自然语言处理3.8——分割
分词是分割的一个更普遍的问题实例,这一节,我们要学习一下分割技术。
1、断句
在词级水平处理文本时候通常假定能够将文本划分成单个句子。 一些语料库提高了句子级别的访问。例如,我们可以计算布朗预料库中每个句子的平均词数。
>>>print(len(nltk.corpus.brown.words())/len(nltk.corpus.brown.sents()) 20.25099070456922
在其他情况下,文本可能只是一个字符流。在将文本分词之前,需要将它分割成句子。NLTK通过包含Punkt句子分割器简化了这些。下面是将它作为一篇小说文本断句的例子:
这个例子其实是一个单独的句子,用于报道Lucian Gregory先生的演讲。
>>> text = nltk.corpus.gutenberg.raw('chesterton-thursday.txt')
>>> sents = nltk.sent_tokenize(text)
>>> pprint.pprint(sents[79:89])
['"Nonsense!"',
'said Gregory, who was very rational when anyone else\nattempted paradox.',
'"Why do all the clerks and navvies in the\n'
'railway trains look so sad and tired, so very sad and tired?',
'I will\ntell you.',
'It is because they know that the train is going right.',
'It\n'
'is because they know that whatever place they have taken a ticket\n'
'for that place they will reach.',
'It is because after they have\n'
'passed Sloane Square they know that the next station must be\n'
'Victoria, and nothing but Victoria.',
'Oh, their wild rapture!',
'oh,\n'
'their eyes like stars and their souls again in Eden, if the next\n'
'station were unaccountably Baker Street!"',]
2.分词
对于一些书写系统,由于没有词边界的可视表示这一事实,文本分词变得更加困难
考虑下面的例子,词的边界已经被去除了:
(1) a.doyouseethekitty
b.seethedoggy
c.doyoulikethekitty
d.likethedoggy
第一个挑战仅仅是表示这个问题:需要找到一种方法来分开文本内容与分词标志。可以给每一个字符标注一个布尔值来指示这个字符后面是否有一个分词标志。假设说话人会给语言学习者一个停顿,这往往对应一个延长的暂停。
>>> text = "doyouseethekittyseethedoggydoyoulikethekittylikethedoggy" >>> seg1 = "0000000000000001000000000010000000000000000100000000000" >>> seg2 = "0100100100100001001001000010100100010010000100010010000"
观察由0和1组成的分词表示字符串。他比原文本要短一个字符。因为长度为n的文本可以在n-1处进行分割。下面例子演示了如何从这个表示回到初始分词的文本
例:从分词表示字符串seg1和seg2中重建文本分词。
def segment(text, segs):
words = []
last = 0
for i in range(len(segs)):
if segs[i] == '1':
words.append(text[last:i+1])
last = i+1
words.append(text[last:])
return words
>>> text = "doyouseethekittyseethedoggydoyoulikethekittylikethedoggy" >>> seg1 = "0000000000000001000000000010000000000000000100000000000" >>> seg2 = "0100100100100001001001000010100100010010000100010010000" >>> segment(text, seg1) ['doyouseethekitty', 'seethedoggy', 'doyoulikethekitty', 'likethedoggy'] >>> segment(text, seg2) ['do', 'you', 'see', 'the', 'kitty', 'see', 'the', 'doggy', 'do', 'you', 'like', 'the', 'kitty', 'like', 'the', 'doggy']
现在分词的任务变成了一个搜索问题:找打将文本字符串正确分割成词汇的字位串。这里的做法是:定义一个目标函数,一个打分函数,将基于词典的大小和从词典中重构原文本所需要的信息量去优化它的值。下图解释了这些:
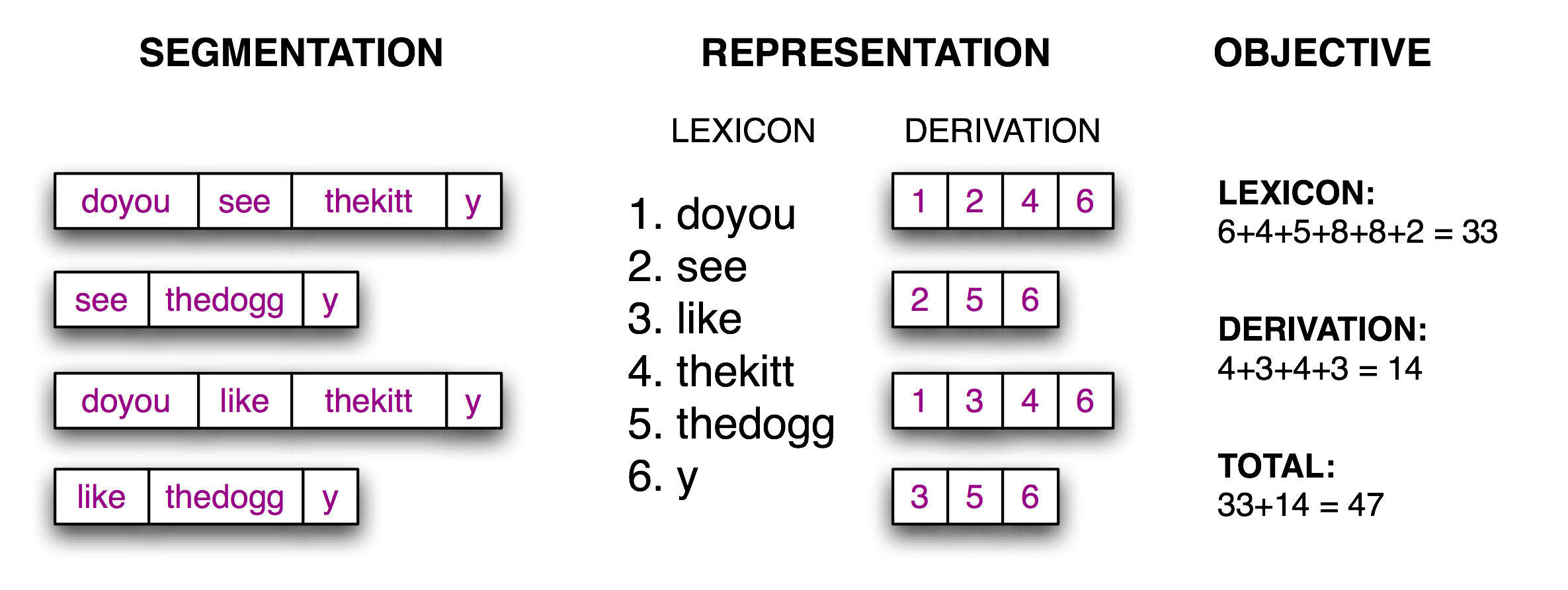
图:计算目标函数:给定一个假设的原文本分分词(左),推导出一个词典和推导表,他能让原文本重构,然后合计每个词项(包括边界标志)和推导表的字符数量,作为分词质量的得分;得分数越小越好。
实现这个目标函数很简答:如下:
def evaluate(text, segs):
words = segment(text, segs)
text_size = len(words)
lexicon_size = sum(len(word) + 1 for word in set(words))
return text_size + lexicon_size
>>> text = "doyouseethekittyseethedoggydoyoulikethekittylikethedoggy" >>> seg1 = "0000000000000001000000000010000000000000000100000000000" >>> seg2 = "0100100100100001001001000010100100010010000100010010000" >>> seg3 = "0000100100000011001000000110000100010000001100010000001" >>> segment(text, seg3) ['doyou', 'see', 'thekitt', 'y', 'see', 'thedogg', 'y', 'doyou', 'like', 'thekitt', 'y', 'like', 'thedogg', 'y'] >>> evaluate(text, seg3) 47 >>> evaluate(text, seg2) 48 >>> evaluate(text, seg1) 64
最后一步是寻找最大化目标函数值0和1的模式,请注意,最好的分词包括像‘thekitty’这样的词,因为没有证据进一步去分割这个词。
现在我们引入模拟退火算法来解决这个问题,关于模拟退火算法在《集体智慧编程》上有讲。或者链接
模拟退火算法的非确定性搜索:一开始搜索短语分词,随机扰动0和1,他们和‘温度’成比例。每次迭代温度都会降低,扰动边界也会减少
from random import randint
def flip(segs, pos):
return segs[:pos] + str(1-int(segs[pos])) + segs[pos+1:]
def flip_n(segs, n):
for i in range(n):
segs = flip(segs, randint(0, len(segs)-1))
return segs
def anneal(text, segs, iterations, cooling_rate):
temperature = float(len(segs))
while temperature > 0.5:
best_segs, best = segs, evaluate(text, segs)
for i in range(iterations):
guess = flip_n(segs, round(temperature))
score = evaluate(text, guess)
if score < best:
best, best_segs = score, guess
score, segs = best, best_segs
temperature = temperature / cooling_rate
print(evaluate(text, segs), segment(text, segs))
print()
return segs
>>> text = "doyouseethekittyseethedoggydoyoulikethekittylikethedoggy" >>> seg1 = "0000000000000001000000000010000000000000000100000000000" >>> anneal(text, seg1, 5000, 1.2) 61 ['doyouseetheki', 'tty', 'see', 'thedoggy', 'doyouliketh', 'ekittylike', 'thedoggy'] 59 ['doy', 'ouseetheki', 'ttysee', 'thedoggy', 'doy', 'o', 'ulikethekittylike', 'thedoggy'] 57 ['doyou', 'seetheki', 'ttysee', 'thedoggy', 'doyou', 'liketh', 'ekittylike', 'thedoggy'] 55 ['doyou', 'seethekit', 'tysee', 'thedoggy', 'doyou', 'likethekittylike', 'thedoggy'] 54 ['doyou', 'seethekit', 'tysee', 'thedoggy', 'doyou', 'like', 'thekitty', 'like', 'thedoggy'] 52 ['doyou', 'seethekittysee', 'thedoggy', 'doyou', 'like', 'thekitty', 'like', 'thedoggy'] 43 ['doyou', 'see', 'thekitty', 'see', 'thedoggy', 'doyou', 'like', 'thekitty', 'like', 'thedoggy'] '0000100100000001001000000010000100010000000100010000000'
这种方法可以用在那些词的边界没有任何视觉表示的手写系统分词。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号