Java对象内存结构、对象在内存是什么样的
我们知道Java对象分配在堆内存中,一个对象在堆内存中的存储布局可以分为三部分:
- 对象头Header
- 实例数据
- 对齐填充
1. 对象头Header
对象头部分又包含两部分:
- 第一部分是用于存储对象自身运行时数据,例如哈希码、GC分代年龄等
- 第二部分就是类型指针,即此对象是哪一个类的实例。
如果是Java数组对象,那么除了这两部分外,还会有一部分用来记录数组的长度。
先说运行时数据,这个是最重要的
1.1 运行时数据
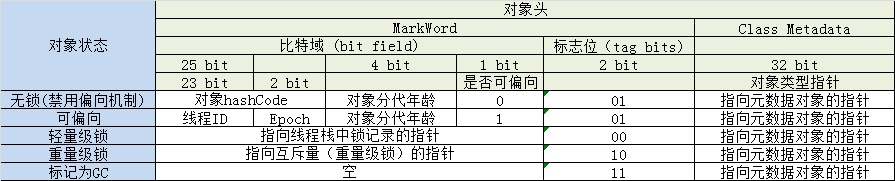
Java对象的对象头中,这部分存储Java对象运行时的数据,这些数据可以是哈希码、GC分代年龄、锁标志状态等等,这部分数据被官方称为“Mark Word"。
这部分数据的长度在32位和64位的虚拟机中分别是32bit和64bit。
由于对象要存储的运行时数据很多,超过了32bit、64bit,为了提高利用效率,“Mark Word"中的内容是动态改变的。
以32bit的虚拟机为例:
“Mark Word"占用32位,有两位用来作为标记位,标记对象的锁状态,在不同的锁状态下,”Mark Word"真正存储的数据是不一样的。

| 锁标志位 | 锁状态 | 真正存储的内容 |
|---|---|---|
| 01 | 未锁定(可不偏向) | 对象的哈希码、分代年龄 |
| 00 | 轻量级锁定 | 指向锁记录的指针 |
| 10 | 重量级锁定(膨胀) | 指向重量级锁的指针 |
| 11 | GC标记 | 空,不需要记录信息 |
| 01 | 可偏向 | 偏向线程ID、偏向时间戳、对象分代年龄等 |
1.2 类型指针
指向此对象类型元数据的指针,JVM就是通过这个指针来判断这个对象是哪一个类的实例。
2. 实例数据
就是对象真正存储的数据信息,例如一些字段、属性的值等。
3. 对齐填充
举个例子,语文作文要求至少400字,那么我为了凑够这400字,在作文末尾连续写了很多个标点符号。
那么在对象中,这一部分的作用也是这样的,这一部分不是必然存在的,没有特别的含义,就是为了凑够对象所占用的字节数。
HotSpot虚拟机的自动内存管理要求对象的起始地址必须是8字节的整数倍,换句话说,就是任何Java对象的大小都必须是8字节的整数倍,那么对齐填充这一部分就是为了使对象能够达到8字节整数倍的大小,当对象除了对齐填充外的其他部分的大小已经满足8字节的整数倍了,那么就不需要对齐填充了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号