JAVA入门基础_spring_cloud微服务高级篇
- (第一章)微服务保护
- (第二章)分布式事务(不在单个服务或单个数据库架构下,产生的事物,ACID难以满足)
- CAP定理、BASE理论、解决分布式事物的思路
- 初始Seata
- XA模式的使用
- AT模式
- TCC模式
- TCC模式的基本介绍及架构图
- 实现TCC模式
- 以为支付订单的服务为例,创建一张冻结表
- 编写一个实体类
- 使用MyBatisPlus创建其Mapper和Service,这里就不再赘述
- 在业务层接口上添加@LocalTCC注解,并且利用@TwoPhaseBusinessAction注解(Try)规范Confirm和Cancel的方法,传递参数使用@BusinessActionContextParameter
- 编写TCC业务代码,需要保证3个方法的幂等性, 还有Try中的业务悬挂,以及Cancel中的空回滚问题(有点类似于对原有业务代码进行了封装)
- 中途如果出现反复不停的调用cancel,是因为cancel返回了false,如果启动seata报错出现No channel is available for resource,就清理一下TC所使用的全局事务表和分支事务表
- SAGA模式(了解,脏写)
- 三、TC服务的高可用和异地容灾
- (第3章)分布式缓存
- (第4章)多级缓存
- (第5章)MQ高级(基于RabbitMQ)
- 消息可靠性
- 死信交换机、TTL、延迟队列
- 惰性队列
- RabbitMQ集群
(第一章)微服务保护
雪崩问题及4个解决方案
-
什么是微服务雪崩问题?
- 一句话:微服务雪崩问题就是整个微服务中的某个服务出现了问题而后导致整个微服务瘫痪。牵一发而动全身。
-
4种解决方案
-
超时处理。当请求某个微服务时,请求时间超过阈值没有响应,则直接放弃该处理任务,返回错误提示。
-
舱壁模式。限定每个微服务的请求线程,一旦达到阈值,则无法再请求新的线程访问该微服务。(舱壁模式通常有2种实现方式:信号量策略和线程隔离策略)
-
熔断/降级。
- 当访问某个微服务时,一旦达到了熔断指定的规则阈值(慢查询、异常比例、异常数量等规则),则会执行熔断策略(例如5秒后才可以再次进行访问)。
- 降级指的是当微服务访问出现异常时的兜底处理方案,例如返回一些默认值等,通常跟Feign远程访问的组件有关。
-
限流。
- 限流模式:指的是访问某个微服务的频率,一般可以按照QPS来进行限制,也就是每秒的访问线程数量。如果设置某个微服务的QPS为10,则代表每秒才能处理10个请求。
- 限流效果:(1)多余的请求直接拒绝 (2)采用冷启动的方式warm up (3)多余的请求会进入队列等待,需要设置最大等待时间。超出时间就拒绝了
-
Sentinel的安装
-
sentinel官方提供了UI控制台,下载Sentinel的jar包:下载地址
-
下载好的样子是这样的

-
直接运行,可以指定端口参数
java -jar sentinel-dashboard-1.8.1.jar -
如果要修改Sentinel的默认端口、账户、密码,可以通过下列配置:
| 配置项 | 默认值 | 说明 |
| -------------------------------- | ---------- | ---------- |
| server.port | 8080 | 服务端口 |
| sentinel.dashboard.auth.username | sentinel | 默认用户名 |
| sentinel.dashboard.auth.password | sentinel | 默认密码 | -
例如:修改端口
java -Dserver.port=8090 -jar sentinel-dashboard-1.8.1.jar -
通过如下地址即可访问sentinel的控制台
http://localhost:8080
微服务整合Sentinel
- 引入如下依赖
<!--sentinel-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
- 修改配置
server:
port: 8088
spring:
cloud:
sentinel:
transport:
dashboard: localhost:8080
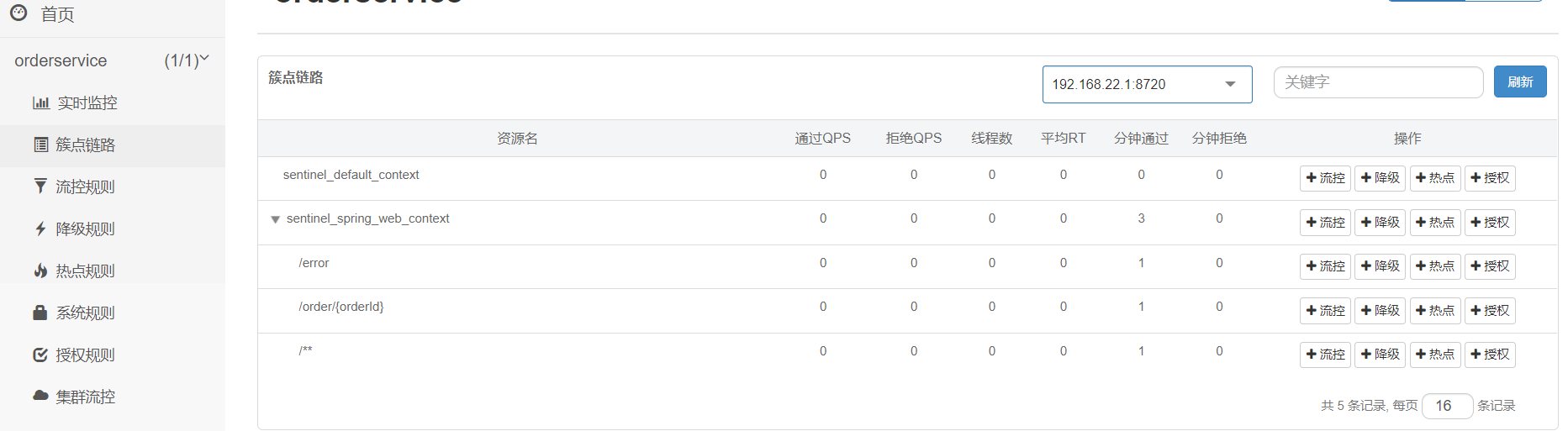
- 访问一个任意端点(任意一个Controller),即可在Sentinel的控制台中的 簇点链路中找到
- 例如:
http://localhost:8088/order/101
- 例如:
Jmeter的快速入门
安装Jmeter
-
下载后的文件解压

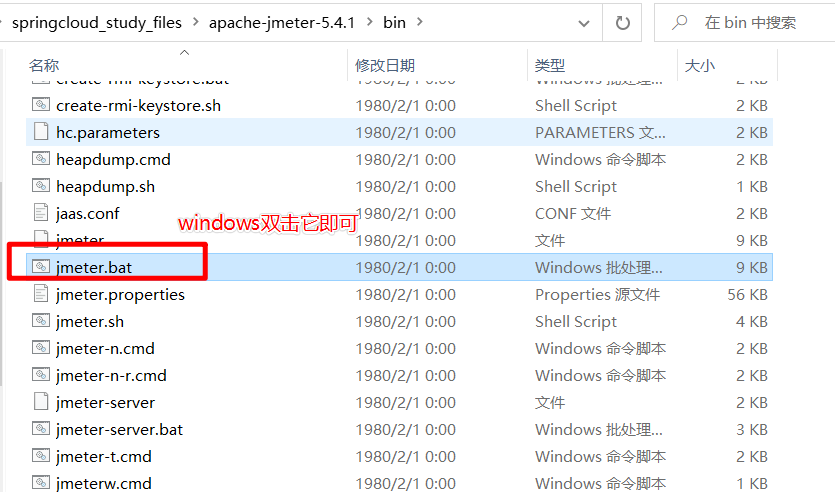
-
打开解压目录后的bin目录,双击打开
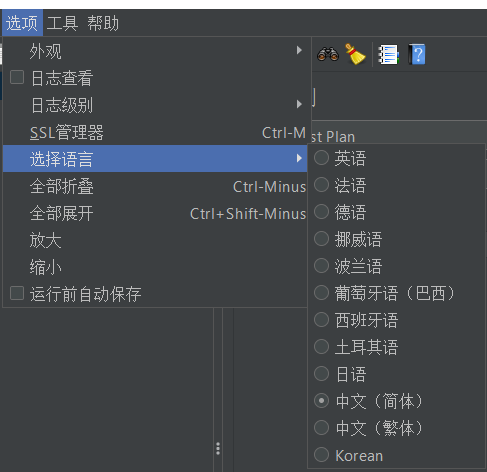
设置中文
-
临时配置
-
永久生效,需要修改bin目录下的
jmeter.properties添加如下配置
language=zh_CN
基本用法(测试计划、线程组、设置QPS、添加HTTP请求、设置参数、查看汇总报告及结果树、启动方式)
-
新建测试计划

-
添加线程组

-
设置QPS

-
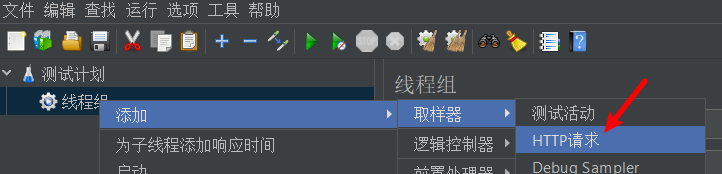
添加HTTP请求
-
设置HTTP请求的参数
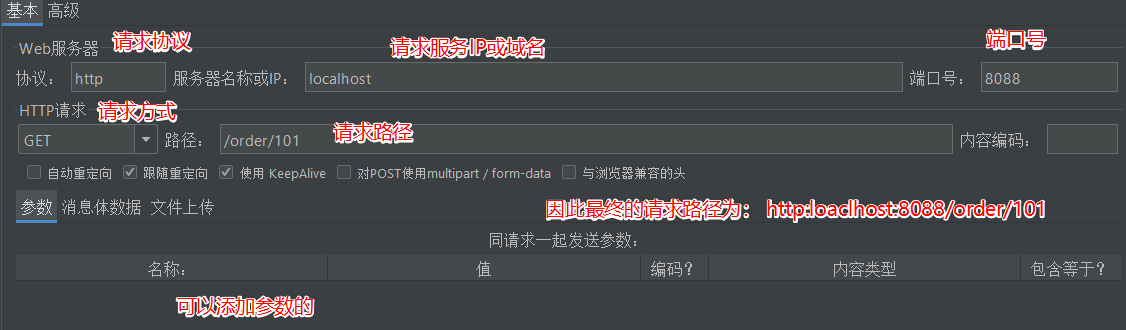
-
添加汇总报告 以及 查看结果树
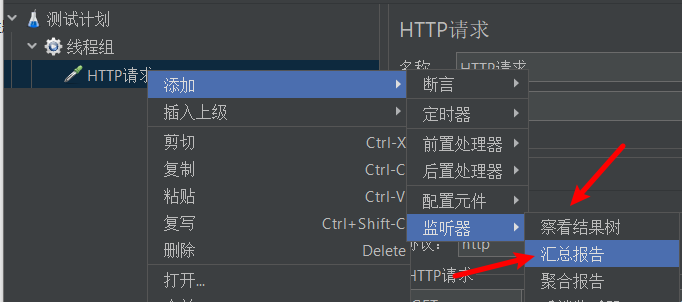
-
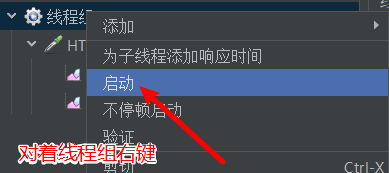
启动压力测试
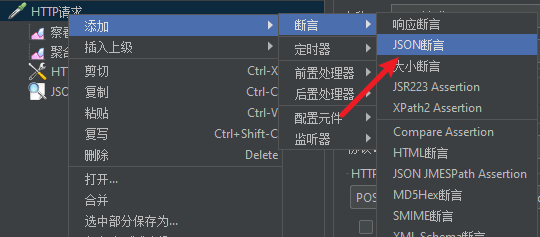
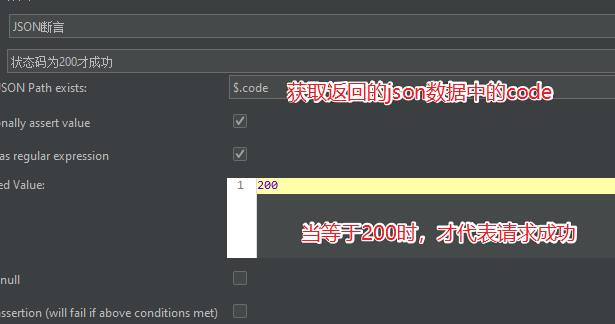
设置Json断言
添加消息头或cookie
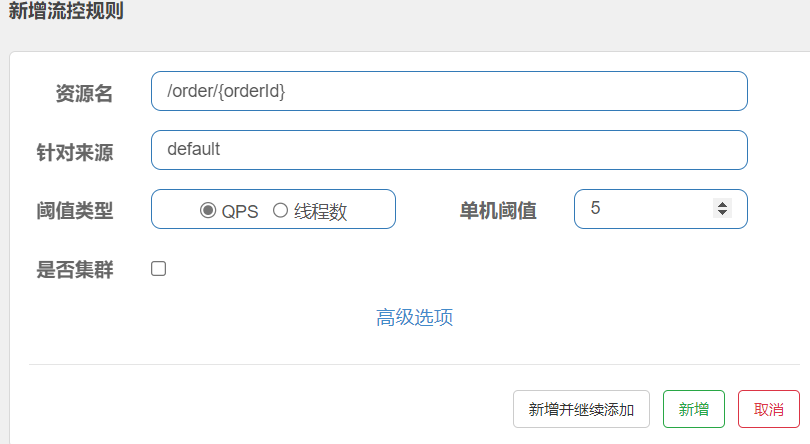
流量控制(限流)
演示3种流控模式
直接模式
-
直接对某个请求进行流量控制。
-
使用示例: 设置某个簇点链路的QPS为5,也就是每秒只能接收5个请求
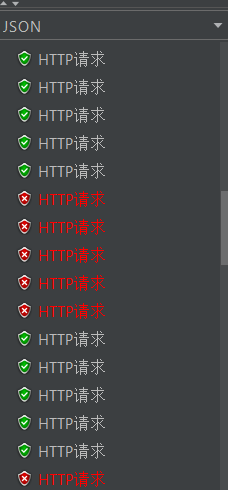
-
设置之后可以在流控规则查看到

-
查看QPS为10的压力测试效果
关联模式
-
当一个簇点链路达到限流阈值时候,对另一个簇点链路进行限流
-
适用场景: 高优先级的服务受到请求压力时,对低优先级的服务进行限流
-
场景: 用户修改订单状态。此时需要修改订单状态的同时,用户又需要查询订单。但是修改订单状态的优先级高于查询。此时当修改订单的服务达到阈值时,对查询订单进行限流。
-
使用示例(添加流控规则是对需要进行限流的簇点链路添加)
首先有2个服务,我们模拟用户修改订单与查询订单

当修改订单的服务达到阈值时,就对查询订单进行限流。(例如设置QPS的阈值为5)
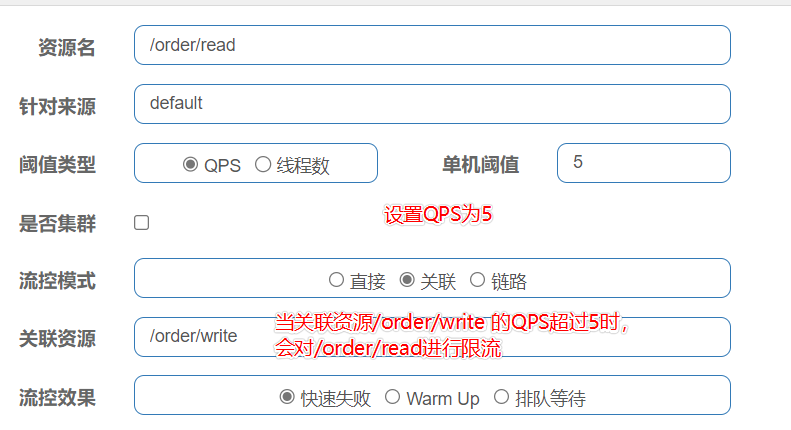
- 进行压力测试(沿用刚刚的线程组,需要修改HTTP请求参数)此时在压力测试的过程中,通过浏览器去访问/read,发现会抛出异常
Blocked by Sentinel (flow limiting)

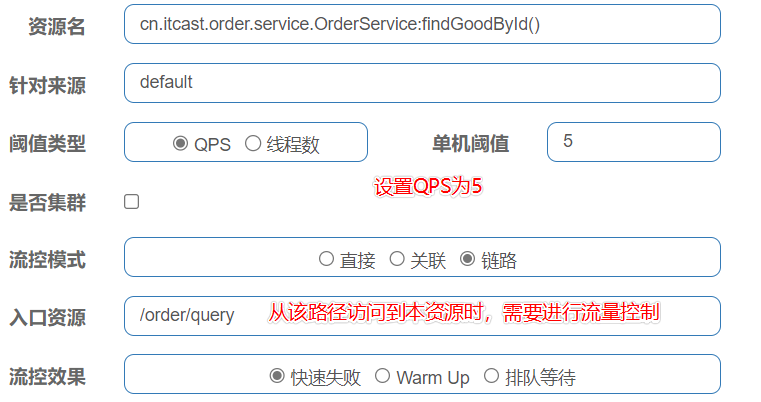
链路模式(请求来源的限流,被控制的资源如果不是一个端点,需要添加注解,以及修改配置文件)
-
只针对从指定的簇点链路访问到本资源的请求进行限流控制
-
例子:查询订单和创建订单的服务都需要查询商品
-
因此查询订单 /order/query 中需要调用查询商品的方法 findGoodById();
-
创建订单的服务 /order/save 中也需要调用查询订单的方法 findGoodById();
-
此时我们可以对 findGoodById()这个簇点链路进行流控,设置从 /order/save访问到本资源的流量需要被控制
-
-
使用实例
(1)为需要进行流量控制的资源添加如下注解(如果本身不是一个断点的话)
@SentinelResource
public void findGoodById(){
System.out.println("根据ID查询商品的方法");
}
(2)在sentinel管理界面中添加流控规则
(3)关闭sentinel对spring的资源整合
链路模式中,是对不同来源的两个链路做监控。但是sentinel默认会给进入SpringMVC的所有请求设置同一个root资源,会导致链路模式失效。
spring:
cloud:
sentinel:
web-context-unify: false # 关闭context整合
(3)进行压力测试(对/order/save 和 /order/save 分别进行压力测试将会看到效果)
流控效果控制
快速失败(默认)
- 当达到阈值时,新的请求会立即被拒绝并直接抛出FlowException异常
warm up 预热效果
-
阈值虽然是一个微服务最大能够承受的QPS大小,但是当服务刚启动时,一切资源尚未初始化(冷启动),如果一瞬间有太多的请求可能导致该微服务不堪重负直接倒下。
-
warm up模式将会通过设置一个时间段,慢慢的加大阈值,让阈值随着时间慢慢达到最大值。
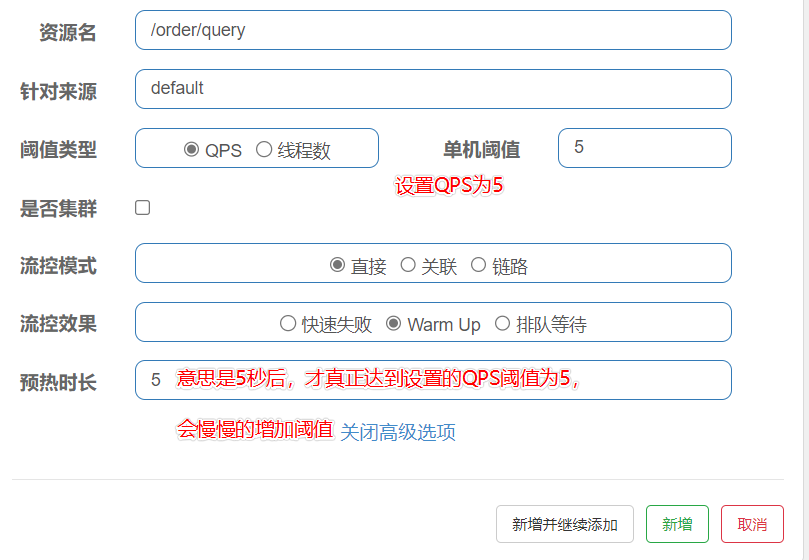
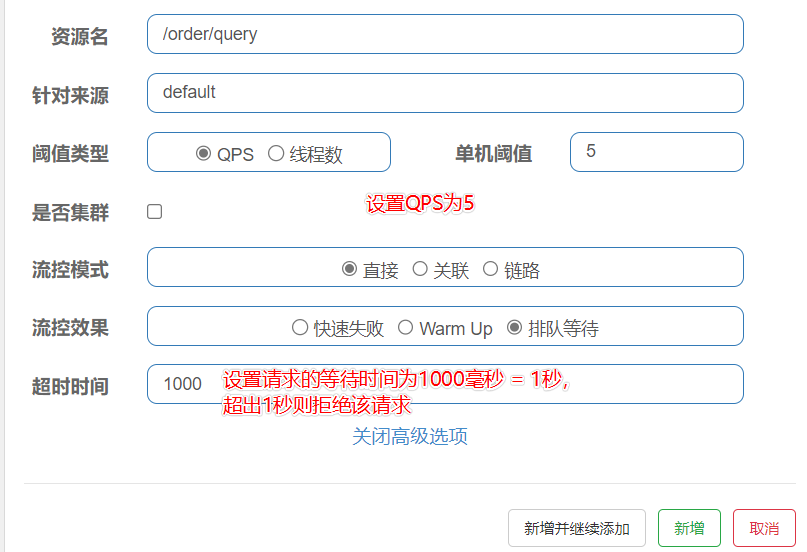
排队等待效果
- 当请求达到阈值时,多出的请求会进入等待队列,当等待时间内仍然没有被响应,则拒绝该请求,返回FlowException异常。
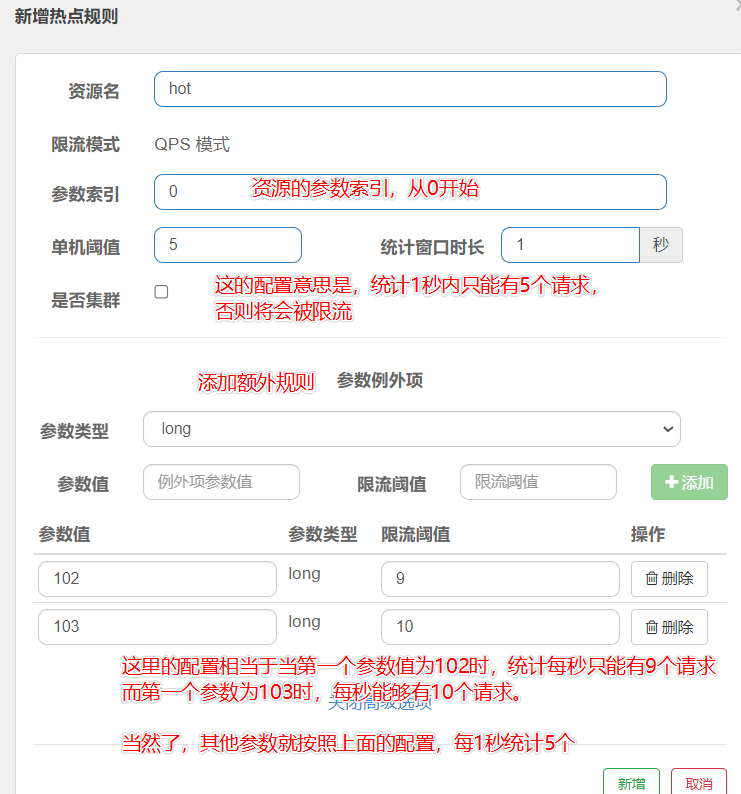
热点参数限流(需要到热点规则中添加,对SpringMVC的资源无效,需要添加注解)
-
是更细粒化对流量的控制,细粒化到请求的参数上。并且可以对某些参数结果做额外限制。
-
使用示例
(1)添加注解(这里取的名字,待会添加限流规则要用)
@GetMapping("{orderId}")
@SentinelResource(value = "hot")
public Order queryOrderByUserId(@PathVariable("orderId") Long orderId) {
// 根据id查询订单并返回
return orderService.queryOrderById(orderId);
}
(2)复制需要限流的热点资源名称(需要在左边菜单项中选择热点规则,再进行配置)

(3)配置热点参数限流规则
隔离、熔断、降级
Feign整合Sentinel(因为微服务都是由Feign请求的,所以...)该Feign是单独的一个模块,注意
修改使用到了Feign的微服务的配置文件,添加如下配置
feign:
sentinel:
enabled: true # 开启feign对sentinel的支持
编写失败降级逻辑(2种方式)
-
方式一: FallbackClass,无法对远程调用的异常做处理
-
方式二: FallbackFactory,可以对远程调用的异常做处理
-
编写一个Feign配置类
@Slf4j
public class UserClientFallbackFactory implements FallbackFactory<UserClient> {
/**
* 当UserClient请求出现异常时的兜底方案
* @param throwable
* @return
*/
@Override
public UserClient create(Throwable throwable) {
log.error("当前UserClient请求出现异常");
return new UserClient() {
/**
* 触发兜底方案,返回一个空User对象
* @param id 根据id查询用户
* @return
*/
@Override
public User findById(Long id) {
return new User();
}
};
}
}
- 将该类加载到Spring容器当中
public class DefaultFeignConfiguration {
@Bean
public Logger.Level logLevel(){
return Logger.Level.BASIC;
}
/**
* 将降级工厂配置到Spring容器当中
* @return
*/
@Bean
public UserClientFallbackFactory userClientFallbackFactory() {
return new UserClientFallbackFactory();
}
}
- 在Feign客户端上配置
@FeignClient(value = "userservice",fallbackFactory = UserClientFallbackFactory.class)
public interface UserClient {
@GetMapping("/user/{id}")
User findById(@PathVariable("id") Long id);
}
- 哪个微服务需要使用到 Feign模块时,需要进行配置
@EnableFeignClients(clients = UserClient.class,
defaultConfiguration = DefaultFeignConfiguration.class)
// 这个defaultConfiguration 配置的很重要,刚好可以将其加入到Spring容器当中
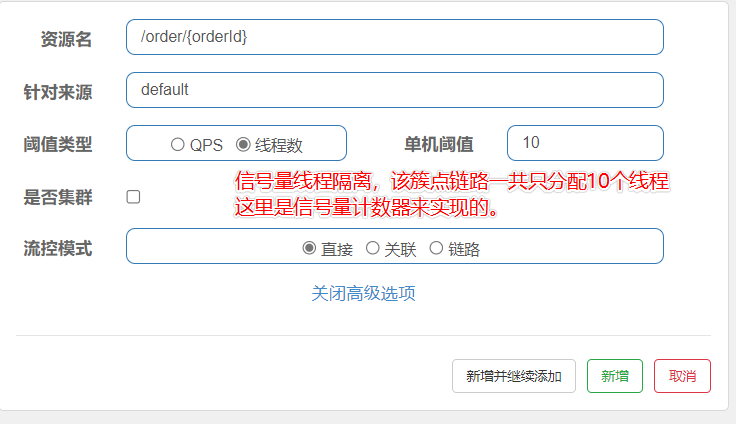
线程隔离(舱壁模式,也可以配置限流的3种流控模式)
-
线程隔离的2种实现方式
-
线程池隔离
-
信号量隔离
-
-
使用Sentinel配置线程隔离
熔断降级(3种熔断策略)
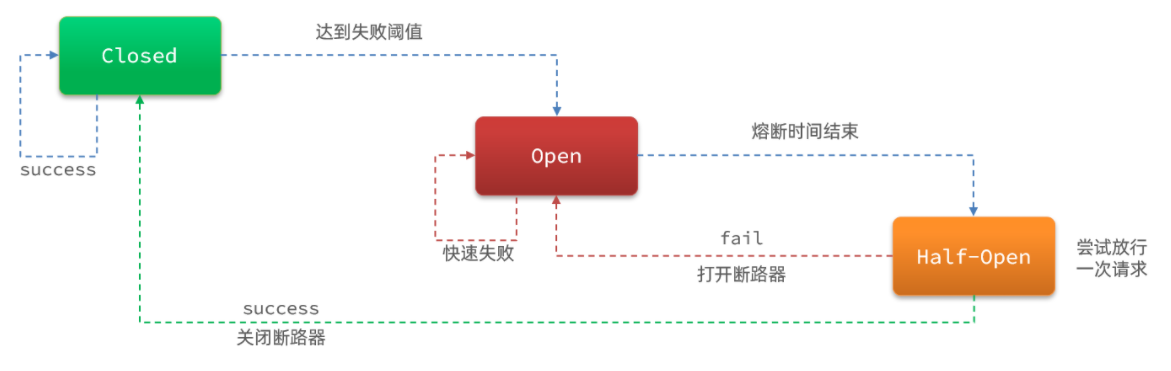
慢查询熔断规则(当half-open状态再请求,依然还是慢查询,则会再次熔断)
-
断路器的状态图,当断路器处于open状态,则代表服务被熔断。
-
当某个微服务达到了熔断的规则,比如根据慢查询阈值 或 异常比例阈值 或 异常数量阈值时,当请求再次需要访问该微服务时,则Sentinel会拒绝该请求,然后抛出异常。
-
设置降级规则
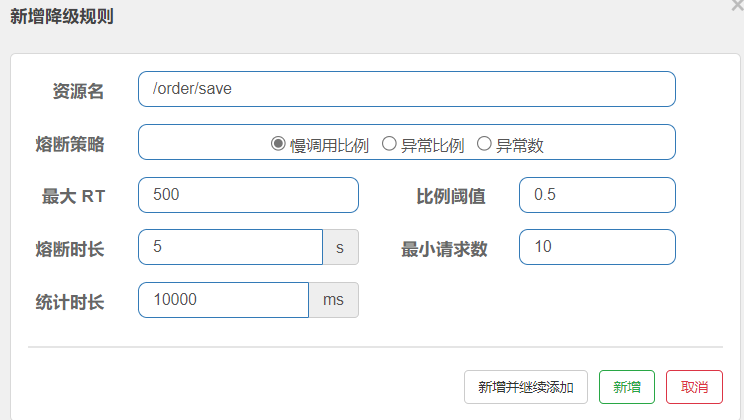
解读:
(1)熔断策略:当然就是断路器什么时候开启的策略了
(2)最大RT:当RT(Response Time)响应时间超过500ms时,代表该查询为慢查询
(3)比例阈值:当有百分之50的请求都为慢查询时,则超出阈值
(4)熔断时长: 当触发熔断后,该为服务5秒内无法被使用,一旦请求该服务则直接拒绝
(5)最小请求数:10个
(6)统计时常: 10000ms内,也就是10秒内
一句话: 统计10秒内的 10个请求,如果这10个请求中有百分之50的请求的响应时间都超过了500毫秒,则触发熔断,使该簇点链路/order/save 5秒内无法被访问。
异常比例
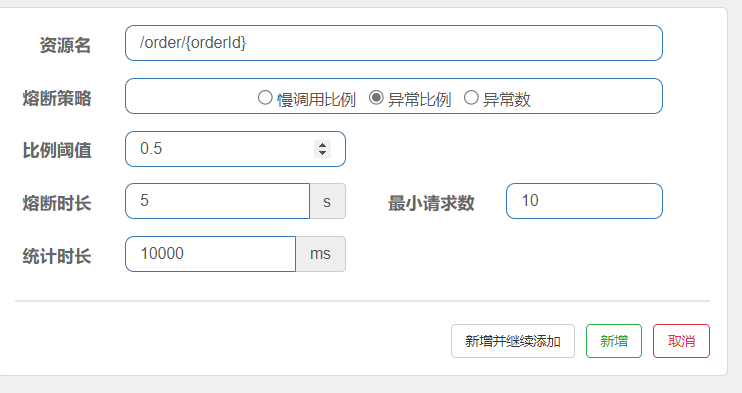
解读:统计10秒内的10个请求,如果有百分之50都发生了异常,则进行熔断
异常数量
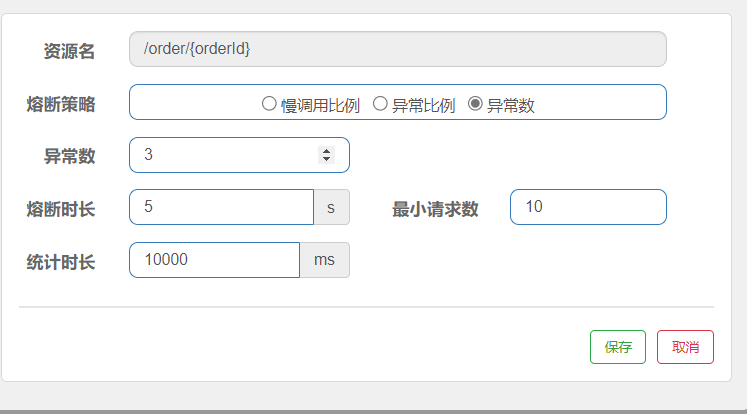
解读: 统计10秒内的10个请求,如果这10个请求中有3个出现了异常,则进行熔断
授权规则 与 自定义异常结果(之前都是抛出异常,页面显示一段异常,太不友好了)
授权规则(防止绕过网关直接访问微服务)
- sentinel的授权规则可以配置访问微服务的黑名单跟白名单
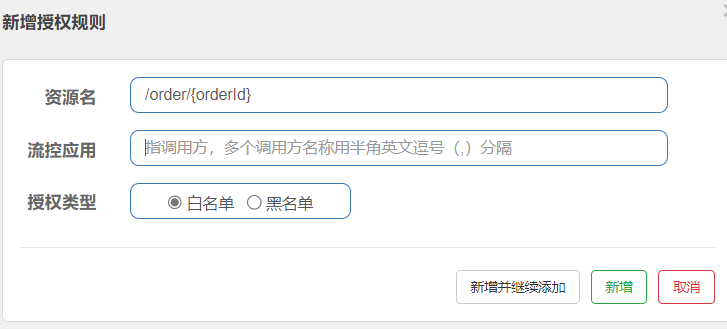
黑名单与白名单中的应用名称从哪来?
-
从每个微服务的实现RequestOriginParser接口所实现的方法来决定
-
例如这里我通过请求头的方式来获取一个应用名称
@Component
public class AuthOriginParser implements RequestOriginParser {
@Override
public String parseOrigin(HttpServletRequest httpServletRequest) {
String origin = httpServletRequest.getHeader("origin");
if(StringUtils.isBlank(origin)) {
origin = "DEFAULT";
}
return origin;
}
}
设置白名单
- 从下图可知,只有应用名称为gateway的程序,才可以访问当前的资源
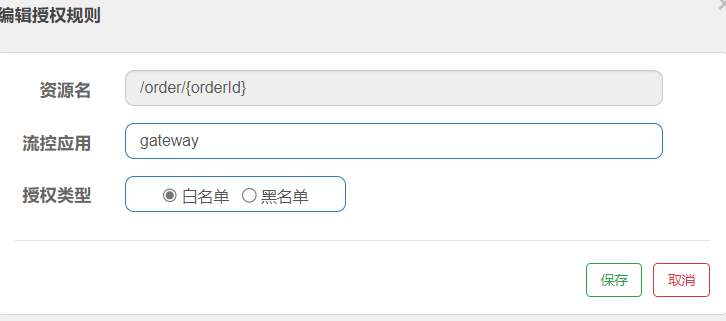
为gateway网关模块配置过滤工厂(gateway不用连接到sentinel)
spring:
application:
name: gateway
cloud:
nacos:
server-addr: localhost:8848 # nacos地址
gateway:
routes:
- id: user-service # 路由标示,必须唯一
uri: lb://userservice # 路由的目标地址
predicates: # 路由断言,判断请求是否符合规则
- Path=/user/** # 路径断言,判断路径是否是以/user开头,如果是则符合
- id: order-service
uri: lb://orderservice
predicates:
- Path=/order/**
default-filters:
- AddRequestHeader=origin,gateway # 从网关访问微服务进行路由转发时,都带上该请求头
- 接下来的主要是从网关访问的微服务,就可以正常访问,否则将会被拒绝
自定义异常结果
-
在被访问的微服务当中实现接口BlockExceptionHandler并实现其中的方法即可完成自定义异常处理
-
HttpServletRequest request:request对象
-
HttpServletResponse response:response对象
-
BlockException e:被sentinel拦截时抛出的异常
@Component
public class SentinelExceptionHandler implements BlockExceptionHandler {
@Override
public void handle(HttpServletRequest request, HttpServletResponse response, BlockException e) throws Exception {
String msg = "未知异常";
int status = 429;
if (e instanceof FlowException) {
msg = "请求被限流了";
} else if (e instanceof ParamFlowException) {
msg = "请求被热点参数限流";
} else if (e instanceof DegradeException) {
msg = "请求被降级了";
} else if (e instanceof AuthorityException) {
msg = "没有权限访问";
status = 401;
}
response.setContentType("application/json;charset=utf-8");
response.setStatus(status);
response.getWriter().println("{\"msg\": " + msg + ", \"status\": " + status + "}");
}
}
Sentinel中的异常种类
这里的BlockException包含多个不同的子类:
| 异常 | 说明 |
|---|---|
| FlowException | 限流异常 |
| ParamFlowException | 热点参数限流的异常 |
| DegradeException | 降级异常 |
| AuthorityException | 授权规则异常 |
| SystemBlockException | 系统规则异常 |
进行Sentinel中规则的持久化
-
sentinel中默认是将我们设置的规则都保存在内存的,因此我们只要重启微服务,这些规则就全都被丢弃了
-
Sentinel的持久化一共有2种方式,分别是pull模式和push模式
-
pull模式:控制台配置的规则推送到sentinel客户端后,客户端会将规则存储到数据库中,然后定时的去访问数据库更新规则(如果是集群可能会导致多台sentinel的数据不一致性问题)
-
push模式: 所有的sentinel全部都去一个统一的配置中心来获取当前的规则。比如说nacos
-
使用push模式来实现规则的持久化
- 需要注意的是:哪个微服务的规则需要被sentinel持久化?
配置需要进行规则持久化的微服务
- 在规则需要被持久化的微服务中添加如下依赖
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-datasource-nacos</artifactId>
</dependency>
- 在配置文件中配置sentinel需要连接的nacos地址及配置信息
spring:
cloud:
sentinel:
datasource:
flow: # 限流有关的配置
nacos:
server-addr: localhost:8848 # nacos地址
dataId: orderservice-flow-rules # 配置文件的名称
groupId: SENTINEL_GROUP
rule-type: flow # 还可以是:degrade、authority、param-flow
authority: # 这个是授权有关的配置
nacos:
server-addr: localhost:8848 # nacos地址
dataId: orderservice-flow-rules
groupId: SENTINEL_GROUP
rule-type: authority # 还可以是:degrade、authority、param-flow
修改Sentinel的源码
-
先下载sentinel的源码并解压
-
修改nacos依赖,sentinel中默认将nacos的依赖的scope设置为了test,将其删掉,使用compile
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-datasource-nacos</artifactId>
</dependency>
-
添加nacos支持:在sentinel-dashboard的test包下,已经编写了对nacos的支持,我们需要将其拷贝到main下
-
修改nacos地址: 修改测试代码中的NacosConfig类,修改其中的nacos地址,让其读取application.properties中的配置
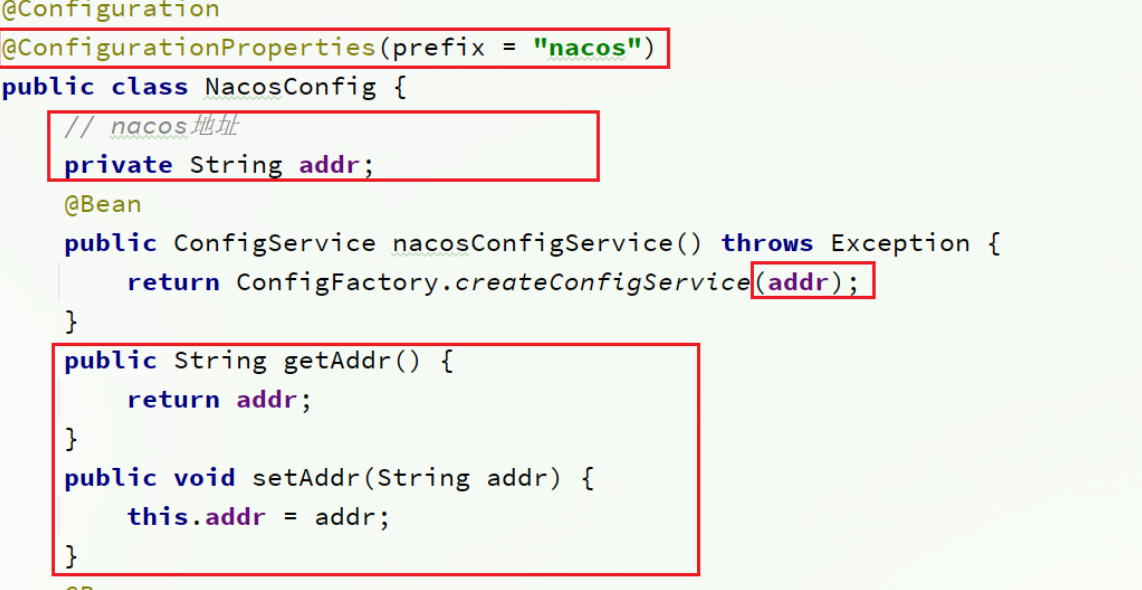
-
在sentinel-dashboard的application.properties中添加nacos地址配置
nacos.addr=localhost:8848 -
还需要修改com.alibaba.csp.sentinel.dashboard.controller.v2包下的FlowControllerV2类,让我们配置的nacos数据源生效
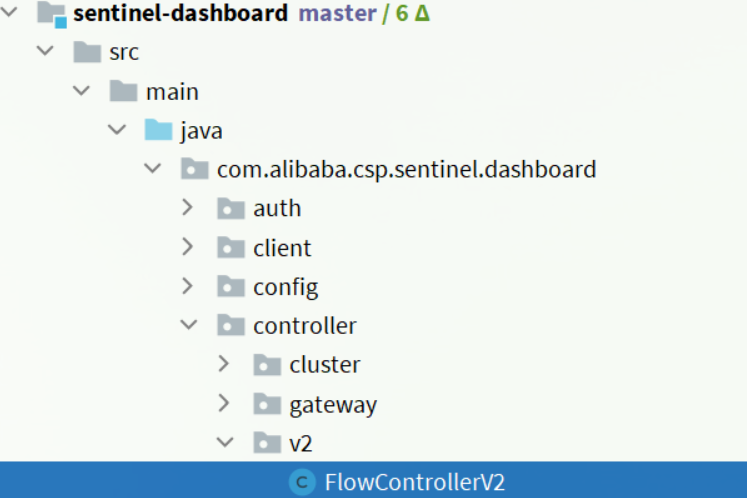
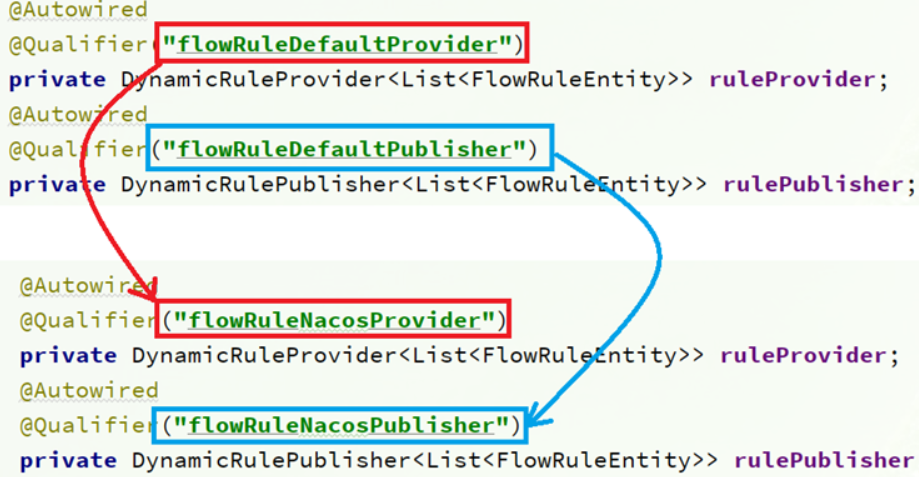
-
修改前端页面,添加一个支持nacos的菜单
修改src/main/webapp/resources/app/scripts/directives/sidebar/目录下的sidebar.html文件:
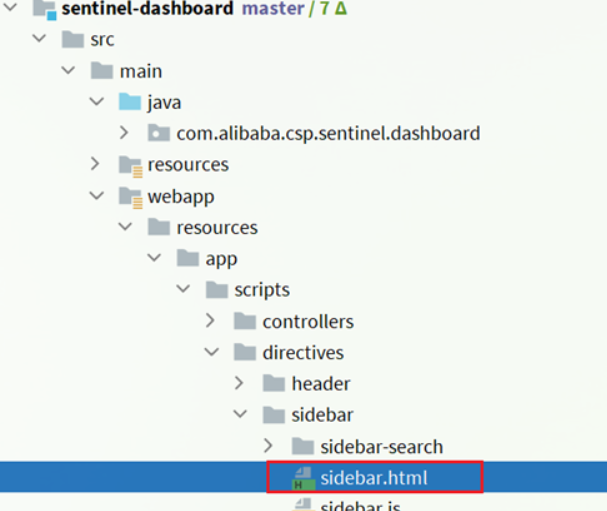
将注释掉的这一部分打开

修改部分内容

-
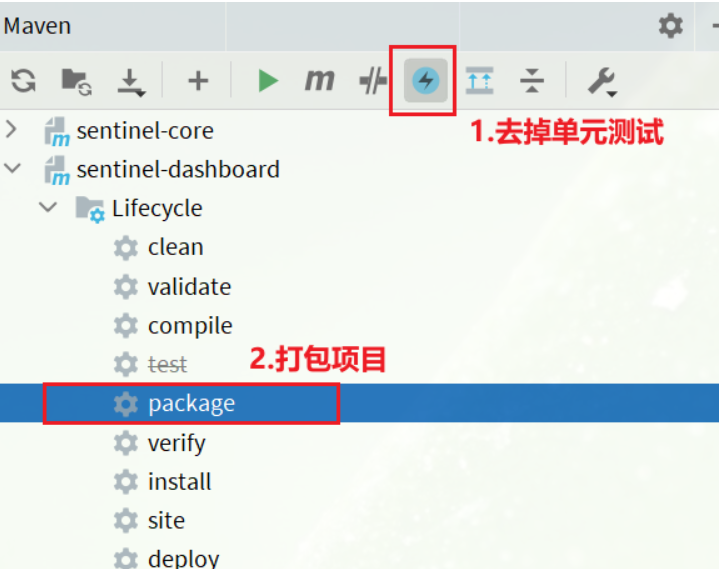
重新编译和打包
-
启动方式
java -jar sentinel-dashboard.jar
如果要修改nacos地址,需要添加参数
java -jar -Dnacos.addr=localhost:8848 sentinel-dashboard.jar
(第二章)分布式事务(不在单个服务或单个数据库架构下,产生的事物,ACID难以满足)
分布式事物:就是指不在单个服务或单个数据库架构下,产生的事物。例如
(1)跨数据源的分布式事物
(2)跨服务的分布式事物
(3)综合情况
CAP定理、BASE理论、解决分布式事物的思路
CAP定理(这三个指标不可能同时做到,这个结论就叫做CAP定理)
- Consistency(一致性)
- Availability(可用性)
- Partition tolerance (分区容错性)
- 分区:因为网络故障原因或其他原因导致分布式系统中的部分节点与其他节点失去联系,成为独立分区
- 容错: 即便出现了分区问题,整个系统也要对外提供服务
- **结论**:在分布式系统中,网络不可能百分百不出现问题,而一旦**出现问题导致了分区**,则会有如下的问题: 此时如果**想要保证C一致性,就必须等待网络恢复后完成数据的同步**。可如果需要**保证A可用性,则会导致直接对外提供服务,出现数据的不一致性**。因此在**P出现的时候,A和C只能选一个**
BASE理论(对CAP的一种解决思路),包含如下3个思想
- **Basically Available** **(基本可用)**:分布式系统出现故障时,允许损失部分可用性,保持**核心可用**
- Soft State(软状态): 在一定时间内,允许出现中间状态,比如临时的不一致性状态
- Eventually Consistent(最终一致性): 虽然无法保证强一致性,但是在软状态结束后,保持最终的一致性。
分布式事物的解决思路 AP、CP、TC
-
AP模式: 各个事物分别执行和提交,允许出现结果不一致,然后需要采用弥补措施,最终达成数据的一致性。
-
CP模式:各个事物执行后相互等待,最终一起提交或回滚,保证了数据的强一致性,但是事物等待的过程中,处于弱可用状态。
-
但是不管是哪一种模式,都需要子系统事物之间相互通讯,协调事物的状态,也就是需要一个事物协调者TC,这里的子系统事物,称为分支事物,有关联的各个分支事物在一起称为全局事物。
初始Seata
-
Seata的官方网站地址:http://seata.io/
-
Seata是蚂蚁金服和阿里巴巴共同开源的分布式事务解决方案。
Seata的架构
Seata中有3个重要的角色
-
TM: 事物管理器:管理分支事物处理的资源,与TC交谈以注册分支事物和报告分支事物的状态,并驱动分支事物提交或回滚。
-
RM: 资源管理器:定义全局事物的范围、开始全局事物、提交或回滚全局事物。
-
TC: 事物协调者:维护全局事物和分支事物的状态,协调全局事物提交和回滚

Seata基于如上架构提供了4种分布式事物的解决方案
-
XA模式:强一致性的分阶段事物模式,牺牲了一定的可用性,无业务侵入
-
AT模式:弱一致性的分阶段事物模式,能保证事物的最终一致性,有业务侵入(默认)
-
TCC模式:弱一致性的分阶段事物模式,能保证事物的最终一致性,通过冻结部分数据实现。非常费程序员,有业务侵入。代码自己写...
-
SAGA模式:长事物模式,有业务侵入(了解即可)
-
如上的无论哪种方案,都离不开事物协调者TC
下载和启动Seata服务
- 下载地址,下载后直接解压
修改配置conf目录下的registry.conf配置文件(使其注册到nacos上)
registry {
# tc服务的注册中心类,这里选择nacos,也可以是eureka、zookeeper等
type = "nacos"
nacos {
# seata tc 服务注册到 nacos的服务名称,可以自定义
application = "seata-tc-server"
serverAddr = "127.0.0.1:8848"
group = "DEFAULT_GROUP"
namespace = ""
# 这个集群,就是之前学习nacos时,nacos对统一集群中的服务进行管理时,
# 可以利用ribbon设置nacos的负载均衡,使同一集群中的服务相互访问,访问不到才访问其他集群的服务
cluster = "SH"
username = "nacos"
password = "nacos"
}
}
config {
# 读取tc服务端的配置文件的方式,这里是从nacos配置中心读取,这样如果tc是集群,可以共享配置
type = "nacos"
# 配置nacos地址等信息
nacos {
serverAddr = "127.0.0.1:8848"
namespace = ""
group = "SEATA_GROUP"
username = "nacos"
password = "nacos"
dataId = "seataServer.properties"
}
}
在nacos中对seata的配置进行统一的管理,创建配置文件seataServer.properties
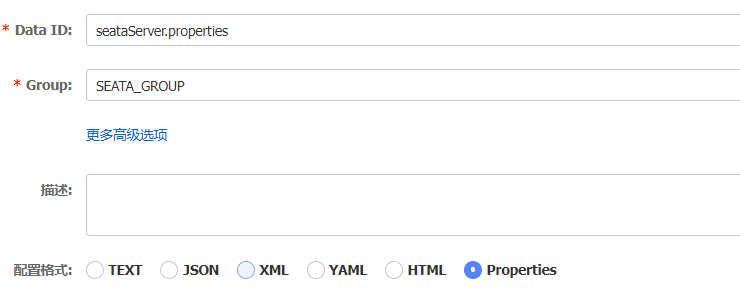
# 数据存储方式,db代表数据库
store.mode=db
store.db.datasource=druid
store.db.dbType=mysql
store.db.driverClassName=com.mysql.jdbc.Driver
store.db.url=jdbc:mysql://127.0.0.1:3306/seata?useUnicode=true&rewriteBatchedStatements=true
store.db.user=root
store.db.password=abc123
store.db.minConn=5
store.db.maxConn=30
# 全局表
store.db.globalTable=global_table
# 分支表
store.db.branchTable=branch_table
store.db.queryLimit=100
# 全局锁的表
store.db.lockTable=lock_table
store.db.maxWait=5000
# 事务、日志等配置
server.recovery.committingRetryPeriod=1000
server.recovery.asynCommittingRetryPeriod=1000
server.recovery.rollbackingRetryPeriod=1000
server.recovery.timeoutRetryPeriod=1000
server.maxCommitRetryTimeout=-1
server.maxRollbackRetryTimeout=-1
server.rollbackRetryTimeoutUnlockEnable=false
server.undo.logSaveDays=7
server.undo.logDeletePeriod=86400000
# 客户端与服务端传输方式
transport.serialization=seata
transport.compressor=none
# 关闭metrics功能,提高性能
metrics.enabled=false
metrics.registryType=compact
metrics.exporterList=prometheus
metrics.exporterPrometheusPort=9898
创建数据库表
- 创建一个名为seata的数据库(因为刚刚配置文件中写的就是这个名字),然后执行如下sql来创建全局事物表和分支事物表
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- 分支事务表
-- ----------------------------
DROP TABLE IF EXISTS `branch_table`;
CREATE TABLE `branch_table` (
`branch_id` bigint(20) NOT NULL,
`xid` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`transaction_id` bigint(20) NULL DEFAULT NULL,
`resource_group_id` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`resource_id` varchar(256) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`branch_type` varchar(8) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`status` tinyint(4) NULL DEFAULT NULL,
`client_id` varchar(64) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`application_data` varchar(2000) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`gmt_create` datetime(6) NULL DEFAULT NULL,
`gmt_modified` datetime(6) NULL DEFAULT NULL,
PRIMARY KEY (`branch_id`) USING BTREE,
INDEX `idx_xid`(`xid`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;
-- ----------------------------
-- 全局事务表
-- ----------------------------
DROP TABLE IF EXISTS `global_table`;
CREATE TABLE `global_table` (
`xid` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`transaction_id` bigint(20) NULL DEFAULT NULL,
`status` tinyint(4) NOT NULL,
`application_id` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`transaction_service_group` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`transaction_name` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`timeout` int(11) NULL DEFAULT NULL,
`begin_time` bigint(20) NULL DEFAULT NULL,
`application_data` varchar(2000) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`gmt_create` datetime NULL DEFAULT NULL,
`gmt_modified` datetime NULL DEFAULT NULL,
PRIMARY KEY (`xid`) USING BTREE,
INDEX `idx_gmt_modified_status`(`gmt_modified`, `status`) USING BTREE,
INDEX `idx_transaction_id`(`transaction_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;
SET FOREIGN_KEY_CHECKS = 1;
启动TC事物协调者服务(注意需要带上端口和ip)
-
进入到解压目录下的bin目录,打开命令行输入如下命令
.\seata-server.bat -p 8091 -h 127.0.0.1 -
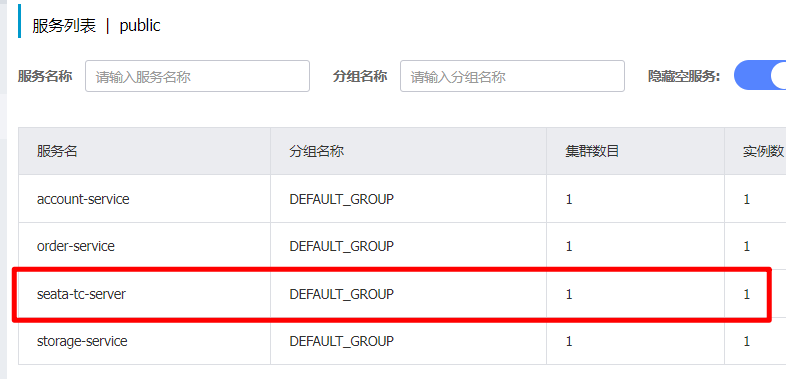
运行后应该已经注册到nacos上了,可以打开nacos的地址看看
localhost:8848/nacos
使微服务集成Seata
- 需要进行分布式事物控制的微服务,需要引入如下依赖
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-seata</artifactId>
<exclusions>
<!--版本较低,1.3.0,因此排除-->
<exclusion>
<artifactId>seata-spring-boot-starter</artifactId>
<groupId>io.seata</groupId>
</exclusion>
</exclusions>
</dependency>
<!--seata starter 采用1.4.2版本-->
<dependency>
<groupId>io.seata</groupId>
<artifactId>seata-spring-boot-starter</artifactId>
<version>${seata.version}</version>
</dependency>
- 修改配置文件,让微服务能够找到TC的地址与其进行连接
seata:
registry: # TC服务注册中心的配置,微服务根据这些信息去注册中心获取tc服务地址
type: nacos # 注册中心类型 nacos
nacos:
server-addr: 127.0.0.1:8848 # nacos地址
namespace: "" # namespace,默认为空
group: DEFAULT_GROUP # 分组,默认是DEFAULT_GROUP
application: seata-tc-server # seata服务名称
username: nacos
password: nacos
tx-service-group: seata-demo # 事务组名称
service:
vgroup-mapping: # 事务组与cluster的映射关系
seata-demo: SH

XA模式的使用
XA模式的基本介绍
- XA 规范 是 X/Open 组织定义的分布式事务处理(DTP,Distributed Transaction Processing)标准,XA 规范 描述了全局的TM与局部的RM之间的接口,几乎所有主流的数据库都对 XA 规范 提供了支持。,XA是规范,目前主流数据库都实现了这种规范,实现的原理都是基于两阶段提交。
原本的XA模型
一阶段:
- 事务协调者通知每个事物参与者执行本地事务
- 本地事务执行完成后报告事务执行状态给事务协调者,此时事务不提交,继续持有数据库锁
二阶段:
- 事务协调者基于一阶段的报告来判断下一步操作
- 如果一阶段都成功,则通知所有事务参与者,提交事务
- 如果一阶段任意一个参与者失败,则通知所有事务参与者回滚事务
Seata的XA模型
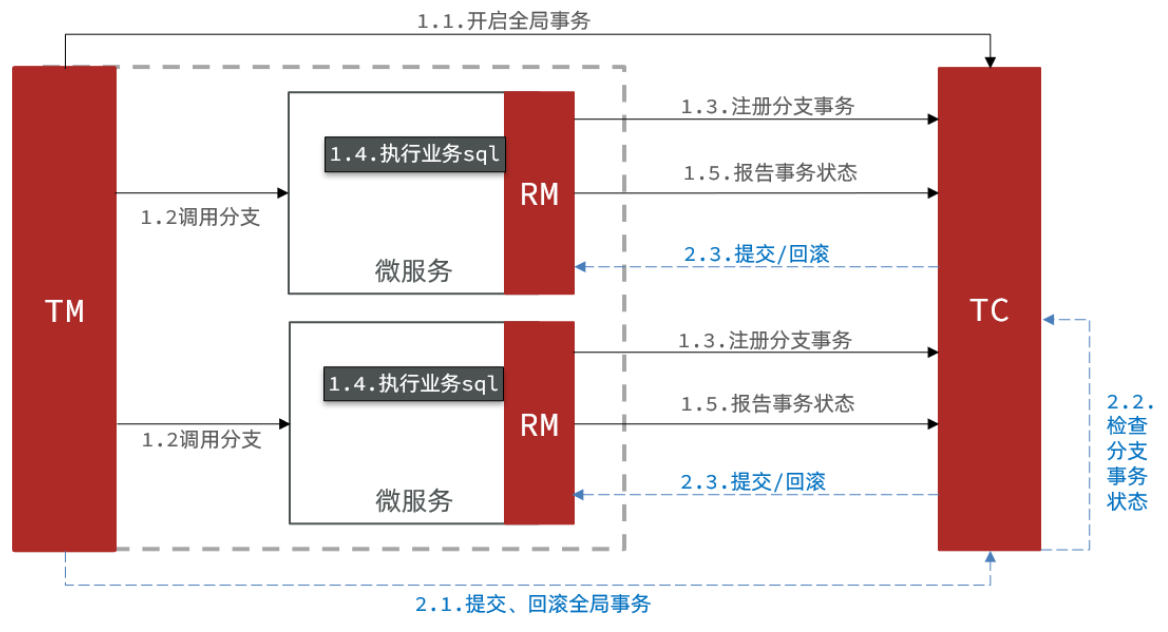
RM一阶段的工作:
① 注册分支事务到TC
② 执行分支业务sql但不提交
③ 报告执行状态到TC
TC二阶段的工作:
-
TC检测各分支事务执行状态
a.如果都成功,通知所有RM提交事务
b.如果有失败,通知所有RM回滚事务
RM二阶段的工作:
- 接收TC指令,提交或回滚事务
优缺点
-
优点
- 事物的强一致性,满足ACID原则
- 常用的数据库都支持,实现简单,并且无代码侵入
-
缺点
- 由于一阶段执行一个全局事物时,需要一直占有锁,占用资源
- 依赖关系型数据库实现事务
代码实现XA模式
-
seata的启动器已经为我们配置进行了XA的自动装配,我们只需要进行少量的配置即可完成XA模式
-
修改application.yml文件,修改模式
seata:
data-source-proxy-mode: XA
- 给全局事物的入口、入口、入口,添加@GlobalTransactional注解,即可完成XA模式
- 注意:这个入口指的不是Controller方法,而是Controller调用的业务层方法
@GlobalTransactional
public Long create(Order order) {
}
@PostMapping
public ResponseEntity<Long> createOrder(Order order){
Long orderId = orderService.create(order);
return ResponseEntity.status(HttpStatus.CREATED).body(orderId);
}
AT模式
AT模式介绍以及架构图
-
AT模式同样是分阶段提交的事务模型,不过缺弥补了XA模型中资源锁定周期过长的缺陷。
-
与XA的区别是,一阶段时并不等待,直接提交事务,最后通过TC检查分支事务状态来决定是否进行数据恢复

阶段一RM的工作:
- 注册分支事务
- 记录undo-log(数据快照)
- 执行业务sql并提交
- 报告事务状态
阶段二提交时RM的工作:
- 删除undo-log即可
阶段二回滚时RM的工作:
- 根据undo-log恢复数据到更新前
XA和AT的区别
简述AT模式与XA模式最大的区别是什么?
- XA模式一阶段不提交事务,锁定资源;AT模式一阶段直接提交,不锁定资源。
- XA模式依赖数据库机制实现回滚;AT模式利用数据快照实现数据回滚。
- XA模式强一致;AT模式最终一致
脏写问题

解决思路就是引入了全局锁的概念。在释放DB锁之前,先拿到全局锁。避免同一时刻有另外一个事务来操作当前数据。

使用JAVA代码实现AT模式
-
AT模式中的快照生成,全局锁的生成都是由框架已经为我们完成了的
-
我们只需要提供保存快照undo_log的表、保存全局锁global_lock的表,并进行少量的配置即可完成AT模式
在seata数据库中执行如下sql引入全局锁表(TC所管理的)
DROP TABLE IF EXISTS `lock_table`;
CREATE TABLE `lock_table` (
`row_key` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`xid` varchar(96) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`transaction_id` bigint(20) NULL DEFAULT NULL,
`branch_id` bigint(20) NOT NULL,
`resource_id` varchar(256) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`table_name` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`pk` varchar(36) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`gmt_create` datetime NULL DEFAULT NULL,
`gmt_modified` datetime NULL DEFAULT NULL,
PRIMARY KEY (`row_key`) USING BTREE,
INDEX `idx_branch_id`(`branch_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;
在微服务所连接的数据库中执行如下sql引入undo_log日志快照表(RM来做的)
DROP TABLE IF EXISTS `undo_log`;
CREATE TABLE `undo_log` (
`branch_id` bigint(20) NOT NULL COMMENT 'branch transaction id',
`xid` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT 'global transaction id',
`context` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT 'undo_log context,such as serialization',
`rollback_info` longblob NOT NULL COMMENT 'rollback info',
`log_status` int(11) NOT NULL COMMENT '0:normal status,1:defense status',
`log_created` datetime(6) NOT NULL COMMENT 'create datetime',
`log_modified` datetime(6) NOT NULL COMMENT 'modify datetime',
UNIQUE INDEX `ux_undo_log`(`xid`, `branch_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = 'AT transaction mode undo table' ROW_FORMAT = Compact;
修改配置文件
seata:
data-source-proxy-mode: AT # 默认就是AT
注意:AT模式,也是要在事务方法的入口加上@GlobalTransactional的,访问的那些微服务中的方法,只需要加上@Transactional就好
TCC模式
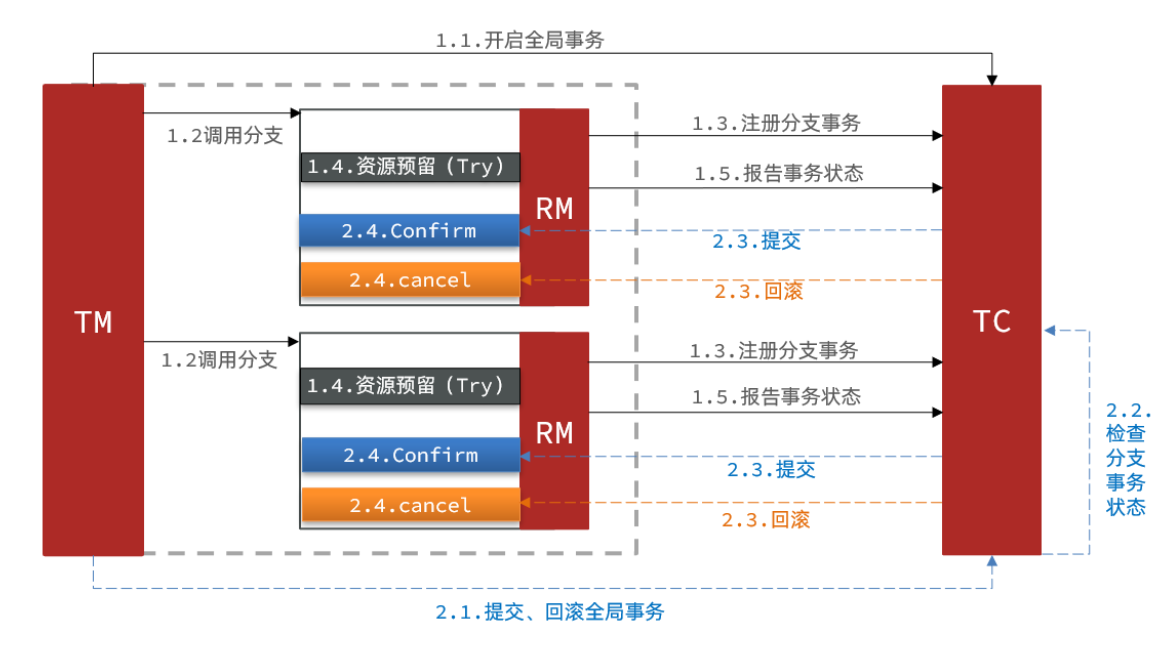
TCC模式的基本介绍及架构图
-
TCC模式与AT模式类似,每个阶段都是独立事物,AT模式是通过记录undo_log,而TCC模式则是通过补偿机制完成的
-
TCC的优势是不需要加锁,因此速度非常快,TCC中3个英文单词分别为
-
Try: 资源的检测和预留;
-
Confirm:完成资源操作业务;要求 Try 成功 Confirm 一定要能成功。
-
Cancel: - 预留资源释放,可以理解为try的反向操作。
TCC模式的优缺点
-
优点
-
一阶段直接提交事物,释放数据库资源,性能好
-
相比于AT模型,无需生成快照,无需使用全局锁,性能最强
-
不依赖数据库事物,也可以用在非关系型数据库上,比如redis
-
-
缺点
-
需要人工编写TCC业务代码,实现Try、Confirm、Cancel接口的方法
-
软状态,事物是最终一致
-
需要考虑Confirm和Cancel失败的情况,做好幂等处理
-
事物悬挂和空回滚
-
当某分支事务的try阶段阻塞时,可能导致全局事务超时而触发二阶段的cancel操作。在未执行try操作时先执行了cancel操作,这时cancel不能做回滚,就是空回滚。
-
事物悬挂:对于已经空回滚的业务,之前被阻塞的try操作恢复,继续执行try,就永远不可能confirm或cancel ,事务一直处于中间状态,这就是业务悬挂。
- 执行try操作时,应当判断cancel是否已经执行过了,如果已经执行,应当阻止空回滚后的try操作,避免悬挂
实现TCC模式
以为支付订单的服务为例,创建一张冻结表
CREATE TABLE `account_freeze_tbl` (
`xid` varchar(128) NOT NULL,
`user_id` varchar(255) DEFAULT NULL COMMENT '用户id',
`freeze_money` int(11) unsigned DEFAULT '0' COMMENT '冻结金额',
`state` int(1) DEFAULT NULL COMMENT '事务状态,0:try,1:confirm,2:cancel',
PRIMARY KEY (`xid`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=COMPACT;
编写一个实体类
@Data
@TableName("account_freeze_tbl")
public class AccountFreeze {
@TableId(type = IdType.INPUT)
private String xid;
private String userId;
private Integer freezeMoney;
private Integer state;
public static abstract class State {
public final static int TRY = 0;
public final static int CONFIRM = 1;
public final static int CANCEL = 2;
}
}
使用MyBatisPlus创建其Mapper和Service,这里就不再赘述
在业务层接口上添加@LocalTCC注解,并且利用@TwoPhaseBusinessAction注解(Try)规范Confirm和Cancel的方法,传递参数使用@BusinessActionContextParameter
@LocalTCC
public interface AccountTCCService{
@TwoPhaseBusinessAction(name = "deduct", commitMethod = "confirm", rollbackMethod = "cancel")
void deduct(@BusinessActionContextParameter(paramName = "userId") String userId,
@BusinessActionContextParameter(paramName = "money")int money);
boolean confirm(BusinessActionContext ctx);
boolean cancel(BusinessActionContext ctx);
}
编写TCC业务代码,需要保证3个方法的幂等性, 还有Try中的业务悬挂,以及Cancel中的空回滚问题(有点类似于对原有业务代码进行了封装)
@Service
@Slf4j
public class AccountTCCServiceImpl implements AccountTCCService {
@Autowired
private AccountMapper accountMapper;
@Autowired
private AccountFreezeMapper freezeMapper;
@Override
@Transactional
public void deduct(String userId, int money) {
// 0.获取事务id
String xid = RootContext.getXID();
// 0.1 防止事物悬挂
AccountFreeze oldFreeze = freezeMapper.selectById(xid);
if(oldFreeze != null) {
// 说明该事务,TRY已经执行过了,拒绝执行,保证幂等
return;
}
// 1.扣减可用余额
accountMapper.deduct(userId, money);
// 2.记录冻结金额,事务状态
AccountFreeze freeze = new AccountFreeze();
freeze.setUserId(userId);
freeze.setFreezeMoney(money);
freeze.setState(AccountFreeze.State.TRY);
freeze.setXid(xid);
freezeMapper.insert(freeze);
}
@Override
public boolean confirm(BusinessActionContext ctx) {
// 1.获取事务id
String xid = ctx.getXid();
// 2.根据id删除冻结记录
int count = freezeMapper.deleteById(xid);
return count == 1;
}
@Override
public boolean cancel(BusinessActionContext ctx) {
// 0.查询冻结记录
String xid = ctx.getXid();
AccountFreeze freeze = freezeMapper.selectById(xid);
// 0.1 是否空回滚
if(freeze == null) {
freeze = new AccountFreeze();
freeze.setXid(xid);
freeze.setState(AccountFreeze.State.CANCEL);
freezeMapper.insert(freeze);
return true;
}
// 0.2 注意幂等性
if(freeze.getState() == AccountFreeze.State.CANCEL) {
return true;
}
// 1.恢复可用余额
accountMapper.refund(freeze.getUserId(), freeze.getFreezeMoney());
// 2.将冻结金额清零,状态改为CANCEL
freeze.setFreezeMoney(0);
freeze.setState(AccountFreeze.State.CANCEL);
int count = freezeMapper.updateById(freeze);
return count == 1;
}
}
中途如果出现反复不停的调用cancel,是因为cancel返回了false,如果启动seata报错出现No channel is available for resource,就清理一下TC所使用的全局事务表和分支事务表

SAGA模式(了解,脏写)
Saga也分为两个阶段:
- 一阶段:直接提交本地事务
- 二阶段:成功则什么都不做;失败则通过编写补偿业务来回滚
优缺点
优点:
- 事务参与者可以基于事件驱动实现异步调用,吞吐高
- 一阶段直接提交事务,无锁,性能好
- 不用编写TCC中的三个阶段,实现简单
缺点:
- 软状态持续时间不确定,时效性差
- 没有锁,没有事务隔离,会有脏写
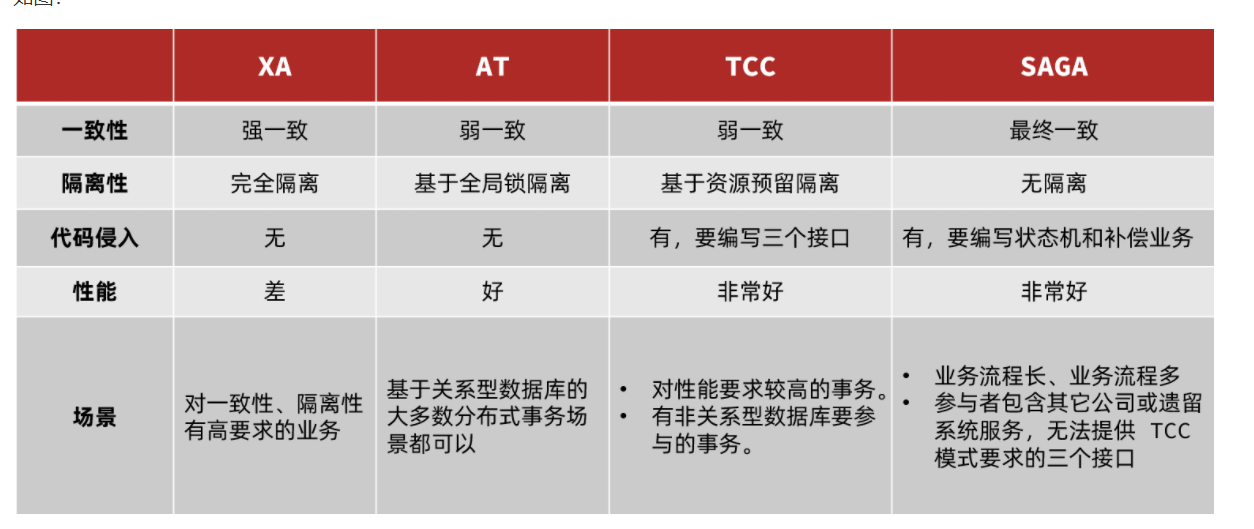
四种模式的对比
三、TC服务的高可用和异地容灾
1.模拟异地容灾的TC集群
计划启动两台seata的tc服务节点:
| 节点名称 | ip地址 | 端口号 | 集群名称 |
|---|---|---|---|
| seata | 127.0.0.1 | 8091 | SH |
| seata2 | 127.0.0.1 | 8092 | HZ |
之前我们已经启动了一台seata服务,端口是8091,集群名为SH。
现在,将seata目录复制一份,起名为seata2
修改seata2/conf/registry.conf内容如下:
registry {
# tc服务的注册中心类,这里选择nacos,也可以是eureka、zookeeper等
type = "nacos"
nacos {
# seata tc 服务注册到 nacos的服务名称,可以自定义
application = "seata-tc-server"
serverAddr = "127.0.0.1:8848"
group = "DEFAULT_GROUP"
namespace = ""
cluster = "HZ"
username = "nacos"
password = "nacos"
}
}
config {
# 读取tc服务端的配置文件的方式,这里是从nacos配置中心读取,这样如果tc是集群,可以共享配置
type = "nacos"
# 配置nacos地址等信息
nacos {
serverAddr = "127.0.0.1:8848"
namespace = ""
group = "SEATA_GROUP"
username = "nacos"
password = "nacos"
dataId = "seataServer.properties"
}
}
进入seata2/bin目录,然后运行命令:
seata-server.bat -p 8092
打开nacos控制台,查看服务列表:

点进详情查看:

2.将事务组映射配置到nacos
接下来,我们需要将tx-service-group与cluster的映射关系都配置到nacos配置中心。
新建一个配置:

配置的内容如下:
# 事务组映射关系
service.vgroupMapping.seata-demo=SH
service.enableDegrade=false
service.disableGlobalTransaction=false
# 与TC服务的通信配置
transport.type=TCP
transport.server=NIO
transport.heartbeat=true
transport.enableClientBatchSendRequest=false
transport.threadFactory.bossThreadPrefix=NettyBoss
transport.threadFactory.workerThreadPrefix=NettyServerNIOWorker
transport.threadFactory.serverExecutorThreadPrefix=NettyServerBizHandler
transport.threadFactory.shareBossWorker=false
transport.threadFactory.clientSelectorThreadPrefix=NettyClientSelector
transport.threadFactory.clientSelectorThreadSize=1
transport.threadFactory.clientWorkerThreadPrefix=NettyClientWorkerThread
transport.threadFactory.bossThreadSize=1
transport.threadFactory.workerThreadSize=default
transport.shutdown.wait=3
# RM配置
client.rm.asyncCommitBufferLimit=10000
client.rm.lock.retryInterval=10
client.rm.lock.retryTimes=30
client.rm.lock.retryPolicyBranchRollbackOnConflict=true
client.rm.reportRetryCount=5
client.rm.tableMetaCheckEnable=false
client.rm.tableMetaCheckerInterval=60000
client.rm.sqlParserType=druid
client.rm.reportSuccessEnable=false
client.rm.sagaBranchRegisterEnable=false
# TM配置
client.tm.commitRetryCount=5
client.tm.rollbackRetryCount=5
client.tm.defaultGlobalTransactionTimeout=60000
client.tm.degradeCheck=false
client.tm.degradeCheckAllowTimes=10
client.tm.degradeCheckPeriod=2000
# undo日志配置
client.undo.dataValidation=true
client.undo.logSerialization=jackson
client.undo.onlyCareUpdateColumns=true
client.undo.logTable=undo_log
client.undo.compress.enable=true
client.undo.compress.type=zip
client.undo.compress.threshold=64k
client.log.exceptionRate=100
3.微服务读取nacos配置
接下来,需要修改每一个微服务的application.yml文件,让微服务读取nacos中的client.properties文件:
seata:
config:
type: nacos
nacos:
server-addr: 127.0.0.1:8848
username: nacos
password: nacos
group: SEATA_GROUP
data-id: client.properties
- 重启微服务,现在微服务到底是连接tc的SH集群,还是tc的HZ集群,都统一由nacos的client.properties来决定了。
(第3章)分布式缓存
Redis的持久化
RDB持久化
RDB全称Redis Database Backup file(Redis数据备份文件),也被叫做Redis数据快照。简单来说就是把内存中的所有数据都记录到磁盘中。当Redis实例故障重启后,从磁盘读取快照文件,恢复数据。快照文件称为RDB文件,默认是保存在当前运行目录。
执行时机(4个、其他配置)
RDB持久化在四种情况下会执行:
- 执行save命令
- 执行bgsave命令
- Redis停机时
- 触发RDB条件时
-
1)save命令,执行后会立即进行一次RDB,其它所有命令都会被阻塞。只有在数据迁移时可能用到。

-
2)bgsave命令,这个命令执行后会开启独立进程完成RDB,主进程可以持续处理用户请求,不受影响。

-
3)停机时:Redis停机时会执行一次save命令,实现RDB持久化。
-
4)Redis内部有触发RDB的机制
# 900秒内,如果至少有1个key被修改,则执行bgsave ,
# 如果是save "" 则表示禁用RDB
save 900 1
save 300 10
save 60 10000
- 5) RDB的其它配置也可以在redis.conf文件中设置:
# 是否压缩 ,建议不开启,压缩也会消耗cpu,磁盘的话不值钱
rdbcompression yes
# RDB文件名称
dbfilename dump.rdb
# 文件保存的路径目录
dir ./
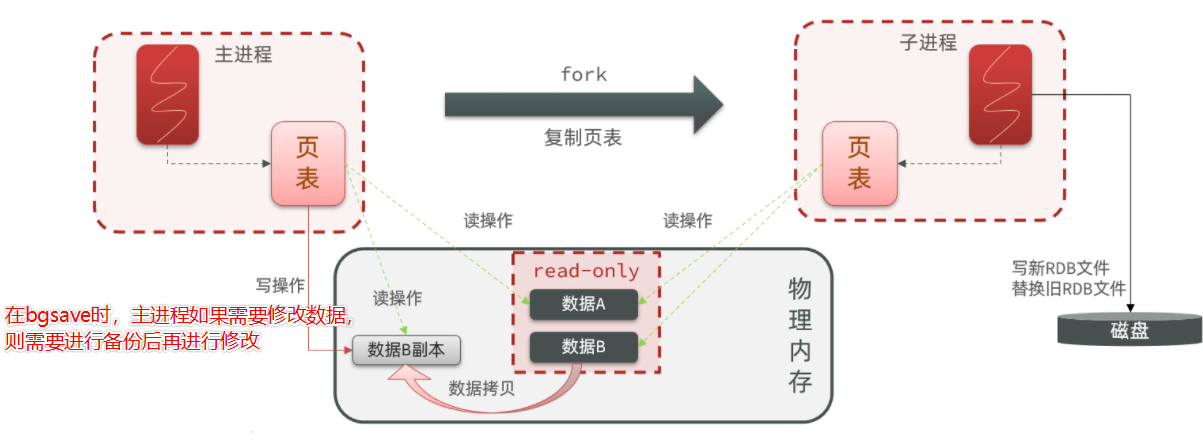
RDB原理(bgsave的过程时,主进程进行写操作,需要copy一份数据进行修改)
bgsave开始时会fork主进程得到子进程,子进程共享主进程的内存数据。完成fork后读取内存数据并写入 RDB 文件。
fork采用的是copy-on-write技术:写时复制技术
- 当主进程执行读操作时,访问共享内存;
- 当主进程执行写操作时,则会拷贝一份数据,执行写操作。
小结
RDB方式bgsave的基本流程?
- fork主进程得到一个子进程,共享内存空间
- 子进程读取内存数据并写入新的RDB文件
- 用新RDB文件替换旧的RDB文件
RDB会在什么时候执行?save 60 1000代表什么含义?
- 默认是服务停止时
- 代表60秒内至少执行1000次修改则触发RDB
RDB的缺点?
- RDB执行间隔时间长,两次RDB之间写入数据有丢失的风险
- fork子进程、压缩、写出RDB文件都比较耗时
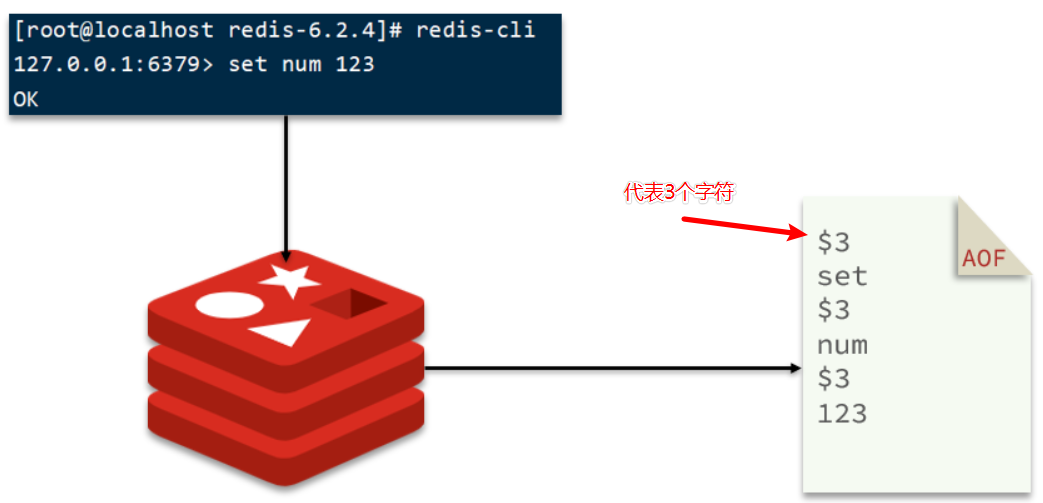
AOF持久化(甚至可以修改AOF文件)
AOF全称为Append Only File(追加文件)。Redis处理的每一个写命令都会记录在AOF文件,可以看做是命令日志文件。
AOF的配置(开启3个配置、重写2个配置)
-
重写: 当AOF文件大小达到指定需要重写的阈值时,会进行重写,重写时会把一些重复的写给进行修改
-
例如: 3个命令set num 1 , set num 2 , set num 4 ,最终直接重写为 set num 4(但是会进行编码,看不懂的)
-
开启、关闭等配置
# 是否开启AOF功能,默认是no
appendonly yes
# AOF文件的名称
appendfilename "appendonly.aof"
- 三种策略对比
# 表示每执行一次写命令,立即记录到AOF文件
appendfsync always
# 写命令执行完先放入AOF缓冲区,然后表示每隔1秒将缓冲区数据写到AOF文件,是默认方案
appendfsync everysec
# 写命令执行完先放入AOF缓冲区,由操作系统决定何时将缓冲区内容写回磁盘
appendfsync no
- 文件重写的配置
# AOF文件比上次文件 增长超过多少百分比则触发重写
auto-aof-rewrite-percentage 100
# AOF文件体积最小多大以上才触发重写
auto-aof-rewrite-min-size 64mb
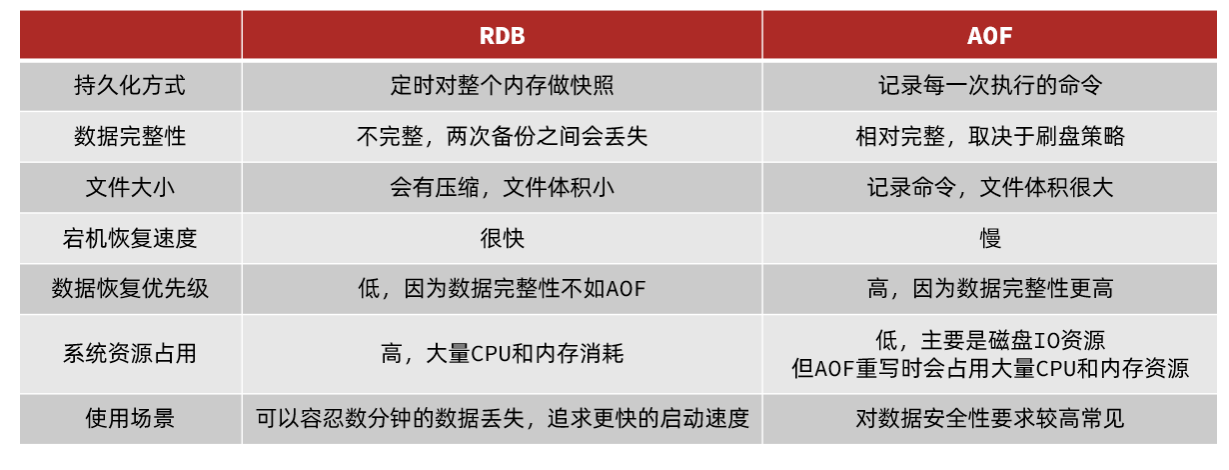
AOF与RDB的对比(持久化方式、数据完整性、文件大小、宕机恢复速度、数据恢复优先级、系统资源占用、使用场景)
- RDB和AOF各有自己的优缺点,如果对数据安全性要求较高,在实际开发中往往会结合两者来使用。
Redis主从集群搭建
下载和安装单台redis
-
下载redis,下载地址
-
下载后的文件为.tar.gz结尾,将其解压到linux的任意目录,例如/opt/redis中
-
执行如下命令
# 安装GCC
yum install -y gcc tcl
# 解压缩
tar -xvf redis-6.2.4.tar.gz
# 解压后进入目录
cd redis-6.2.4
# 运行编译命令
make && make install
# 修改该路径下的配置文件
bind 0.0.0.0
protected-mode no
databases 1
# 启动
redis-server ./redis.conf
redis-cli shutdown
- 安装成功后,会把一些redis的常用命令,放在/local/usr/bin目录下,因此可以直接在任意目录使用这些指令
搭建主从集群
-
在/rmp/redisTest 目录下 创建3个文件夹 7001、7002、7003
mkdir -p 7001 7002 7003 -
复制一份原有的redis文件到/tmp/redisTest目录下
cp /opt/redis-6.2.1/redis.conf /tmp/redisTest/ -
进入到/tmp/redisTest目录下
cd /tmp/redisTest -
在7001、7002、7003的3个文件夹中,分别创建redis7001.conf、redis7002.conf、redis7003.conf(这里先在7001中创建了),另外2个就只需要批量替换下7001为 7002或 7003
# 引入公共的redis配置文件
include /tmp/redisTest/redis.conf
# 网络相关
bind 0.0.0.0
protected-mode yes
port 7001
pidfile /tmp/redisTest/7001/redis7001.pid
# 通用配置
daemonize yes
loglevel notice
logfile /tmp/redisTest/7001/redis7001.log
databases 1
# RDB & AOF
dbfilename 7001dump.rdb
appendonly no
dir /tmp/redisTest/7001/
# redis实例的声明 IP,每一个配置文件都需要配置
replica-announce-ip 192.168.22.100
- 将配置文件复制到另外2个文件目录下
cp /tmp/redisTest/7001/redis7001.conf /tmp/redisTest/7002/redis7002.conf
cp /tmp/redisTest/7001/redis7001.conf /tmp/redisTest/7003/redis7003.conf
- 启动3台redis服务
redis-server ./7001/redis7001.conf
redis-server ./7002/redis7002.conf
redis-server ./7003/redis7003.conf

- 创建3个终端,分别连接到3台不同的redis服务
redis-cli -p 7001
redis-cli -p 7002
redis-cli -p 7003
主从集群的常用命令(永久生效需要修改配置文件 新增命令:replicaof)
-
使从节点认主
slaveof 192.168.22.100 7001- 配置文件方式:
slaveof <masterip> <masterport>
- 配置文件方式:
-
查看当前主从状态
info replication -
将自己升级为主节点
slaveof no one -
redis5.0新增命令replicaof,与slaveof作用一致
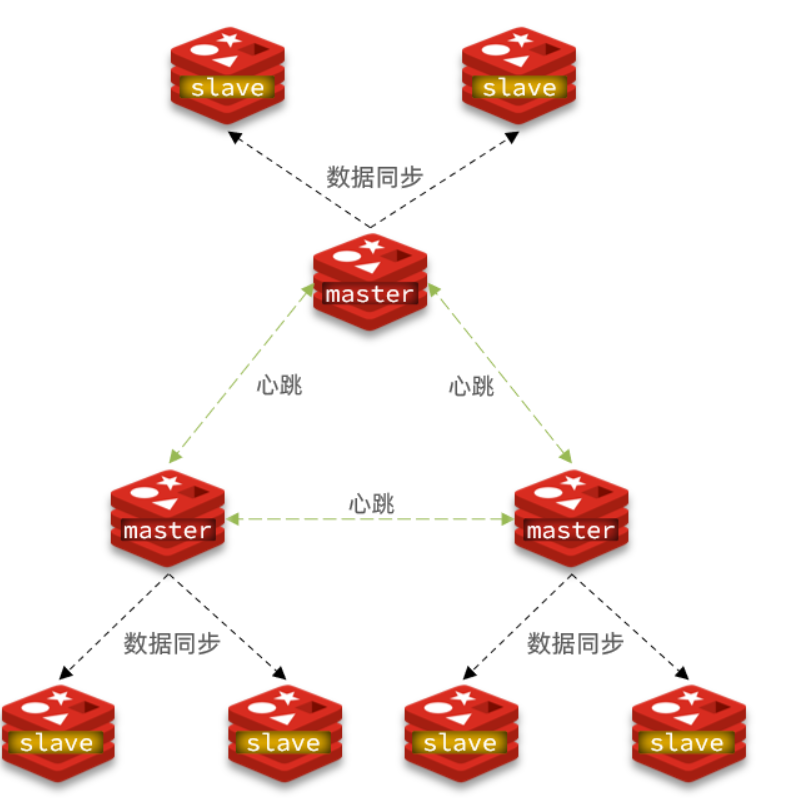
主从同步原理

-
slave节点请求增量同步
-
master节点判断replid,发现不一致,拒绝增量同步
-
master将完整内存数据生成RDB,发送RDB到slave
-
slave清空本地数据,加载master的RDB
-
master将RDB期间的命令记录在repl_baklog,并持续将log中的命令发送给slave
-
slave执行接收到的命令,保持与master之间的同步
增量同步repl_backlog
该日志文件类似于mysql的binlog主从复制时的效果。
主从同步优化(无磁盘复制)
-
在master中配置repl-diskless-sync yes启用无磁盘复制,避免全量同步时的磁盘IO。
-
Redis单节点上的内存占用不要太大,减少RDB导致的过多磁盘IO
-
适当提高repl_baklog的大小,发现slave宕机时尽快实现故障恢复,尽可能避免全量同步
-
限制一个master上的slave节点数量,如果实在是太多slave,则可以采用主-从-从链式结构,减少master压力
搭建哨兵集群
-
在redisTest目录下创建3个文件夹,分别为s1、s2、s3
mkdir -p s1 s2 s3 -
在3个目录中都创建一个sentinel.conf文件,端口可以分别为 27001 27002 27003,修改他们的端口和文件目录
port 27001
# sentinel的ip地址
sentinel announce-ip 192.168.22.100
# 标志当前主从集群的主机, 后面的2代表:有2名哨兵表示主机挂了时,那么就同意重新选主
sentinel monitor mymaster 192.168.22.100 7001 2
# 主机宕机的处理时间
sentinel down-after-milliseconds mymaster 5000
# 故障转移超时时间
sentinel failover-timeout mymaster 60000
# sentinel生成的文件目录
dir "/tmp/redisTest/s1"
- 运行3个哨兵
redis-sentinel /tmp/redisTest/s1/sentinel.conf
redis-sentinel /tmp/redisTest/s2/sentinel.conf
redis-sentinel /tmp/redisTest/s3/sentinel.conf
- 接下来就已经完成了哨兵集群的搭建了
哨兵故障恢复原理(包含选举规则)
-
首先会判断slave节点与master节点断开时间长短,如果超过指定值(down-after-milliseconds * 10)则会排除该slave节点
-
然后判断slave节点的slave-priority值,越小优先级越高,如果是0则永不参与选举
-
如果slave-prority一样,则判断slave节点的offset值,越大说明数据越新,优先级越高
-
最后是判断slave节点的运行id大小,越小优先级越高。
处理流程
-
sentinel给备选的slave1节点发送slaveof no one命令,让该节点成为master
-
sentinel给所有其它slave发送slaveof 192.168.22.100 7002 命令,让这些slave成为新master的从节点,开始从新的master上同步数据。
- 并且还会修改宕机的服务的配置文件
slaveof 192.168.22.100 7002,使其上线就变成从机
- 并且还会修改宕机的服务的配置文件
-
最后,sentinel将故障节点标记为slave,当故障节点恢复后会自动成为新的master的slave节点
集群监控原理
Sentinel基于心跳机制监测服务状态,每隔1秒向集群的每个实例发送ping命令:
•主观下线:如果某sentinel节点发现某实例未在规定时间响应,则认为该实例主观下线。
•客观下线:若超过指定数量(quorum)的sentinel都认为该实例主观下线,则该实例客观下线。quorum值最好超过Sentinel实例数量的一半。
搭建Redis的分片集群(不需要哨兵)
分片集群能够解决的问题、特点、架构图
-
主从集群 + 哨兵集群 虽然可以解决高可用、高并发读的问题,但是还有如下2个问题无法解决
-
海量数据存储问题
-
高并发写问题
-
-
分片集群的架构图如下
分片集群的特点
-
集群中有多个master,每个master保存不同数据
-
每个master都可以有多个slave节点
-
master之间通过ping监测彼此健康状态
-
客户端请求可以访问集群任意节点,最终都会被转发到正确节点(去中心化集群)
搭建一个分片集群
- 本文中将会模拟如下的一个集群信息
| IP | PORT | 角色 |
|---|---|---|
| 192.168.150.101 | 7001 | master |
| 192.168.150.101 | 7002 | master |
| 192.168.150.101 | 7003 | master |
| 192.168.150.101 | 8001 | slave |
| 192.168.150.101 | 8002 | slave |
| 192.168.150.101 | 8003 | slave |
进入/tmp/redisTest目录下,创建如下6个目录
mkdir -p 7001 7002 7003 8001 8002 8003
在/tmp/redisTest目录下创建一个redis.conf文件
port 6379
# 开启集群功能
cluster-enabled yes
# 集群的配置文件名称,不需要我们创建,由redis自己维护
cluster-config-file /tmp/redisTest/6379/nodes.conf
# 节点心跳失败的超时时间
cluster-node-timeout 5000
# 持久化文件存放目录
dir /tmp/redisTest/6379
# 绑定地址
bind 0.0.0.0
# 让redis后台运行
daemonize yes
# 注册的实例ip
replica-announce-ip 192.168.150.101
# 保护模式
protected-mode no
# 数据库数量
databases 1
# 日志
logfile /tmp/redisTest/6379/run.log
将这个文件拷贝到每一个目录下
# 进入/tmp目录
cd /tmp
# 执行拷贝
echo 7001 7002 7003 8001 8002 8003 | xargs -t -n 1 cp redis.conf
修改每个目录下的redis.conf,将其中的6379修改为与所在目录一致
# 进入/tmp目录
cd /tmp
# 修改配置文件
printf '%s\n' 7001 7002 7003 8001 8002 8003 | xargs -I{} -t sed -i 's/6379/{}/g' {}/redis.conf
一键启动所有服务
# 进入/tmp目录
cd /tmp
# 一键启动所有服务
printf '%s\n' 7001 7002 7003 8001 8002 8003 | xargs -I{} -t redis-server {}/redis.conf
# 查看服务状态
ps -ef | grep redis
如果需要关闭所有进程,则执行如下命令
# 方式一
ps -ef | grep redis | awk '{print $2}' | xargs kill
# 方式二
printf '%s\n' 7001 7002 7003 8001 8002 8003 | xargs -I{} -t redis-cli -p {} shutdown
创建集群
redis5之前的版本
- Redis5.0之前集群命令都是用redis安装包下的src/redis-trib.rb来实现的。因为redis-trib.rb是有ruby语言编写的所以需要安装ruby环境。
# 安装依赖
yum -y install zlib ruby rubygems
gem install redis
- 然后通过命令来管理集群
# 进入redis的src目录,你安装在哪就进入哪
cd /opt/redis-6.2.4/src
# 创建集群
./redis-trib.rb create --replicas 1 192.168.22.100:7001 192.168.22.100:7002 192.168.22.100:7003 192.168.22.100:8001 192.168.22.100:8002 192.168.22.100:8003
redis5之后的版本
- redis5之后的版本,将集群管理已经集成到了redis-cli中,可以通过如下命令创建分片集群
redis-cli --cluster create --cluster-replicas 1 192.168.22.100:7001 192.168.22.100:7002 192.168.22.100:7003 192.168.22.100:8001 192.168.22.100:8002 192.168.22.100:8003
- 命令说明
-
redis-cli --cluster或者./redis-trib.rb:代表集群操作命令 -
create:代表是创建集群 -
--replicas 1或者--cluster-replicas 1:指定集群中每个master的副本个数为1,此时节点总数 ÷ (replicas + 1)得到的就是master的数量。因此节点列表中的前n个就是master,其它节点都是slave节点,随机分配到不同master
-
分片集群的常用命令
-
查看集群状态
redis-cli -p 7001 cluster nodes -
连接集群时候:
redis-cli -c -p 7001,需要带上 -c参数,表示以集群方式连接
散列插槽
Redis会把每一个master节点映射到0~16383共16384个插槽(hash slot)上,查看集群信息时就能看到:
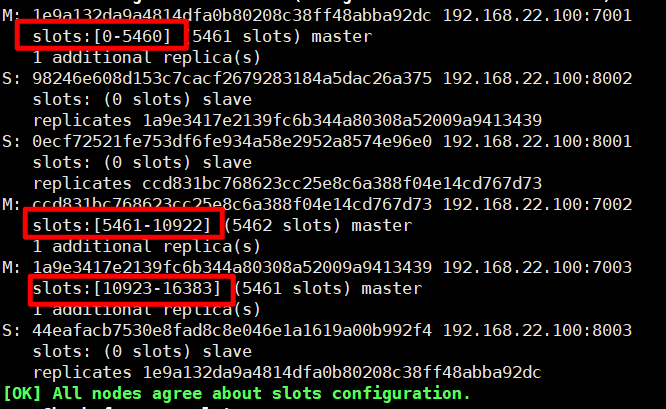
Redis如何判断某个key应该在哪个实例?
- 将16384个插槽分配到不同的实例
- 根据key的有效部分计算哈希值,对16384取余
- 余数作为插槽,寻找插槽所在实例即可
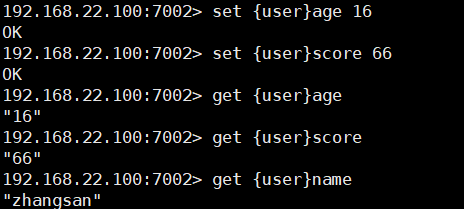
如何将同一类数据固定的保存在同一个Redis实例?
- 这一类数据使用相同的有效部分,例如key都以{typeId}为前缀
使同一组数据都放在同一台服务器上
-
存储数据的时候带上组
-
例如:
set {user}name zhangsan
集群伸缩
添加一个新的节点
创建一个新的redis示例
-
首先进入/tmp/redisTest目录下
-
创建7004文件夹
mkdir 7004 -
复制一个配置文件到7004文件夹下
cp redis.conf 7004/ -
修改配置文件,将6379都替换成7004
sed /s/6379/7004/g 7004/redis.conf -
启动
redis-server 7004/redis.conf
添加新节点到redis
- 执行如下命令
redis-cli --cluster add-node 192.168.22.100:7004 192.168.22.100:7001
- 查看集群状态(发现新节点没有任何的插槽)
redis-cli -p 7001 cluster nodes
转移插槽
-
例如这里将 7001节点上的0~2999共计3000个插槽转移给7004新节点
-
执行如下命令
redis-cli --cluster reshard 192.168.22.100:7001
-
接下来会询问需要移动多少个插槽,输入3000

-
询问由谁来接收这些插槽,输入 7004节点的ID,可以通过
redis-cli -p 7001 cluster nodes获取
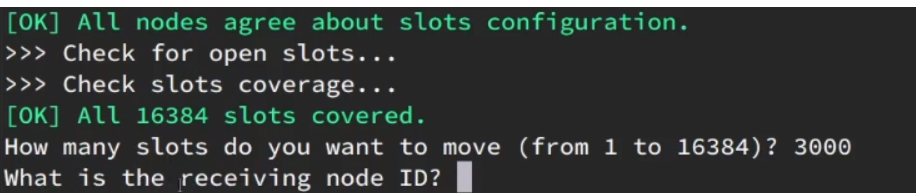
-
再询问插槽是从哪个节点来获取的,此时输入7001节点的ID

(1)all,代表全部,也就是从3个节点各转移一部分
(2)目标的id: 指定具体从哪个节点上转移这3000个节点
(3)done:没有了 -
再次输入done回车,告知没有了
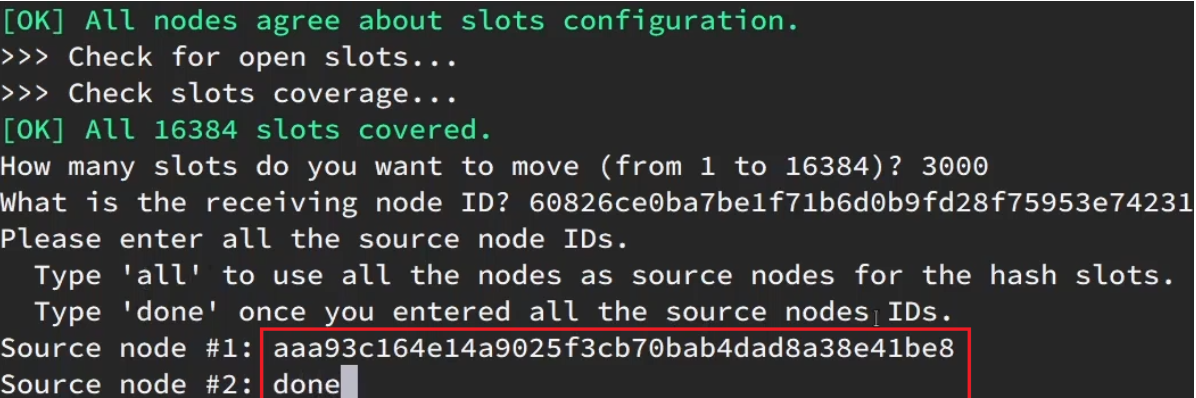
-
这样插槽就转移完毕了
故障转移
自动故障转移
-
跟sentinel哨兵模式差不多
-
节点之间会相互通过ping来检测心跳,如果出现宕机,会将其salve从机转换为主机。
-
当之前的主机再次上线时,就变成从机了
手动故障转移(实现无感知的数据迁移)
- 利用cluster failover命令可以手动让集群中的某个master宕机,切换到执行cluster failover命令的这个slave节点,实现无感知的数据迁移。

-
cluster failvoer命令可以指定3种模式
- 缺省:默认的流程,如图1~6歩
- force:省略了对offset的一致性校验
- takeover:直接执行第5歩,忽略数据一致性、忽略master状态和其它master的意见
-
使用步骤
1)利用redis-cli连接7002这个节点
2)执行cluster failover命令
使用SpringBoot整合redis
整合哨兵集群(配置读写策略)
- 引入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
- 修改配置
spring:
redis:
sentinel:
master: mymaster
nodes:
- 192.168.22.100:27001
- 192.168.22.100:27002
- 192.168.22.100:27003
- 配置读写分离策略
@Bean
public LettuceClientConfigurationBuilderCustomizer clientConfigurationBuilderCustomizer(){
return clientConfigurationBuilder -> clientConfigurationBuilder.readFrom(ReadFrom.REPLICA_PREFERRED);
}
- MASTER:从主节点读取
- MASTER_PREFERRED:优先从master节点读取,master不可用才读取replica
- REPLICA:从slave(replica)节点读取
- REPLICA _PREFERRED:优先从slave(replica)节点读取,所有的slave都不可用才读取master
整合分片集群
spring:
redis:
cluster:
nodes:
- 192.168.22.100:7001
- 192.168.22.100:7002
- 192.168.22.100:7003
- 192.168.22.100:8001
- 192.168.22.100:8002
- 192.168.22.100:8003
(第4章)多级缓存
多级缓存的大致架构图
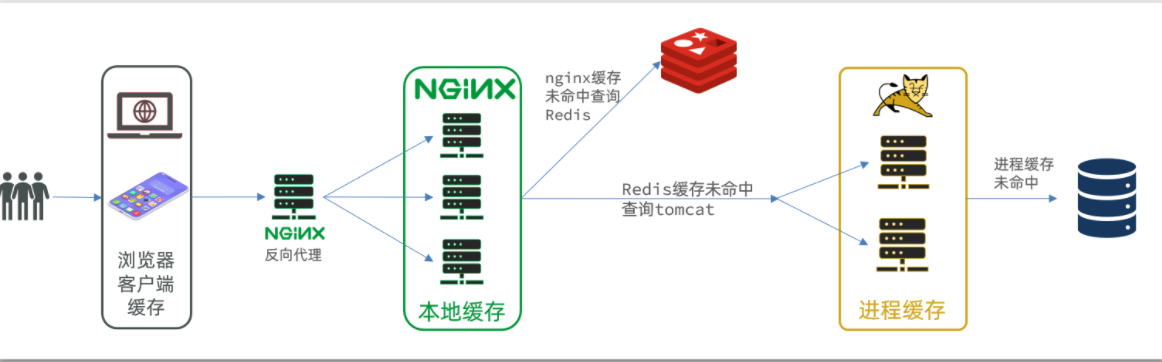
JVM进程缓存
缓存的分类及其优缺点
缓存一共分为两类
-
分布式缓存
- 优点:存储容量大、可靠性好、可以在集群之间共享
- 缺点:访问缓存有网络网络开销
- 场景:缓存数据量大、可靠性要求较高、需要在集群间共享
-
进程本地缓存
- 优点: 读取本地内存速度更快并且没有网络开销
- 缺点:存储容量有限,可靠性较低,不能共享
- 场景:性能要求较高,缓存数据量小
Caffeine是什么?
Caffeine是基于java8所开发的,性能相比于其他进程本地缓存遥遥领先。
Caffeine的基本使用(新增、获取、驱逐策略)
- 引入如下依赖
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
</dependency>
- 通过Caffeine创建缓存对象
1、普通创建
Cache<String, String> cache = Caffeine.newBuilder().build();
2、设置过期时间
Cache<String, String> cache = Caffeine.newBuilder()
.expireAfterWrite(10, TimeUnit.SECONDS)
.build();
3、 设置缓存最大可以存储的数量
Cache<String, String> cache = Caffeine.newBuilder()
// 设置缓存的中的数量上限为1, 注意: 不是立刻清理掉缓存的
.maximumSize(1)
.build();
- Caffeine缓存的获取
// 1、通过get的方式
String str = cache.get("k2", key -> {
System.out.println("如果通过k1这个key找不到的话,我就成为了返回结果,这个key其实就是k1");
System.out.println("这里可以去查询数据库了,因为从缓存中查不到~~");
return "没查到,该查数据库了";
});
// 2、通过getIfPresent的方式,未查询到则返回null
String k1 = cache.getIfPresent("k1");
-
缓存的驱逐策略
- 基于数量
- 基于时间
-
注意:在默认情况下,当一个缓存元素过期的时候,Caffeine不会自动立即将其清理和驱逐。而是在一次读或写操作后,或者在空闲时间完成对失效数据的驱逐。
实现JVM进程缓存
- 添加配置类
@Configuration
public class CaffeineConfig {
@Bean
public Cache<Long, Item> itemCache(){
return Caffeine.newBuilder()
.initialCapacity(100)
.maximumSize(10_000)
.build();
}
@Bean
public Cache<Long, ItemStock> stockCache(){
return Caffeine.newBuilder()
.initialCapacity(100)
.maximumSize(10_000)
.build();
}
}
- 通过缓存获取(先从缓存获取,如果获取不到,则访问数据库)
@Autowired
private Cache<Long, Item> itemCache;
@Autowired
private Cache<Long, ItemStock> stockCache;
@GetMapping("/{id}")
public Item findById(@PathVariable("id") Long id){
return itemCache.get(id, key -> {
return itemService.query()
.ne("status", 3)
.eq("id", id)
.one();
});
}
@GetMapping("/stock/{id}")
public ItemStock findStockById(@PathVariable("id") Long id){
return stockCache.get(id, key -> stockService.getById(id));
}
Lua语法入门(可以在OpenResty中使用)
lua的数据类型(6个)
-
nil 表示一个无效值,在条件表达式当中表示 false
-
number 代表数值
-
boolean 布尔值
-
string 字符串
-
table 可以代表数组,也可以代表map, 数组: [1,2,3] ,map:
-
function 函数类型
变量和循环
定义变量及使用(number、boolean、string、table[arr|map]、function)
-- 定义字符串
local name = '张三';
print(name)
-- 字符串拼接
local namePrefix = '姓名前缀:';
print(namePrefix .. name);
-- 定义number
local age = 18;
print(age)
-- 定义boolean
local flag = true;
print(flag)
-- 定义function
local num = function()
return 1 + 2
end
-- 调用函数
local result = num();
print(result)
-- 定义table类型,数组
local arr = {1,2,4};
print(arr[1] .. arr[2] .. arr[3])
-- 定义table类型,map
local map = {name='王五',age='81'};
print(map.name .. map.age)
使用循环(pairs)遍历数组和table
-- 遍历数组
local arr = {1,2,4};
for index,value in pairs(arr) do
print(index .. ' ' .. value)
end
-- 遍历集合
local map = {name='张三',age=88}
for key,value in pairs(map) do
print(key .. ' ' .. value)
end
条件控制、函数、条件控制的操作符
- 3个操作符: and 、or 、not
-- 条件控制
local flag = 1;
if (flag == 1)
then
print('flag结果为1')
else
print('flag的结果不为1')
end
-- 测试not操作符
if(not 1==1) then
print('你好')
else
print('不好')
end
-- 函数
local num = function(a, b)
return a + b;
end
print(num(10,40))
实现多级缓存
- 多级缓存的实现离不开Nginx的编程,而Nginx的变成离不开OpenResty
使用OpenResty实现Nginx本地线程缓存(架构图中的nginx集群)
使用Linux安装OpenResty
- 安装OpenResty及OPM管理工具
- 安装开发库
yum install -y pcre-devel openssl-devel gcc --skip-broken
- 安装OpenResty仓库
yum-config-manager --add-repo https://openresty.org/package/centos/openresty.repo
- 如果命令yum-config-manager不存在,则运行,然后再重新安装OpenResty仓库
yum install -y yum-utils
- 安装OpenResty
yum install -y openresty
- 安装OPM工具(opm是OpenResty的一个管理工具)可以帮助我们安装一个第三方的Lua模块
yum install -y openresty-opm
- 配置环境变量
vi /etc/profile
export NGINX_HOME=/usr/local/openresty/nginx
export PATH=${NGINX_HOME}/sbin:$PATH
source /etc/profile
- 启动和停止
# 启动nginx
nginx
# 重新加载配置
nginx -s reload
# 停止
nginx -s stop
- 修改/usr/local/openresty/nginx/conf/nginx.conf配置文件,把注释删掉
#user nobody;
worker_processes 1;
error_log logs/error.log;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
server {
listen 8081;
server_name localhost;
location / {
root html;
index index.html index.htm;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
}
OpenResty监听请求完成对Tomcat的负载均衡获取数据
修改openresty的配置文件,再server模块下添加如下代码,监听请求
location /api/item {
# 默认的响应类型
default_type application/json;
# 响应结果由lua/item.lua文件来决定
content_by_lua_file lua/item.lua;
}
修改OpenResty的配置文件/usr/local/openresty/nginx/conf/nginx.conf,添加模块
- 在http模块下添加如下代码
#lua 模块
lua_package_path "/usr/local/openresty/lualib/?.lua;;";
#c模块
lua_package_cpath "/usr/local/openresty/lualib/?.so;;";
编写item.lua ,该文件的目录为/usr/local/openresty/nginx/lua/item.lua,先返回假数据
ngx.say('{"id":10001,"name":"SALSA AIR","title":"RIMOWA 21寸托运箱拉杆箱 SALSA AIR系列果绿色 820.70.36.4","price":17900,"image":"https://m.360buyimg.com/mobilecms/s720x720_jfs/t6934/364/1195375010/84676/e9f2c55f/597ece38N0ddcbc77.jpg!q70.jpg.webp","category":"拉杆箱","brand":"RIMOWA","spec":"","status":1,"createTime":"2019-04-30T16:00:00.000+00:00","updateTime":"2019-04-30T16:00:00.000+00:00","stock":2999,"sold":31290}')
OpenResty接收前端发送的参数

修改/usr/local/openresty/nginx/conf/nginx.conf文件,接收参数
# 以正则匹配的方式来获取最后的参数(由于本文中的测试,请求就是一串数字)
location ~ /api/item/(\d+) {
# 默认的响应类型
default_type application/json;
# 响应结果由lua/item.lua文件来决定
content_by_lua_file lua/item.lua;
}
实现对于Tomcat的数据请求
修改OpenResty的配置文件,反向代理到Tomcat中(注意这里的负载均衡算法)
- 因为nginx中的请求会被自身所监听,因此发送http请求的时候,就会被自己监听到,然后再反向代理到Tomcat服务器上。
- 注意这个在http模块下
upstream tomcat-cluster {
hash $request_uri;
server 192.168.22.1:8081;
server 192.168.22.1:8082;
}
- 这个在http>server模块下
location /item {
proxy_pass http://tomcat-cluster;
}
封装一个发送http请求的工具类,放在/usr/local/openresty/lualib目录下
- 为什么放在这个目录下? 还记得我们在之前引入了吗
使用nginx发送http请求
-- 封装函数,发送http请求,并解析响应
local function read_http(path, params)
local resp = ngx.location.capture(path,{
method = ngx.HTTP_GET,
args = params,
})
if not resp then
-- 记录错误信息,返回404
ngx.log(ngx.ERR, "http请求查询失败, path: ", path , ", args: ", args)
ngx.exit(404)
end
return resp.body
end
-- 将方法导出
local _M = {
read_http = read_http
}
return _M
编写item.lua脚本,文件地址在/usr/local/openresty/nginx/lua/item.lua
-- 导入common函数库
local common = require('common')
local read_http = common.read_http
-- 导入cjson库
local cjson = require('cjson')
-- 获取路径参数
local id = ngx.var[1]
-- 根据id查询商品
local itemJSON = read_http("/item/".. id, nil)
-- 根据id查询商品库存
local itemStockJSON = read_http("/item/stock/".. id, nil)
-- JSON转化为lua的table
local item = cjson.decode(itemJSON)
local stock = cjson.decode(itemStockJSON)
-- 组合数据
item.stock = stock.stock
item.sold = stock.sold
-- 把item序列化为json 返回结果
ngx.say(cjson.encode(item))
Redis缓存预热
- 利用docker安装一个redis
docker run --name redis -p 6379:6379 -d redis redis-server --appendonly yes
- 在Tomcat中引入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
- 修改配置文件
spring:
redis:
host: 192.168.22.100
- 新建一个配置类,实现InitializingBean接口(当Bean初始化完毕时会调用实现的方法)
@Component
public class RedisCacheWarmUp implements InitializingBean {
@Autowired
private StringRedisTemplate redisTemplate;
@Autowired
private IItemService itemService;
@Autowired
private IItemStockService stockService;
private static final ObjectMapper MAPPER = new ObjectMapper();
@Override
public void afterPropertiesSet() throws Exception {
// 初始化缓存
// 1.查询商品信息
List<Item> itemList = itemService.list();
// 2.放入缓存
for (Item item : itemList) {
// 2.1.item序列化为JSON
String json = MAPPER.writeValueAsString(item);
// 2.2.存入redis
redisTemplate.opsForValue().set("item:id:" + item.getId(), json);
}
// 3.查询商品库存信息
List<ItemStock> stockList = stockService.list();
// 4.放入缓存
for (ItemStock stock : stockList) {
// 2.1.item序列化为JSON
String json = MAPPER.writeValueAsString(stock);
// 2.2.存入redis
redisTemplate.opsForValue().set("item:stock:id:" + stock.getId(), json);
}
}
}
OpenResty完成对Redis数据的查询
修改/usr/local/openresty/lualib/common.lua,封装访问redis的方法
-- 导入redis
local redis = require('resty.redis')
-- 初始化redis
local red = redis:new()
red:set_timeouts(1000, 1000, 1000)
-- 关闭redis连接的工具方法,其实是放入连接池
local function close_redis(red)
local pool_max_idle_time = 10000 -- 连接的空闲时间,单位是毫秒
local pool_size = 100 --连接池大小
local ok, err = red:set_keepalive(pool_max_idle_time, pool_size)
if not ok then
ngx.log(ngx.ERR, "放入redis连接池失败: ", err)
end
end
-- 查询redis的方法 ip和port是redis地址,key是查询的key
local function read_redis(ip, port, key)
-- 获取一个连接
local ok, err = red:connect(ip, port)
if not ok then
ngx.log(ngx.ERR, "连接redis失败 : ", err)
return nil
end
-- 查询redis
local resp, err = red:get(key)
-- 查询失败处理
if not resp then
ngx.log(ngx.ERR, "查询Redis失败: ", err, ", key = " , key)
end
--得到的数据为空处理
if resp == ngx.null then
resp = nil
ngx.log(ngx.ERR, "查询Redis数据为空, key = ", key)
end
close_redis(red)
return resp
end
-- 封装函数,发送http请求,并解析响应
local function read_http(path, params)
local resp = ngx.location.capture(path,{
method = ngx.HTTP_GET,
args = params,
})
if not resp then
-- 记录错误信息,返回404
ngx.log(ngx.ERR, "http请求查询失败, path: ", path , ", args: ", args)
ngx.exit(404)
end
return resp.body
end
-- 将方法导出
local _M = {
read_http = read_http,
read_redis = read_redis
}
return _M
修改/usr/local/openresty/nginx/lua/item.lua,访问redis缓存
-- 导入common函数库
local common = require('common')
local read_http = common.read_http
local read_redis = common.read_redis
-- 导入cjson库
local cjson = require('cjson')
-- 封装查询函数
function read_data(key, path, params)
-- 查询本地缓存
local val = read_redis("127.0.0.1", 6379, key)
-- 判断查询结果
if not val then
ngx.log(ngx.ERR, "redis查询失败,尝试查询http, key: ", key)
-- redis查询失败,去查询http
val = read_http(path, params)
end
-- 返回数据
return val
end
-- 获取路径参数
local id = ngx.var[1]
-- 查询商品信息
local itemJSON = read_data("item:id:" .. id, "/item/" .. id, nil)
-- 查询库存信息
local stockJSON = read_data("item:stock:id:" .. id, "/item/stock/" .. id, nil)
-- JSON转化为lua的table
local item = cjson.decode(itemJSON)
local stock = cjson.decode(stockJSON)
-- 组合数据
item.stock = stock.stock
item.sold = stock.sold
-- 把item序列化为json 返回结果
ngx.say(cjson.encode(item))
OpenResty本地缓存
- 开启共享字典,在nginx.conf的http下添加配置
# 共享字典,也就是本地缓存,名称叫做:item_cache,大小150m
lua_shared_dict item_cache 150m;
- 操作共享字典
-- 获取本地缓存对象
local item_cache = ngx.shared.item_cache
-- 存储, 指定key、value、过期时间,单位s,默认为0代表永不过期
item_cache:set('key', 'value', 1000)
-- 读取
local val = item_cache:get('key')
- 实现本地缓存(别忘了read_data方法需要传入一个expire)
-- 导入共享词典,本地缓存
local item_cache = ngx.shared.item_cache
-- 封装查询函数
function read_data(key, expire, path, params)
-- 查询本地缓存
local val = item_cache:get(key)
if not val then
ngx.log(ngx.ERR, "本地缓存查询失败,尝试查询Redis, key: ", key)
-- 查询redis
val = read_redis("127.0.0.1", 6379, key)
-- 判断查询结果
if not val then
ngx.log(ngx.ERR, "redis查询失败,尝试查询http, key: ", key)
-- redis查询失败,去查询http
val = read_http(path, params)
end
end
-- 查询成功,把数据写入本地缓存
item_cache:set(key, val, expire)
-- 返回数据
return val
end
缓存同步
缓存同步的3种方式
缓存数据同步的常见方式有三种:
设置有效期:给缓存设置有效期,到期后自动删除。再次查询时更新
- 优势:简单、方便
- 缺点:时效性差,缓存过期之前可能不一致
- 场景:更新频率较低,时效性要求低的业务
同步双写:在修改数据库的同时,直接修改缓存
- 优势:时效性强,缓存与数据库强一致
- 缺点:有代码侵入,耦合度高;
- 场景:对一致性、时效性要求较高的缓存数据
异步通知:修改数据库时发送事件通知,相关服务监听到通知后修改缓存数据
- 优势:低耦合,可以同时通知多个缓存服务
- 缺点:时效性一般,可能存在中间不一致状态
- 场景:时效性要求一般,有多个服务需要同步
基于Canal完成异步通知的架构图
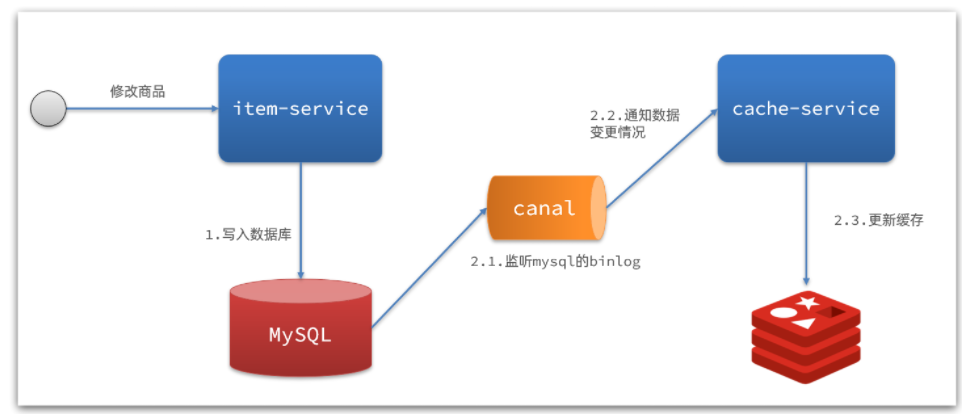
搭建Canal来监听Mysql的binlog完成对数据的异步通知
使用MySql修改配置文件开启biglog功能,并且创建一个账户供canal使用
- 进入/emp目录下,创建一个mysql文件夹,然后进入该文件夹
docker run
-p 3306:3306 \
--name mysql \
-v $PWD/conf:/etc/mysql/conf.d \
-v $PWD/logs:/logs \
-v $PWD/data:/var/lib/mysql \
-e MYSQL_ROOT_PASSWORD=123 \
--privileged -d \
mysql:5.7.25
- 修改配置文件
[mysqld]
skip-name-resolve
character_set_server=utf8
datadir=/var/lib/mysql
server-id=1000
log-bin=/var/lib/mysql/mysql-bin
server-id=1
binlog-do-db=db_cache
- 开启主从功能
create user canal@'%' IDENTIFIED by 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT,SUPER ON *.* TO 'canal'@'%' identified by 'canal';
FLUSH PRIVILEGES;
- 重启mysql后测试是否开启成功
docker restart mysql;
show master status;
使用docker安装canal(Mysql和Canal要在同一个网络)
-
下载canal
docker pull canal/canal-server:v1.1.5 -
使用docker创建一个网络,并使mysql连接该网络
docker network create cache
docker network connect cache mysql
- 创建canal容器
docker run -p 11111:11111 --name canal \
-e canal.destinations=canalCluter1 \
-e canal.instance.master.address=mysql:3306 \
-e canal.instance.dbUsername=canal \
-e canal.instance.dbPassword=canal \
-e canal.instance.connectionCharset=UTF-8 \
-e canal.instance.tsdb.enable=true \
-e canal.instance.gtidon=false \
-e canal.instance.filter.regex=db_cache\\..* \
--network cache \
-d canal/canal-server:v1.1.5
- canal的参数解释
- destinations :代表canal的集群名称,java连接canal要用
- master.address:需要连接的mysql的ip和端口,由于在docker当中,同一个网络中的容器可以通过服务名访问
- dbUsername: 连接数据库的用户名
- dbPassword: 连接数据库的密码
- regex: 需要监听的表名称,有如下正则语法
mysql 数据解析关注的表,Perl正则表达式.
多个正则之间以逗号(,)分隔,转义符需要双斜杠(\\)
常见例子:
1. 所有表:.* or .*\\..*
2. canal schema下所有表: canal\\..*
3. canal下的以canal打头的表:canal\\.canal.*
4. canal schema下的一张表:canal.test1
5. 多个规则组合使用然后以逗号隔开:canal\\..*,mysql.test1,mysql.test2
使用java来连接canal完成缓存的异步通知写入
- 引入依赖
<dependency>
<groupId>top.javatool</groupId>
<artifactId>canal-spring-boot-starter</artifactId>
<version>1.2.1-RELEASE</version>
</dependency>
修改配置文件
canal:
destination: canalCluter1 # canal的集群名字,要与安装canal时设置的名称一致
server: 192.168.22.100:11111
修改实体类,主要有如下3个注解
- @Id 用于标识实体类对应数据库的Id
- @Cloumn 用于标识实体类对应数据库的字段名,一般不用写,支持驼峰转换的
- @Transient 标识当前字段不是实体类中的字段
修改原有的缓存预热的RedisHandler
@Component
public class RedisHandler implements InitializingBean {
@Autowired
private StringRedisTemplate redisTemplate;
@Autowired
private IItemService itemService;
@Autowired
private IItemStockService stockService;
private static final ObjectMapper MAPPER = new ObjectMapper();
@Override
public void afterPropertiesSet() throws Exception {
// 初始化缓存
// 1.查询商品信息
List<Item> itemList = itemService.list();
// 2.放入缓存
for (Item item : itemList) {
saveOrUpdate(item);
}
// 3.查询商品库存信息
List<ItemStock> stockList = stockService.list();
// 4.放入缓存
for (ItemStock stock : stockList) {
// 2.1.item序列化为JSON
String json = MAPPER.writeValueAsString(stock);
// 2.2.存入redis
redisTemplate.opsForValue().set("item:stock:id:" + stock.getId(), json);
}
}
/**
* 新增或更新Item缓存
* @param item
* @throws JsonProcessingException
*/
public void saveOrUpdate(Item item) throws JsonProcessingException {
// 2.1.item序列化为JSON
String json = MAPPER.writeValueAsString(item);
// 2.2.存入redis
redisTemplate.opsForValue().set("item:id:" + item.getId(), json);
}
/**
* 删除Item缓存
* @param id
*/
public void delete(Long id) {
// 2.2.存入redis
redisTemplate.delete("item:id:" + id);
}
}
编写监听器(别忘了告知监听哪个表)
@Component
@CanalTable("tb_item")
public class ItemHandler implements EntryHandler<Item> {
/**
* 操作redis的缓存
*/
@Autowired
private RedisHandler redisHandler;
/**
* 操作JVM本地进程缓存
*/
@Autowired
private Cache<Long, Item> itemCache;
/**
* 新增时
* @param item
*/
@Override
public void insert(Item item) {
try {
// 1、为redis添加缓存
redisHandler.saveOrUpdate(item);
// 2、为Caffeine添加缓存
itemCache.put(item.getId(), item);
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
}
/**
* 修改时
* @param before
* @param after
*/
@Override
public void update(Item before, Item after) {
try {
// 1、为redis更新缓存
redisHandler.saveOrUpdate(after);
// 2、为Caffeine更新缓存
itemCache.put(after.getId(), after);
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
}
/**
* 删除时
*/
@Override
public void delete(Item item) {
// 1、为redis删除缓存
redisHandler.delete(item.getId());
// 2、为Caffeine删除缓存
itemCache.invalidate(item.getId());
}
}
如果Canal一直打印日志,想要屏蔽一下的话,可以修改日志级别
logging:
level:
com.heima: debug
top.javatool.canal: warn
(第5章)MQ高级(基于RabbitMQ)
消息可靠性
消息从发送到接收需要经过的步骤
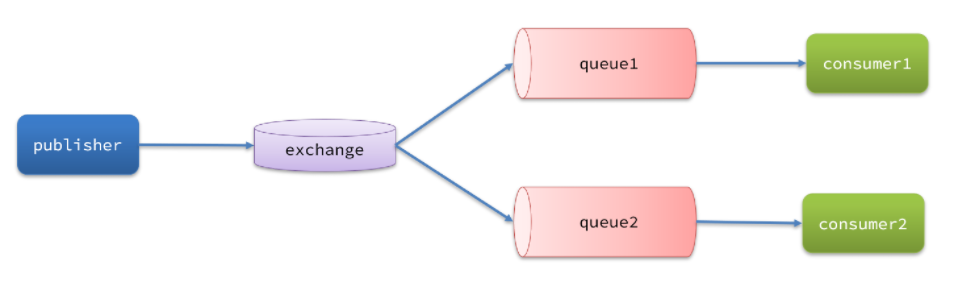
- 如上图的每一步都可能会导致消息的丢失
-
发送时丢失
- 可能还没发送到交换机就丢失了
- 可能发送到了交换机,但是交换机没有将消息成功路由到队列
-
MQ宕机,queue将消息丢弃
-
cosumer接收到消息但未消费就宕机了
-
针对如上问题,MQ给出了如下解决方案(4个)
-
生产者确认机制
-
MQ持久化
-
消费者确认机制
-
失败重试机制
生产者消息确认(确保消息可以投递到队列当中)
RabbitMQ提供了publisher confirm机制来避免消息发送到MQ过程中丢失。
这种机制必须给每个消息指定一个唯一ID。消息发送到MQ以后,会返回一个结果给发送者,表示消息是否处理成功。

修改配置(生产者)
spring:
rabbitmq:
host: 192.168.22.100 # rabbitMQ的ip地址
port: 5672 # 端口
username: admin
password: admin
virtual-host: /
publisher-confirm-type: correlated
publisher-returns: true
template:
mandatory: true
publish-confirm-type:开启publisher-confirm,这里支持两种类型:simple:同步等待confirm结果,直到超时correlated:异步回调,定义ConfirmCallback,MQ返回结果时会回调这个ConfirmCallback
publish-returns:开启publish-return功能,同样是基于callback机制,不过是定义ReturnCallbacktemplate.mandatory:定义消息路由失败时的策略。true,则调用ReturnCallback;false:则直接丢弃消息
定义ConfiremCallback,Publish-confirm发送者确认
-
ConfirmCallback可以在发送消息的时候进行指定,因为每一个业务处理confirm失败或成功的逻辑不一定相同。
-
使用示例
@Test
public void testSendMessage2SimpleQueue() throws InterruptedException {
// 1.消息体
String message = "hello, spring amqp!";
// 2.全局唯一的消息ID,需要封装到CorrelationData中
CorrelationData correlationData = new CorrelationData(UUID.randomUUID().toString());
// 3.添加callback
correlationData.getFuture().addCallback(
result -> {
if(result.isAck()){
// 3.1.ack,消息成功
log.debug("消息发送到交换机成功, ID:{}", correlationData.getId());
}else{
// 3.2.nack,消息失败
log.error("消息发送到交换机失败, ID:{}, 原因{}",correlationData.getId(), result.getReason());
}
},
ex -> log.error("消息发送异常, ID:{}, 原因{}",correlationData.getId(),ex.getMessage())
);
// 4.发送消息
rabbitTemplate.convertAndSend("task.direct", "task", message, correlationData);
// 休眠一会儿,等待ack回执
Thread.sleep(2000);
}
- 消息消费者
@RabbitListener(
bindings = @QueueBinding(
value = @Queue("task.queue1"),
exchange = @Exchange(name = "task.direct", type = ExchangeTypes.DIRECT),
key = "task"
)
)
public void listenTeskDirect(String msg) {
System.out.println("消费者接收到task.direct,routing key为task的消息:【" + msg + "】");
}
定义Return回调,Publish-return发送者回执(项目加载时)
-
一个RabbitTemplate只能定义一个CallBackReturn,用于当消息虽然发送到了交换机那,但是交换机并没有成功的将消息路由给队列。
-
创建一个配置类,在Spring容器加载后,对RabbitTemplate绑定Return回执
@Configuration
@Slf4j
public class CommonConfig implements ApplicationContextAware {
@Autowired
private RabbitTemplate rabbitTemplate;
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
// 1、配置Publish-return确认的回调
rabbitTemplate.setReturnCallback((message, replyCode, replyText, exchange, routingKey) -> {
// 投递失败,记录日志
log.info("消息路由失败,应答码{},原因{},交换机{},路由键{},消息{}",
replyCode, replyText, exchange, routingKey, message.toString());
// 如果有业务需要,可以重发消息
});
}
}
通过实现RabbitTemplate.ConfirmCallback, RabbitTemplate.ReturnCallback来完成发送到交换机、以及交换机路由到队列失败时的回调函数
- 发送消息的代码
/**
* 特别提示: 如果通过Future和将CallBack绑定到RabbitTemplate两种方式都使用了的话,则2个回调都会执行,先执行futrue再执行callback
*/
@GetMapping("/sendByCallBack")
public void sendByCallBack() {
// 1.消息体
String message = "hello, spring amqp!这条消息可能会丢失~,此种方式是通过配置一个CallBack再绑定到RabbitTemplate的方式";
// 2.全局唯一的消息ID,需要封装到CorrelationData中
CorrelationData correlationData = new CorrelationData(UUID.randomUUID().toString());
// 3. 将消息封装到CorrelationData当中,因为CallBack中会用到
// 注意: MessageProperties可以存储一些配置,其中可以存放routingkey、exchange,这样就可以重发消息了
correlationData.setReturnedMessage(new Message(message.getBytes(), new MessageProperties()));
// 4.发送消息
rabbitTemplate.convertAndSend("task.direct", "task", message, correlationData);
}
- 回调函数的代码
package com.codestars.producer.config;
import lombok.extern.slf4j.Slf4j;
import org.springframework.amqp.core.Message;
import org.springframework.amqp.core.MessageProperties;
import org.springframework.amqp.rabbit.connection.CorrelationData;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import javax.annotation.PostConstruct;
@Component
@Slf4j
public class RabbitMqCallBack implements RabbitTemplate.ConfirmCallback, RabbitTemplate.ReturnCallback {
@Autowired
private RabbitTemplate rabbitTemplate;
@PostConstruct
public void init(){
rabbitTemplate.setReturnCallback(this);
rabbitTemplate.setConfirmCallback(this);
}
/**
*
* @param correlationData 全局唯一的消息ID,会被封装到CorrelationData中
* @param ack 交换机接收消息的状态 false:表示交换机接收失败 true : 表示交换机接收成功
* @param cause 消息发送到交换机失败的原因
*/
@Override
public void confirm(CorrelationData correlationData, boolean ack, String cause) {
if(ack){
log.debug("消息发送到交换机成功, ID:{}", correlationData.getId());
}else{
log.error("消息发送到交换机失败, ID:{}, 消息内容{},原因{}",
correlationData.getId(),
new String(correlationData.getReturnedMessage().getBody()),
cause);
//TODO 处理该异常的消息,可以选择重发消息,也可以选择放到异常队列中
// 如果想要重发消息,可以在发送消息时,把交换机名称和路由key放到该MessageProperties对象中,这样就可以重发消息了
// MessageProperties messageProperties = correlationData.getReturnedMessage().getMessageProperties();
}
}
/**
* returnFallBack,当消息已经发送到了交换机,但是却没有成功发送到队列时调用
* @param message
* @param replyCode
* @param replyText
* @param exchange
* @param routingKey
*/
@Override
public void returnedMessage(Message message, int replyCode, String replyText, String exchange, String routingKey) {
// 投递失败,记录日志
log.info("消息路由失败,应答码{},原因{},交换机{},路由键{},消息{}",
replyCode, replyText, exchange, routingKey, message.toString());
// 如果有业务需要,可以重发消息
}
}
对于数据的持久化(默认情况下,SpringAMQP发出的任何消息都是持久化的,不用特意指定。)
- 虽然生产者可以确保消息投递到队列当中,但是此时如果RabbitMQ突然宕机,可能导致消息丢失,因此我们需要对其进行持久化
- 那么消息的存储需要经过交换机、队列,最后就是消息本身,需要为他们3者都进行持久化,才可以实现真正的持久化。
交换机持久化
- 使用@RabbitListener来创建交换机时,只需要添加durable为true即可
@Exchange(name = "task.direct", type = ExchangeTypes.DIRECT,durable = "true")
- 利用@Bean的方式来创建交换机时
@Bean
public DirectExchange directExchange() {
return ExchangeBuilder.directExchange("test.direct")
.durable(true)
.build();
}
@Bean
public DirectExchange simpleExchange(){
// 三个参数:交换机名称、是否持久化、当没有queue与其绑定时是否自动删除
return new DirectExchange("simple.direct", true, false);
}
}
队列持久化
- 使用@RabbitListener来创建队列时,只需要添加durable为true即可
@Queue(value = "task.queue1",durable = "true")
- 利用@Bean的方式来创建交换机时
@Bean
public Queue queue1() {
return QueueBuilder.durable("queue").build();
}
消息持久化(发布者)
- 使用MessageBuilder来创建Message对象
@Test
public void testSendMessage() throws InterruptedException {
// 1.消息体
String body = "hello, spring amqp!";
Message message = MessageBuilder.withBody(body.getBytes())
.setDeliveryMode(MessageDeliveryMode.PERSISTENT)
.build();
// 2.发送消息
rabbitTemplate.convertAndSend("task.direct", "task", message);
}
消费者消息确认
RabbitMQ是通过消费者回执来确认消费者是否成功处理消息的:消费者获取消息后,应该向RabbitMQ发送ACK回执,表明自己已经处理消息。
-
试想这样一个场景
- RabbitMQ将消息发送给了消费者
- 消费者在接收消息后,立刻发送了一个ACK回执给RabbitMQ
- RabbitMQ将消息给删除
- 而此时消费者宕机了,那么消息就丢失了
-
为了解决这样的问题,Spring的AMQP提供了如下3种确认机制
- (1)manual:手动ack,需要在业务代码结束后,手动调用api发送ack
- (2)auto: 自动ack,由于spring监测listener代码是否出现异常,没有异常则返回ack,否则返回nack
- (3)none:关闭ack,MQ假定消费者只要接收到了消息就会成功处理,因此消息投递后立即被删除
演示none模式
- 修改消费者的配置文件
spring:
rabbitmq:
host: 192.168.22.100 # rabbitMQ的ip地址
port: 5672 # 端口
username: admin
password: admin
virtual-host: /
listener:
simple:
prefetch: 1
acknowledge-mode: none # 主要就是这句话
- 通过debug调试的方式看到
- RabbitMQ在将消息投递给了消费者后,就已经把消息删除掉了。
演示auto模式(注意死循环问题)
- 修改消费者的配置文件
spring:
rabbitmq:
host: 192.168.22.100 # rabbitMQ的ip地址
port: 5672 # 端口
username: admin
password: admin
virtual-host: /
listener:
simple:
prefetch: 1
acknowledge-mode: auto
- 通过debug调试的方式看到
- RabbitMQ在将消息投递给了消费者后,会等待消费者执行之后返回的回执,如果回执不是ack,而是nack的话,那么rabbitMQ会再次将消息发送给消费者。如此反复不断,死循环。
失败重试机制
-
当消费者出现异常后,消息会不断requeue(重入队)到队列,再重新发送给消费者,然后再次异常,再次requeue,无限循环,导致mq的消息处理飙升
-
由于如上直接修改为auto可能会导致死循环,因此我们需要修改失败重试机制
本地重试
我们可以利用Spring的retry机制,在消费者出现异常时利用本地重试,而不是无限制的requeue到mq队列。
- 修改消费者的配置文件
spring:
rabbitmq:
host: 192.168.22.100 # rabbitMQ的ip地址
port: 5672 # 端口
username: admin
password: admin
virtual-host: /
listener:
simple:
prefetch: 1
acknowledge-mode: auto
retry:
enabled: true # 开启本地重试功能
max-attempts: 3 # 最大重试次数
max-interval: 1000 # 失败的初始等待时长
multiplier: 2 # 失败的等待时长倍数,下一次的等待时长为: max-interval * multiplier
stateless: true # true无状态,false有状态,当业务中包含事物,请改成false
-
在重试3次后,SpringAMQP会抛出异常AmqpRejectAndDontRequeueException,说明本地重试触发了
-
查看RabbitMQ控制台,发现消息被删除了,说明最后SpringAMQP返回的是ack,mq删除消息了
失败策略
-
如上已经能够进行本地的失败重试了,但是失败重试依然没有成功执行的话,将会有失败策略
-
SpringAMQP为我们提供了3种失败策略
- RejectAndDontRequeueRecoverer :在重试耗尽后,会向RabbitMQ发送ack回执,直接丢弃消息(默认)
- ImmediateRequeueMessageRecoverer: 重试耗尽后,返回nack,消息重新入队
- RepublishMessageRecoverer : 重试耗尽后,将失败的消息投递到指定的交换机中
定义处理失败消息的交换机和队列,并为RabbitTemplate绑定指定的失败策略
@Configuration
public class ErrorMessgeConfig {
@Bean
public DirectExchange errorDirectExchange() {
return new DirectExchange("error.direct");
}
@Bean
public Queue errorQueue() {
return new Queue("error.queue");
}
@Bean
public Binding errorBinding(DirectExchange errorDirectExchange, Queue errorQueue) {
return BindingBuilder.bind(errorQueue).to(errorDirectExchange).with("error");
}
@Bean
public MessageRecoverer messageConverter(RabbitTemplate rabbitTemplate) {
return new RepublishMessageRecoverer(rabbitTemplate, "error.direct", "error");
}
}
总结(如何确保RabbitMQ消息的可靠性?)
-
开启生产者确认机制,确保生产者的消息能到达队列
-
开启持久化功能,确保消息未消费前在队列中不会丢失
-
开启消费者确认机制为auto,由spring确认消息处理成功后完成ack
-
开启消费者失败重试机制,并设置MessageRecoverer,多次重试失败后将消息投递到异常交换机,交由人工处理
如果设置消息为手动确认时的处理方式(获取到消息后进行手动确认)
1、修改配置
# 开启消费端手动应答
acknowledge-mode: manual
2、处理消息的代码
/**
* 重试三次后,会丢到该队列所绑定的死信交换机上当中(这里还没有添加死信交换机,所以这段代码并没有测试)
* @param message
*/
@RabbitListener(bindings = @QueueBinding(
exchange = @Exchange(name = "task.direct2", type = ExchangeTypes.DIRECT),
value = @Queue("task.queue2"),
key = "task"
))
public void securityConsumer2(String message, Message mess, Channel channel) throws IOException {
// 是否重投
Boolean redelivered = mess.getMessageProperties().getRedelivered();
System.out.println("是否重投的标记:" + redelivered);
try {
int i = 1 / 0;
System.out.println("消费者ConfirmConsumer接收到的消息为:" + message);
// 如果正常接收到消息,则确认收到消息
channel.basicAck(mess.getMessageProperties().getDeliveryTag(), false);
} catch (Exception e) {
e.printStackTrace();
if (redelivered) {// 已经重投过
/**
* 参数1: 消息的标识
* 参数2: true: 继续重试 false:放入死信队列
*/
channel.basicReject(mess.getMessageProperties().getDeliveryTag(), false);
System.out.println("消息消费异常,直接作废,添加到死信队列");
} else {
/**
* 参数1: 消息的标识
* 参数2: 是否批量确认
* 参数3: true: 继续重试 false:放入死信队列
*/
channel.basicNack(mess.getMessageProperties().getDeliveryTag(), false, true);
System.out.println("消息消费异常,消息进行重投");
}
}
}
消费端如何保证消息不被重复消费
使用DataID + Redis的处理方式
1、发送端
@GetMapping("/send")
public void sendMessage(String message, String routingKey){
// 创建correlationData,用于保存发送的信息
String uuid = UUID.randomUUID().toString();
CorrelationData correlationData = new CorrelationData(uuid);
Message mess = new Message(message.getBytes());
// 设置该条消息的唯一ID
mess.getMessageProperties().setMessageId(uuid);
correlationData.setReturnedMessage(mess);
MessagePostProcessor messagePostProcessor = mess2 -> {
mess2.getMessageProperties().setMessageId(uuid);
System.out.println("生产的消息ID为:" + uuid);
return mess2;
};
rabbitTemplate.convertAndSend("confirm_exchange", routingKey, message, messagePostProcessor, correlationData);
}
2、消费端
@RabbitListener(queues = "confirm_queue")
public void getMessage(String message, Message mess){
// 1、获取一把分布式锁
// 2、获取mess中的DataId
String messageId = mess.getMessageProperties().getMessageId();
// 3、从redis中通过key获取该DataId,然后做一系列判断
System.out.println("消费者ConfirmConsumer接收到的消息为:" + message);
}
死信交换机、TTL、延迟队列
什么是死信?什么是死信交换机
-
当一个队列中的消息满足如下3种情况之一时,可以称为死信(dead letter)
-
消费者使用basic.reject或basic.nack声明了消费失败,并且消息的requeue参数设置为false
-
消息是一个过期消息,超时无人消费(需要设置过期时间)
-
需要投递的队列满了,无法投递
-
-
如果这个包含死信的队列配置了dead-letter-exchange属性来指定了一个交换机,那么队列中的死信就会投递到该交换机中。而该交换机就称之为死信交换机。
利用死信交换机接收死信(千万注意RabbitMQ中原有的队列,同名的建议处理下)
- 在失败重试策略中,默认的RejectAndDontRequeueRecoverer会在本地重试次数耗尽后,发送reject给RabbitMQ,消息变成死信,被丢弃。
创建死信的队列和交换机,将其进行绑定。再创建一个简单队列,用于演示消息传递到死信交换机
@Configuration
public class DeadLetterConfig {
@Bean
public DirectExchange dlDirectExchange() {
return new DirectExchange("dl.direct");
}
@Bean
public Queue dlQueue() {
return new Queue("dl.queue", true);
}
@Bean
public Binding dlBinding(DirectExchange dlDirectExchange, Queue dlQueue) {
return BindingBuilder.bind(dlQueue).to(dlDirectExchange).with("dl");
}
/**
* 创建一个队列,为其指定死信交换机
* @return
*/
@Bean
public Queue simpleQueue() {
return QueueBuilder.durable("simple.queue")
.deadLetterExchange("dl.direct")
.deadLetterRoutingKey("dl")
// 设置超时时间,如果超过了指定时间,则该队列中的消息会变成死信
.ttl(5000)
.build();
}
}
监听绑定了死信交换机的队列
@RabbitListener(queues = "simple.queue")
public void listenSimpleQueue(String msg) {
int i = 1/0;
System.out.println("消费者接收到simple.queue的消息:【" + msg + "】");
}
为绑定了死信交换机的队列发消息
@Test
public void testSendMessage(){
// 1.消息体
String body = "hello, spring amqp!";
// 2.发送消息
rabbitTemplate.convertAndSend("simple.queue", body);
}
消息进入了死信交换机的解析
-
此时由于绑定了死信交换机的队列会根据本地重试机制来进行重试,重试之后如果失败策略使用的是默认,则会丢弃该消息,该消息就变成了死信,就会进入死信交换机了
-
注意此时,我已经注释掉了RepublishMessageRecoverer本次重试失败后的解决策略,因此就变成向rabbitMQ发送reject丢弃该消息了。此时该消息就变成了死信。这个时候由于该队列绑定了死信交换机,就交给死信交换机了。
TTL(Time To Live)生存时间(2种情况变死信)
- 一个队列中的消息如果超时未被消费,则会变成死信,这个时候分如下2种情况
- 队列设置了超时时间
- 消息设置了超时时间
- 如果2者都设置了超时时间(哪个时间更短,就按照哪个时间来)
声明一个队列,并且指定TTL
@Bean
public Queue ttlQueue(){
return QueueBuilder.durable("ttl.queue") // 指定队列名称,并持久化
.ttl(10000) // 设置队列的超时时间,10秒
.deadLetterExchange("dl.ttl.direct") // 指定死信交换机
.build();
}
声明一个消息,并且指定Expire
// 创建消息
Message message = MessageBuilder
.withBody("hello, ttl message".getBytes(StandardCharsets.UTF_8))
.setExpiration("5000")
.build();
如何实现发送一个消息20秒后消费者才收到消息
-
创建一个死信交换机dl.direct 、 一个死信队列dl.queue,创建一个绑定器使交换机与队列绑定(再设置个routingkey为dl)
-
创建一个消费者,监听死信队列dl.queue(最终延迟消息的消费者...)
-
创建一个队列simple.queue,该队列设置过期时间20秒,绑定死信交换机dl.direct和死信routingkey为dl,但是该队列没有任何的监听者
-
接下来只需要一个发送者,向simple.queue发送消息,即可实现延迟处理消息了。
延迟队列,实际用的是交换机(官方提供的插件)
-
利用TTL结合死信交换机,我们实现了消息发出后,消费者延迟收到消息的效果。这种消息模式就称为延迟队列(Delay Queue)模式。
-
延迟队列的使用场景
- 延迟发送短信
- 预约工作会议,20分钟后自动通知
- 用户下单,超过15分钟不付款自动取消订单等
安装DelayExchange插件
-
使用方式官方文档:https://blog.rabbitmq.com/posts/2015/04/scheduling-messages-with-rabbitmq
-
此时可以考虑重新创建一个rabbitMQ容器
docker run \
--name rabbitmq3 \
-p 5672:5672 \
-p 15672:15672 \
-v rabbitMqData:/var/lib/rabbitmq \
-v rabbitPlugins:/plugins \
--hostname myRabbit \
-e RABBITMQ_DEFAULT_VHOST=my_vhost \
-e RABBITMQ_DEFAULT_USER=admin \
-e RABBITMQ_DEFAULT_PASS=admin\
-d \
rabbitmq:3-management
- 通过如下命令找到rabbitPlugins该映射文件夹的目录
docker volume inspect rabbitPlugins
-
将下载好到插件放到该插件目录下
-
进入到rabbitMQ容器当中并且执行如下命令
# 进入容器
docker exec -it rabbitmq3 /bin/bash
# 执行命令加载插件
rabbitmq-plugins enable rabbitmq_delayed_message_exchange
DelayExchange插件的实现原理(5步走)
DelayExchange需要将一个交换机声明为delayed类型。当我们发送消息到delayExchange时,流程如下:
-
接收消息
-
判断消息是否具备x-delay属性
-
如果有x-delay属性,说明是延迟消息,持久化到硬盘,读取x-delay值,作为延迟时间
-
返回routing not found结果给消息发送者
-
x-delay时间到期后,重新投递消息到指定队列
使用DelayExchange
插件的使用也非常简单:声明一个交换机,交换机的类型可以是任意类型,只需要设定delayed属性为true即可,然后声明队列与其绑定即可。
声明DelayExchange交换机的2种方式
- 基于注解的配置方式(推荐)
@RabbitListener(
bindings = @QueueBinding(
value = @Queue(value = "delay.queue",durable = "true"),
exchange = @Exchange(name = "delay.direct",delayed = "true", type = ExchangeTypes.DIRECT),
key = "delay"
)
)
public void listenSimpleQueue(String msg) {
log.info("监听到了延迟队列消息,结果为:{}", msg);
}
- 基于@Bean的配置方式
@Bean
public Exchange delayDirectExchange() {
return ExchangeBuilder.directExchange("delay.direct") // 配置交换机类型和名称
.delayed() // 配置为延迟交换机
.durable(true) // 开启持久化
.build();
}
消费者发送延迟消息(注意需要携带的属性)
@Test
public void testSendDelayMessage() {
Message message = MessageBuilder
.withBody("张三真好".getBytes(StandardCharsets.UTF_8))
.setHeader("x-delay", 10000)
.build();
// 2.发送消息
rabbitTemplate.convertAndSend("delay.direct","delay", message);
log.info("消息发送成功");
}
如果有延迟消息,将会返回routing not found结果给消息发送者,此时会触发发送者的ReturnCallback
- 修改发送者的ReturnCallback
@Configuration
@Slf4j
public class CommonConfig implements ApplicationContextAware {
@Autowired
private RabbitTemplate rabbitTemplate;
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
// 1、配置Publish-return确认的回调
rabbitTemplate.setReturnCallback((message, replyCode, replyText, exchange, routingKey) -> {
Integer delay = message.getMessageProperties().getReceivedDelay();
if(delay != null && delay >= 0) {
// 代表此时是延迟消息,忽略
return;
}
// 投递失败,记录日志
log.info("消息路由失败,应答码{},原因{},交换机{},路由键{},消息{}",
replyCode, replyText, exchange, routingKey, message.toString());
// 如果有业务需要,可以重发消息
});
}
}
惰性队列
消息堆积问题(2个解决思路)
当生产者发送消息的速度超过了消费者处理消息的速度,就会导致队列中的消息堆积,直到队列存储消息达到上限。之后发送的消息就会成为死信,可能会被丢弃,这就是消息堆积问题。
- 解决消息堆积的2个思路
- 增加消费者,也就是之前说的Work Queue模式
- 扩大队列容积,提高堆积上限
- 提示:要提升队列容积,把消息保存在内存中显然是不行的。因为内存就那么大。
惰性队列的概念与使用
从RabbitMQ的3.6.0版本开始,就增加了Lazy Queues的概念,也就是惰性队列。惰性队列的特征如下:
-
接收到消息后直接存入磁盘而非内存
-
消费者要消费消息时才会从磁盘中读取并加载到内存
-
支持数百万条的消息存储
基于rabbitmq的命令来设置lazy-queue
rabbitmqctl set_policy Lazy "^lazy-queue$" '{"queue-mode":"lazy"}' --apply-to queues
命令解读:
rabbitmqctl:RabbitMQ的命令行工具set_policy:添加一个策略Lazy:策略名称,可以自定义"^lazy-queue$":用正则表达式匹配队列的名字'{"queue-mode":"lazy"}':设置队列模式为lazy模式--apply-to queues:策略的作用对象,是所有的队列
基于@Bean来声明lazy-queue
@Bean
public Queue lazyQueue() {
return QueueBuilder.durable("lazy.queue")
.lazy() // 开启x-queue-mode 为 lazy模式
.build();
}
基于@RabbitListener来声明lazy-queue
@RabbitListener(queuesToDeclare = @Queue(
name = "lazy.queue",
durable = "true",
arguments = @Argument(name = "x-queue-mode", value = "lazy")
)
)
public void lazyListener() {
}
惰性队列总结(别忘了page-out)
-
消息堆积的解决方案?
- 增加消费者,使用Work Queue模式
- 采用惰性队列来存储消息,使消息存储在磁盘当中
-
惰性队列的优点有哪些?
- 基于磁盘存储,消息上限高
- 不像普通队列一样有间歇的page-out,性能比较稳定
-
惰性队列的缺点有哪些?
- 基于磁盘存储,消息时效性会降低
- 性能受限于磁盘IO
RabbitMQ集群
集群的分类以及仲裁队列是什么
RabbitMQ的是基于Erlang语言编写,而Erlang又是一个面向并发的语言,天然支持集群模式。RabbitMQ的集群有两种模式
-
普通集群:是一种分布式集群,将队列分散到集群的各个节点,从而提高整个集群的并发能力。
-
镜像集群:是一种主从集群,普通集群的基础上,添加了主从备份功能,提高集群的数据可用性。
镜像集群虽然支持主从,但主从同步并不是强一致的,某些情况下可能有数据丢失的风险。因此在RabbitMQ的3.8版本以后,推出了新的功能:仲裁队列来代替镜像集群,底层采用Raft协议确保主从的数据一致性
普通集群
普通集群(标准集群)的3个特征
-
会在集群的各个节点间共享部分数据,包括:交换机、队列元信息。不包含队列中的消息。
-
当访问集群某节点时,如果队列不在该节点,会从数据所在节点传递到当前节点并返回
-
队列所在节点宕机,队列中的消息就会丢失
部署普通集群
预期部署情况
| 主机名 | 控制台端口 | amqp通信端口 |
|---|---|---|
| mq1 | 8081 ---> 15672 | 8071 ---> 5672 |
| mq2 | 8082 ---> 15672 | 8072 ---> 5672 |
| mq3 | 8083 ---> 15672 | 8073 ---> 5672 |
获取cookie
RabbitMQ底层依赖于Erlang,而Erlang虚拟机就是一个面向分布式的语言,默认就支持集群模式。集群模式中的每个RabbitMQ 节点使用 cookie 来确定它们是否被允许相互通信。
要使两个节点能够通信,它们必须具有相同的共享秘密,称为Erlang cookie。cookie 只是一串最多 255 个字符的字母数字字符。
每个集群节点必须具有相同的 cookie。实例之间也需要它来相互通信。
我们先在之前启动的mq容器中获取一个cookie值,作为集群的cookie。执行下面的命令:
docker exec -it rabbitmq3 cat /var/lib/rabbitmq/.erlang.cookie
# 得到的cookie值如下
HGTEIYVNQDRUCNSAOWBD
删除现有的rabbitmq容器,开始重新搭建
docker rm -f mq
准备一个集群配置,在/tmp/docker/RabbitMQ下创建配置文件(2个)
- 配置文件名称:rabbitmq.conf
# 禁用guest用户
loopback_users.guest = false
listeners.tcp.default = 5672
cluster_formation.peer_discovery_backend = rabbit_peer_discovery_classic_config
# 因为打算让rebbitmq在同一个网络,并且容器名分别为mq1 mq2 mq3
cluster_formation.classic_config.nodes.1 = rabbit@mq1
cluster_formation.classic_config.nodes.2 = rabbit@mq2
cluster_formation.classic_config.nodes.3 = rabbit@mq3
- 再创建一个文件
.erlang.cookie,注意是隐藏文件
# 创建cookie文件
touch .erlang.cookie
# 写入cookie
echo "HGTEIYVNQDRUCNSAOWBD" > .erlang.cookie
# 修改cookie文件的权限
chmod 600 .erlang.cookie
- 准备三个目录,mq1、mq2、mq3
mkdir mq1 mq2 mq3
- rabbitmq.conf、cookie文件到mq1、mq2、mq3
cp rabbitmq.conf mq1
cp rabbitmq.conf mq2
cp rabbitmq.conf mq3
cp .erlang.cookie mq1
cp .erlang.cookie mq2
cp .erlang.cookie mq3
创建网络并启动集群
-
创建网络
docker network create mq-net -
创建3台容器
docker run -d --net mq-net \
-v ${PWD}/mq1/rabbitmq.conf:/etc/rabbitmq/rabbitmq.conf \
-v ${PWD}/mq1/.erlang.cookie:/var/lib/rabbitmq/.erlang.cookie \
-e RABBITMQ_DEFAULT_USER=admin \
-e RABBITMQ_DEFAULT_PASS=admin \
--name mq1 \
--hostname mq1 \
-p 8071:5672 \
-p 8081:15672 \
rabbitmq:3.8-management
docker run -d --net mq-net \
-v ${PWD}/mq2/rabbitmq.conf:/etc/rabbitmq/rabbitmq.conf \
-v ${PWD}/.erlang.cookie:/var/lib/rabbitmq/.erlang.cookie \
-e RABBITMQ_DEFAULT_USER=admin \
-e RABBITMQ_DEFAULT_PASS=admin \
--name mq2 \
--hostname mq2 \
-p 8072:5672 \
-p 8082:15672 \
rabbitmq:3-management
docker run -d --net mq-net \
-v ${PWD}/mq3/rabbitmq.conf:/etc/rabbitmq/rabbitmq.conf \
-v ${PWD}/.erlang.cookie:/var/lib/rabbitmq/.erlang.cookie \
-e RABBITMQ_DEFAULT_USER=admin \
-e RABBITMQ_DEFAULT_PASS=admin \
--name mq3 \
--hostname mq3 \
-p 8073:5672 \
-p 8083:15672 \
rabbitmq:3-management
docker查看错误启动容器的日志
docker inspect --format '{{.LogPath}}' 容器id或容器名称
镜像集群(本质是主从模式)
集群结构和特征
部署镜像集群(有点像ElasticSearch)
-
交换机、队列、队列中的消息会在各个mq的镜像节点之间同步备份。
-
创建队列的节点被称为该队列的主节点,备份到的其它节点叫做该队列的镜像节点。
-
一个队列的主节点可能是另一个队列的镜像节点
-
所有操作都是主节点完成,然后同步给镜像节点
-
主宕机后,镜像节点会替代成新的主
仲裁队列
特征
仲裁队列:仲裁队列是3.8版本以后才有的新功能,用来替代镜像队列,具备下列特征:
- 与镜像队列一样,都是主从模式,支持主从数据同步
- 使用非常简单,没有复杂的配置
- 主从同步基于Raft协议,强一致
部署仲裁队列
Java代码创建仲裁队列
@Bean
public Queue quorumQueue() {
return QueueBuilder
.durable("quorum.queue") // 持久化
.quorum() // 仲裁队列
.build();
}
SpringAMQP连接MQ集群
spring:
rabbitmq:
addresses: 192.168.22.100:8071, 192.168.22.100:8072, 192.168.22.100:8073
username: itcast
password: 123321
virtual-host: /

 浙公网安备 33010602011771号
浙公网安备 33010602011771号