e) -> e.equalsIgnoreCase(tableName));
}
});
// 创建SQL解析器集合
List<ISqlParser> sqlParserList = new ArrayList<>();
sqlParserList.add(tenantSqlParser);
// 设置SQL解析器集合
paginationInterceptor.setSqlParserList(sqlParserList);
return paginationInterceptor;
}
}
@SpringBootTest
@RunWith(SpringRunner.class)
public class StoreTest {
@Reference(version = "1.0.0", check = false)
private IStoreService storeService;
@Test
@Rollback(false)
public void saveTest() {
Store store = new Store();
store.setBrandId("test");
store.setStoreName("测试");
store.setProvince("北京");
store.setCity("昌平区");
store.setArea("金燕龙大厦");
store.setAddress("北京 昌平区 金燕龙大厦");
// 这里没有设置shopId的值
storeService.save(store);
}
@Test
public void queryTest() {
Store store = storeService.getById("1400885090552180737");
System.out.println(store);
}
}
配置好之后,不管是查询、新增、修改删除方法,MP都会自动加上租户ID的标识。

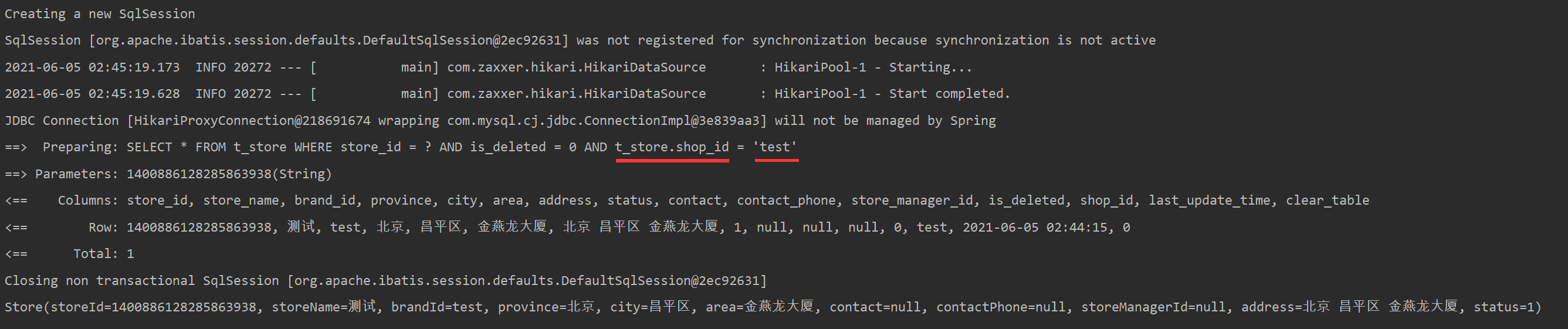
某些特定语句需要不过滤租户条件,比喻运营管理时候看所有用户什么的,可以在Mapper上租户注解的形式实现。
@Repository
public interface SysUserMapper extends BaseMapper<SysUser> {
/**
* 根据条件分页查询用户列表
*
* @param sysUser 用户信息
* @return 用户信息集合信息
*/
@SqlParser(filter = true)
public List<SysUser> selectUserList(@Param(Constants.WRAPPER) Wrapper<User> userWrapper, @Param("user")SysUser sysUser);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号