Go语言 参数传递究竟是值传递还是引用传递的问题分析
之前我们谈过,在Go语言中的引用类型有:映射(map),数组切片(slice),通道(channel),方法与函数。起初我一直认为,除了以上说的五种是引用传递外,其他的都是值传递,也就是Go语言中存在值传递与引用传递,但事实真的如所想的这样吗?
我们知道在内存中的任何东西都有自己的内存地址,普通值,指针都有自己的内存地址
i := 10 ip := &i i的内存地址为: 0xc042060080,i的指针的内存地址为 0xc042080018
比如 我们创建一个整型变量 i,该变量的值为10,有一个指向整型变量 i 的指针ip,该ip包含了 i 的内存地址 0xc042060080 。但是ip也有自己的内存地址 0xc042080018。
那么在Go语言传递参数时,我们可能会有以下两种假设:
①函数参数传递都是值传递,也就是传递原值的一个副本。无论是对于整型,字符串,布尔,数组等非引用类型,还是映射(map),数组切片(slice),通道(channel),方法与函数等引用类型,前者是传递该值的副本的内存地址,后者是传递该值的指针的副本的内存地址。
②函数传递时,既包含整型,字符串,布尔,数组等非引用类型的值传递,传递该值的副本,也包括映射(map),数组切片(slice),通道(channel),方法与函数等引用类型的引用传递,传递该值的指针。
现在我们根据上述两种假设来探讨一下。
首先我们知道对于非引用类型:整型,字符串,布尔,数组在当作参数传递时,是传递副本的内存地址,也就是值传递
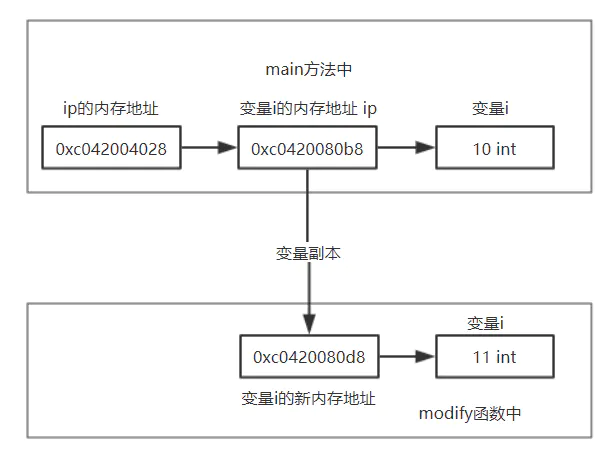
func main() { i := 10 //整形变量 i ip := &i //指向整型变量 i 的指针ip,包含了 i 的内存地址 fmt.Printf("main中i的值为:%v,i 的内存地址为:%v,i的指针的内存地址为:%v\n",i,ip,&ip) modifyBypointer(i) fmt.Printf("main中i的值为:%v,i 的内存地址为:%v,i的指针的内存地址为:%v\n",i,ip,&ip) } func modify(i int) { fmt.Printf("modify i 为:%v,i的指针的内存地址为:%v\n",i,&i) i = 11 } ----output---- main中 i 的值为:10,i 的内存地址为:0xc0420080b8,i 的指针的内存地址为:0xc042004028 modify i 为:10,i 的指针的内存地址为:0xc0420080d8 main中 i 的值为:10,i 的内存地址为:0xc0420080b8,i 的指针的内存地址为:0xc042004028
上面在函数接收的参数中没有使用指针,所以在传递参数时,传递的是该值的副本,内存地址会改变,因此在函数中对该变量进行操作不会影响到原变量的值。
内存分布图如下:
如果我将上面函数的参数传递方式改一下,改为接收参数的指针
func main() { i := 10 //整形变量 i ip := &i //指向整型变量 i 的指针ip,包含了 i 的内存地址 fmt.Printf("main中i的值为:%v,i 的内存地址为:%v,i的指针的内存地址为:%v\n",i,ip,&ip) modifyBypointer(ip) fmt.Printf("main中i的值为:%v,i 的内存地址为:%v,i的指针的内存地址为:%v\n",i,ip,&ip) } func modifyBypointer(i *int) { fmt.Printf("modifyBypointer i 的内存地址为:%v,i的指针的内存地址为:%v\n",i,&i) *i = 11 } ---output--- main中i的值为:10,i 的内存地址为:0xc042060080,i的指针ip的内存地址为:0xc042080018 modifyBypointer i 的内存地址为:0xc042060080,i的指针ip的内存地址为:0xc042080028 main中i的值为:11,i 的内存地址为:0xc042060080,i的指针ip的内存地址为:0xc042080018
将函数的参数改为传递指针后,函数内部对变量的修改就会影响到原变量的值,且不会影响到原变量的内存地址。但是可以看出main中各个参数的内存地址与函数中接收到的内存地址不一致,也就是说指针作为函数参数的传递过程中,是传递了该指针的副本地址,不是原指针地址。
那么既然函数中的指针地址与main中的指针地址不一致,那么我们在函数中对变量进行修改时,函数中对变量的修改又怎么会影响到main中原变量的值呢?
这是因为,虽然函数中的指针地址与main中的指针地址不一致,但是它们都指向同一个整形变量的内存地址,所以无论哪一方对变量i进行操作都会影响到变量i,且另一方是可以观察到的。
我们来看一下这个内存分布图

到目前为止,我们验证了非引用类型和指针的参数传递都是传递副本,那么对于引用类型的参数传递又是如何的呢?
①映射map
我们使用make初始化一个映射map时,实际上返回的是该映射map的一个指针,具体源码如下
// makemap implements Go map creation for make(map[k]v, hint). // If the compiler has determined that the map or the first bucket // can be created on the stack, h and/or bucket may be non-nil. // If h != nil, the map can be created directly in h. // If h.buckets != nil, bucket pointed to can be used as the first bucket. func makemap(t *maptype, hint int, h *hmap) *hmap {}
也就是说,对于引用类型map来讲,实际上在作为传递参数时还是使用了指针的副本进行传递,属于值传递。
②chan类型
使用make初始化 chan类型,底层其实跟map一样,都是返回该值的指针
func makechan(t *chantype, size int) *hchan {}
③Slice类型
Slice类型对于之前的map,chan类型不太一样,比如下面这个代码示例
func main() { i := []int{1,2,3} fmt.Printf("i:%p\n",i) fmt.Println("i[0]:",&i[0]) fmt.Printf("i:%v\n",&i) } ---output--- i:0xc04205e0c0 i[0]: 0xc04205e0c0 i:&[1 2 3]
我们可以看到,使用&操作符表示slice的地址是无效的,而且使用%p输出的内存地址与slice的第一个元素的地址是一样的,那么为什么会出现这样的情况呢?
我们来看一下在 fmt/print.go中的printValue函数源码
case reflect.Ptr: // pointer to array or slice or struct? ok at top level // but not embedded (avoid loops) if depth == 0 && f.Pointer() != 0 { switch a := f.Elem(); a.Kind() { case reflect.Array, reflect.Slice, reflect.Struct, reflect.Map: p.buf.WriteByte('&') //这就是 使用 &打印地址输出结果前面带有“&”的原因 p.printValue(a, verb, depth+1) //然后递归获取vaule的内容 return } }
如果是slice或者数组就用[]包围
} else { p.buf.WriteByte('[') for i := 0; i < f.Len(); i++ { if i > 0 { p.buf.WriteByte(' ') } p.printValue(f.Index(i), verb, depth+1) } p.buf.WriteByte(']') }
以上就是为什么使用 fmt.Printf("i:%v\n",&i) 会输出 i:&[1 2 3]的原因。
然后我们再来分析一下为什么使用%p输出的内存地址与slice的第一个元素的地址是一样的。
继续看fmt/print.go中的 fmtPointer 源码
func (p *pp) fmtPointer(value reflect.Value, verb rune) { var u uintptr switch value.Kind() { case reflect.Chan, reflect.Func, reflect.Map, reflect.Ptr, reflect.Slice, reflect.UnsafePointer: u = value.Pointer() default: p.badVerb(verb) return }
通过源代码发现,对于chan、map、slice,Func等被当成指针处理,通过value.Pointer获取对应的值的指针。
value.Pointer的源码如下:
// 如果v的类型是Func,则返回的指针是底层代码指针,但不一定足以唯一地标识单个函数。 // 唯一的保证是当且仅当v是nil func值时结果为零。 // //如果v的类型是Slice,则返回的指针指向切片的第一个元素。 //如果切片为nil,则返回值为0。如果切片为空但非nil,则返回值为非零。 func (v Value) Pointer() uintptr { k := v.kind() switch k { case Chan, Map, Ptr, UnsafePointer: return uintptr(v.pointer()) case Func: if v.flag&flagMethod != 0 { f := methodValueCall return **(**uintptr)(unsafe.Pointer(&f)) } p := v.pointer() // Non-nil func value points at data block. // First word of data block is actual code. if p != nil { p = *(*unsafe.Pointer)(p) } return uintptr(p) case Slice: return (*SliceHeader)(v.ptr).Data } panic(&ValueError{"reflect.Value.Pointer", v.kind()}) }
所以当是slice类型的时候,fmt.Printf返回是slice这个结构体里第一个元素的地址。说到底,又转变成了指针处理,只不过这个指针是slice中第一个元素的内存地址。之前说Slice类型对于之前的map,chan类型不太一样,不一样就在于slice是一种结构体+第一个元素指针的混合类型,通过元素array(Data)的指针,可以达到修改slice里存储元素的目的。
根据slice与map,chan对比,我们可以总结一条规律:
可以通过某个变量类型本身的指针(如map,chan)或者该变量类型内部的元素的指针(如slice的第一个元素的指针)修改该变量类型的值。
因此slice也跟chan与map一样,属于值传递,传递的是第一个元素的指针的副本。
总结:在Go语言中只存在值传递(要么是该值的副本,要么是指针的副本),不存在引用传递。之所以对于引用类型的传递可以修改原内容数据,是因为在底层默认使用该引用类型的指针进行传递,但是也是使用指针的副本,依旧是值传递。
思考问题:
①既然slice是使用第一个元素的内存地址作为slice的指针,那么如果出现两个相同的slice,它们的指针岂不会相同
②slice在作为参数传递时,可以修改原slice的数据,那么可以修改原slice的len和cap吗
转载:https://www.jianshu.com/p/f201d6da488a

 浙公网安备 33010602011771号
浙公网安备 33010602011771号