内存结构与垃圾回收
😉 本文共6125字,阅读时间约12min
内存结构#
JVM、JRE、JDK关系#
- JVM:运行在操作系统上
- JRE:包含了JVM和基础类库
- JDK:包含JRE的基础上,多了一些编译工具
学习路线#

- Java Class 编译后的字节码文件
- 类加载器:加载字节码文件到JVM内存结构里
- 内存结构
- 堆、元空间、虚拟机栈、本地方法栈、程序计数器(后三个线程私有)
- 本地方法栈:JVM执行的native方法,这些方法由非java实现。比如与操作系统交互时用到
- 执行引擎:解释器逐行执行方法字节码,热点代码如频繁调用的方法,有JIT即时编译器直接编译成机器码。GC进行垃圾回收,回收堆中对象。
程序计数器#
- PC,程序计数器,记录下一条jvm的执行地址
- 线程私有,不会内存溢出
- 作用:
- 解释器会解释指令为机器码交给 cpu 执行,程序计数器会记录下一条指令的地址行号,这样下一次解释器会从程序计数器拿到指令然后进行解释执行。
- 多线程,上下文切换时,程序计数器会记录当前线程下一行指令的地址。
虚拟机栈#
- 每个线程都有自己的虚拟机栈,每个栈由多个栈帧组成,是调用方法时所占的内存
- 每个线程只能有一个活动栈帧,对应当前正在执行的方法
- 辨析:
- 垃圾回收不涉及栈内存,方法调用结束后会自动弹出栈帧
- 栈内存不是越大越好。栈内存越大,可以支持更多的递归调用,但是可执行的线程数就会越少。
- 方法内部局部变量是否线程安全?
- 如果方法内部的变量没有逃离方法的作用访问,它是线程安全的
- 如果是局部变量引用了对象,并逃离了方法的访问,那就要考虑线程安全问题。
StackOverflow#
栈内存溢出,由栈帧过大,过多引起。
线程运行诊断#
案例一:cpu 占用过多
解决方法:Linux 环境下运行某些程序的时候,可能导致 CPU 的占用过高,这时需要定位占用 CPU 过高的线程
- top 命令,查看是哪个进程占用 CPU 过高
- ps H -eo pid, tid(线程id), %cpu | grep 刚才通过 top 查到的进程号 通过 ps 命令进一步查看是哪个线程占用 CPU 过高
- jstack 进程 id 通过查看进程中的线程的 nid ,刚才通过 ps 命令看到的 tid 来对比定位,注意 jstack 查找出的线程 id 是 16 进制的,需要转换。
jstack命令#
stack是JVM自带的Java堆栈跟踪工具,用于生成虚拟机当前时刻的线程快照。
线程快照是每一条线程正在执行的方法堆栈的集合,生成线程快照的主要目的是定位线程出现长时间停顿的原因, 如线程间死锁、死循环、请求外部资源导致的长时间等待等问题。
查看各个线程的调用堆栈,就可以知道没有响应的线程到底在后台做什么,或者等待什么资源。
本地方法栈#
本地方法栈:服务JVM执行的native方法,这些方法由非java实现,C或C++实现的。比如与操作系统交互时用到。
堆#
- new出来的对象都在堆内存
- 特点
- 它是线程共享,堆内存中的对象都需要考虑线程安全问题
- 有GC机制
OOM#
java.lang.OutofMemoryError :java heap space. 堆内存溢出
可以使用 -Xmx8m 来指定堆内存大小。
OOM也可能是方法区空间溢出了
出现原因
- 申请内存速度超出GC释放速度,导致空间不够。
- 比如往内存加载超大对象
- 循环创建大量对象
- 内存泄漏
- 资源对象没关闭,比如File没关闭
- static修饰的大集合强引用没清理
堆内存诊断#
-
jps 工具
查看当前系统中有哪些 java 进程及其进程id -
jmap 工具
查看堆内存占用情况 jmap - heap 进程id
jmap(Java Memory Map)主要用于查看 jvm 内存,是 jvm 自带的一种内存映像工具。
- jconsole 工具
图形界面的,多功能的监测工具,可以连续监测

方法区#
运行时常量池#
运行时常量池,包括编译期就已经明确的数值字面量,也包括到运行期解析后才能够获得的方法或者字段引用。
当该类被加载以后,对应的字节码文件的常量池信息就会放入运行时常量池,并把里面的符号地址变为真实地址。
注意常量池是字节码class文件的一部分。
一个java源文件中的类、接口,编译后产生一个字节码文件。二进制字节码包含类的基本信息,常量池,类方法定义,包含了虚拟机的指令。
而Java中的字节码需要数据支持,通常这种数据会很大以至于不能直接存到字节码里,换另一种方式,可以存到常量池,这个字节码包含了指向常量池的引用。
常量池、可以看做是一张表,虚拟机指令根据这张常量表找到要执行的类名、方法名、参数类型、字面量等类型。
存放的内容有字面量,字符串值,类引用,字段引用,方法引用(这几个都是符号引用)。
方法区内容#
-
方法区内部包含:
- 运行时常量池。
- 类信息:类结构、字段和方法数据,以及方法和构造函数代码
- 类信息:类的全限定名(包名+类名)、父类名称、修饰符如public
- 字段、方法
-
线程共享,方法区是一个概念,1.8以前由永久代实现,1.8由元空间实现。
- 串池在1.8前在永久代的运行时常量池里,1.8后在堆里。
- 元空间不在虚拟机设置的内存中,而是使用本地内存
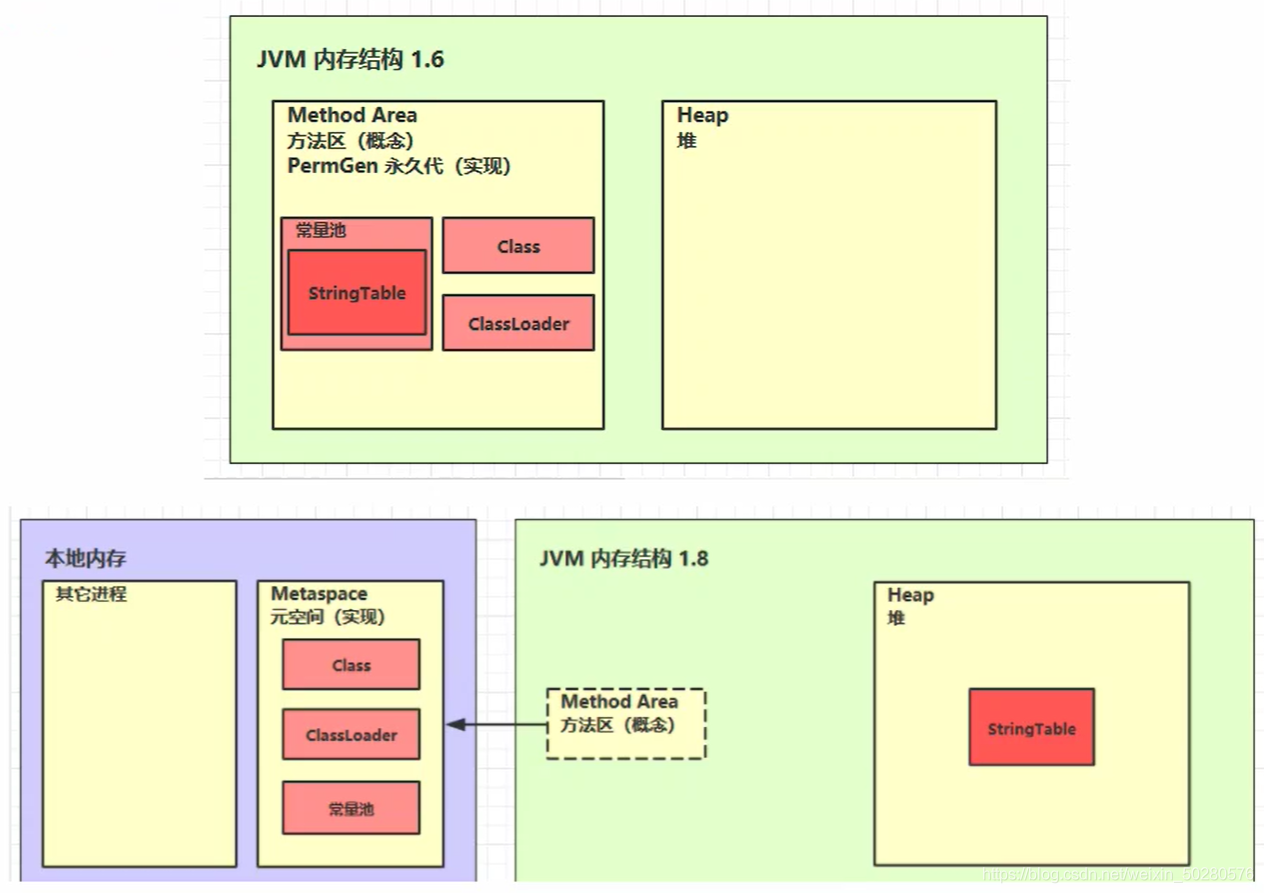
方法区OOM#
- 1.8 之前会导致永久代内存溢出
- 1.8 之后会导致元空间内存溢出
方法区垃圾回收#
一般来说这个区域的回收效果比较难令人满意,尤其是类型的卸载,条件相当苛刻。但是这部分区域的回收有时又确实是必要的。
方法区的垃圾收集主要回收两部分内容:常量池中废弃的常量和不再使用的类。HotSpot虚拟机对常量池的回收策略是很明确的,只要常量池中的常量没有被任何地方引用,就可以被回收。
为什么要将永久代 (PermGen) 替换为元空间 (MetaSpace)#
- 整个永久代有一个 JVM 本身设置的固定大小上限,无法进行调整,而元空间使用的是直接内存,受本机可用内存的限制,虽然元空间仍旧可能溢出,但是比原来出现的几率会更小。
- 元空间里面存放的是类的元数据,这样加载多少类的元数据就不由
MaxPermSize控制了, 而由系统的实际可用空间来控制,这样能加载的类就更多了。
串池#
串池,StringTable,字符串常量池。hashtable结构,不能扩容。
串池为什么要调整位置?#
jdk7中将StringTable放到了堆空间中。因为永久代的回收效率很低,在full gc的时候才会触发。而full gc是老年代的空间不足、永久代不足时才会触发。
这就导致StringTable回收效率不高。而我们开发中会有大量的字符串被创建,回收效率低,导致永久代内存不足。放到堆里,能及时回收内存。
串池作用#
- 运行时常量池中的字符串仅是符号,只有在被用到时才会转化为加载对象放入串池
- 这就是字符串延迟加载
- 利用串池的机制,来避免重复创建字符串对象
字符串拼接原理#
-
字符串常量拼接的原理是编译器优化
-
字符串变量拼接的原理是StringBuilder
String s1 = "a",s2 = "b";
String s3 = "a" + "b";
String s4 = s1 +s2; // s3 != s4
字符串延迟加载#
运行时常量池中的字符串仅是符号,只有在被用到时才会转化为加载对象放入串池
intern方法#
- 可以使用intern方法,主动将串池中还没有的字符串对象放入串池中。
- 如果串池中没有该字符串对象,则放入成功。
- 如果有该字符串对象,则放入失败。
- 无论放入是否成功,都会返回串池中的字符串对象
注意:此时如果调用 intern 方法成功,堆内存与串池中的字符串对象是同一个对象;如果失败,则不是同一个对象。
public class Main {
public static void main(String[] args) {
// 堆中创建新对象"a"、"b"、"ab",并返回引用
// "ab"不在串池,因为串池只存常量字符串, 现在是拼接后new出来的
String str = new String("a") + new String("b"); // ["a","b"]
// 将"ab"放入串池,无论成功失败都返回串池中的引用
String st2 = str.intern(); // ["a","b","ab"]
// 常量池中的信息,都会被加载到运行时常量池中。
// 此时运行时常量池中“ab”,此时还是符号,还没有变成Java中的对象
// 延迟加载:只有执行到引用“ab”的代码,才会创建对象,并尝试将其放到串池。
String str3 = "ab";
System.out.println(str == st2); // true
System.out.println(str == str3); // true
}
}
串池垃圾回收#
触发垃圾回收时,串池中没有被引用的字符串常量会被回收
StringTable 性能调优#
- 因为StringTable是由HashTable实现的,所以可以适当增加HashTable桶的个数,来减少哈希碰撞,降低链表长度。来减少字符串放入串池所需要的时间。
-XX:StringTableSize=桶个数(最少设置为 1009 以上)。 - 通过 intern 方法让字符串入池,减少堆内存的使用
直接内存#
Direct Memory
- 常见于 NIO 操作时,用于数据缓冲区
- 分配回收成本较高,但读写性能高
- 不受 JVM 内存回收管理
使用直接内存的好处#
文件读写流程:
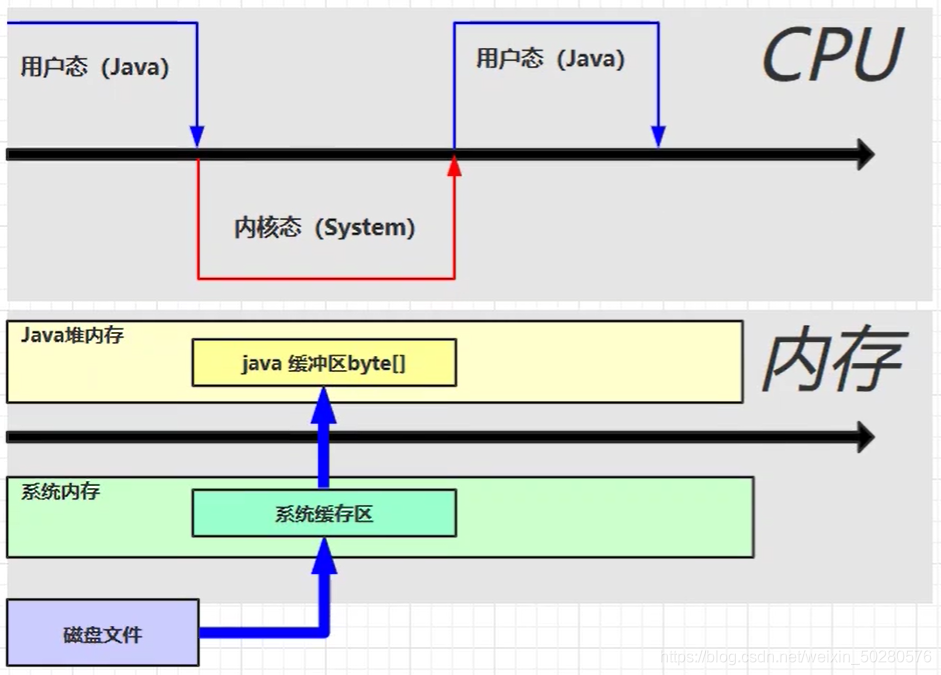
因为 java 不能直接操作文件管理,需要切换到内核态,使用本地方法进行操作,然后读取磁盘文件,会在系统内存中创建一个缓冲区,将数据读到系统缓冲区, 然后在将系统缓冲区数据,复制到 java 堆内存中。缺点是数据存储了两份,在系统内存中有一份,java 堆中有一份,造成了不必要的复制。
使用了 DirectBuffer 文件读取流程
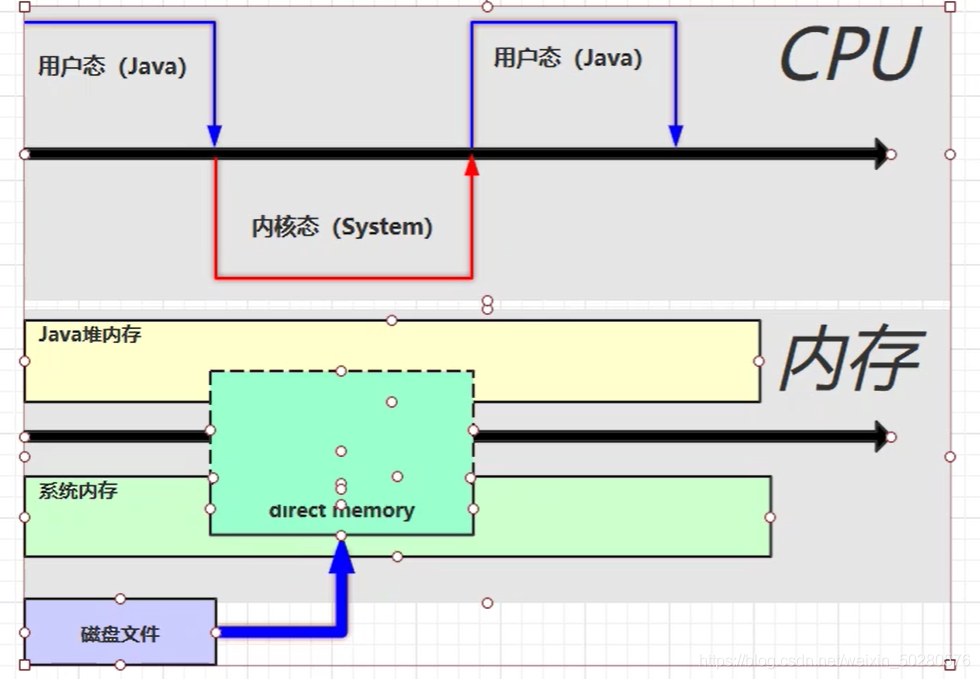
直接内存是操作系统和 Java 代码都可以访问的一块区域,无需将代码从系统内存复制到 Java 堆内存,从而提高了效率。
直接内存回收原理#
- 虚引用监测手动回收:直接内存的回收不是通过 JVM 的垃圾回收来释放的,而是通过unsafe.freeMemory 来手动释放。
- 使用了 Unsafe 类来完成直接内存的分配回收,回收需要主动调用freeMemory 方法
- ByteBuffer 实现内部使用了 Cleaner(继承了虚引用类型),由ReferenceHandler线程来监测 ByteBuffer对象 ,如果虚引用的实际对象(这里是 DirectByteBuffer )被回收以后,就会调用 Cleaner 的 clean 方法,来清除直接内存中占用的内存。
垃圾回收#
如何判断对象可回收?#
引用计数法#
当一个对象被引用时,就当引用对象的值加一,当值为 0 时,就表示该对象不被引用,可以被垃圾收集器回收。
这个引用计数法听起来不错,但是有一个弊端,如下图所示,循环引用时,两个对象的计数都为1,导致两个对象都无法被释放。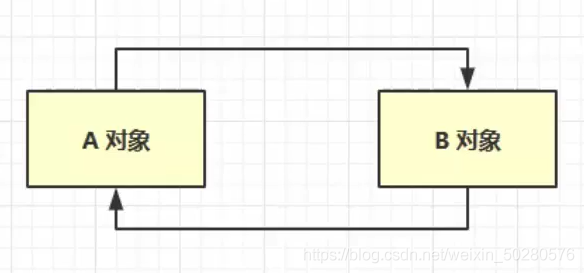
可达性分析#
- JVM 中的垃圾回收器通过可达性分析来探索所有存活的对象
- 扫描堆中的对象,看能否沿着 GC Root 对象为起点的引用链找到该对象,如果找不到,则表示可以回收
- 所谓GCRoots就是一组必须活跃的引用,可以作为 GC Root 的对象
- 虚拟机栈(栈帧中的本地变量表)中引用的对象。
- 方法区中类静态属性引用的对象
- 方法区中常量引用的对象
- 本地方法栈中 JNI(即一般说的Native方法)引用的对象
- 对象被gc掉同时需要满足两个条件,一个是gc roots不可达,另一个是没必要执行finalize方法。
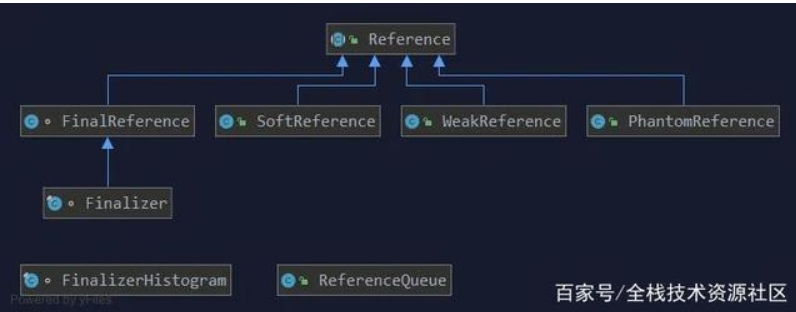
四种引用#
强引用、软引用、弱引用、虚引用、终结器引用
引用继承关系图#
强引用是Java的默认实现,它会尽可能长时间的存活于JVM内,当没有GC Root引用时,强引用变量引用的对象将被回收。
其他引用需要使用Reference的子类进行声明,一般的应用程序不会涉及到 Reference 编程, 但是了解这些知识会对理解 GC 的工作原理以及性能调优有一定帮助, 在实现一些基础性设施比如缓存时也可能会用到。
WeakReference<Object> weakReference = new WeakReference<Object>(referent, referenceQueue);
四种引用特点#
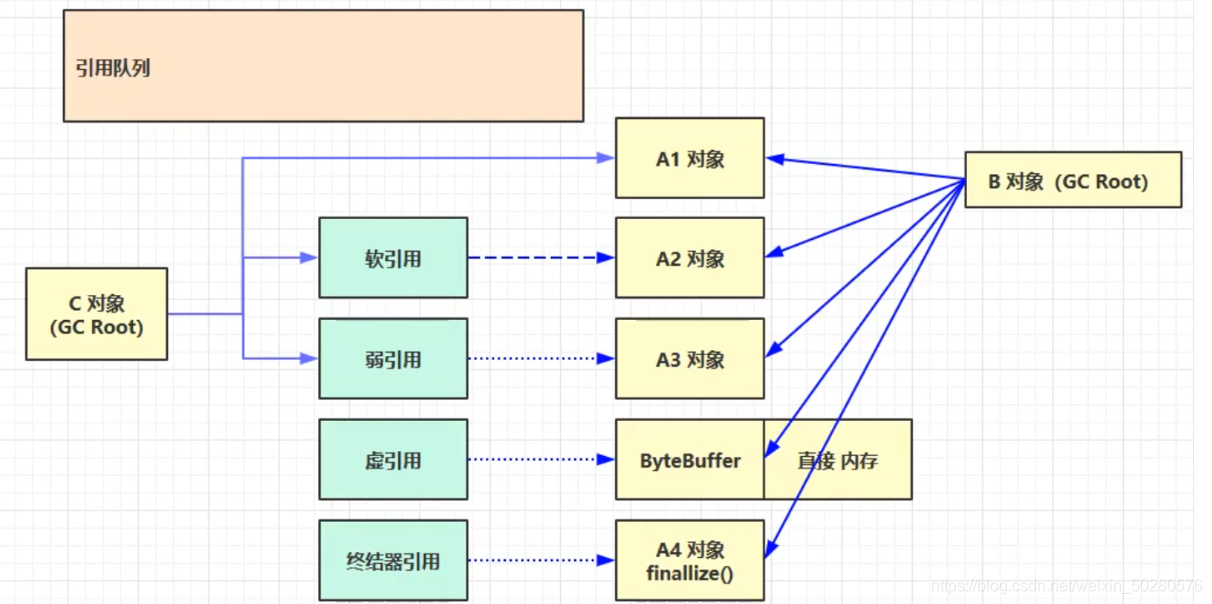
强引用
强引用指的是代码中普遍存在的Object obj=new Object()这类的引用。
只有所有 GC Roots 对象都不通过【强引用】引用该对象,该对象才能被垃圾回收。
软引用
仅有软引用引用该对象时,在垃圾回收后,内存仍不足时会再次触发垃圾回收。
可以配合引用队列来释放软引用自身
弱引用
仅有弱引用引用该对象时,在垃圾回收时,无论内存是否充足都会回收弱引用对象。
可以配合引用队列来释放弱引用自身。
虚引用
主要配合 ByteBuffer 使用,唯一作用是被引用对象回收时,会将虚引用入队。由 Reference Handler 线程调用虚引用相关方法释放直接内存。
必须配合引用队列使用
终结器引用(FinalReference)
为什么需要FinalReference?
因为jvm只能管理jvm内存空间,但是对于应用运行时需要的其它native资源(jvm通过jni暴漏出来的功能):例如直接内存DirectByteBuffer,网络连接SocksSocketImpl,文件流FileInputStream等与操作系统有交互的资源,jvm就无能为力了,需要我们自己来调用释放这些资源方法来释放。
为了避免对象死了之后,程序员忘记手动释放这些资源,导致这些对象有的外部资源泄露,java提供了finalizer机制通过重写对象的finalizer方法,比如关闭socket连接,在这个方法里面执行释放对象占用的外部资源的操作。
帮助我们调用这个方法回收资源的线程就是我们在导出jvm线程栈时看到的名为Finalizer的守护线程。Finalizer其实是实现了析构函数的概念,我们在对象被回收前可以执行一些『收拾性』的逻辑,应该说是一个特殊场景的补充。
其内部配合引用队列使用,在垃圾回收时,终结器引用入队(被引用对象暂时没有被回收),再由 Finalizer 线程通过终结器引用找到被引用对象并调用它的 finalize 方法,第二次 GC 时才能回收被引用对象。
但是如果真的是用户忘记关闭了,那这些socket对象可能因为FinalizeThread迟迟没有执行到这些socket对象的finalize方法,对象占用的内存也迟迟得不到释放,而导致内存泄露。(所以不建议重写finalize()方法)
引用队列#
如果WeakReference的get方法返回null了,那么这个WeakReference所关联的对象已经被释放了,但是这个WeakReference对象本身还是存在的,它会占用空间,为了避免内存泄漏。我们需要一个机制来确保WeakReference也能被释放。
如果在创建WeakReference的时候,在构造函数里传入一个ReferenceQueue,那么在这个WeakReference所引用的对象被回收之后,这个WeakReference会被自动插入到ReferenceQueue里来。于是我们可以在适当的时候(比方说后台开一个定时线程)去扫描这个ReferenceQueue,然后把队列里的无用的WeakReference全部清除掉。
适用场景#
- 软引用:比如图片缓存
- 虚引用:比如那些需要手动释放
finalize()方法#
finalize()是Object中的方法,当垃圾回收器将要回收对象所占内存时,该方法被调用,即当一个对象被虚拟机宣告死亡时会先调用它的finalize()方法,让此对象临终前交代点遗言,当然对象也可以趁机复活。
可达性分析算法中,要宣告一个对象真正的死亡,要经历两次标记的过程:
如果对象在经历可达性分析之后,发现没有与GC root相连的引用链,将会被第一次标记并且进行第一次筛选,筛选的条件是是否有必要执行finalize()方法,当对象没有finalize()方法或者虚拟机已经调用过finalize()方法,视为没有必要执行。
如果这个对象被判定为有必要执行finalize()方法,那么对象将会放置在一个F-Queue队列中,稍后由一个虚拟机自动建立的、低优先级的Finalizer线程去执行它。finalize()方法是对象逃离死亡的最后一次机会,稍后GC将会对队列进行第二次小规标记,如果对象要finalize()拯救它,只需要与引用链上的任意一个对象建立关联即可,那么第二次标记的时候它将会被移出即将回收的集合,如果没逃脱,就会真正被回收。
书中记载,“它不是C/C++中的析构函数,而是Java刚诞生时为了使C/C++程序员更容易接受它所做出的一个妥协”。
垃圾回收算法#
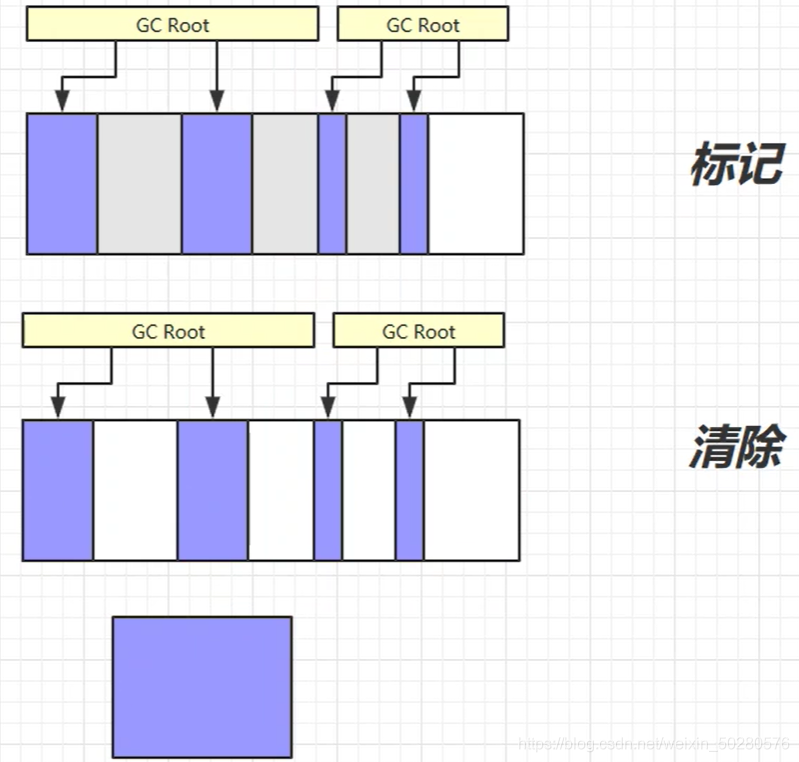
标记清除#
Mark Sweep
- 速度较快
- 会产生内存碎片
标记整理#
Mark Compact
- 速度慢
- 没有内存碎片

复制#
Copy
- 不会有内存碎片
- 需要占用两倍内存空间

分代垃圾回收#
什么是分代垃圾回收#
Minor GC:当年轻代Eden区域满的时候会触发一次Minor GC,新生代的 GC。
Major GC:老年代的 GC。目前,只有 CMS GC 会有单独收集老年代的行为。
Full GC:整堆收集,收集整个 Java 堆和方法区的垃圾收集。
JVM 的调优的一个环节,就是垃圾收集,我们需要尽量的避免垃圾回收,因为在垃圾回收的过程中,容易出现 STW 的问题。
Major GC 和 Full GC 出现 STW 的时间是 Minor GC 的10倍以上。
为什么要进行分代垃圾回收#
多轮回收后仍存活的对象在这一轮大概率也不会被回收,回收它们浪费性能。
新生代朝生夕死,回收效率高。
老年代存放生命周期比较长的对象,在新生代中经历了n次垃圾回收后仍然存活的对象就会被放到老年代中。此外,老年代的内存也比新生代大很多(比例大概是1:2)。full gc概率也低。
如何进行分代垃圾回收#
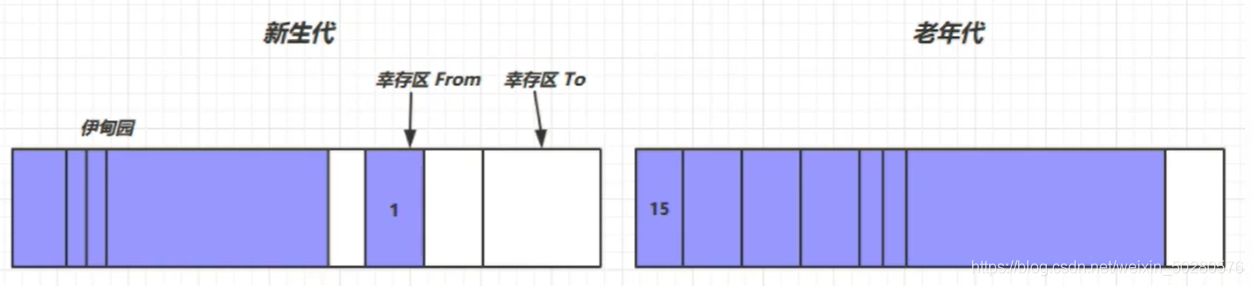
- 新创建的对象首先分配在 eden 区
- 新生代空间不足时,触发 minor gc ,eden 区 和 from 区存活的对象使用 - copy 复制到 to 中,存活的对象年龄加一,然后交换 from to
- minor gc 会引发 stop the world,暂停其他线程,等垃圾回收结束后,恢复用户线程运行
- 当幸存区对象的寿命超过阈值时,会晋升到老年代,最大的寿命是 15(4bit)
- 当老年代空间不足时,会先触发 minor gc,如果空间仍然不足,那么就触发 full fc ,停止的时间更长!(比如当新生代放不下新对象时,对象会直接放到老年代,这种情况下如果老年代也放不下,先触发minor gc,最好能让新对象待在新生代)。
空间分配担保策略#
在发生Minor GC之前,检查老年代最大可用的连续空间是否大于新生代所有对象的总空间。
- 如果大于,则此次Minor GC是安全的
- 如果小于,则虚拟机会查看-X:HandlePromotionFailure设置值是否允许担保失败。
- 不允许,直接Full GC
- 允许,检查最大可用连续空间是否大于历代晋升的对象平均大小
- 大于,进行一次有风险的Minor GC
- 小于,直接Full GC
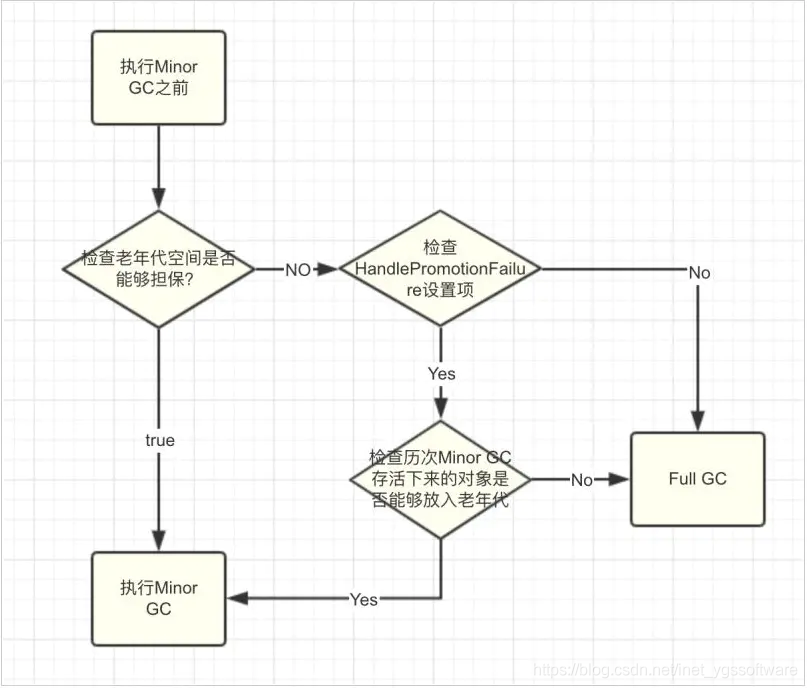
Full GC触发条件#
- 老年代空间不足,引起Full GC
- 大对象直接进入老年代
- 经历过多次Minor GC仍存在的对象进入老年代
- Minor GC时,动态对象年龄判定机制会将对象提前转移老年代。
- Minor GC时,Eden和From Space区向To Space区复制时,大于To Space区可用内存,会直接把对象转移到老年代
- 空间分配担保机制可能会触发Full GC,如上图
- 调用System.gc()方法
频繁Full GC可能的原因#
- 堆内存分配过低
- 集合类频繁加入大对象,比如图片等等
相关 JVM 参数#
堆初始大小-Xms
堆最大大小-Xmx
新生代大小-Xmn
GC详情-XX:+PrintGCDetails -verbose:gc
FullGC 前 MinorGC-XX:+ScavengeBeforeFullGC
垃圾回收器#
相关概念:
- 并行收集:指多条垃圾收集线程并行工作,但此时用户线程仍处于等待状态。
- 并发收集:指用户线程与垃圾收集线程同时工作(不一定是并行的可能会交替执行)。用户程序在继续运行,而垃圾收集程序运行在另一个 CPU 上
- 吞吐量:即 CPU 用于运行用户代码的时间与 CPU 总消耗时间的比值(吞吐量 = 运行用户代码时间 / ( 运行用户代码时间 + 垃圾收集时间 )),也就是。例如:虚拟机共运行 100 分钟,垃圾收集器花掉 1 分钟,那么吞吐量就是 99% 。
几种常见的垃圾回收器#
-
串行:
- 单线程
- 堆内存较小,适合个人电脑
- Serial + SerialOld
-
吞吐量优先:
- 多线程
- 堆内存较大,多核CPU
- 单位时间内,STW 的时间最短 0.2 0.2 = 0.4,垃圾回收时间占比最低,这样就称吞吐量高
- Parallel Scavenge 收集器 + Parallel Old 收集器
-
响应时间优先:
- 多线程
- 堆内存较大,多核CPU
- 尽可能让单次 STW 的时间最短 0.1 0.1 0.1 0.1 0.1 = 0.5
- 新生代可搭配ParNew收集器 + 老年代用CMS收集器
-
同时注重吞吐量和低延迟(响应时间):
- G1收集器
- 超大堆内存(内存大的),会将堆内存划分为多个大小相等的区域
- 整体上是标记-整理算法,两个区域之间是复制算法
什么是STW#
Java中Stop-The-World机制简称STW,是在执行垃圾收集算法时,Java应用程序的其他所有线程都被挂起。Java中一种全局暂停现象,全局停顿,所有Java代码停止,native代码可以执行,但不能与JVM交互;这些现象多半是由于gc引起。
GC时的Stop the World(STW)是大家最大的敌人。
串行#

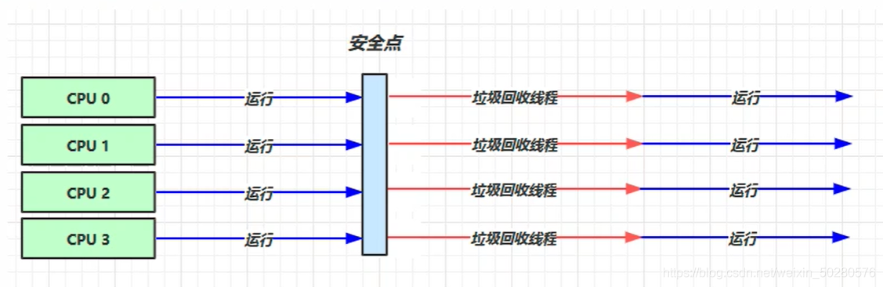
安全点#
让其他线程都在这个点停下来,以免垃圾回收时移动对象地址,使得其他线程找不到被移动的对象。因为是串行的,所以只有一个垃圾回收线程。且在该线程执行回收工作时,其他线程进入阻塞状态。需要STW(Stop The World)。
几种收集器#
| Serial收集器 | ParNew 收集器(非串行) | Serial Old 收集器 |
|---|---|---|
| Serial 收集器的多线程版本 | Serial 收集器的老年代版本 | |
| 单线程 | 多线程 | 单线程 |
| 复制算法 | 复制算法 | 标记整理 |
| STW | STW | STW |
吞吐量优先#
-XX:+UseParallelGC ~ -XX:+UsePrallerOldGC
* XX:MaxGCPauseMillis=ms 控制最大的垃圾收集停顿时间(默认200ms)
* XX:GCTimeRatio=rario 直接设置吞吐量的大小
Parallel Scavenge 收集器#
吞吐量优先收集器,该收集器的目标是达到一个可控制的吞吐量。
新生代收集器、多线程并行、复制算法,很像ParNew,区别在于有GC自适应调节策略。
GC自适应调节策略:不需要手动指定新生代的大小、Eden 与 Survivor 区的比例、晋升老年代的对象年龄,虚拟机会根据系统的运行状况收集性能监控信息,动态设置这些参数以提供最优的停顿时间和最高的吞吐量,这种调节方式称为 GC 的自适应调节策略。
Parallel Old 收集器#
是 Parallel Scavenge 收集器的老年代版本,多线程,采用标记-整理算法。
响应时间优先#
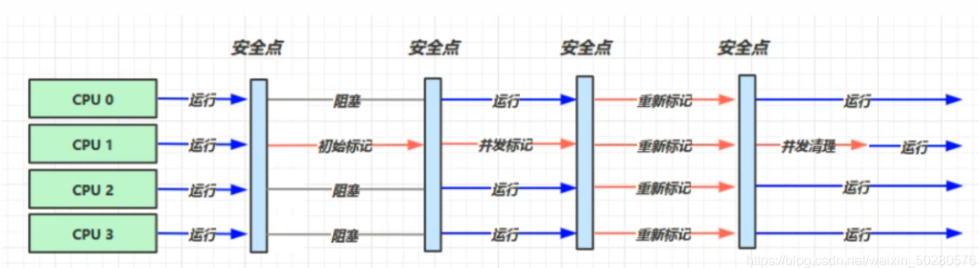
-XX:+UseConcMarkSweepGC ~ -XX:+UseParNewGC
-XX:+CMSScavengeBeforeRemark
CMS收集器#
使用CMS 收集器。一种以获取最短回收停顿时间为目标的老年代收集器。
应用场景:适用于注重服务的响应速度,希望系统停顿时间最短,给用户带来更好的体验等场景下。如 web 程序、b/s 服务。




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构