

数据库,缓存数据一致性常用解决方案总结
1. 为什么要使用缓存
使用缓存的好处:减少服务器的压力,数据查询速度快。解决数据响应慢的问题。
2. 使用缓存的常见场景
轮播图
广告
菜单
2.1 是否使用缓存的考量点
- 项目的读写操作比例为多少,如果是写多读少,那缓存真的不一定能帮助你,此时不妨考虑数据库分库分表,然后做MySQL的分布式集群,或者简单直接,将硬盘全部替换为SSD(如果你的公司财大气粗),反之,以读为主的项目就比较适合加缓存了.
- 项目的访问频率高不高(用户多不多)?如果用户区区几千人或几万人,全然没有必要使用缓存,这点访问量经过网络后几乎不会造成并发,即使偶出现几万的并发,MySQL也是扛得住的,强行使用缓存反而会增加代码复杂度,甚至不容易维护,得不偿失。
- 数据是否要求强一致性?如果项目涉及到金钱或者重要数据,且数据频繁发生变化,不允许存在一点差异,那是否使用缓存就要慎重慎重再慎重!因为缓存适用的是对数据一致性不是特别高的项目,如果使用,需要对缓存的设计有很好的方案,非常考验技术功底.
3. 使用缓存的步骤
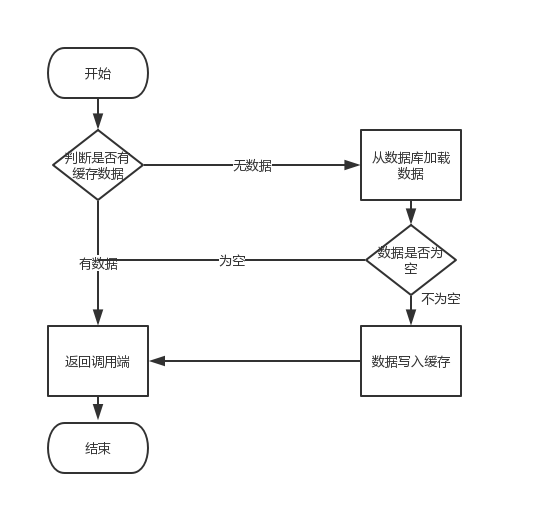
- 首先需要在执行正常的业务逻辑之前(查询数据库之前),查询缓存,如果缓存中没有需要的数据,查询数据库。为了防止添加缓存出错,影响正常业务代码的执行,将添加缓存的代码放置到try-catch代码快中,让程序自动捕获。
- 完成数据库的查询操作之后需要将查询的数据添加到缓存中。
4. 数据库和缓存双写一致性问题
一般情况下更新数据表时,缓存的操作:先更改数据表,然后删除缓存。
场景:当我们更改数据表后,缓存还没来的及更改。而我们项目并发比较高,此时用户来了一个查询,他走的就是缓存的数据。查到的就是脏数据。
解决方案一:
https://www.cnblogs.com/rjzheng/p/9041659.html
https://mp.weixin.qq.com/s/gYQvP69sao8U0azuNRMG1w
延时双删
public void write(String key,Object data){
redis.delKey(key); // 先淘汰缓存
db.updateData(data); // 再写数据库(这两步和原来一样)
Thread.sleep(1000); // 休眠1秒
redis.delKey(key); // 再次淘汰缓存
}
这么做,可以将1秒内所造成的缓存脏数据,再次删除。
那么,这个1秒怎么确定的,具体该休眠多久呢?
针对上面的情形,读者应该自行评估自己的项目的读数据业务逻辑的耗时。然后写数据的休眠时间则在读数据业务逻辑的耗时基础上,加几百ms即可。这么做的目的,就是确保读请求结束,写请求可以删除读请求造成的缓存脏数据。

