JVM 编译期处理 & 类加载机制 & 运行期优化
😉 本文共6125字,阅读时间约12min
编译期处理#
所谓的 语法糖 ,其实java源码编译成class字节码的过程中,自动生成和转换的一些代码。
注意,以下代码的分析,借助了 javap 工具,idea 的反编译功能,idea 插件 jclasslib 等工具。另外, 编译器转换的 结果直接就是 class 字节码,只是为了便于阅读,给出了 几乎等价 的 java 源码方式,并不是编译器还会转换出中间的 java 源码,切记。
自动拆装箱#
基本类型和其包装类型的相互转换过程,称为拆装箱。编译器自动完成。
public class Candy2 {
public static void main(String[] args) {
Integer x = 1; // Integer x = Integer.valueOf(1);
int y = x; // int y = x.intValue();
}
}
泛型集合取值#
编译期执行泛型擦除的动作,即泛型信息在编译为字节码之后就丢失了,实际的类型都当做了 Object 类型处理。
public class Candy3 {
public static void main(String[] args) {
// 编译期泛型擦除
List<Integer> list = new ArrayList<>();
list.add(10);
Integer x = list.get(0);
}
}
// 所以调用 get 函数取值时,编译期有一个类型转换的操作。
Integer x = (Integer) list.get(0);
// 如果要将返回结果赋值给一个 int 类型的变量,则还有自动拆箱的操作
int x = (Integer) list.get(0).intValue();
匿名内部类#
匿名内部类也就是没有名字的内部类,使用匿名内部类还有个前提条件:必须继承一个父类或实现一个接口。
public class Candy10 {
public static void main(String[] args) {
Runnable runnable = new Runnable() {
@Override
public void run() {
System.out.println("running...");
}
};
}
}
转换后代码:
// 用一个类实现接口
final class Candy11$1 implements Runnable {
int val$x;
Candy11$1(int x) {
this.val$x = x;
}
public void run() {
System.out.println("ok:" + this.val$x);
}
}
public class Candy11 {
public static void test(final int x) {
Runnable runnable = new Candy11$1(x);
}
}
注意:这同时解释了为什么匿名内部类引用局部变量时,局部变量必须是 final 的:因为在创建 Candy111 对象的 值后,如果不是 final 声明的 x 值发生了改变,匿名内部类则值不一致。
异常处理#
try-catch
public class Code_15_TryCatchTest {
public static void main(String[] args) {
int i = 0;
try {
i = 10;
}catch (Exception e) {
i = 20;
}
}
}
对应字节码指令
Code:
stack=1, locals=3, args_size=1
0: iconst_0
1: istore_1
2: bipush 10
4: istore_1
5: goto 12
8: astore_2
9: bipush 20
11: istore_1
12: return
Exception table:
from to target type
2 5 8 Class java/lang/Exception
- 可以看到多出来一个 Exception table 的结构,[from, to) 是前闭后开(也就是检测 2~4 行)的检测范围,一旦这个范围内的字节码执行出现异常,则通过 type 匹配异常类型,如果一致,进入 target 所指示行号
- 8 行的字节码指令 astore_2 是将异常对象引用存入局部变量表的 2 号位置(为 e )
多个 single-catch
public class Code_16_MultipleCatchTest {
public static void main(String[] args) {
int i = 0;
try {
i = 10;
}catch (ArithmeticException e) {
i = 20;
}catch (Exception e) {
i = 30;
}
}
}
对应的字节码
Code:
stack=1, locals=3, args_size=1
0: iconst_0
1: istore_1
2: bipush 10
4: istore_1
5: goto 19
8: astore_2
9: bipush 20
11: istore_1
12: goto 19
15: astore_2
16: bipush 30
18: istore_1
19: return
Exception table:
from to target type
2 5 8 Class java/lang/ArithmeticException
2 5 15 Class java/lang/Exception
- 因为异常出现时,只能进入 Exception table 中一个分支,所以局部变量表 slot 2 位置被共用
finally
public class Code_17_FinallyTest {
public static void main(String[] args) {
int i = 0;
try {
i = 10;
} catch (Exception e) {
i = 20;
} finally {
i = 30;
}
}
}
对应字节码
Code:
stack=1, locals=4, args_size=1
0: iconst_0
1: istore_1
2: bipush 10
4: istore_1
5: bipush 30
7: istore_1
8: goto 27
11: astore_2
12: bipush 20
14: istore_1
15: bipush 30
17: istore_1
18: goto 27
21: astore_3
22: bipush 30
24: istore_1
25: aload_3
26: athrow
27: return
Exception table:
from to target type
2 5 11 Class java/lang/Exception
2 5 21 any
11 15 21 any
可以看到 finally 中的代码被复制了 3 份,分别放入 try 流程,catch 流程以及 catch 剩余的异常类型流程
注意:虽然从字节码指令看来,每个块中都有 finally 块,但是 finally 块中的代码只会被执行一次
finally 中的 return
public class Code_18_FinallyReturnTest {
public static void main(String[] args) {
int i = Code_18_FinallyReturnTest.test();
System.out.println(i);
}
public static int test() {
int i;
try {
i = 10;
return i;
} finally {
i = 20;
return i;
}
}
}
对应字节码
Code:
stack=1, locals=3, args_size=0
0: bipush 10
2: istore_0
3: iload_0
4: istore_1
5: bipush 20
7: istore_0
8: iload_0
9: ireturn
10: astore_2
11: bipush 20
13: istore_0
14: iload_0
15: ireturn
Exception table:
from to target type
0 5 10 any
- 由于 finally 中的 ireturn 被插入了所有可能的流程,因此返回结果肯定以finally的为准
- 至于字节码中第 2 行,似乎没啥用,且留个伏笔,看下个例子
- 跟上例中的 finally 相比,发现没有 athrow 了,这告诉我们:如果在 finally 中出现了 return,会吞掉异常
- 所以不要在finally中进行返回操作
被吞掉的异常
public static int test() {
int i;
try {
i = 10;
i = i/0;
return i;
} finally {
i = 20;
return i;
}
}
会发现打印结果为 20 ,并未抛出异常
finally 不带 return
public static int test() {
int i = 10;
try {
return i;
} finally {
i = 20;
}
}
对应字节码
Code:
stack=1, locals=3, args_size=0
0: bipush 10
2: istore_0
3: iload_0
4: istore_1
5: bipush 20
7: istore_0
8: iload_1
9: ireturn
10: astore_2
11: bipush 20
13: istore_0
14: aload_2
15: athrow
Exception table:
from to target type
3 5 10 any
类加载机制#
懒加载模式,用到才加载
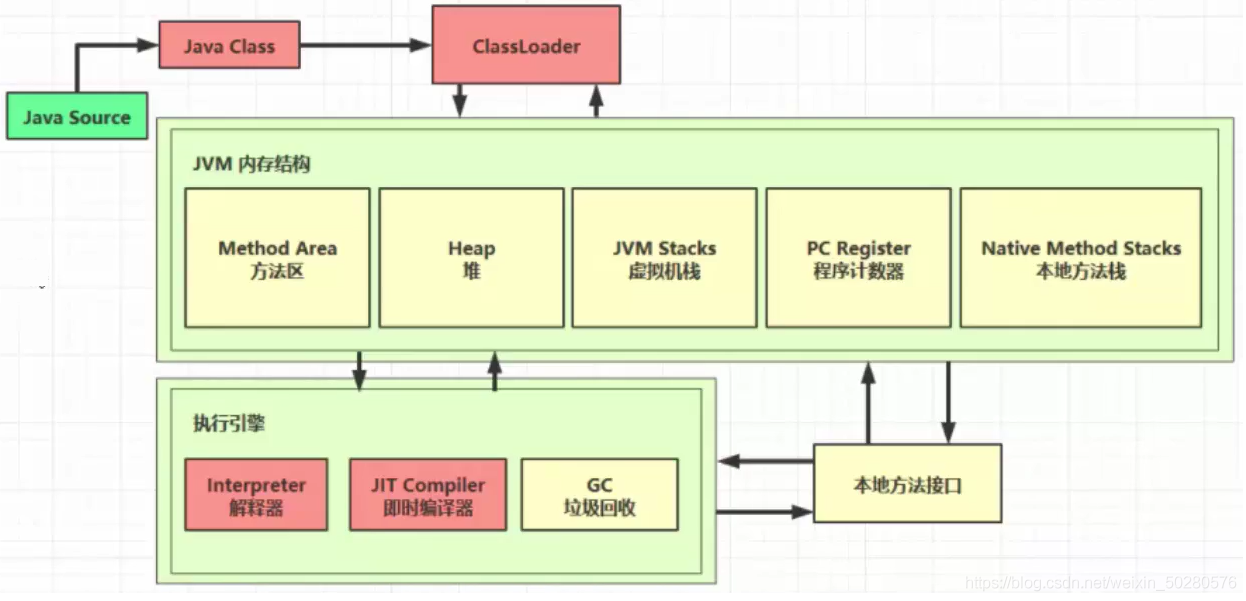
加载#
instanceKlass#
- 类的字节码文件载入方法区,并在堆中生成java mirror类对象
- 方法区使用 instanceKlass 描述 java 类,重要field有:
- java_mirror,java的类镜像,指向堆中的类对象。例如对 String 来说,它的镜像类就是 String.class,作用是把 klass 暴露给 java 使用。
- super,父类,如果这个类还有父类没有加载,先加载父类
- fields 即成员变量、methods 即方法
- _vtable 虚方法表
从对象到instanceKlass#
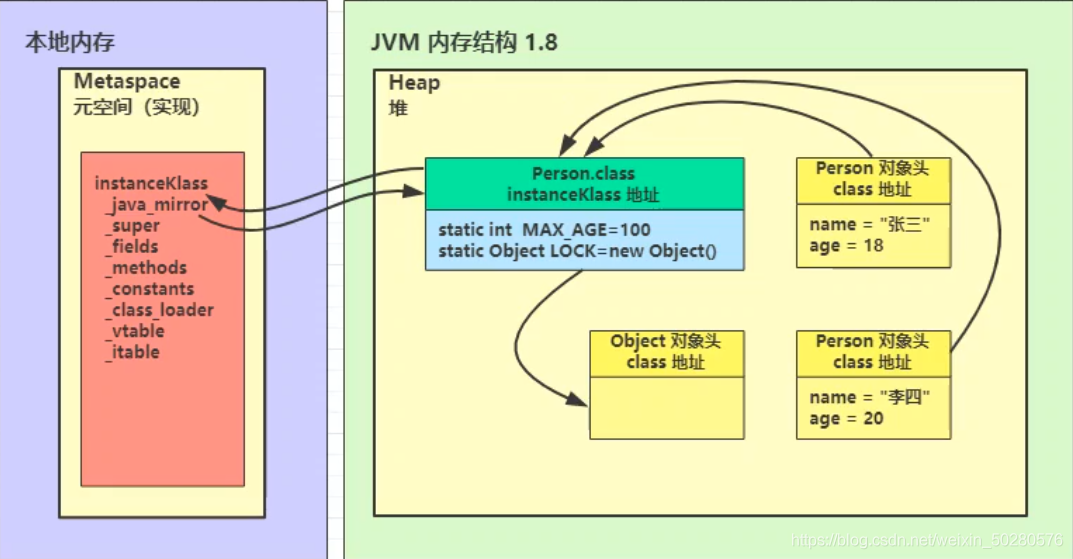
- instanceKlass保存在方法区。
- java_mirror则是保存在堆内存中
- InstanceKlass和*.class(JAVA镜像类)互持引用
- 对象的对象头保存了*.class(Java镜像类/类对象)的地址 => java mirror内找到元空间instanceKlass的引用 => 在instanceKlass里找到类的各种信息。
多态原理#
// Dog类父类是Animal,Dog类重写了Animal类的方法eat()
Animal a = new Dog();
a.eat();
-
因为普通成员方法在运行时才能确定具体的内容,所以虚拟机需要调用 invokevirtual 指令。
-
在执行 invokevirtual 指令时,经历了以下几个步骤:
- 先通过栈帧中对象的引用找到
dog对象(注意a不过是个引用罢了,还是到dog上) - 分析对象头,找到对象实际的java_mirror, 再找到方法区的instanceKlass
- instanceKlass结构中有虚方法表vtable
- 查询 vtable 找到方法的具体地址
- 执行方法的字节码
- 先通过栈帧中对象的引用找到
链接#
将Java类的二进制代码合并到JVM的运行状态之中的过程
验证#
验证类是否符合 JVM规范,安全性检查
用 UE 等支持二进制的编辑器修改 HelloWorld.class 的魔数,在控制台运行,验证不通过
魔数是为了方便虚拟机识别一个文件是否是class类型的文件,0xCAFEBABE。
准备#
static 变量分配空间和赋值是两个步骤,分配空间在准备阶段完成,赋值在初始化阶段完成
- 为 static 变量分配空间,设置默认值:
- static变量在6之前存储于 instanceKlass 末尾,从1.7开始,存储于 _java_mirror 末尾
- 如果 static 变量是 final 的基本类型,以及字符串常量,那么编译阶段值就确定了,赋值在准备阶段完成。
- 如果 static 变量是 final 的,但属于引用类型,那么赋值也会在初始化阶段完成将常量池中的符号引用解析为直接引用

解析#
将方法区中常量池的符号引用替换为直接引用。
public class Code_22_AnalysisTest {
public static void main(String[] args) throws ClassNotFoundException{
new C();
System.in.read();
}
}
class C { // C的d的符号引用在这一个改为直接引用,就是类D的地址
D d = new D();
}
class D {
}
初始化#
初始化阶段做了什么#
- 执行类构造器()方法的过程。类构造器方法是由编译期自动收集类中所有类变量的赋值动作和静态代码块中的语句合并产生的。(类构造器是构造类信息的,不是构造该类对象的构造器)。
- 当初始化一个类的时候,如果发现其父类还没有进行初始化,则需要先触发其父类的初始化。
发生的时机#
概括的说,类初始化是【懒惰的】
- main 方法所在的类,总会被首先初始化
- 首次访问这个类的静态变量或静态方法时
- 子类初始化,如果父类还没初始化,会引发父类先初始化
- 子类访问父类的静态变量,只会触发父类的初始化
- Class.forName
- new 会导致初始化
不会导致类初始化的情况
- 访问类的 static final 静态常量(基本类型和字符串)不会触发初始化
- 类对象.class 不会触发初始化
- 创建该类的数组不会触发初始化
public class Load1 {
static {
System.out.println("main init");
}
public static void main(String[] args) throws ClassNotFoundException {
}
}
class A {
static int a = 0;
static {
System.out.println("a init");
}
}
class B extends A {
final static double b = 5.0;
static boolean c = false;
static {
System.out.println("b init");
}
}
单例模式 - 懒惰初始化#
- 懒惰实例化
- 初始化时的线程安全是有保障的
// jvm会保证一个类的初始化阶段的构造器方法在多线程环境中被正确加锁和同步。
public class Singleton {
private Singleton() { }
private static class LazyHolder {
static final Singleton INSTANCE = new Singleton();
}
public static Singleton getInstance() {
return LazyHolder.INSTANCE;
}
}
【搞定Jvm面试】 面试官:谈谈 JVM 类加载过程是怎样的?
类加载器#
三种类加载器#
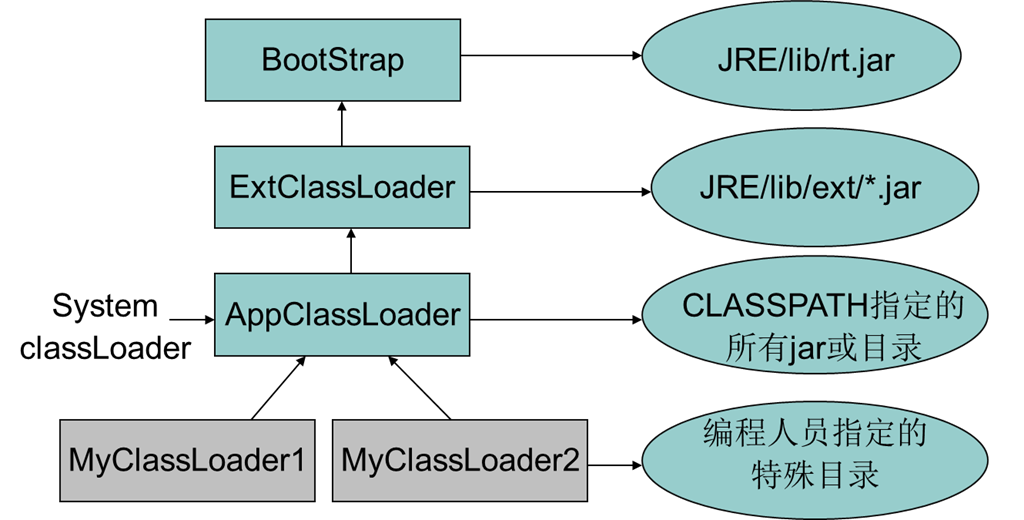
JVM类加载特点#
- 全盘负责: 当一个类加载器负责加载某个Class时,该Class所依赖的和引用的其他Class也将由该类加载器负责载入,除非显示使用另外一个类加载器来载入
- 父类委托(双亲委派模型): 先让父类加载器试图加载该类,只有在父类加载器无法加载该类时才尝试从自己的类路径中加载该类
- 缓存机制: 缓存机制将会保证所有加载过的Class都会被缓存,当程序中需要使用某个Class时,类加载器先从缓存区寻找该Class,只有缓存区不存在,系统才会读取该类对应的二进制数据,并将其转换成Class 对象,存入缓存区。这就是为什么修改了Class后,必须重启JVM,程序的修改才会生效
双亲委派机制#
- Java 虚拟机对 class file 采用的是按需加载的方式,也就是说,当需要使用该类才会将他的 class file 加载到内存中生成 class 对象。而且加载某个类的 class file 时,JVM 采取双亲委派模式,即把请求交由父类处理,他是一种任务委派模式
- 工作原理
- 如果一个类加载器收到了类加载的请求,他并不会自己先去加载,而是把这个请求委托给父类加载器去执行
- 如果一个父类加载器还存在其他父类加载器,则进一步向上委托,依次递归,请求最终达到顶层的 BootstrapClassLoader(引导类加载器)
- 如果父类加载器可以完成类加载任务,就成功返回,若父类加载器无法完成加载此任务,子加载器就会尝试自己去加载,这就是双亲委派模式
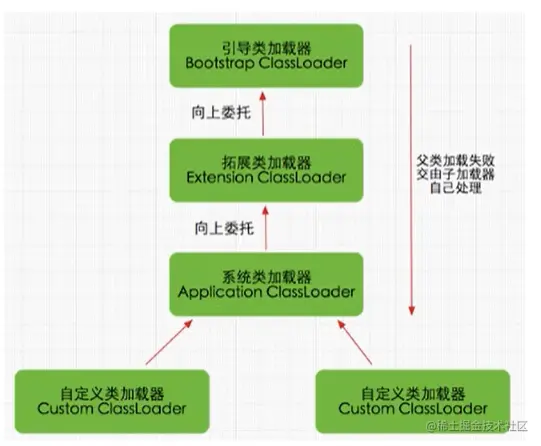
双亲委派机制的优势
- 避免类的重复加载
- 保护应用程序安全,防止核心 API 被篡改
如何破坏双亲委派机制
调用父加载器去加载类的逻辑是在loadClass里面实现的,所以我们要破坏双亲委托模型,只需要重写loadClass方法就可以。
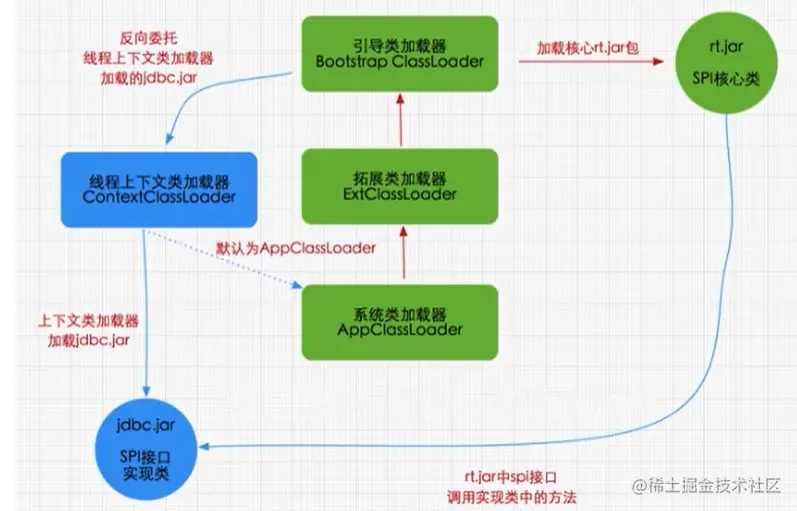
反向委托机制#
- 例如我们在项目中加载 JDBC 的有关类,当我们加载 jdbc.jar 用于实现数据库连接的时候。
- 首先我们需要知道的是 jdbc.jar 是基于 SPI 接口进行实现的,所以在加载的时候,会进行双亲委派机制,接口是由 BootstrapClassLoader 加载的
- 而具体接口的第三方实现类是由线程上下文类加载器加载的,也就是我们系统类加载器,来完成 jdbc.jar 的加载。(这两加载器是一个东西)
扩展:SPI 机制的实际应用就是如:JDBC包的加载、SpringBoot 自动装配原理等,作用是极大的减轻了框架之间的耦合度,使得扩展性大大增强,能更加便捷的引入外部包。
沙箱安全机制#
自定义 String 类,但是在加载自定义 String 类的时候会率先使用引导类加载器加载,而引导类加载器在加载的过程中会先加载 JDK 自带的文件(rt.jar包中 java\lang\String.class),报错信息说没有 main 方法,就是因为加载的是 rt.jar 包中的 String 类。这样可以保证对 Java 核心源代码的保护,这就是沙箱安全机制。
判断两个 Class 对象是否是同一个类#
- 类的全限定类名必须一致,且加载这两个类的 ClassLoader 必须相同
换句话说,在 JVM 中,即使这两个类对象(Class对象)来源同一个 class 文件,被同一个虚拟机所加载,但只要加载它们的 ClassLoader 实例对象不同,那么这两个类对象也是不相等的。
自定义类加载器#
使用场景
-
隔离加载类
这些类希望予以隔离,不同应用的同名类都可以加载,不冲突,常见于 tomcat 容器。
在某些框架当中需要使用中间件,中间件和应用模块是隔离的,所以就要把这些类加载到不同的环境当中,确保我们引用的框架、jar包,与中间件使用的 jar包是不冲突的
主要是由于中间件都有自己依赖的 jar包,而在同一个工程里面引入多个框架有可能会出现某些类路径一样、类名相同的情况。在这种情况下就会出现类的冲突。那么此时就要进行类的仲裁。像现在主流的容器类框架都会自定义一些类的加载器,从而实现不同的中间件相互之间是隔离的,避免类的冲突。
-
想加载非 classpath 随意路径中的类文件
-
防止源码泄漏:因为 Java 文件很容易被反编译,为了防止代码泄露或篡改,可以在字节码文件上加密,然后通过自定义的类加载器进行解密、加载
步骤
- 继承 ClassLoader 父类
- 要遵从双亲委派机制,重写 findClass 方法。不是重写 loadClass 方法,否则可能不会走双亲委派机制。
- 读取类文件的字节码,调用父类的 defineClass 方法来加载类
- 使用者调用该类加载器的 loadClass 方法
执行引擎#
GC#
不在此介绍
解释器#
字节码是由 Java 编译器生成的一种中间代码,它比机器码更加抽象,并且可以跨平台运行。
-
初衷:为了跨平台,避免采用静态编译将其转化为机器指令,运行时采用逐行动态解释字节码并执行程序。
-
工作机制
- 担任翻译者,将字节码文件中的内容翻译为机器指令并执行
- 每执行完一条指令后,便根据pc程序计数器执行下一条指令
-
分类
- 两套解释执行器为古老的字节码解释器和模板解释器。
- 字节码解释器:执行时通过纯软件代码模拟字节码的执行,效率低下
- 模板解释器:执行时将每一条字节码和一个模板函数相关联,模板函数直接产生这条字节码的机器指令,提高解释器的性能。
优缺点#
JVM 字节码解释器的优点在于可以跨平台运行,但是它的缺点在于运行速度相对较慢,因为它需要在运行时动态解释字节码。
为了提高程序的运行效率,可以使用 JIT(即时编译器)将字节码编译成机器码。
JIT编译器#
-
避免函数被直接解释执行,先将整个函数体编译成机器指令,再执行相应的机器指令,提高执行效率。
-
Java语言的编译过程时一段不确定的操作过程,可以是以下任意一种:
- 前端编译器:把.java文件转化为.class(字节码文件)的过程
- 后端编译器(jit编译):把字节码转为机器码的过程
- 静态提前编译器(AOP):直接把*.java文件编译为本地机器码的过程
-
采用热点代码及探测方式
- 根据代码被调用执行的频率,在执行期间根据哪些经常被调用的热点代码做深度优化,将其直接编译为机器码,提高执行效率。
- 热点代码:一个被多次调用的方法或一个方法体内部循环多次的循环体
运行期优化#
即时编译#
分层编译#
-
JVM 将执行状态分成了 5 个层次:
- 0层:解释执行,用解释器将字节码翻译为机器码
- 1层:使用 C1 即时编译器编译执行(不带 profiling)
- 2层:使用 C1 即时编译器编译执行(带基本的profiling)
- 3层:使用 C1 即时编译器编译执行(带完全的profiling)
- 4层:使用 C2 即时编译器编译执行
-
profiling 是指在运行过程中收集一些程序执行状态的数据,例如【方法的调用次数】、【循环的 次数】等
-
即时编译器(JIT)与解释器的区别
- 解释器
- 将字节码解释为机器码,下次即使遇到相同的字节码,仍会执行重复的解释
- 是将字节码解释为针对所有平台都通用的机器码
- 即时编译器
- 将一些字节码编译为机器码,并存入 Code Cache,下次遇到相同的代码,直接执行,无需再编译
- 根据平台类型,生成平台特定的机器码
- 解释器
-
对于大部分的不常用的代码,我们无需耗费时间将其编译成机器码,而是采取解释执行的方式运行;另一方面,对于仅占据小部分的热点代码,我们则可以将其编译成机器码,以达到理想的运行速度。 执行效率上简单比较一下 Interpreter < C1 < C2,总的目标是发现热点代码(hotspot名称的由 来),并优化这些热点代码。
那么 C1 编译模式和 C2 编译模式有什么区别呢?
C1 编译模式会将字节码编译为本地代码,进行简单、可靠的优化,如有必要将加入性能监控的逻辑。
而 C2 编译模式,也是将字节码编译为本地代码,但是会启用一些编译耗时较长的优化,甚至会根据性能监控信息进行一些不可靠的激进优化。
简单地说 C1 编译模式做的优化相对比较保守,其编译速度相比 C2 较快。而 C2 编译模式会做一些激进的优化,并且会根据性能监控做针对性优化,所以其编译质量相对较好,但是耗时更长。
逃逸分析#
虚拟机可以分析新创建对象的使用范围,并决定是否在 Java 堆上分配内存的一项技术
对象逃逸状态#
-
全局逃逸(GlobalEscape),即一个对象的作用范围逃出了当前方法或者当前线程,有以下几种场景:
- 对象是一个静态变量
- 对象是一个已经发生逃逸的对象
- 对象作为当前方法的返回值
-
参数逃逸(ArgEscape)
- 即一个对象被作为方法参数传递或者被参数引用,但在调用过程中不会发生全局逃逸,这个状态是通过被调方法的字节码确定的
-
没有逃逸
- 即方法中的对象没有发生逃逸
逃逸分析优化#
当一个对象没有逃逸时,可以得到以下几个虚拟机的优化。
锁消除
我们知道线程同步锁是非常牺牲性能的,当编译器确定当前对象只有当前线程使用,那么就会移除该对象的同步锁。注意,锁消除都要建立在逃逸分析的基础上。
例如,StringBuffer 和 Vector 都是用 synchronized 修饰线程安全的,但大部分情况下,它们都只是在当前线程中用到,这样编译器就会优化移除掉这些锁操作
标量替换、栈上分配
首先要明白标量和聚合量,基础类型和对象的引用可以理解为标量,它们不能被进一步分解。而能被进一步分解的量就是聚合量,比如:对象
对象是聚合量,它又可以被进一步分解成标量,将其成员变量分解为分散的变量,这就叫做标量替换。
当对象没有发生逃逸时,该对象就可以通过标量替换分解成成员标量分配在栈内存中,和方法的生命周期一致,随着栈帧出栈时销毁,减少了 GC 压力,提高了应用程序性能
标量替换要建立在逃逸分析的基础上。
方法内联
如果JVM监测到一些小方法被频繁的执行,它会把方法的调用替换成方法体本身,如:
private int add4(int x1, int x2, int x3, int x4) {
return add2(x1, x2) + add2(x3, x4);
}
private int add2(int x1, int x2) {
return x1 + x2;
}
方法调用被替换后
private int add4(int x1, int x2, int x3, int x4) {
return x1 + x2 + x3 + x4;
}




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 终于写完轮子一部分:tcp代理 了,记录一下
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理