Redis 高级篇 Part 3
😉 本文共4776字,阅读时间约8min
Redis持久化#
Redis有两种持久化方案:
- RDB持久化
- AOF持久化
RDB持久化#
RDB全称Redis Database Backup file(Redis数据备份文件),也被叫做Redis数据快照。
简单来说就是把内存中的所有数据都记录到磁盘中。当Redis实例故障重启后,从磁盘读取快照文件,恢复数据。快照文件称为RDB文件,默认是保存在当前运行目录。
执行时机#
RDB持久化在四种情况下会执行:
- 执行save命令
- 导致主进程执行RDB,这个过程中其它所有命令都会被阻塞。只有在数据迁移时可能用到。
- 执行bgsave命令
- fork子进程完成RDB,主进程可以持续处理用户请求
- Redis停机时
- 触发RDB条件时
- 可配置,m秒至少有n个key被修改
RDB原理#
bgsave开始时会fork主进程得到子进程,子进程共享主进程的内存数据。完成fork后读取内存数据并写入 RDB 文件。
fork采用的是copy-on-write技术:
- 当主进程执行读操作时,访问共享内存;(读时共享)
- 当主进程执行写操作时,则会拷贝一份数据,执行写操作。(写时复制)
bgsave基本流程#
-
fork主进程得到一个子进程,共享内存空间
-
子进程读取内存数据并写入新的RDB文件
-
用新RDB文件替换旧的RDB文件
缺点#
- RDB执行间隔时间长,两次RDB之间写入数据有丢失的风险
- fork子进程、写出RDB文件都比较耗时
AOF持久化#
三种策略#

AOF文件重写#
因为是记录命令,AOF文件会比RDB文件大的多。而且AOF会记录对同一个key的多次写操作,但只有最后一次写操作才有意义。通过执行bgrewriteaof命令/配置自动重写,可以让AOF文件执行重写功能,用最少的命令达到相同效果。

如图,AOF原本有三个命令,但是set num 123 和 set num 666都是对num的操作,第二次会覆盖第一次的值,因此第一个命令记录下来没有意义。
所以重写命令后,AOF文件内容就是:mset name jack num 666
RDB和AOF对比#
RDB和AOF各有自己的优缺点,如果对数据安全性要求较高,在实际开发中往往会结合两者来使用。
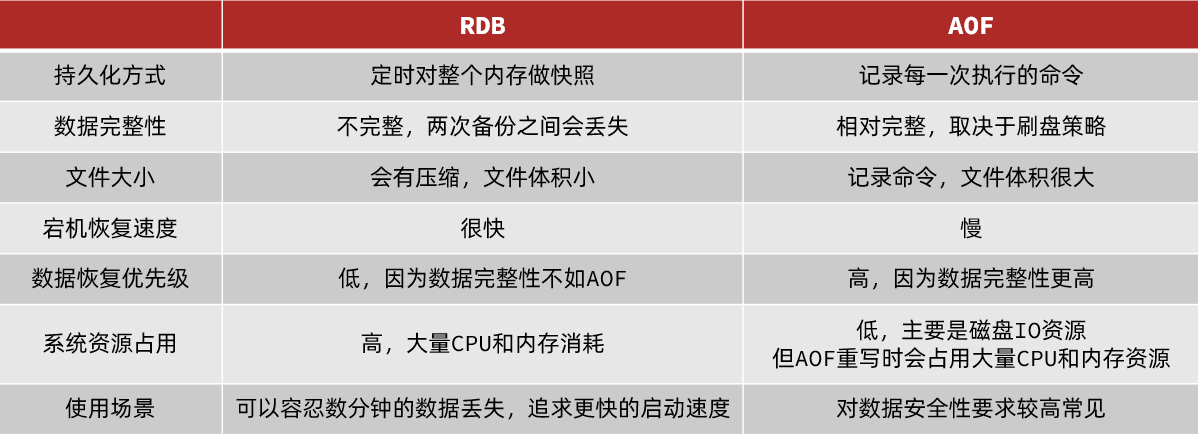
Redis主从同步原理#
单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,就需要搭建主从集群,实现读写分离。
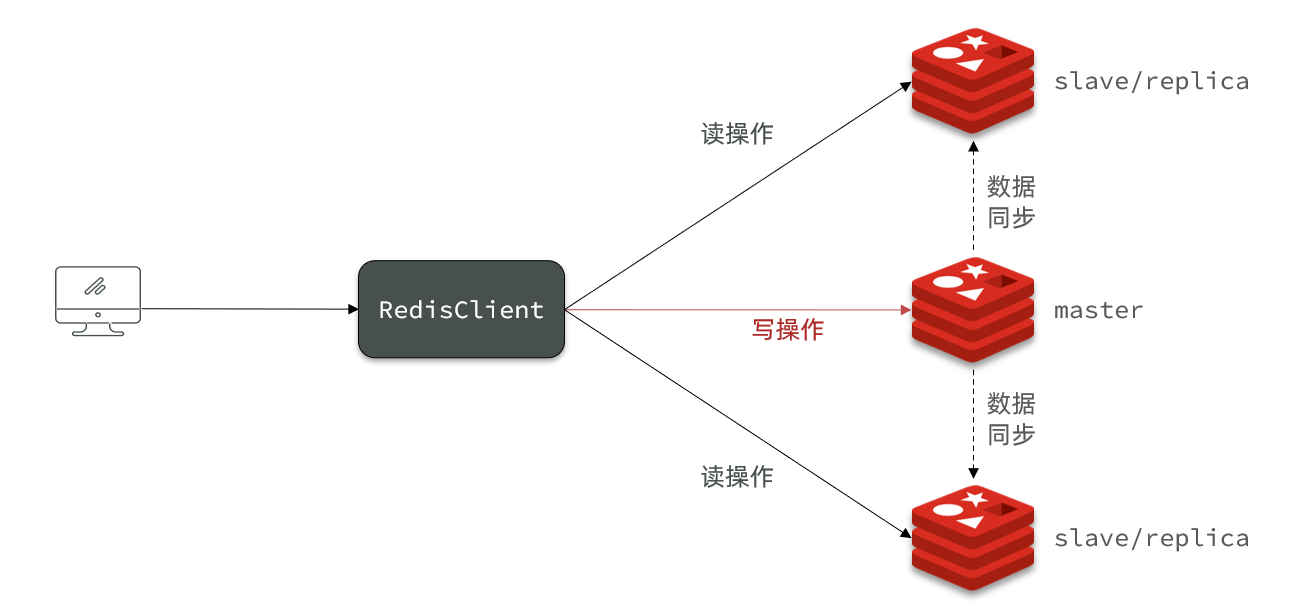
第一次连接全量同步#
主从第一次建立连接时,会执行全量同步,将master节点的所有数据都拷贝给slave节点
三个阶段#
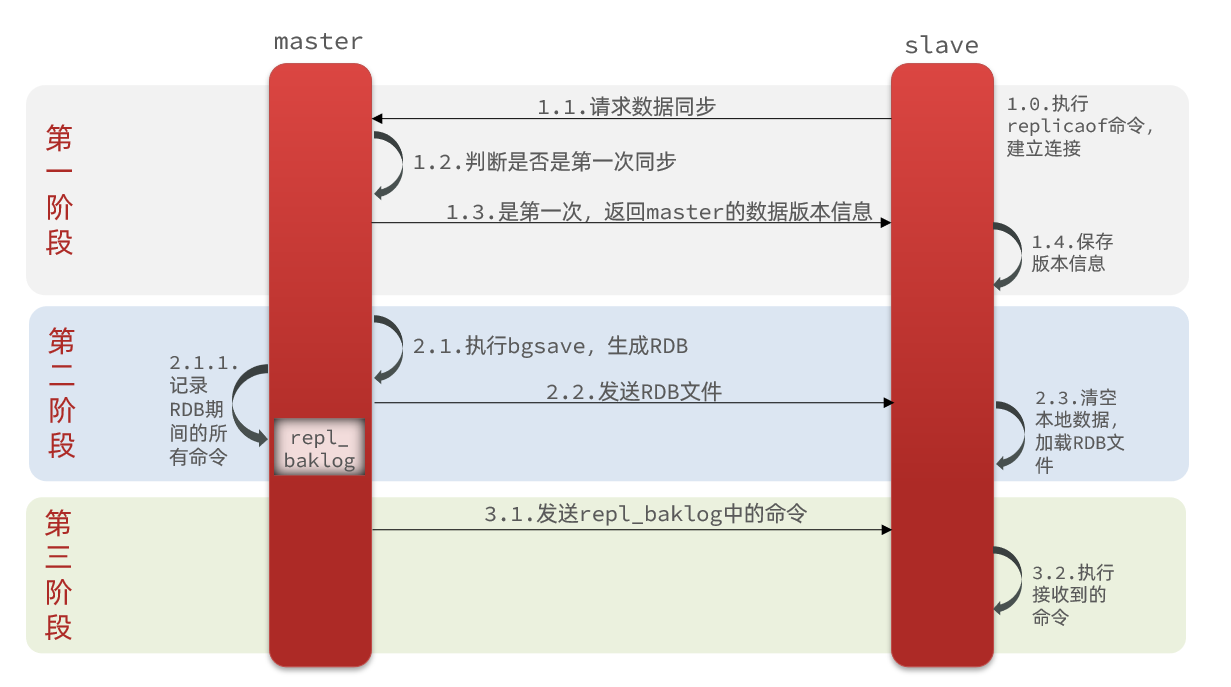
- 主节点判断是否第一次同步 + 返回主节点的版本信息给子节点
- 主节点fork子进程生成RDB,子节点加载RDB文件。
- 另外记录一份RDB期间的命令日志repl_baklog。
- 主节点发送命令日志,子节点replay该日志的命令
怎么判断要做第一次同步?#
里有一个问题,master如何得知salve是第一次来连接呢??
有几个概念,可以作为判断依据:
- Replication Id:简称replid,是数据集的标记,id一致则说明是同一数据集。每一个master都有唯一的replid,slave则会继承master节点的replid
- offset:偏移量,随着记录在repl_baklog中的数据增多而逐渐增大。slave完成同步时也会记录当前同步的offset。如果slave的offset小于master的offset,说明slave数据落后于master,需要更新。
因为slave原本也是一个master,有自己的replid和offset,当第一次变成slave,与master建立连接时,发送的replid和offset是自己的replid和offset。
master判断发现slave发送来的replid与自己的不一致,说明这是一个全新的slave,就知道要做全量同步了。
master会将自己的replid和offset都发送给这个slave,slave保存这些信息。以后slave的replid就与master一致了。
因此,master判断一个节点是否是第一次同步的依据,就是看replid是否一致。
之后增量同步#
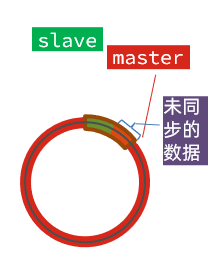
全量同步需要先做RDB,然后将RDB文件通过网络传输个slave,成本太高了。因此除了第一次做全量同步,其它大多数时候slave与master都是做增量同步。
什么是增量同步?就是只更新slave与master存在差异的部分数据。如图:
两个阶段#
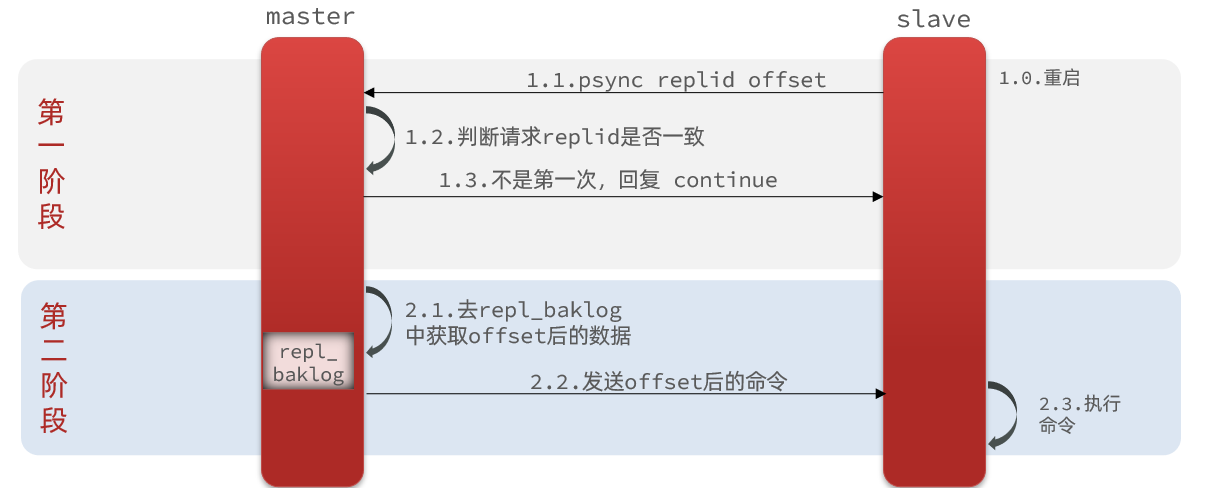
- 子节点发送repid和offset + 主节点判断不是第一次连接
- 主节点去repl_baklog获取offset后的命令,发送这些命令 + 子节点replay
repl_baklog原理#
master怎么知道slave与自己的数据差异在哪里呢?
这就要说到全量同步时的repl_baklog文件了。
这个文件是一个固定大小的数组,只不过数组是环形,也就是说角标到达数组末尾后,会再次从0开始读写,这样数组头部的数据就会被覆盖。
repl_baklog中会记录Redis处理过的命令日志及offset,包括master当前的offset,和slave已经拷贝到的offset:
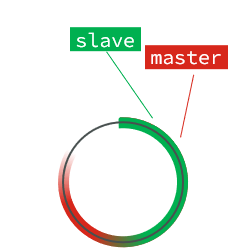
此时,如果有新的数据写入,就会覆盖数组中的旧数据。不过,旧的数据只要是绿色的,说明是已经被同步到slave的数据,即便被覆盖了也没什么影响。因为未同步的仅仅是红色部分。
但是,如果slave出现网络阻塞,导致master的offset远远超过了slave的offset,如果master继续写入新数据,其offset就会覆盖旧的数据,直到将slave现在的offset也覆盖。

主从同步优化#
主从同步可以保证主从数据的一致性,非常重要。
可以从以下几个方面来优化Redis主从就集群:
- Redis单节点上的内存占用不要太大,减少RDB导致的过多磁盘IO
- 适当提高repl_baklog的大小,发现slave宕机时尽快实现故障恢复,尽可能避免全量同步
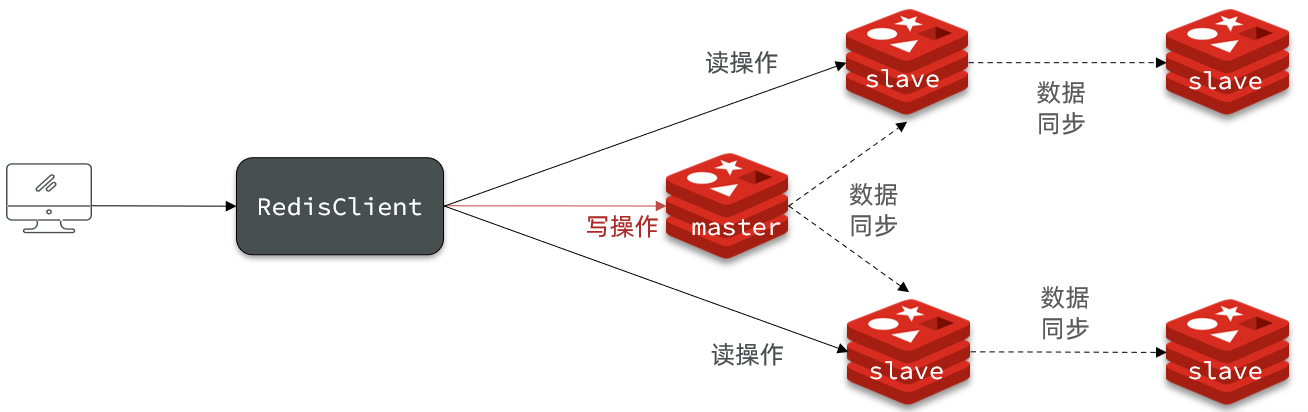
- 限制一个master上的slave节点数量,如果实在是太多slave,则可以采用主-从-从链式结构,减少master压力
主从从架构图:
小结#
什么时候执行全量同步?
- slave节点第一次连接master节点时
- slave节点断开时间太久,repl_baklog中的offset已经被覆盖时
什么时候执行增量同步?
- slave节点断开又恢复,并且在repl_baklog中能找到offset时
分布式缓存 - Redis集群#
单机的Redis存在四大问题:
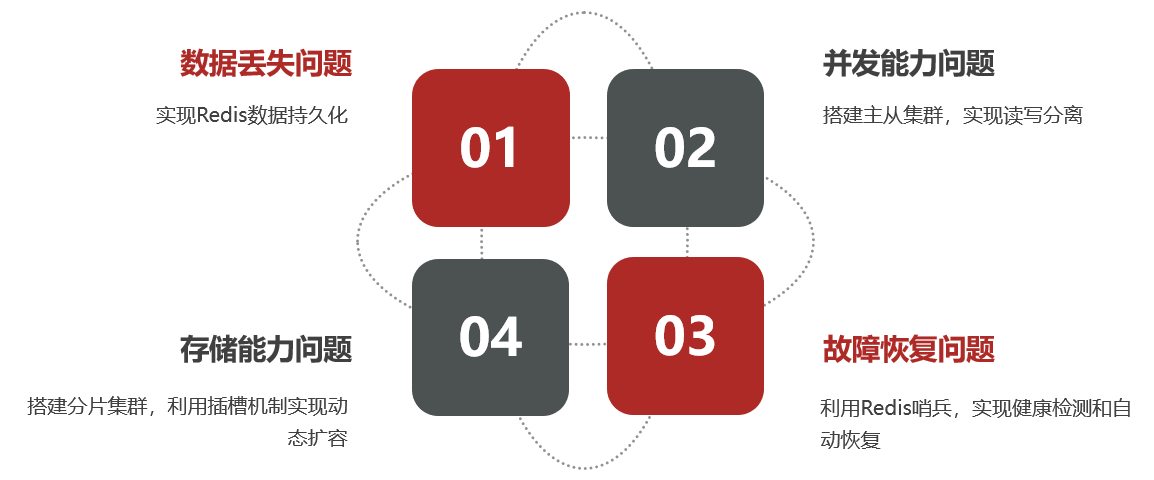
并发能力、存储能力、故障恢复
主从集群#
读写分离,解决了并发性的问题
如之前介绍
哨兵集群#
Redis提供了哨兵(Sentinel)机制来实现主从集群的自动故障恢复。
哨兵作用#
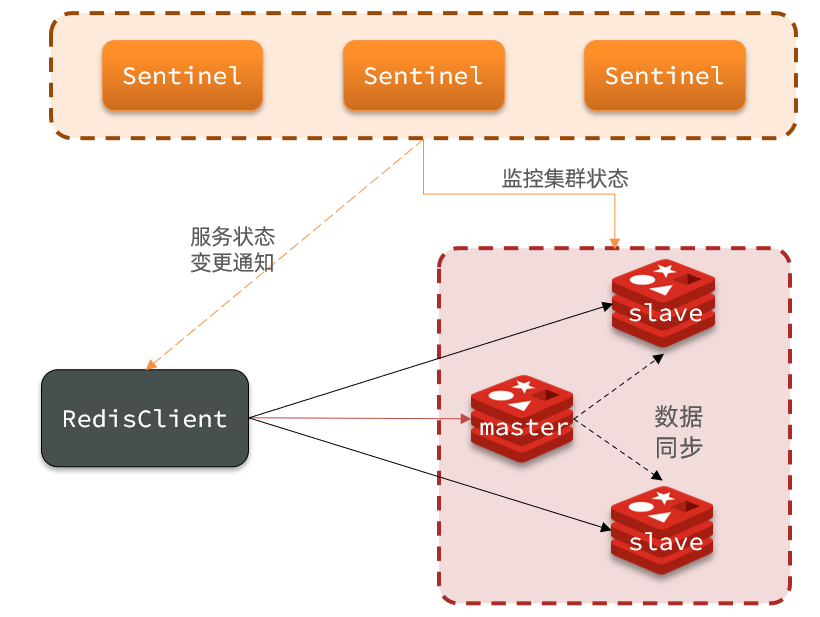
- 监控:Sentinel 会不断检查您的master和slave是否按预期工作
- 自动故障恢复:如果master故障,Sentinel会将一个slave提升为master。当故障实例恢复后也以新的master为主
- 通知:Sentinel充当Redis客户端的服务发现来源,当集群发生故障转移时,会将最新信息推送给Redis的客户端
集群监控原理#
- Sentinel基于心跳机制监测服务状态,每隔1秒向集群的每个实例发送ping命令:
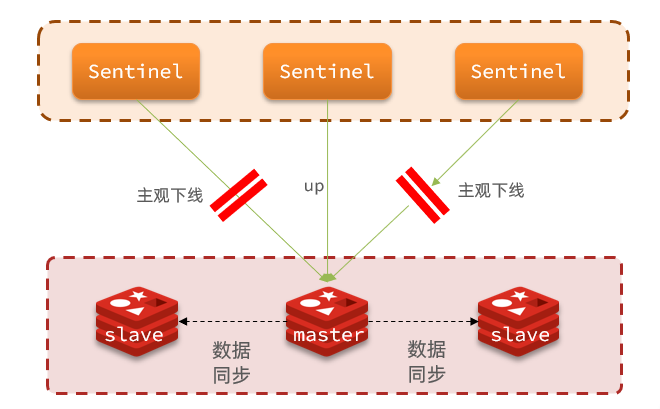
- 主观下线:如果某sentinel节点发现某实例未在规定时间响应,则认为实例主观下线。
- 客观下线:若超过指定数量(quorum)的sentinel都认为该实例主观下线,则该实例客观下线。quorum值最好超过Sentinel实例数量的一半。
集群故障恢复原理#
1. 选主
- 发现master,哨兵需要在slave中选一个master
- 首先排除与原master节点断开时间过长的(可配置阈值)
- 然后判断slave节点的优先级(可配置)
- 如果优先级一样,判断offset值,越大说明数据越新,优先级越高
- 如果offset一样,判断运行id大小,选小的
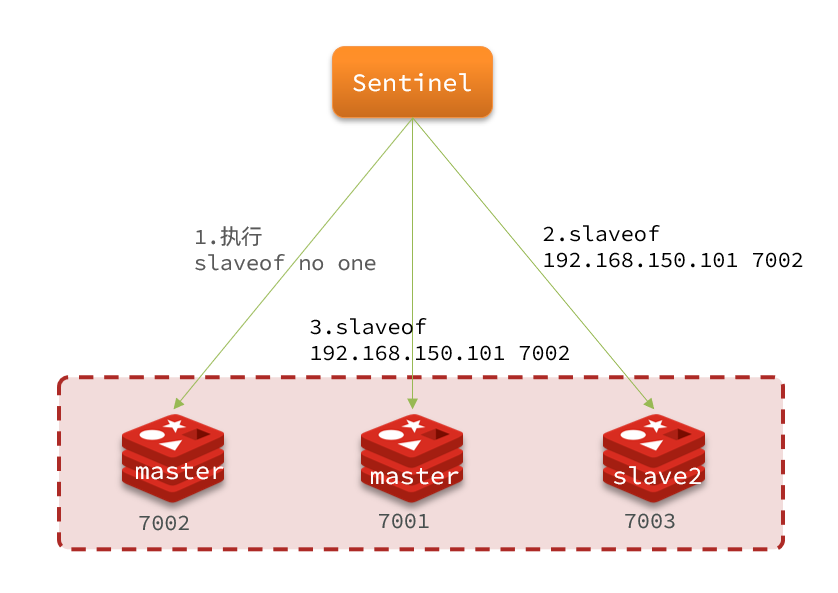
2. 切换
- 新master执行slave of no one
- 给所有其它slave发送slaveof 192.168.150.101 7002 命令,让这些slave成为新master的从节点,开始从新的master上同步数据。
- 将故障节点标记为slave,恢复后还是slave
个人觉得:哨兵 + 主从从架构 足以面对大部分场景
分片集群#
海量数据存储 + 高并发写?#
主从和哨兵可以解决高可用、高并发读的问题。但是依然有两个问题没有解决:
-
海量数据存储问题
-
高并发写的问题
使用分片集群可以解决上述问题,如图:
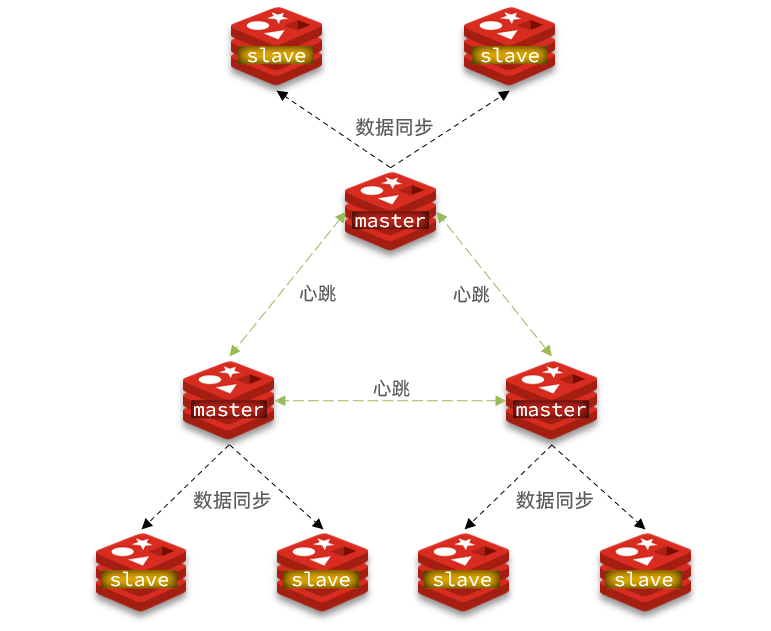
分片集群特征:
-
集群中有多个master,每个master保存不同数据
-
每个master都可以有多个slave节点
-
master之间通过ping监测彼此健康状态
-
客户端请求可以访问集群任意节点,最终都会被转发到正确节点
分片原理 - 散列插槽#
Redis会把每一个master节点映射到0~16383共16384个插槽(hash slot)上,查看集群信息时就能看到:
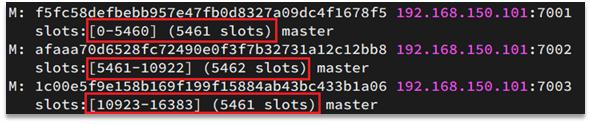
数据key不是与节点绑定,而是与插槽绑定。
redis会根据key的有效部分计算插槽值,分两种情况:
- key中包含"{}",且“{}”中至少包含1个字符,“{}”中的部分是有效部分
- key中不包含“{}”,整个key都是有效部分
例如:key是num,那么就根据num计算,如果是{itcast}num,则根据itcast计算。计算方式是利用CRC16算法得到一个hash值,然后对16384取余,得到的结果就是slot值。
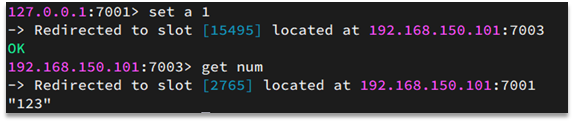
如图,在7001这个节点执行set a 1时,对a做hash运算,对16384取余,得到的结果是15495,因此要存储到103节点。
到了7003后,执行get num时,对num做hash运算,对16384取余,得到的结果是2765,因此需要切换到7001节点
小结#
Redis如何判断某个key应该在哪个实例?
- 将16384个插槽分配到不同的实例
- 根据key的有效部分计算哈希值,对16384取余
- 余数作为插槽,寻找插槽所在实例即可
如何将同一类数据固定的保存在同一个Redis实例?
- 这一类数据使用相同的有效部分,例如key都以{typeId}为前缀
分片集群伸缩#
需求:
- 添加一个节点到集群中
- 将部分插槽分配到新插槽
add node命令把新节点加入集群,默认是一个master节点,查看集群状态,这个节点没有插槽- 转移插槽,
使用reshard命令把插槽转移到新节点
自动故障转移#
master失去连接后,slave自动被提升为master。
master恢复后,变成slave
最佳实践#
批处理优化#
为啥要批处理#
- 单个命令一条条发
- N次命令的响应时间 = N次往返的网络传输耗时 + N次Redis执行命令耗时
- Redis执行速度很快,主要时间在网络延时
mset、hmset优化#
实现批量插入数据
比如10w数据,每1000个mset一下,就很省网络延时
pipeline优化#
MSET虽然可以批处理,但是却只能操作部分数据类型,因此如果有对复杂数据类型的批处理需要,建议使用Pipeline
@Test
void testPipeline() {
// 创建管道
Pipeline pipeline = jedis.pipelined();
long b = System.currentTimeMillis();
for (int i = 1; i <= 100000; i++) {
// 放入命令到管道
pipeline.set("test:key_" + i, "value_" + i);
if (i % 1000 == 0) {
// 每放入1000条命令,批量执行
pipeline.sync();
}
}
long e = System.currentTimeMillis();
System.out.println("time: " + (e - b));
}
注意:原生批命令是原子性,pipeline是非原子性
集群下的批处理#
因为key在cluster分布在不同的slot,可能在不同的机器,部分redis的客户端(比如jedis)是不支持pipeline的。
这个时候,我们可以找到4种解决方案:
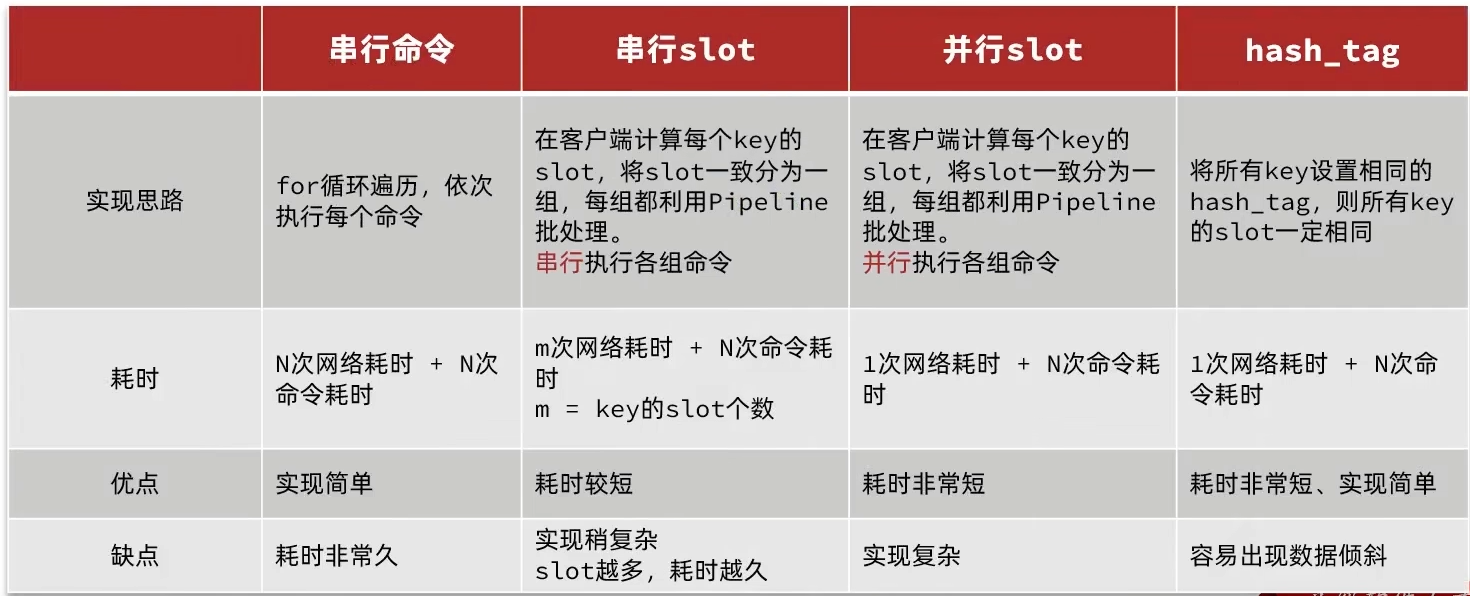
注意,第四种会产生数据倾斜的问题,建议并行slot
持久化优化#
- 定期在slave节点做RDB,实现数据备份
- 单个Redis实例内存上限不要太大,例如4G或8G。可以加快fork的速度、减少主从同步、数据迁移压力
慢查询优化#
redis单线程,有慢查询,会导致其他请求阻塞
SLOWLOG命令查看慢查询列表
集群还是主从#
分片集群问题#
- 可用性:在Redis的默认配置中,如果发现任意一个插槽不可用,则整个集群都会停止对外服务
- 集群带宽问题,集群节点之间会不断的互相Ping来确定集群中其它节点的状态。Ping携带的信息至少包括:插槽信息、集群状态信息(与集群节点数正相关,10个节点就达到1kb)
- 避免大集群,集群节点数不要太多,最好少于1000,如果业务庞大,则建立多个集群
结论#
单体Redis(主从Redis)已经能达到万级别的QPS,并且也具备很强的高可用特性。如果主从能满足业务需求的情况下,所以如果不是在万不得已的情况下,尽量不搭建Redis集群
键值设计#
key如何设计#
- 遵循基本格式:[业务名称]:[数据名]:[id]。好处:可读性强、避免key冲突、方便管理
- 长度不超过44字节。embstr在小于44字节使用,采用连续内存空间,内存占用更小。
拒绝bigkey#
什么是bigkey?
BigKey通常以Key的大小和Key中成员的数量来综合判定,例如:
- Key本身的数据量过大:一个String类型的Key,它的值为5 MB
- Key中的成员数过多:一个ZSET类型的Key,它的成员数量为10,000个
- Key中成员的数据量过大:一个Hash类型的Key,它的成员数量虽然只有1,000个但这些成员的Value(值)总大小为100 MB
推荐值:
- 单个key的value小于10KB
- 对于集合类型的key,建议元素数量小于1000
危害
- 网络阻塞:对BigKey执行读请求时,少量的QPS就可能导致带宽使用率被占满
- 数据倾斜:BigKey所在的Redis实例内存使用率远超其他实例,无法使数据分片的内存资源达到均衡
- Redis阻塞:对元素较多的hash、list、zset等做运算会耗时较旧,使主线程被阻塞
发现bigkey
-
命令:
redis-cli -a 密码 --bigkeys -
scan扫描:利用scan扫描Redis中的所有key,利用strlen、hlen等命令判断key的长度,scan会返回下一次迭代的光标,一次读几个。
删除bigkey
BigKey内存占用较多,即便时删除这样的key也需要耗费很长时间,导致Redis主线程阻塞,引发一系列问题。
redis 3.0 及以下版本,如果是集合类型,则遍历BigKey的元素,先逐个删除子元素,最后删除BigKey。
Redis在4.0后提供了异步删除的命令:unlink
恰当的数据类型#
例1:比如存储一个User对象,我们有三种存储方式:
①方式一:json字符串
| user:1 |
|---|
优点:实现简单粗暴
缺点:数据耦合,不够灵活
②方式二:字段打散
| user:1:name | Jack |
|---|---|
| user:1:age | 21 |
优点:可以灵活访问对象任意字段
缺点:占用空间大、没办法做统一控制
③方式三:hash(推荐)
| user:1 | name | jack |
| age | 21 |
优点:底层使用ziplist,空间占用小,可以灵活访问对象的任意字段
缺点:代码相对复杂
例2:假如有hash类型的key,其中有100万对field和value,field是自增id,这个key存在什么问题?如何优化?
典型的BigKey
| key | field | value |
| someKey | id:0 | value0 |
| ..... | ..... | |
| id:999999 | value999999 |
hash的entry数量超过500时,会使用哈希表而不是ZipList,内存占用较多
方案一
拆分为string类型
| key | value |
| id:0 | value0 |
| ..... | ..... |
| id:999999 | value999999 |
存在的问题:
- string结构底层没有太多内存优化,内存占用较多
- 想要批量获取这些数据比较麻烦
方案二
拆分为小的hash,将 id / 100 作为key, 将id % 100 作为field,这样每100个元素为一个Hash
| key | field | value |
| key:0 | id:00 | value0 |
| ..... | ..... | |
| id:99 | value99 | |
| key:1 | id:00 | value100 |
| ..... | ..... | |
| id:99 | value199 | |
| .... | ||
| key:9999 | id:00 | value999900 |
| ..... | ..... | |
| id:99 | value999999 | |




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· C#/.NET/.NET Core技术前沿周刊 | 第 29 期(2025年3.1-3.9)
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异