关键词提取处理流程
关键词提取处理流程
1 数据预处理#
1.1 PDFBox提取PDF文字#
从org.apache.pdfbox中引入PDDocument和PDFTextStripper,前者用来在内存中存储pdf document,后者用来提取文本,使用getText方法将其转为String类型。
1.2 文字处理与过滤#
步骤一 :将所有大写字母转为小写
步骤二:将所有特殊字符转为空格,然后用[\s](file://s)的正则表达式来分割字符串,将其转化为String数组
步骤三:对所有词做词形还原,例如将ies转为y,将s去掉
步骤四:使用停顿词(stopwords)表,过滤掉所有长度小于等于2或为停顿词的单词
1.3 数据存储#
依次读取文件中的pdf文件,对每一个pdf调用1.1和1.2来得到一个arraylist,然后使用类型为ArrayList<ArrayList
2 关键词提取#
2.1 TF-IDF方法提取#
2.1.1 算法思想#
如果某个词在其他文章较少见,但是它在这篇文章中多次出现,那么它很可能就反映了这篇文章的特性,正是我们所需要的关键词。
Tf = 该词在文章中出现次数/文章总词数
Idf = log(文章数/(包含该词的文章数+1))
Tf-idf = Tf * Idf
2.1.2 算法实现#
步骤一:对每篇文章的每个单词计算出它的Tf-Idf值,并将其存入一个类型为ArrayList<Map<String, Double>>的maplist,每一个pdf对应一个HashMap。
步骤二:使用findMaxKey方法来找到每一个Map的前10个最大值(value),并使用一个类型为ArrayList<Map<String, Double>>的keylist来存储这些最大值。这些HashMap中的key-value对就是对应每篇文章的关键词。
2.2 TextRank方法提取#
2.2.1 算法思想#
在PageRank的基础上,引入边的权值的概念,代表句子间的相似度。而其阻尼系数d取值范围为 0 到 1, 代表从图中某一特定点指向其他任意点的概率, 一般取值为 0.85。使用TextRank 算法计算图中各点的得分时, 需要给图中的点指定任意的初值, 并递归计算直到收敛, 即图中任意一点的误差率小于给定的极限值时就可以达到收敛, 一般该极限值取 0.0001。
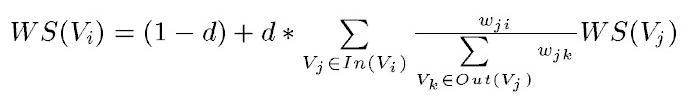
但如果把一个单词视为一个句子的话,那么所有句子(单词)构成的边的权重都是0(没有交集,没有相似性),所以分子分母的权值w约掉了,算法退化为PageRank。所以说,关键字提取算法也就是PageRank。
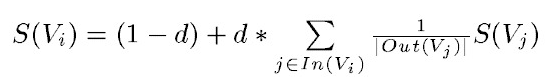
2.2.2 算法实现#
步骤一:计算距离每个词距离不大于窗口大小的词的集合
步骤二:根据公式进行迭代,直到所有词的重要性收敛到某一个值的时候,就可以停止迭代并得到结果。结果存储在类型为Map<String, Double>的map中
步骤三:使用findMaxKey方法取前50个权值最大的作为关键词,并将其存入Map<String, Double>的key-map中
2.3 WordMax方法提取#
2.3.1 算法思想#
如果某个词在预处理中没有被过滤,并且在本篇文章出现次数非常多,那么它很可能就反映了这篇文章的特性,正是我们所需要的关键词。
2.3.2 算法实现#
步骤一:对每篇文章计算出每个词出现的次数,并将其存入一个类型为ArrayList<HashMap<String,Double>>的wordMapList
步骤二: 使用findMaxKey方法来找到每一个Map的前10个最大值,并将其存入一个类型为ArrayList<Map<String, Double>>的wordMaxKeyList。这些HashMap中的key-value对就是对应每篇文章的关键词。
3 数据输出#
使用writer方法将2中得到的结果按一定格式分别写入TFIDF_dic.txt,TextRank_dic.txt,WordMax_dic.txt.




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix