自然语言处理3.3——使用Unicode进行文字处理
全世界有多种语言,经常需要应用程序处理不同的语言和字符集。下面将介绍如何利用Unicode处理使用非ASCII字符集文字。
1.什么是Unicode
Unicode支持一百万种以上的字符,每一个字符分配一个编号,称为编码点。在Python中编码点写作\uXXXX,其中XXXX是四位十六进制数。
在一段程序中,可以像普通字符串那样操纵Unicode字符串。然而,当Unicode字符被存储在文件里或者终端上显示时候,必须编码为字节流。由于一些编码的每个编码点都使用单字节,所以他们只需要支持Unicode中的一个小子集就足够一种语言使用了,但是其他编码(UTF-8)使用多个字节,可以表示全部的Unicode字符。
注意:将文本翻译成Unicode叫做解码,相对的,将Unicode转化为合适的编码称为编码。如下图:
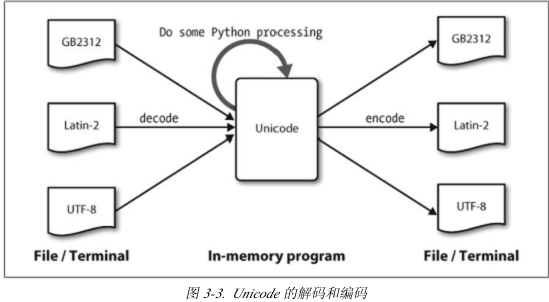
2,从文件中提取已经编码文本。
假设有一个小的文本文件,并且知道他是怎么编码的,例如:polish-lat2.txt是波兰语的文本片段。为Latin-2编码。下面首先使用nltk.data.find()函数定位文件
path=nltk.data.find('corpora/unicode_samples/polish-lat2.txt')
Python的codecs模块提供了将编码数据读入为Unicode字符串和将Unicode字符串以编码的形式输出的函数。codecs.open()函数有一个encoding参数来制定被读取或者写入的文件的编码。我们导入codecs模块,以‘Latin-2’为encoding的参数,打开制定的波兰语文件
>>>import codecs >>>f=codecs.open(path,encoding='latin2')
从文件对象f读出的文本将会以Unicode返回。为了能在终端上查看这个文本我们需要使用合适的编码对它进行编码。Python特定的unicode_escape是一个虚拟的编码,他把所有的非ASCII字符转换成\uXXXX形式。编码点在ASCII码0~127的范围以外但是低于256的,使用两位数字的形式表示。
>>>for line in f:
line=line.strip()
print(line.encode('unicode_escape'))
b'Pruska Biblioteka Pa\\u0144stwowa. Jej dawne zbiory znane pod nazw\\u0105'
b'"Berlinka" to skarb kultury i sztuki niemieckiej. Przewiezione przez'
b'Niemc\\xf3w pod koniec II wojny \\u015bwiatowej na Dolny \\u015al\\u0105sk, zosta\\u0142y'
b'odnalezione po 1945 r. na terytorium Polski. Trafi\\u0142y do Biblioteki'
b'Jagiello\\u0144skiej w Krakowie, obejmuj\\u0105 ponad 500 tys. zabytkowych'
b'archiwali\\xf3w, m.in. manuskrypty Goethego, Mozarta, Beethovena, Bacha.'
可以看到在输出文本的第一行有一个以\u转义字符串开始的Unicode转义字符串。即\u0144。
在Python中,一个Unicode字符串常量可以通过在字符串前面加一个u也就是例如u‘hello’来制定。
>>>print(u'\u0061') a >>>nacute=u'\u0144' >>>print(nacute) ń
Python在指定print使用repr()转化字符串,repr()输出UTF-8转义字符,而不是试图显示字形。
>>>nacute_utf=nacute.encode('utf-8')
>>>print(repr(nacute_utf))
b'\xc5\x84'
unicodedata模块使我们可以检查Unicode字符的属性。
>>> import unicodedata
>>> unicodedata.lookup('LEFT CURLY BRACKET')
'{'
>>> unicodedata.name('/')
'SOLIDUS'
>>> unicodedata.decimal('9')
9
>>> unicodedata.decimal('a')
Traceback (most recent call last):
File "<stdin>", line 1, in ?
ValueError: not a decimal
>>> unicodedata.category('A') # 'L'etter, 'u'ppercase
'Lu'
>>> unicodedata.bidirectional('\u0660') # 'A'rabic, 'N'umber
'AN'


 浙公网安备 33010602011771号
浙公网安备 33010602011771号