高性能MYSQL LEC3 服务器性能剖析
最常碰到的三个性能相关问题:
- 如何确认服务器达到性能最佳
- 找出某条语句为什么执行不够快
- 以及诊断“停顿”、“堆积”、“卡死”的问题
解决:
- 专注于测量服务器的时间花费在哪里,使用的技术则是性能剖析(profiling)
- 本章将展示如何测量系统并生成剖析报告,以及如何分析整个系统的堆栈,包括从应用程序到数据库服务器到单个查询。
1 性能优化简介#
性能优化思想#
-
数据库的性能:完成某件任务所需要的时间。换句话说,性能即响应时间。
-
数据库的性能优化:在一定工作负载下尽可能降低响应时间。
-
优化思想:先测量再优化,优化前请先测量响应时间花在哪里 。
-
响应时间,由执行时间和等待时间组成。
-
优化执行时间,要测量不同子任务花费时间,然后优化子任务。
-
优化等待时间,较为复杂,因为等待可能由其它系统间接影响造成,任务间也可能由于争用磁盘或者CPU资源、锁而相互影响。
-
通过性能剖析来进行性能优化#
- 性能剖析步骤:
- 测量任务花费时间
- 然后对结果进行统计和排序,重要的任务排到前面。
- 性能剖析报告(PROFILE REPORT BY pt-query-digest)会按照任务的总响应时间进行降序排序。
- 每一行包括了查询的总响应时间和占总时间的百分比、查询的执行次数、单次执行的平均响应时间以及该查询摘要(比如SELECT语句)
- 没有显示的信息:
- 值得优化的查询。一些只占总响应时间比重很小的查询是不值得优化的。如果优化的成本大于收益,就应当停止优化。
- 异常情况:比如某些任务执行次数很少,但每次执行都非常慢,这样总响应时间占比很小。这种情况也需要优化。
- 被掩藏的细节:比如查询的平均值,可能存在一两个极端较,这需要大查询时间拉高平均时间,比如2s拉高1ms,这需要更多信息,比如百分比、标准差、直方图等。
- 性能剖析类型:
- 基于执行时间的分析:研究的是什么任务执行时间最长
- 基于等待的分析:判断任务在什么地方被阻塞的时间最长
- 当基于执行时间的分析发现一个任务需要花费太多时间的时候,应该深入去分析一下,可能会发现某些“执行时间”实际上是在等待。比如一个SELECT可能在等待I/O完成上。
- 比如日志显示一条查询花费10秒,其中9.6秒在磁盘I/O,那么追究其他4%的时间花费在哪里毫无意义,磁盘I/O才是最重要的原因。
- 性能剖析手段:
- 使用explain 语句可看是否走了索引(是否使用了索引)
- 使用SHOW PROFILES可看执行该语句前所有语句的执行时间排名
- 使用show profile cpu ,block io for QUERY ID (块IO开销)可看具体情况。
3 剖析MYSQL查询#
剖析服务器负载(找出慢查询)#
- 这里一般用慢查询日志找可以优化的查询
- 捕获比较慢的查询,也可以设置long_query_time为0来捕获所有的查询
- 慢查询日志是开销最低、精度最高的测量查询时间的工具。即使在I/O密集型场景,其I/O开销也可以忽略不计。
- 慢查询日志的正确使用方式:
- 不要直接打开整个慢查询日志进行分析,这样只会浪费时间
- 应当使用工具从慢查询日志中生成剖析报告,如把慢查询日志文件作为参数传递给pt-query-digest。它会将“重要”的查询逐条打印出更详细的信息。
- 每行有查询ID(对查询语句计算出的hash值指纹)、总响应时间、总查询次数、方差均值比(方差均值比高的对应执行时间变化大值得优化)、查询ITEM(比如SELECT)。
- 如果pt-query-digest指定了--explain选项,输出结果会增加一列简要描述执行计划。
剖析单条查询#
通过慢查询日志可以找出需要优化的单条查询,以下几种方法帮助我们优化单条查询。
SHOW PROFILES、SHOW STATUS、慢查询日志、EXPLAIN
使用SHOW PROFILES
-
SHOW PROFILES展示之前的所有查询

-
查某条查询的信息,阶段耗时、CPU、I/O情况
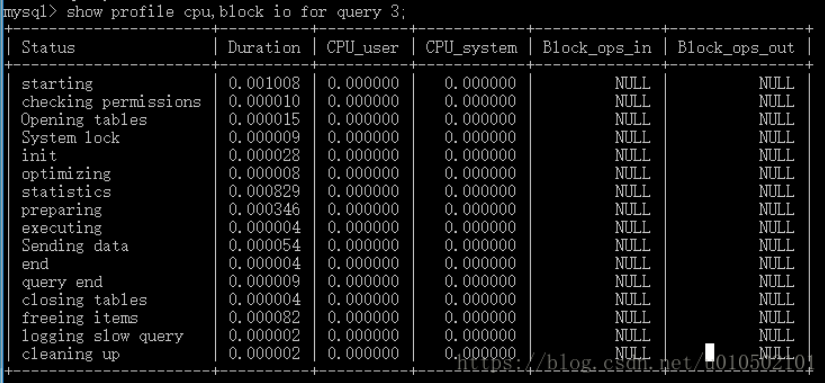
- INFORMATION_SCHEMA.PROFILING表有相关信息,同样where QUERY ID,这样做是可以把阶段操作按耗时排序。
使用SHOW STATUS#
-
SHOW STATUS返回一些计数器。注意到EXPLAIN查看执行计划也能获得大部分相同信息,但EXPLAIN是估计得到的结果,计数器是实际的测量结果。比如EXPLAIN无法告诉你临时表是否是磁盘表。
flush STATUS; SELECT * FROM users; SHOW STATUS WHERE VARIABLE_NAME LIKE 'Handler%' OR VARIABLE_NAME LIKE 'Created%'; 注意其中Created_tmp_tables,Created_tmp_disk_tables,可以判断是否多表关联等 Handler_read_key: 访问索引的时候定位到值所在的位置用到的函数。 Handler_read_first:定位索引的第一条数据。 Handler_read_next:访问索引的下一条数据。 Handler_read_rnd_next:不用索引,全表扫描。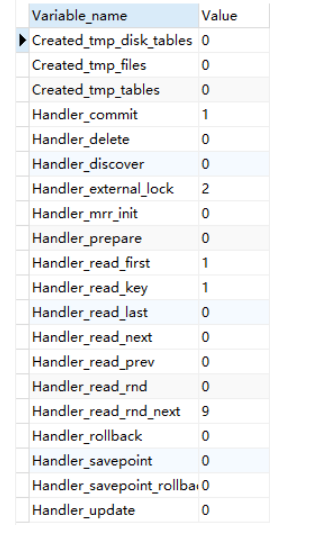
使用慢查询日志#
看对应慢查询日志的部分
使用EXPLAIN查询其执行计划#
查看该SQL语句有没有使用上了索引,有没有做全表扫描




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)