JAVA入门基础_SpringCloud入门学习
- 分布式的最佳实践:微服务的大致框架
- 服务注册与发现、配置中心、负载均衡、远程调用、网关
- Docker容器化技术
- RabbitMQ 消息队列的使用(基于Docker安装)
- ElasticSearch分布式搜索
分布式的最佳实践:微服务的大致框架
-
首先微服务,会将我们的功能模块进行拆分
- 拆分的粒度如何界定?
- 服务之间如何调用?
- 服务的调用关系如何管理。
-
微服务的主要特点有几个
- 要求拆分的一个个微服务有着单一指责,每个微服务都有自己的数据库
- 自治:团队独立、技术独立、数据独立、独立部署与交付
- 面向服务:每个微服务对外暴露接口来提供服务
- 隔离性强:服务调用之间做好隔离、容错、降级、避免出现级联问题
-
综上所述,微服务是一种经过良好架构设计的分布式架构方案。
单体架构(优缺点)
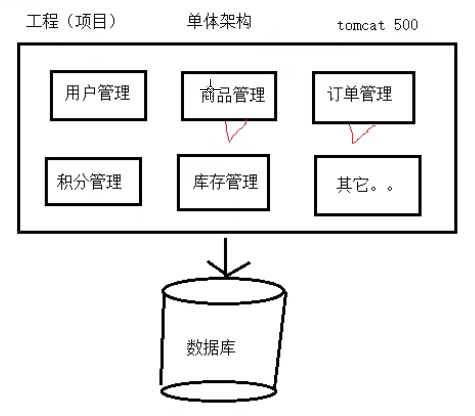
缺点
- 只要一个地方出问题,那么整个项目都不能运行
- 只有一个数据库,所有的功能都访问一个数据库(数据库压力大)
- 如果需要集群,则只能复制一份(造成资源的浪费,因为并不是每个功能都需要那么多的并发量)
- 技术栈统一(导致没法使用多种不同的技术来解决不同的问题)
- 后期维护困难
优点
- 简单
- 前期的开发成本低
垂直架构
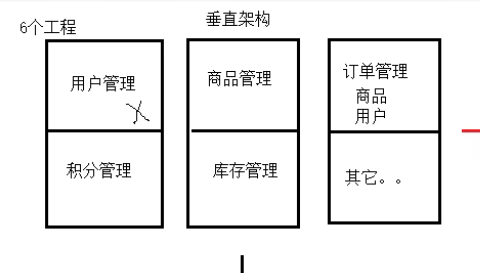
缺点
- 只有一个数据库,所有功能访问同一个数据库
- 开发成本比单体架构更高
- 工程之间没有关联关系,因此在不同的工程中需要使用另一个工程的功能(需要把代码全部复制一份过来),此时就造成了代码的大量重复,这是致命缺点
优点
- 模块之间解耦(但又没完全解)
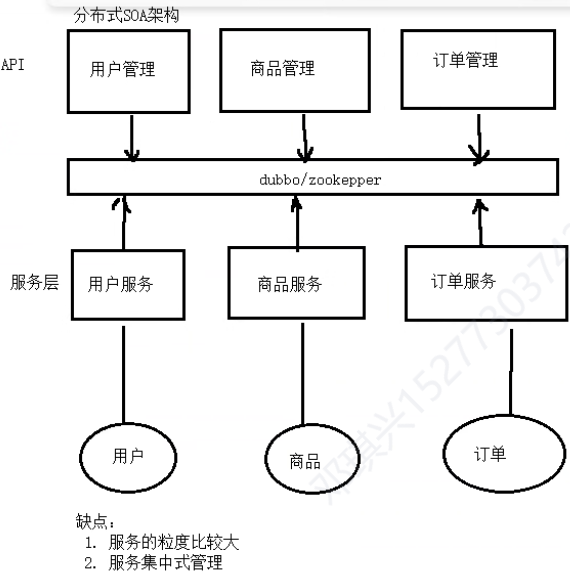
分布式架构(SOA)
微服务架构(知道API网关与服务的区别)
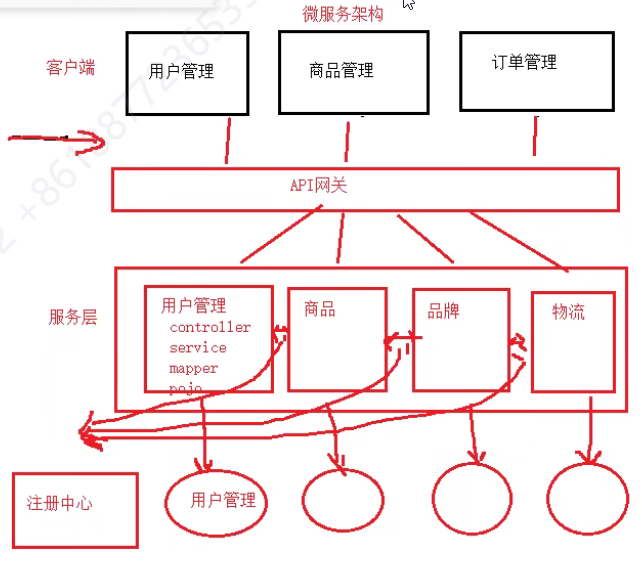
API网关:相当于客户端,是对用户端暴露的接口
服务: 就是我们API网关来调用到一个个服务,不过这个中间会夹着一个注册中心
SOA到微服务的主要区别
1、服务的粒度拆分问题
- SOA:例如商品管理拆分成一个服务。
- 微服务:商品管理拆分成: 品类服务、商品服务(其实就是拆分粒度更加细)
2、SOA中的服务一般指的只有service层的代码,微服务中的服务是包含整个工程的完整代码(controller、service、dao、entity、utils等等)
3、SOA是集中式管理Service、微服务是集中式管理Controller
什么是SpringCloud呢?
-
springcloud帮助我们集成了各种微服务需要使用到的功能组件,实现开箱即用,大幅的降低了程序员的工作量。
-
SpringCloud是依赖于SpringBoot来构建的一套微服务解决方案,因此SpringCloud与SpringBoot的版本需要进行对应
-
大致的版本信息如下,更加全面的需要查阅官方文档
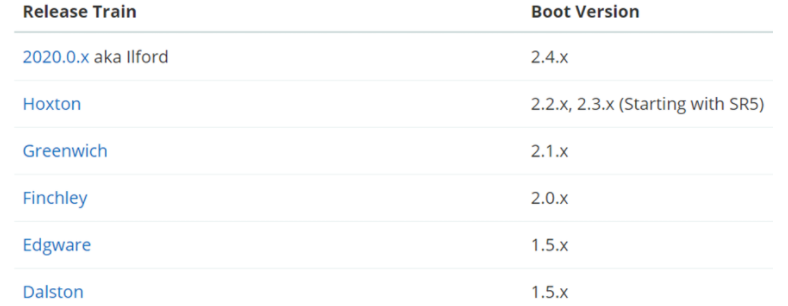
-
本文中所采用的版本为
- springboot: 2.3.9
- springcloud:Hoxton.SR10
服务注册与发现、配置中心、负载均衡、远程调用、网关
进行一个最基础的服务拆分与远程调用
定义父工程,引入所需要的必备依赖
- 引入springcloud
- 引入springboot
- 管理mysql的版本
- 管理mybatis的版本
- 管理java的版本为jdk1.8
<packaging>pom</packaging>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.9.RELEASE</version>
<relativePath/>
</parent>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>1.8</java.version>
<spring-cloud.version>Hoxton.SR10</spring-cloud.version>
<mysql.version>5.1.47</mysql.version>
<mybatis.version>2.1.1</mybatis.version>
</properties>
<dependencyManagement>
<dependencies>
<!-- springCloud,这里就相当于引入了第二个父工程 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring-cloud.version}</version>
<!-- 设置打包方式为pom -->
<type>pom</type>
<!-- 将该pom导入到当前项目中 -->
<scope>import</scope>
</dependency>
<!-- mysql驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
</dependency>
<!--mybatis-->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>${mybatis.version}</version>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>
在父工程下创建2个模块(SpringBoot模块)
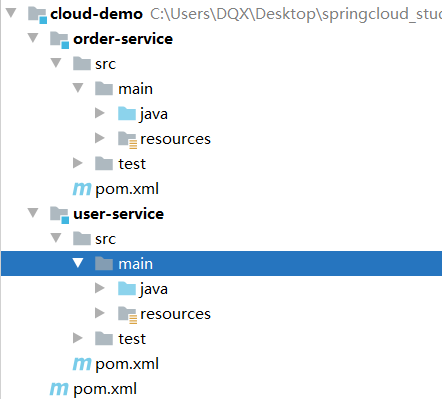
加入一些必备的依赖(web启动器等)
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<!--mybatis-->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
</dependency>
</dependencies>
<build>
<finalName>app</finalName>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
编写远程调用的代码RestTemplate(5个条件)
-
URL
-
请求方式
-
服务地址/服务名(需要注册中心的服务发现)
-
发送的参数
-
返回值类型
-
在需要进行远程调用的类中添加如下依赖(不加也可以)
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter</artifactId>
</dependency>
- 在任意一个Spring配置类中配置一个RestTemplate的Bean
@Configuration
public class Config {
@Bean
@LoadBalanced // 开启负载均衡,内部使用的是Ribbon
public RestTemplate restTemplate(RestTemplateBuilder builder){
return builder.build();
}
}
- 编写一个远程访问的请求代码
@Autowired
private RestTemplate restTemplate;
public Order queryOrderById(Long orderId) {
// 1.查询订单
Order order = orderMapper.findById(orderId);
// 2、调用User服务, 2.1 URL、服务地址、请求参数
String url = "http://127.0.0.1:8081/user/" + order.getUserId();
// 2.1 请求方式、返回值类型
User user = restTemplate.getForObject(url , User.class);
// 3、封装结果
order.setUser(user);
// 4.返回
return order;
}
使用Eureka注册中心
搭建Eureka服务注册中心(服务端)
创建一个模块,添加依赖
<!-- 1、 引入Eureka注册中心服务端的依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
修改配置,使自身注册到服务中心
spring:
application:
name: eureka-server # 服务名称
server:
port: 10086 # Eureka注册中心服务端口
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:10086/eureka # 由于本身也是一个微服务,也要注册到服务中心
其实也可以不将自己注册到服务中心
spring:
application:
name: eureka-server
server:
port: 10086 # Eureka注册中心服务端口
eureka:
client:
service-url:
# 由于本身也是一个微服务,也要注册到服务中心
defaultZone: http://127.0.0.1:10086/eureka
# 是否向注册中心注册自己,缺省:true、一般情况下,Eureka服务端是不需要再注册自己的
register-with-eureka: false
# 是否从Eureka获取注册信息,缺省:true, 一般情况下,Eureka服务端是不需要的
fetch-registry: false
添加一个启动类、启动服务
@SpringBootApplication
@EnableEurekaServer
public class EurekaServerApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaServerApplication.class, args);
}
}
使其他的服务注册到服务中心(客户端)
引入依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
修改配置
spring:
application:
name: order-server
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:10086/eureka
远程调用的url需要修改
String url = "http://user-server/user/" + order.getUserId();
注意: Ribbon使用远程调用时,服务名不能用下划线,否则会报错
Request URI does not contain a valid hostname:http://xxx
记住了
查看Eureka的管理界面
- 访问:
localhost:10086即可
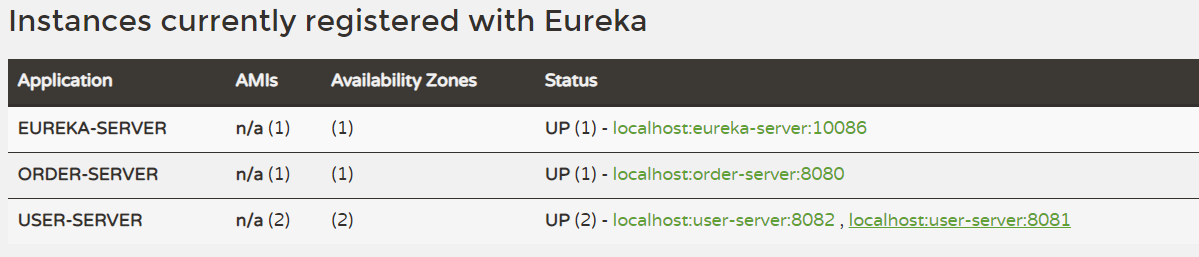
Eureka注册中心服务调用的简易流程
-
当服务注册到了Eureka注册中心后,需要每30秒向Eureka发送心跳,告知当前服务器的运行状态
-
服务之间的调用时,消费者需要到注册中心中获取可使用的服务列表(服务拉取),找到之后再进行访问调用,此时服务地址就需要换成对应的服务名
使同一个服务开启2次
-
右键复制一个服务
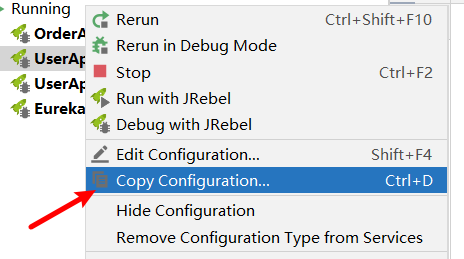
-
添加配置
-Dserver.port=xxxx,修改个端口号,当然,也可以改变其profile环境


Eureka配置实例名称,以及高可用
首先,Eureka自身需要注册到服务中心中,并且也需要拉取服务列表,因此我们准备2台Eureka
spring:
application:
name: eureka-server
eureka:
instance:
instance-id: ${spring.cloud.client.ip-address}:${server.port}
---
spring:
profiles: eureka1
server:
port: 8050 # Eureka注册中心服务端口
eureka:
client:
service-url:
# 由于本身也是一个微服务,也要注册到服务中心
defaultZone: http://127.0.0.1:8060/eureka
---
spring:
profiles: eureka2
server:
port: 8060 # Eureka注册中心服务端口
eureka:
client:
service-url:
# 由于本身也是一个微服务,也要注册到服务中心
defaultZone: http://127.0.0.1:8050/eureka
其他需要使用到注册中心的服务,需要配置多个注册中心的列表,OrderService的application.yml
server:
servlet:
context-path: /order
port: 8081
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:8050/eureka,http://127.0.0.1:8060/eureka
Ribbon负载均衡
负载均衡策略IRule(默认轮询)
| 内置负载均衡规则类 | 规则描述 |
|---|---|
| RoundRobinRule | 简单轮询服务列表来选择服务器。它是Ribbon默认的负载均衡规则。 |
| AvailabilityFilteringRule | 对以下两种服务器进行忽略: (1)在默认情况下,这台服务器如果3次连接失败,这台服务器就会被设置为“短路”状态。短路状态将持续30秒,如果再次连接失败,短路的持续时间就会几何级地增加。 (2)并发数过高的服务器。如果一个服务器的并发连接数过高,配置了AvailabilityFilteringRule规则的客户端也会将其忽略。并发连接数的上限,可以由客户端的、<clientName>.<clientConfigNameSpace>.ActiveConnectionsLimit属性进行配置。 |
| WeightedResponseTimeRule | 为每一个服务器赋予一个权重值。服务器响应时间越长,这个服务器的权重就越小。这个规则会随机选择服务器,这个权重值会影响服务器的选择。 |
| ZoneAvoidanceRule | 以区域可用的服务器为基础进行服务器的选择。使用Zone对服务器进行分类,这个Zone可以理解为一个机房、一个机架等。而后再对Zone内的多个服务做轮询。 |
| BestAvailableRule | 忽略那些短路的服务器,并选择并发数较低的服务器。 |
| RandomRule | 随机选择一个可用的服务器。 |
| RetryRule | 重试机制的选择逻辑 |
默认的实现就是ZoneAvoidanceRule,是一种轮询方案
自定义负载均衡的2种方式
- 在使用到负载均衡的服务任意配置类中,配置一个Bean(全局生效)
@Bean
public IRule randomRule(){
return new RandomRule();
}
- 修改配置文件方式,指定某个具体使用的服务
user-server: # 给某个微服务配置负载均衡规则,这里是userservice服务
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule
使Ribbon进行饥饿加载
ribbon:
eager-load:
enabled: true
# 需要指定使用哪个服务时饥饿加载,可以指定多个,逗号分隔
clients: userservice
负载均衡的两种方式(客户端、服务端)
1、例如nginx就是服务端的负载均衡,因为客户端并不知道具体访问的服务列表
2、注册中心中的服务发现使用的负载均衡,就是客户端的负载均衡,客户端知道能够访问的服务列表,并根据不同的策略进行负载均衡的分流调用
Ribbon的重试机制以及会带来的问题(接口幂等性)
没有请求重试时会出现的问题:
首先一个服务宕机了,但是注册中心中的服务列表此时还没有剔除,那么我们客户端在拉取服务列表的时候,就会拉取到这个已经宕机的服务,那么访问时,一旦访问到了已经宕机的服务,那么将会直接给用户响应错误界面,这个显然不合理。
请求重试:就是当前请求的实例不可用,那么重试其它服务
1、添加依赖(在进行服务拉取并调用到服务中添加,例如order调用product,那么在order服务中添加)
<dependency>
<groupId>org.springframework.retry</groupId>
<artifactId>spring-retry</artifactId>
</dependency>
2、修改配置
# 修改指定服务的负载均衡策略
product-server:
ribbon:
# 指定负载均衡策略为:随机策略
#NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RoundRobinRule
ConnectTimeout: 250 # Ribbon的连接超时时间 简历http连接的时间
ReadTimeout: 1000 # Ribbon的数据读取超时时间,请求响应的时间
OkToRetryOnAllOperations: true # 是否对所有操作都进行重试
MaxAutoRetriesNextServer: 1 # 切换实例的重试次数
MaxAutoRetries: 1 # 对当前实例的重试次数
2.2、如果想要配置全局
ribbon:
# 指定负载均衡策略为:随机策略
#NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RoundRobinRule
ConnectTimeout: 250 # Ribbon的连接超时时间 简历http连接的时间
ReadTimeout: 1000 # Ribbon的数据读取超时时间,请求响应的时间
OkToRetryOnAllOperations: true # 是否对所有操作都进行重试
MaxAutoRetriesNextServer: 1 # 切换实例的重试次数
MaxAutoRetries: 1 # 对当前实例的重试次数
Nacos注册中心
搭建Nacos注册中心
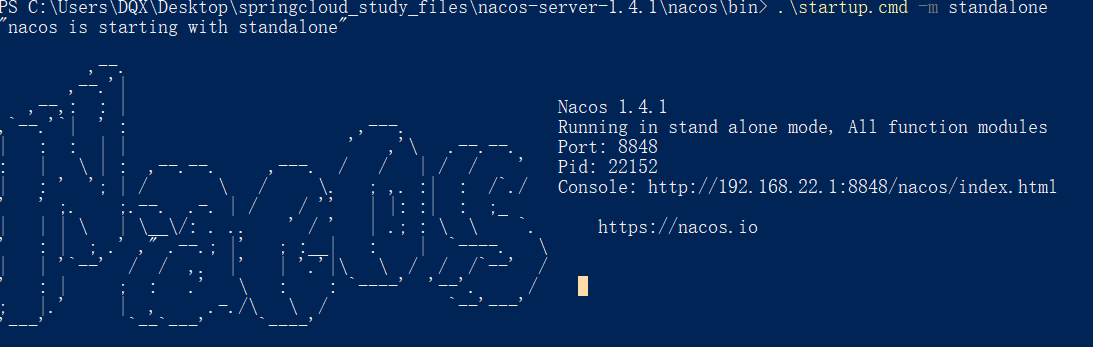
下载与安装Nacos并启动服务(服务端)
-
下载后将其解压到一个非中文目录下
-
以为管理员身份打开cmd命令,在其bin目录下运行如下命令
startup.cmd -m standalone -
接下来可以通过如下地址访问:
http://192.168.22.1:8848/nacos/index.html默认的账号和密码都是:nacos
在父工程、客户端中引入依赖,并在客户端修改配置
- 父工程POM
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2.2.6.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
- 客户端POM
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
- 修改客户端配置文件
spring:
cloud:
nacos:
server-addr: http://localhost:8848
Nacos服务分级存储模型
-
Nacos可以让我们的一个个客户端实例划分到相对应的集群中,可以在服务列表的一个个详情中看到所在集群。
-
优先访问相同集群之内的服务实例,相当集群内没有可用的服务实例才考虑其他集群的。但是需要配置ribbon中的负载均衡规则。
-
修改客户端的配置服务
spring:
cloud:
nacos:
server-addr: http://localhost:8848
discovery:
cluster-name: shanghai # 集群
user-server:
ribbon:
NFLoadBalancerRuleClassName: com.alibaba.cloud.nacos.ribbon.NacosRule # nacos负载均衡规则
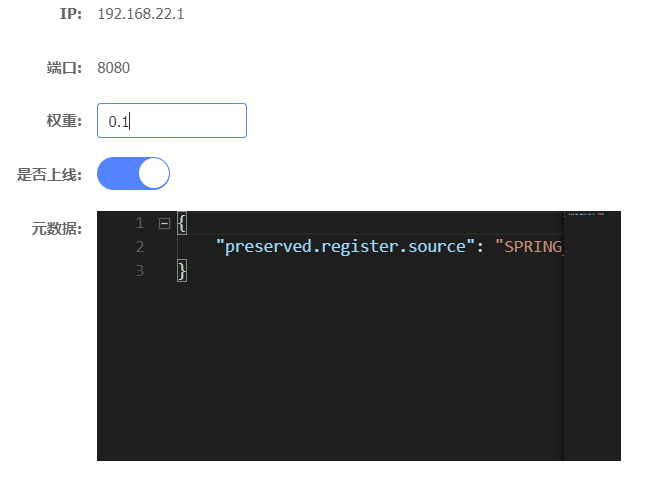
权重配置,实现优雅的重启系统
-
在Nacos中可以配置实例的权重,权重越低,被访问的频率越低
-
当设置为0时,将不会再被访问
-
可以逐渐降低某个需要更新的实例的权重,最后设置为0后,再重启该实例
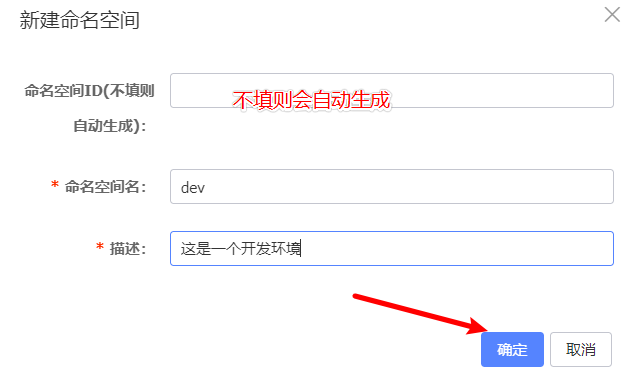
Nacos的环境隔离
-
默认情况下,所有的客户端都在同一个namespace下
-
可以通过Nacos创建一个新的namespace,然后通过修改客户端的配置实现访问指定的namespace

spring:
cloud:
nacos:
server-addr: http://localhost:8848
discovery:
cluster-name: shanghai
namespace: 0c222dc3-b003-4fea-80a8-3f3db0baa171
- 不同namespace下的实例相互之间是不可见的。
为一个服务配置为永久实例(非临时实例)
spring:
cloud:
nacos:
discovery:
ephemeral: false # 设置为非临时实例
Nacos与Eureka作为注册中心的区别
-
Eureka、Nacos都支持接收客户端的心跳检测
-
Eureka、Nacos都可以让客户端拉取服务列表
-
Nacos 可以主动为非临时实例发送请求保证非临时实例的可用性。非临时实例宕机也不会从服务列表中剔除。
-
Nacos 会主动向客户端发送服务列表,增加客户端响应请求的速度。
-
两者对于宕机的临时实例都会剔除。
搭建Nacos集群
新建一个数据库nacos,执行如下脚本
CREATE TABLE `config_info` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id',
`data_id` varchar(255) NOT NULL COMMENT 'data_id',
`group_id` varchar(255) DEFAULT NULL,
`content` longtext NOT NULL COMMENT 'content',
`md5` varchar(32) DEFAULT NULL COMMENT 'md5',
`gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间',
`src_user` text COMMENT 'source user',
`src_ip` varchar(50) DEFAULT NULL COMMENT 'source ip',
`app_name` varchar(128) DEFAULT NULL,
`tenant_id` varchar(128) DEFAULT '' COMMENT '租户字段',
`c_desc` varchar(256) DEFAULT NULL,
`c_use` varchar(64) DEFAULT NULL,
`effect` varchar(64) DEFAULT NULL,
`type` varchar(64) DEFAULT NULL,
`c_schema` text,
PRIMARY KEY (`id`),
UNIQUE KEY `uk_configinfo_datagrouptenant` (`data_id`,`group_id`,`tenant_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='config_info';
/******************************************/
/* 数据库全名 = nacos_config */
/* 表名称 = config_info_aggr */
/******************************************/
CREATE TABLE `config_info_aggr` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id',
`data_id` varchar(255) NOT NULL COMMENT 'data_id',
`group_id` varchar(255) NOT NULL COMMENT 'group_id',
`datum_id` varchar(255) NOT NULL COMMENT 'datum_id',
`content` longtext NOT NULL COMMENT '内容',
`gmt_modified` datetime NOT NULL COMMENT '修改时间',
`app_name` varchar(128) DEFAULT NULL,
`tenant_id` varchar(128) DEFAULT '' COMMENT '租户字段',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_configinfoaggr_datagrouptenantdatum` (`data_id`,`group_id`,`tenant_id`,`datum_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='增加租户字段';
/******************************************/
/* 数据库全名 = nacos_config */
/* 表名称 = config_info_beta */
/******************************************/
CREATE TABLE `config_info_beta` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id',
`data_id` varchar(255) NOT NULL COMMENT 'data_id',
`group_id` varchar(128) NOT NULL COMMENT 'group_id',
`app_name` varchar(128) DEFAULT NULL COMMENT 'app_name',
`content` longtext NOT NULL COMMENT 'content',
`beta_ips` varchar(1024) DEFAULT NULL COMMENT 'betaIps',
`md5` varchar(32) DEFAULT NULL COMMENT 'md5',
`gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间',
`src_user` text COMMENT 'source user',
`src_ip` varchar(50) DEFAULT NULL COMMENT 'source ip',
`tenant_id` varchar(128) DEFAULT '' COMMENT '租户字段',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_configinfobeta_datagrouptenant` (`data_id`,`group_id`,`tenant_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='config_info_beta';
/******************************************/
/* 数据库全名 = nacos_config */
/* 表名称 = config_info_tag */
/******************************************/
CREATE TABLE `config_info_tag` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id',
`data_id` varchar(255) NOT NULL COMMENT 'data_id',
`group_id` varchar(128) NOT NULL COMMENT 'group_id',
`tenant_id` varchar(128) DEFAULT '' COMMENT 'tenant_id',
`tag_id` varchar(128) NOT NULL COMMENT 'tag_id',
`app_name` varchar(128) DEFAULT NULL COMMENT 'app_name',
`content` longtext NOT NULL COMMENT 'content',
`md5` varchar(32) DEFAULT NULL COMMENT 'md5',
`gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间',
`src_user` text COMMENT 'source user',
`src_ip` varchar(50) DEFAULT NULL COMMENT 'source ip',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_configinfotag_datagrouptenanttag` (`data_id`,`group_id`,`tenant_id`,`tag_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='config_info_tag';
/******************************************/
/* 数据库全名 = nacos_config */
/* 表名称 = config_tags_relation */
/******************************************/
CREATE TABLE `config_tags_relation` (
`id` bigint(20) NOT NULL COMMENT 'id',
`tag_name` varchar(128) NOT NULL COMMENT 'tag_name',
`tag_type` varchar(64) DEFAULT NULL COMMENT 'tag_type',
`data_id` varchar(255) NOT NULL COMMENT 'data_id',
`group_id` varchar(128) NOT NULL COMMENT 'group_id',
`tenant_id` varchar(128) DEFAULT '' COMMENT 'tenant_id',
`nid` bigint(20) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`nid`),
UNIQUE KEY `uk_configtagrelation_configidtag` (`id`,`tag_name`,`tag_type`),
KEY `idx_tenant_id` (`tenant_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='config_tag_relation';
/******************************************/
/* 数据库全名 = nacos_config */
/* 表名称 = group_capacity */
/******************************************/
CREATE TABLE `group_capacity` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`group_id` varchar(128) NOT NULL DEFAULT '' COMMENT 'Group ID,空字符表示整个集群',
`quota` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '配额,0表示使用默认值',
`usage` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '使用量',
`max_size` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '单个配置大小上限,单位为字节,0表示使用默认值',
`max_aggr_count` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '聚合子配置最大个数,,0表示使用默认值',
`max_aggr_size` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '单个聚合数据的子配置大小上限,单位为字节,0表示使用默认值',
`max_history_count` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '最大变更历史数量',
`gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_group_id` (`group_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='集群、各Group容量信息表';
/******************************************/
/* 数据库全名 = nacos_config */
/* 表名称 = his_config_info */
/******************************************/
CREATE TABLE `his_config_info` (
`id` bigint(64) unsigned NOT NULL,
`nid` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`data_id` varchar(255) NOT NULL,
`group_id` varchar(128) NOT NULL,
`app_name` varchar(128) DEFAULT NULL COMMENT 'app_name',
`content` longtext NOT NULL,
`md5` varchar(32) DEFAULT NULL,
`gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`src_user` text,
`src_ip` varchar(50) DEFAULT NULL,
`op_type` char(10) DEFAULT NULL,
`tenant_id` varchar(128) DEFAULT '' COMMENT '租户字段',
PRIMARY KEY (`nid`),
KEY `idx_gmt_create` (`gmt_create`),
KEY `idx_gmt_modified` (`gmt_modified`),
KEY `idx_did` (`data_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='多租户改造';
/******************************************/
/* 数据库全名 = nacos_config */
/* 表名称 = tenant_capacity */
/******************************************/
CREATE TABLE `tenant_capacity` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`tenant_id` varchar(128) NOT NULL DEFAULT '' COMMENT 'Tenant ID',
`quota` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '配额,0表示使用默认值',
`usage` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '使用量',
`max_size` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '单个配置大小上限,单位为字节,0表示使用默认值',
`max_aggr_count` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '聚合子配置最大个数',
`max_aggr_size` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '单个聚合数据的子配置大小上限,单位为字节,0表示使用默认值',
`max_history_count` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '最大变更历史数量',
`gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_tenant_id` (`tenant_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='租户容量信息表';
CREATE TABLE `tenant_info` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id',
`kp` varchar(128) NOT NULL COMMENT 'kp',
`tenant_id` varchar(128) default '' COMMENT 'tenant_id',
`tenant_name` varchar(128) default '' COMMENT 'tenant_name',
`tenant_desc` varchar(256) DEFAULT NULL COMMENT 'tenant_desc',
`create_source` varchar(32) DEFAULT NULL COMMENT 'create_source',
`gmt_create` bigint(20) NOT NULL COMMENT '创建时间',
`gmt_modified` bigint(20) NOT NULL COMMENT '修改时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_tenant_info_kptenantid` (`kp`,`tenant_id`),
KEY `idx_tenant_id` (`tenant_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='tenant_info';
CREATE TABLE `users` (
`username` varchar(50) NOT NULL PRIMARY KEY,
`password` varchar(500) NOT NULL,
`enabled` boolean NOT NULL
);
CREATE TABLE `roles` (
`username` varchar(50) NOT NULL,
`role` varchar(50) NOT NULL,
UNIQUE INDEX `idx_user_role` (`username` ASC, `role` ASC) USING BTREE
);
CREATE TABLE `permissions` (
`role` varchar(50) NOT NULL,
`resource` varchar(255) NOT NULL,
`action` varchar(8) NOT NULL,
UNIQUE INDEX `uk_role_permission` (`role`,`resource`,`action`) USING BTREE
);
INSERT INTO users (username, password, enabled) VALUES ('nacos', '$2a$10$EuWPZHzz32dJN7jexM34MOeYirDdFAZm2kuWj7VEOJhhZkDrxfvUu', TRUE);
INSERT INTO roles (username, role) VALUES ('nacos', 'ROLE_ADMIN');
复制3个Nacos文件夹,并分别修改2个配置文件(集群配置、数据库配置、端口配置)
-
复制3个nacos
-
修改它们配置文件下的cluster.conf.example文件,将其改名为cluster.conf,然后进行追加如下配置
-
注意~~~ ,这里可以全都改成自动生成的 ip地址,不然可能会出现异常。
127.0.0.1:8848
127.0.0.1:8849
127.0.0.1:8850
- 修改它们的application.properties文件,分别改成不同的端口
nacos1 : server.port=8848
nacos2 : server.port=8849
nacos3 : server.port=8850
- 修改它们的application.properties文件,分别加上如下数据库信息(连自己的数据库)
spring.datasource.platform=mysql
db.num=1
db.url.0=jdbc:mysql://127.0.0.1:3306/nacos?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&useUnicode=true&useSSL=false&serverTimezone=UTC
db.user.0=root
db.password.0=abc123
搭建Nginx代理服务器,追加如下配置,放在http标签内
upstream nacos-cluster {
server 127.0.0.1:8848;
server 127.0.0.1:8849;
server 127.0.0.1:8850;
}
server {
listen 80;
server_name localhost;
location /nacos {
proxy_pass http://nacos-cluster;
}
}
启动3台nacos再启动nginx,并且微服务客户端中的nacos注册地址需要换成nginx的地址
-
启动nacos,需要进入到nacos的bin目录中,开启cmd命令行
startup.cmd -
启动nginx,双击nginx.exe即可
-
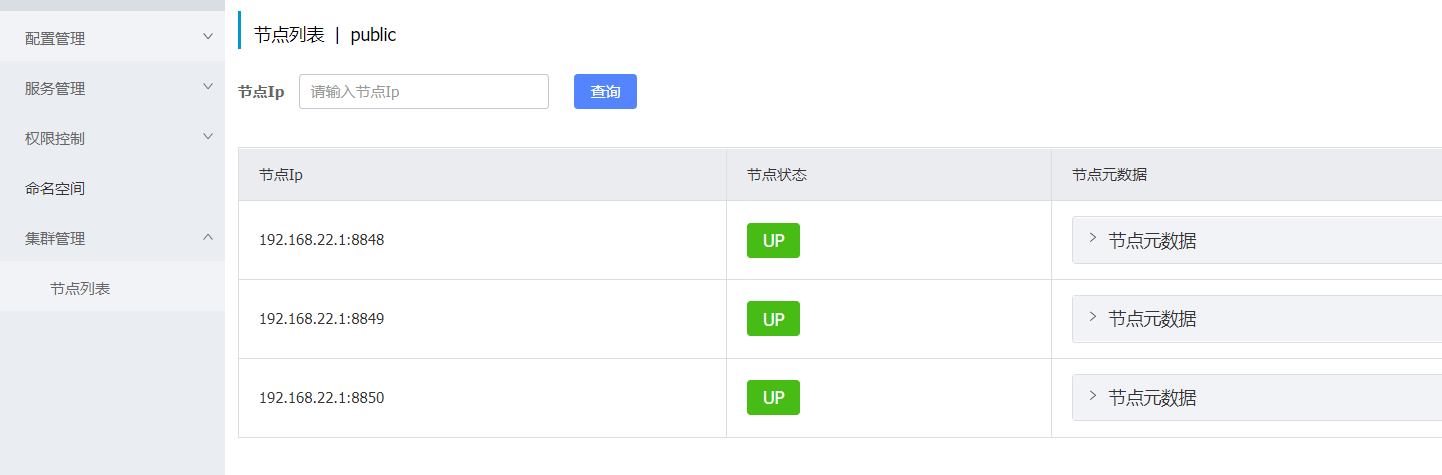
浏览器通过:
http://localhost/nacos即可访问到nacos服务
Nacos 配置管理
-
Nacos可以实现配置的集中管理与热更新
-
统一配置管理一般就放那些需要热更新的数据
在Nacos中添加配置文件
添加客户端的依赖
<!--nacos配置管理依赖-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
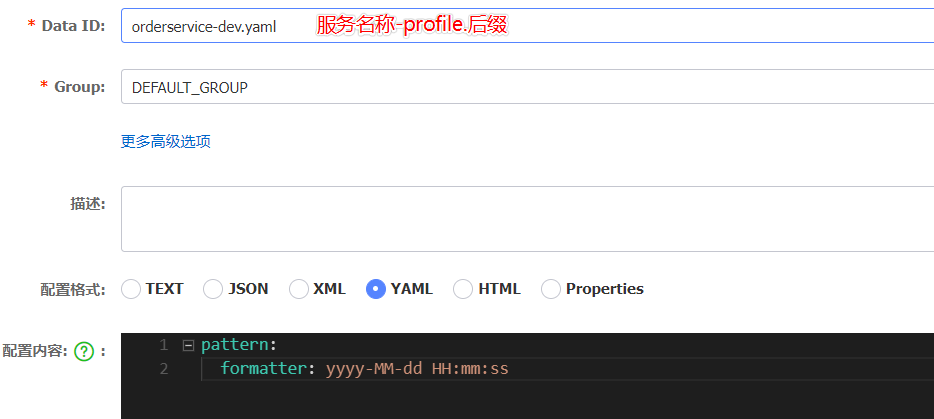
修改客户端的配置,在bootstrap.yml中(服务名、profile)
spring:
application:
name: orderservice # 1、服务名称
profiles:
active: dev # 2、profile
cloud:
nacos:
server-addr: http://localhost:80
config:
file-extension: yaml # 3、文件后缀名
# 刚好能够构成: orderservice-dev.yaml配置文件
客户端获取配置的2种方式
- 通过@Value注入,这个类上需要加注解
@RestController
@RefreshScope
public class ConfigController {
@Value("${pattern.formatter}")
private String pattern;
@Autowired
private PatternProperties patternProperties;
@GetMapping("/date")
public String getDate() {
DateTimeFormatter dateTimeFormatter = DateTimeFormatter.ofPattern(pattern);
System.out.println(patternProperties);
return LocalDateTime.now().format(dateTimeFormatter);
}
}
- 通过@ConfigurationProperties和@Component的方式
@Component
@ConfigurationProperties("pattern")
@Data
public class PatternProperties {
private String formatter;
}
配置共享 以及 3种配置的优先级
-
有2种命名的配置文件可以作为配置管理,被读取到
-
第一种就是 : 服务名-profile.后缀名,例如: orderservice-dev.yaml
-
第二种是: 服务名.后缀名,例如: orderservice.yaml

-
优先级: orderservice-dev.yaml > orderservice.yaml > 本地配置(本地配置是优先级最低的)
nacos扩展公共配置
1、新建配置
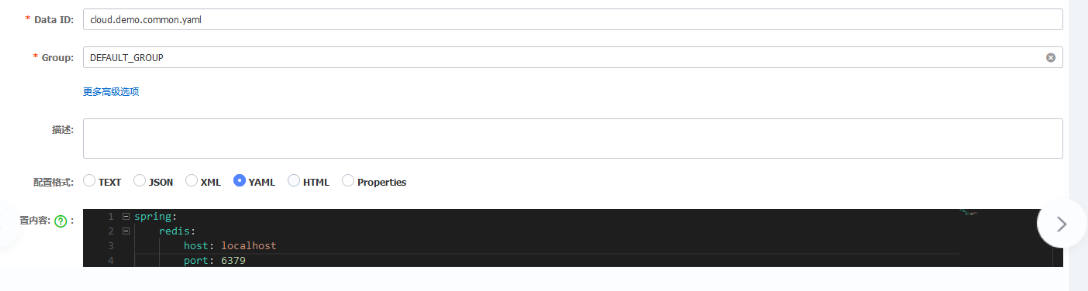
2、引用通用配置文件
# 指定nacos配置中心的地址
spring:
cloud:
nacos:
discovery:
server-addr: http://localhost:8848
username: nacos
password: nacos
config:
# 指定读取配置文件的格式
file-extension: yaml
shared-configs:
# 通用的配置文件的ID,一定要带上后缀名
- data-id: cloud.demo.common.yaml
# 自动刷新
refresh: true
3、配置的优先级
SpringCloudAlibabaNacosConfig目前提供了三种配置能力从Nacos拉取相关的配置。
A:通过spring.cloud.nacos.config.shared-configs支持多个共享DataId的配置
B:通过spring.cloud.nacos.config.ext-config[n].data-id的方式支持多个扩展DataId的配置
C:通过内部相关规则(应用名、应用名+Profile)自动生成相关的DataId配置
当三种方式共同使用时,他们的一个优先级关系是:A < B < C
Feign远程调用
-
Feign可以实现优雅的调用远程服务,不用像之前的RestTemplate那么繁琐
-
Feign通过RestFul定义接口的方式来让其完成远程调用
搭建一个Feign远程调用环境
在需要进行远程调用的服务中引入依赖、添加启动类注解
- 引入依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
- 在启动类上添加注解
@EnableFeignClients
编写一个接口,添加注解,配置服务间调用的5个条件
@FeignClient("user-server") // 1、服务名
public interface UserClient {
@GetMapping("/user/{id}") // 2.3.4.5、 请求方式、 请求URL、请求参数、返回值
User getUserById(@PathVariable Long id);
}
需要使用到的地方,就只需要依赖注入一下即可
@Autowired
private UserClient userClient;
修改Feign的自定义配置
| 类型 | 作用 | 说明 |
|---|---|---|
| feign.Logger.Level | 修改日志级别 | 包含四种不同的级别:NONE、BASIC、HEADERS、FULL |
| feign.codec.Decoder | 响应结果的解析器 | http远程调用的结果做解析,例如解析json字符串为java对象 |
| feign.codec.Encoder | 请求参数编码 | 将请求参数编码,便于通过http请求发送 |
| feign. Contract | 支持的注解格式 | 默认是SpringMVC的注解 |
| feign. Retryer | 失败重试机制 | 请求失败的重试机制,默认是没有,不过会使用Ribbon的重试 |
根据配置文件配置的2种方式
- 配置对所有的服务都生效
feign:
client:
config:
default: # 使用default就是对所有服务都生效
loggerLevel: FULL # 日志级别 ,一般推荐使用 NONE或者BASIC
- 配置对指定的服务生效
feign:
client:
config:
user-server: # 使用服务名则代表对单个服务生效
loggerLevel: FULL # 日志级别 ,一般推荐使用 NONE或者BASIC
JAVA代码配置的2种方式
- 先创建一个Feign的配置类,注入点Bean
public class DefaultFeignConfiguration {
@Bean
public Logger.Level feignLogLevel(){
return Logger.Level.BASIC; // 日志级别为BASIC
}
}
- 在启动类上进行指定,相当于全局配置
@EnableFeignClients(defaultConfiguration = DefaultFeignConfiguration.class)
- 对单个服务生效,在@FeignClient上配置
@FeignClient(value = "user-server",configuration = DefaultFeignConfiguration.class)
public interface UserClient {
@GetMapping("/user/{id}")
User getUserById(@PathVariable Long id);
}
Feign配置支持连接池的HTTP请求
-
Feign默认底层使用的是URLConnection,而请求方式并不支持连接池
-
而支持连接池的有Apache HttpClient 和 OKHttp,因此我们可以为Feign配置一个支持连接池的HTTP请求技术
添加HttpClient的依赖
<!--httpClient的依赖 -->
<dependency>
<groupId>io.github.openfeign</groupId>
<artifactId>feign-httpclient</artifactId>
</dependency>
在配置文件中修改feign的配置
feign:
client:
config:
default: # default全局的配置
loggerLevel: BASIC # 日志级别,BASIC就是基本的请求和响应信息
httpclient:
enabled: true # 开启feign对HttpClient的支持
max-connections: 200 # 最大的连接数
max-connections-per-route: 50 # 每个路径的最大连接数
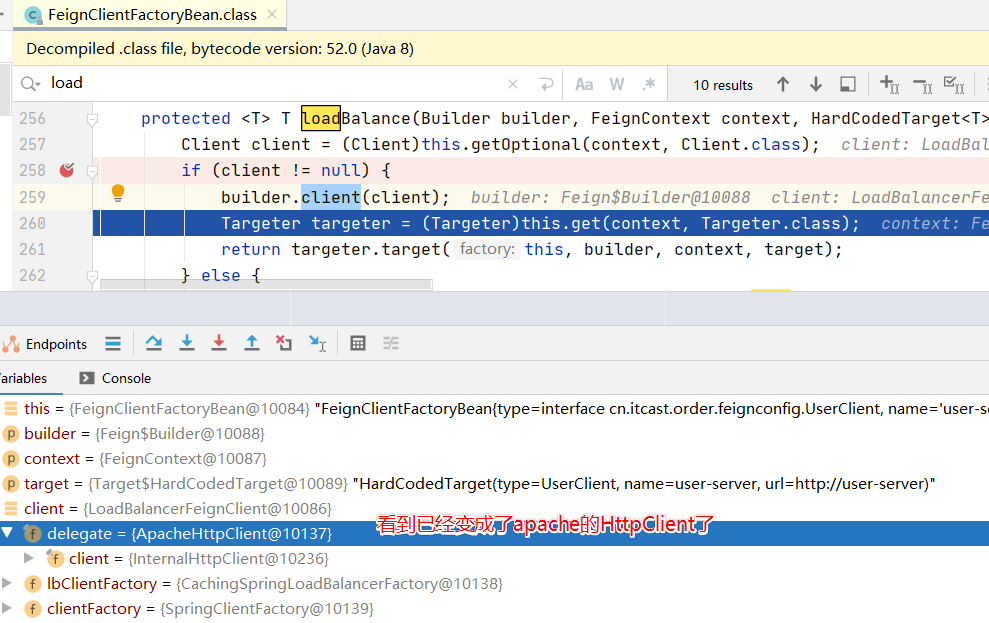
Feign配置数据压缩,以及与ribbon配置重复的情况优先级问题
# feign的相关配置
feign:
client:
config:
product-server:
connectTimeout: 3000 # 连接超时时间 默认是2S
readTimeout: 3000 # 处理请求的时间 默认是5S
compression:
request:
# 开启请求数据压缩(默认值为false)
enabled: true
# 支持压缩的数据类型
mime-types: text/html,application/xml,application/json
# 设置触发压缩的数据大小下限
min-request-size: 2048
response:
# 开启响应压缩(默认值为false)
enabled: true
如果Feign的配置与Ribbon重复,优先使用Feign的
Feign在实际生产中解决代码重复的2种方式
-
在Feign的使用当中,我们发现FeignClient中的接口代码,与UserService服务所暴露的接口,声明方式是一模一样的。
-
解决方案一:创建一个模块,该模块中定义UserService暴露服务的统一接口。然后让UserService模块去实现统一接口。再让OrderService也去实现统一接口。
- 弊端:增加了耦合。2个不同的模块竟然同时依赖于相同的接口
-
解决方案二:定义一个模块feign-api ,里面专门定义需要进行远程访问的FeignClient,哪个服务需要使用到远程调用,就依赖于feign-api这个模块即可
- 弊端:即便Feign-api中有些服务在当前服务用不到,但也会引入到当前服务当中,占用资源。
演示解决方案二,定义一个feign-api模块
- 引入如下依赖(feign和httpclient)
<!--httpClient的依赖 -->
<dependency>
<groupId>io.github.openfeign</groupId>
<artifactId>feign-httpclient</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
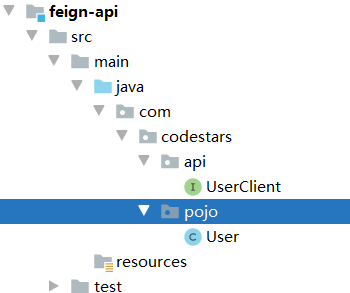
-
将UserClient迁移到feign-api模块当中,结构如下
-
在原有的OrderService服务中引入feign-api模块
<dependency>
<groupId>cn.codestars.demo</groupId>
<artifactId>feign-api</artifactId>
<version>1.0</version>
</dependency>
解决扫描包的问题
-
由于现在UserClient已经不在当前Order模块中了,因此无法扫描到对应的包。有如下2个解决方案
-
解决方案一:扫描整个包
@EnableFeignClients(basePackages = "com.codestars.api")
- 解决方案二:单独注册一个个FeignClient(推荐)
@EnableFeignClients(clients = UserClient.class)
GateWay服务网关
-
有了网关之后,用户以后就访问网关,然后由网关判断该用户是否有权限访问,并在进行了一系列过滤后,为其提供服务
-
网关大致有如下几个作用:
- 权限控制:可以校验用户是否有资格访问,没有则进行拦截
- 路由和负载均衡:网关通过某种规则请求转发到指定的某个微服务(这个过程叫做路由),当目标的路由有多个时,还需要做负载均衡。
- 限流:当请求流量过大时,网关可以按照下流的处理速度来放行请求,避免服务压力过大。
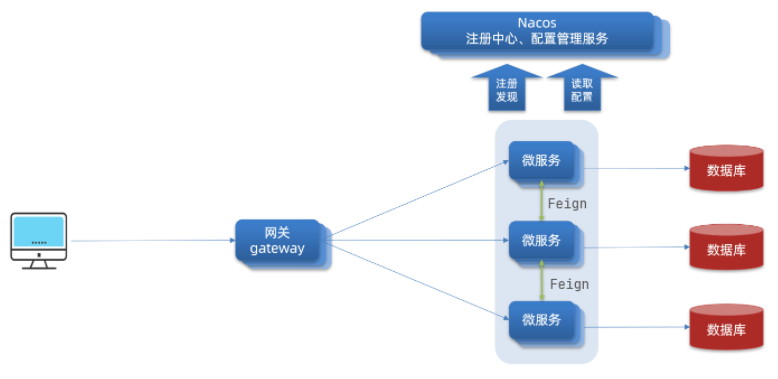
GateWay快速入门
GatWay也是一个微服务,因此需要创建一个gateway模块引入依赖(并且也需要注册到服务中心)
<!--网关-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
<!--nacos服务发现依赖-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
创建启动类
@SpringBootApplication
public class GatewayApplication {
public static void main(String[] args) {
SpringApplication.run(GatewayApplication.class, args);
}
}
修改配置文件
spring:
application:
name: gateway
cloud:
nacos:
server-addr: http://localhost:80
gateway:
routes:
- id: user-server # 路由id,自定义,只要唯一即可
uri: lb://user-server # lb 代表负载均衡, 后面跟服务名称
predicates: # 路由断言,也就是判断请求是否符合路由规则的条件
- Path=/user/** # 这个是按照路径匹配,只要以/user/开头就符合要求,意思是:访问/user/开头的请求就会使用该路由
server:
port: 10010
启动服务后尝试访问(只能处理配置了路由的请求)
http://localhost:10010/user/2
断言工厂、过滤器工厂、全局过滤器
断言工厂分类
| 名称 | 说明 | 示例 |
|---|---|---|
| After | 是某个时间点后的请求 | - After=2037-01-20T17:42:47.789-07:00[America/Denver] |
| Before | 是某个时间点之前的请求 | - Before=2031-04-13T15:14:47.433+08:00[Asia/Shanghai] |
| Between | 是某两个时间点之前的请求 | - Between=2037-01-20T17:42:47.789-07:00[America/Denver], 2037-01-21T17:42:47.789-07:00[America/Denver] |
| Cookie | 请求必须包含某些cookie | - Cookie=chocolate, ch.p |
| Header | 请求必须包含某些header | - Header=X-Request-Id, \d+ |
| Host | 请求必须是访问某个host(域名) | - Host=.somehost.org,.anotherhost.org |
| Method | 请求方式必须是指定方式 | - Method=GET,POST |
| Path | 请求路径必须符合指定规则 | - Path=/red/{segment},/blue/** |
| Query | 请求参数必须包含指定参数 | - Query=name, Jack或者- Query=name |
| RemoteAddr | 请求者的ip必须是指定范围 | - RemoteAddr=192.168.1.1/24 |
| Weight | 权重处理 |
- 我们只需要掌握Path这一种断言工厂就可以了
过滤器工厂(针对单个路由、默认过滤器)
-
可以对进入网关的请求进行过滤(进入了网关,意味着已经通过了断言工厂)
-
过滤器工厂的种类,Spring中提供了30多种,这里简单列举几个
| 名称 | 说明 |
| -------------------- | ---------------------------- |
| AddRequestHeader | 给当前请求添加一个请求头 |
| RemoveRequestHeader | 移除请求中的一个请求头 |
| AddResponseHeader | 给响应结果中添加一个响应头 |
| RemoveResponseHeader | 从响应结果中移除有一个响应头 |
| RequestRateLimiter | 限制请求的流量 | -
测试添加一个AddResponseHeader过滤器工厂和一个默认过滤器
spring:
application:
name: gateway
cloud:
nacos:
server-addr: http://localhost:80
gateway:
routes:
- id: user-server # 路由id,自定义,只要唯一即可
uri: lb://user-server # lb 代表负载均衡, 后面跟服务名称
predicates: # 路由断言,也就是判断请求是否符合路由规则的条件
- Path=/user/** # 这个是按照路径匹配,只要以/user/开头就符合要求,意思是:访问/user/开头的请求就会使用该路由
filters:
- AddResponseHeader=responseTitle, responseTitleBody # 响应头的key与value使用逗号分割
default-filters:
- AddResponseHeader=name, zhangsan # 默认过滤器,针对所有路由,key与value使用逗号分割
- AddRequestHeader=name, zhangsan # 默认过滤器,针对所有路由,key与value使用逗号分割
server:
port: 10010
全局过滤器
- 定义一个类,实现GlobalFilter接口
@Order(-1) // 执行优先级,数值越低优先级越高
@Component
public class AuthorizeFilter implements GlobalFilter {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
// 1.获取请求参数
MultiValueMap<String, String> params = exchange.getRequest().getQueryParams();
// 2.获取authorization参数
String auth = params.getFirst("authorization");
// 3.校验
if ("admin".equals(auth)) {
// 放行
return chain.filter(exchange);
}
// 4.拦截
// 4.1.禁止访问,设置状态码
exchange.getResponse().setStatusCode(HttpStatus.FORBIDDEN);
// 4.2.结束处理
return exchange.getResponse().setComplete();
}
}
过滤器执行顺序
-
首先按照优先级执行,也就是Order
-
其次是按照defaultFilters > 路由的过滤器 > 全局过滤器
路径重写过滤器(重要)
spring:
application:
name: gulimall-gateway
cloud:
nacos:
server-addr: localhost:8848
gateway:
routes:
# 2、匹配商品服务的请求
- id: gulimall-product
uri: lb://gulimall-product
predicates:
- Path=/api/product/**
filters:
- RewritePath=/api/product/?(?<segment>.*), /product/$\{segment}
# 3、匹配第三方服务的请求
- id: gulimall-third-party
uri: lb://gulimall-third-party
predicates:
- Path=/api/third-party/**
filters:
- RewritePath=/api/third-party/?(?<segment>.*), /$\{segment}
# 1、匹配后台管理界面的renren-fast请求
- id: renren-fast
uri: lb://renren-fast
predicates:
- Path=/api/**
filters:
- RewritePath=/api/?(?<segment>.*), /renren-fast/$\{segment}
server:
port: 88
跨域问题解决
- 在gateway中修改一下配置文件
spring:
application:
name: gateway
cloud:
nacos:
server-addr: http://localhost:80
gateway:
routes:
- id: user-server # 路由id,自定义,只要唯一即可
uri: lb://user-server # lb 代表负载均衡, 后面跟服务名称
predicates: # 路由断言,也就是判断请求是否符合路由规则的条件
- Path=/user/** # 这个是按照路径匹配,只要以/user/开头就符合要求,意思是:访问/user/开头的请求就会使用该路由
filters:
- AddResponseHeader=responseTitle, responseTitleBody # 响应头的key与value使用逗号分割
default-filters:
- AddResponseHeader=name, zhangsan # 默认过滤器,针对所有路由,key与value使用逗号分割
- AddRequestHeader=name, zhangsan # 默认过滤器,针对所有路由,key与value使用逗号分割
globalcors: # 全局的跨域处理
add-to-simple-url-handler-mapping: true # 解决options请求被拦截问题
corsConfigurations:
'[/**]':
allowedOrigins: # 允许哪些网站的跨域请求
- "http://localhost:8090"
allowedMethods: # 允许的跨域ajax的请求方式
- "GET"
- "POST"
- "DELETE"
- "PUT"
- "OPTIONS"
allowedHeaders: "*" # 允许在请求中携带的头信息
allowCredentials: true # 是否允许携带cookie
maxAge: 360000 # 这次跨域检测的有效期
server:
port: 10010
GateWay全局过滤器不生效的情况
问题描述: GateWay网关配置的全局过滤器不生效,检查后发现该过滤器已经成功添加到容器当中。
问题原因:
一定要匹配到了断言的请求,才会进入到过滤器当中,如果使用了loadbance负载均衡,还要保证那个服务必须在注册中心中存在。
Docker容器化技术
为什么要用?有哪些问题需要解决?为什么能够解决出现的问题?
- 因为我们需要管理项目中各个组件非常的繁琐,例如mysql、redis、nginx、elasticsearch、rabbitMQ等等一系列的,首先是**环境安装比较麻烦**。其次是在**不同的Linux环境下**可能导致不可用。
- 为什么Docker能够解决这些问题?
-
1、Docker把一个软件所需要的配置、运行环境、运行函数库通通进行了打包,形成了一个镜像,我们只需要通过镜像来创建一个个容器(应用程序)即可轻松完成环境的搭建
-
2、为什么能够跨不同的Linux平台仍然能运行? 因为它打包了程序运行所需要的函数库,是直接与Linux内核打交道的,与Linux到底是什么平台无关。
-
Docker在Linux上的下载与安装
卸载Docker(可选)
yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-selinux \
docker-engine-selinux \
docker-engine \
docker-ce
安装yum-utils工具(安装前最好配置一下yum的下载镜像)
yum install -y yum-utils \
device-mapper-persistent-data \
lvm2 --skip-broken
更新本地镜像源
# 设置docker镜像源
yum-config-manager \
--add-repo \
https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
sed -i 's/download.docker.com/mirrors.aliyun.com\/docker-ce/g' /etc/yum.repos.d/docker-ce.repo
yum makecache fast
安装Docker,并且关闭Linux防火墙、配置镜像加速器
yum install -y docker-ce
# 关闭
systemctl stop firewalld
# 禁止开机启动防火墙
systemctl disable firewalld
启动Docker并查看版本
systemctl start docker # 启动docker服务
systemctl stop docker # 停止docker服务
systemctl restart docker # 重启docker服务
docker -v # 查看docker版本
Docker的常用命令
与镜像有关的命令
- 构建镜像(用于dockerFile),后面的./只是个示例,标识dockerfile的文件地址
docker build ./
- 拉取镜像
docker pull mysql:5.7.2
- 删除镜像
docker rmi mysql:5.7.2
- 查看所有镜像
docker images
- 保存镜像
docker save -o mysqlBak.tar mysql:5.7.2
- 加载镜像
docker load -i mysqlBak.tar
与容器有关的命令
# 运行一个容器,--name当前容器名称,-d后台运行,最后跟 镜像:版本,将本机的80端口映射到容器的80端口
docker run --name mnginx -p 80:80 -d nginx
# 进入一个容器
docker exec -it mnginx bash
# 删除一个容器,-f代表强制删除
docker rm -f mnginx
# 查询当前所有的容器状态
docker ps -a
# 查看容器的日志
docker logs mnginx
# 开启容器 与 重启容器 与 关闭容器
docker start mnginx
docker restart mnginx
docker stop mnginx
# 暂时 与 解除暂停
docker pause
docker unpause
与数据卷相关的命令
# 创建一个数据卷
docker volumn create myHtml
# 删除指定数据卷 与 删除未使用的数据卷
docker volumn rm myHtml
docker volumn prune
# 列出已有的数据卷 与 查看指定的数据卷详情信息
docker volumn ls
docker volumn inspect myHtml
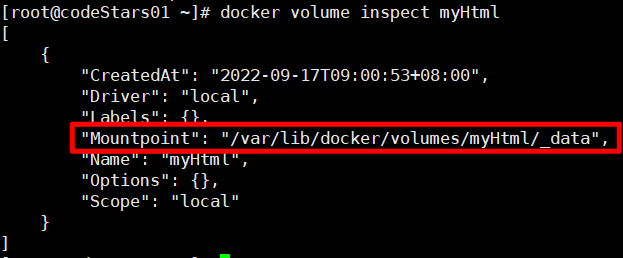
数据卷的默认地址
-
创建的数据卷默认放在:
/var/lib/docker/volumes/ -
测试一下
docker volume create myHtml
docker volume inspect myHtml
小案例(使用docker安装mysql 5.7.2)
-
拉取镜像
docker pull mysql:5.7.25 -
查看是否拉取成功
docker images -
执行如下命令完成运行
# -- name 为容器取名
# -e 配置容器的环境变量
# -v 配置数据卷, /etc/mysql/conf.d是容器中数据库的扩展配置, 顺便配置了数据目录
# -d 以后台方式运行
# 注意:/opt/dockerTest/mysql/myConf/my.cnf 这个是需要进行扩展的配置文件,可以自行定义
docker run --name mysql2\
-p 3306:3306\
-e MYSQL_ROOT_PASSWORD=abc123\
-v /opt/dockerTest/mysql/myConf/my.cnf:/etc/mysql/conf.d/my.cnf \
-v /opt/dockerTest/mysql/data:/var/lib/mysql \
-d mysql:5.7.25
- 扩展配置文件/opt/dockerTest/mysql/myConf/my.cnf
[mysqld]
skip-name-resolve
character_set_server=utf8 # mysql 5.7,一定要配置一下字符集
datadir=/var/lib/mysql # 这个地址很重要,因为在容器中,数据目录的地址就是这
server-id=1000
DockerFile自定义镜像
DockerFile文件的几大组成部分
-
(1)From 需要来自于哪个镜像作为初始镜像
-
(2)ENV 配置镜像所需的环境变量
-
(3)COPY 复制当前Linux系统的文件到镜像当中
-
(4)RUN 在镜像中运行一些指令
-
(5)EnterPoint 入口,指的是执行docker run 时会执行的命令
准备一个DockerFile文件,完成springBoot项目的搭建
-
随便打包一个springboot项目
-
准备一个jdk8的安装包
-
编写DockerFile文件
# 指定基础镜像
FROM ubuntu:16.04
# 配置环境变量,JDK的安装目录
ENV JAVA_DIR=/usr/local
# 拷贝jdk和java项目的包
COPY ./jdk8.tar.gz $JAVA_DIR/
COPY ./demo.jar /tmp/app.jar
# 安装JDK
RUN cd $JAVA_DIR \
&& tar -xf ./jdk8.tar.gz \
&& mv ./jdk1.8.0_144 ./java8
# 配置环境变量
ENV JAVA_HOME=$JAVA_DIR/java8
ENV PATH=$PATH:$JAVA_HOME/bin
# 暴露端口
EXPOSE 8080
# 入口,java项目的启动命令
ENTRYPOINT java -jar /tmp/app.jar
-
最终目录结构
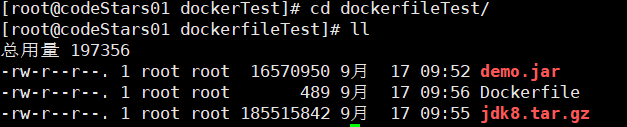
-
运行DockerFile文件
# -t 设置镜像的名称和版本 ./ 代表在当前目录找DockerFile文件
docker build -t javaweb:1.0 ./
- 通过docker命令运行该镜像
docker run --name myJar -p 8080:8080 -d javaweb:1.0
通过alpine来创建一个镜像
- 编写DockerFile文件
# 指定基础镜像, 该镜像已经安装好了JDK环境
FROM java:8-alpine
# 拷贝java项目的包
COPY ./demo.jar /tmp/app.jar
# 暴露端口
EXPOSE 8081
# 入口,java项目的启动命令,这里稍微修改了下启动参数,因为application.yml中配置的端口号是8080
ENTRYPOINT java -jar -Dserver.port=8081 /tmp/app.jar
-
拖一个java项目到当前目录下,改名为demo.jar
-
运行docker命令来构建
docker build -t javaweb:2.0 ./
- 创建该镜像的容器运行
docker run --name myJar2 -p 8081:8081 -d javaweb:2.0
docker-compose 快速部署多个分布式应用(DockerFile的集群版本,能够基于镜像创建容器,也能bulid一个镜像再创建容器)
下载与安装、修改文件权限、自动补全命令配置
- 通过如下命令下载,并且放在/usr/local/bin目录当中
# 安装
sudo curl -L "https://github.com/docker/compose/releases/download/v2.2.2/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
- 修改文件权限
chmod a+x /usr/local/bin/docker-compose
- 配置自动补全命令
部署微服务集群(示例)docker-compose up -d
准备项目的jar包(注意项目中的nacos与mysql地址)
# 修改的原因:由于待会打docker-compose中会配置指定的服务,可以让其通过服务访问
nacos地址需要修改:server-addr: nacos:8848
mysql地址需要修改:url: jdbc:mysql://mysql:3306/cloud_user?useSSL=false
如果最后阶段出现了message from server: "Host '172.25.0.2' is not allowed to connect to this MySQL server之类的错误
- 在出错的微服务的pom文件中的打包插件中添加如下内容后重新打包
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<!--加入下面两项配置-->
<executions>
<execution>
<goals>
<goal>repackage</goal>
</goals>
</execution>
</executions>
<configuration>
<includeSystemScope>true</includeSystemScope>
</configuration>
</plugin>
</plugins>
准备Dockerfile文件,每个微服务一份(注意需要修改的地方),注意端口号、文件名
# 指定基础镜像, 该镜像已经安装好了JDK环境
FROM java:8-alpine
# 拷贝java项目的包
COPY ./gateway-1.0.jar /tmp/app.jar
# 暴露端口
EXPOSE 10010
# 入口
ENTRYPOINT java -jar /tmp/app.jar
准备项目的mysql数据目录和配置文件(从开发环境下复制mysql的data目录,并收集其配置文件,注意user表的权限,需要开放能够远程访问)

- 配置文件如下(自行修改)
[mysqld]
skip-name-resolve
character_set_server=utf8 # mysql 5.7,一定要配置一下字符集
datadir=/var/lib/mysql # 这个地址很重要,因为在容器中,数据目录的地址就是这
server-id=1000
编写docker-compose.yml 文件
-
services标签下,就是一个个的容器名称
-
容器名称下面可以配置 所用到的镜像、环境变量、端口、数据卷等,甚至也可以通过DockerFile来构建对应的镜像再生成容器。(注意这里填写的服务名,将来可以使用docker-compose restart mysql nacos userservice)这样使用
version: "3.2"
services:
nacos:
image: nacos/nacos-server
environment:
MODE: standalone
ports:
- "8848:8848"
mysql:
image: mysql:5.7.25
environment:
MYSQL_ROOT_PASSWORD: abc123
volumes:
- "$PWD/mysql/data:/var/lib/mysql"
- "$PWD/mysql/my.cnf:/etc/mysql/conf.d/my.cnf"
userservice:
build: ./userservice
orderservice:
build: ./orderservice
gateway:
build: ./gateway
ports:
- "10010:10010"
检查当前的目录结构,并执行docker-compose命令
- 执行如下命令执行docker-compose.yml(注意先cd进入到目录结构当中)
# -d 代表后台方式运行
docker-compose up -d
# 可以通过如下命令查看日志
docker-compose logs -f
# 因为必须nacos先启动,但是它启动的比较慢,所以可能导致另外的服务启动失败,因此可以重启
docker-compose restart userservice gateway orderservice
搭建Docker镜像仓库
- 先安装registry镜像
docker pull registry
简化版(没有图形界面)
- 输入如下命令运行
docker run -d \
--restart=always \
--name registry \
-p 5000:5000 \
-v registry-data:/var/lib/registry \
registry
带图形化界面版(编写docker-compose.yaml文件、添加信任、执行文件)
- 编写一个docker-compose文件
version: '3.0'
services:
registry:
image: registry
volumes:
- ./registry-data:/var/lib/registry
ui:
image: joxit/docker-registry-ui:static
ports:
- 8888:80
environment:
- REGISTRY_TITLE=个人私有仓库
- REGISTRY_URL=http://registry:5000
depends_on:
- registry
- 添加信任地址

# 打开要修改的文件
vi /etc/docker/daemon.json
# 添加内容:别忘了逗号分割
"insecure-registries":["http://192.168.22.100:8888"]
# 重新加载
systemctl daemon-reload
# 重启docker
systemctl restart docker
- 运行即可
docker-compose up -d
往私人镜像仓库上传镜像 | 拉取镜像
- 重新tag本地镜像,名称前缀为私有仓库的地址
docker tag registry:latest 192.168.22.100:8888/registry:1.11
- 上传镜像
docker push 192.168.22.100:8888/registry:1.11
- 拉取镜像
docker pull 192.168.22.100:8888/registry:1.11

RabbitMQ 消息队列的使用(基于Docker安装)
同步通讯与异步通讯的各自优缺点
同步通讯
-
优点
- 实时性较强,可以立即得到结果
-
缺点
- 耦合度高
- 性能和吞吐能力下降
- 有额外的资源消耗
- 有级联失败的问题
异步通讯(流量削峰)
-
优点
- 吞吐量提升,无需等待订阅者处理完成,响应速度更快
- 故障隔离。服务没有直接调用,不存在级联失败问题(疑惑: 那么如果对方失败了,如何保证事物的一致性?)
- 调用间没有阻塞,不会造成无效的资源占用
- 耦合度较低,每个服务都可以灵活插拔
- 流量削峰。不管发生事件的流量波动多大,都由Broker中间商来接收,订阅者可以按照自己的处理速度去处理(需要小心中间商出问题)
-
缺点
- 架构复杂了,不好管理
- 需要依赖于Broker的可靠、安全、性能。
常见的集中MQ对比
几种常见MQ的对比:
| RabbitMQ | ActiveMQ | RocketMQ | Kafka | |
|---|---|---|---|---|
| 公司/社区 | Rabbit | Apache | 阿里 | Apache |
| 开发语言 | Erlang | Java | Java | Scala&Java |
| 协议支持 | AMQP,XMPP,SMTP,STOMP | OpenWire,STOMP,REST,XMPP,AMQP | 自定义协议 | 自定义协议 |
| 可用性 | 高 | 一般 | 高 | 高 |
| 单机吞吐量 | 一般 | 差 | 高 | 非常高 |
| 消息延迟 | 微秒级 | 毫秒级 | 毫秒级 | 毫秒以内 |
| 消息可靠性 | 高 | 一般 | 高 | 一般 |
追求可用性:Kafka、 RocketMQ 、RabbitMQ
追求可靠性:RabbitMQ、RocketMQ
追求吞吐能力:RocketMQ、Kafka
追求消息低延迟:RabbitMQ、Kafka
在Docker环境下载与安装RabbitMQ
- 获取RabbitMQ的docker镜像(mangement版本是包含web管理页面的)
docker pull rabbitmq:3-management
- 创建并运行容器
# 进行了端口的映射,5672是服务地址,15672是图形化管理界面
# 添加了一个数据卷映射,后期可以通过docker volumn inspect rabbitMqData查看信息
# 添加了虚拟主机,之后使用的时候,就写该虚拟主机,当然也可以在图形化界面再加一个
# 定义了管理界面的用户名和密码
# 以后台方式运行 -d
docker run --name rabbitmq3 \
-p 5672:5672 -p 15672:15672 \
-v rabbitMqData:/var/lib/rabbitmq \
--hostname myRabbit \
-e RABBITMQ_DEFAULT_VHOST=my_vhost \
-e RABBITMQ_DEFAULT_USER=admin \
-e RABBITMQ_DEFAULT_PASS=admin\
-d\
rabbitmq:3-management
RabbitMQ中的一些专业名词
-
publisher 生产者
-
consumer 消费者
-
exchange 交换机,负责消息的路由,可能会涉及到路由key
-
queue 队列,存储消息
-
virtualHost 虚拟主机,隔离不同用户使用的exchange、queue,使消息隔离
RabbitMQ的快速入门(使用原生API)
创建一个父工程,2个子工程,引入rabbitMQ的客户端依赖
- 引入依赖
<dependency>
<groupId>com.rabbitmq</groupId>
<artifactId>amqp-client</artifactId>
<version>5.6.0</version>
</dependency>
创建子工程Publisher生产者,编写一个类
public class MQPublisher {
public static void main(String[] args) throws Exception {
// 1、创建连接
ConnectionFactory factory = new ConnectionFactory();
// 1.1 设置链接参数
factory.setHost("192.168.22.100");
factory.setPort(5672);
factory.setUsername("admin");
factory.setPassword("admin");
factory.setVirtualHost("/");
// 1.2 建立连接
Connection connection = factory.newConnection();
// 2、创建通道
Channel channel = connection.createChannel();
// 3、创建队列
String queueName = "simple.queue";
channel.queueDeclare(queueName, false, false, false, null);
// 4、发送消息
String message = "你好呀";
channel.basicPublish("", queueName, null, message.getBytes());
System.out.println("消息发送成功:" + message);
// 5、关闭通道与连接
channel.close();
connection.close();
}
}
创建子工程Publisher消费者,编写一个类
public class MQConsumer {
public static void main(String[] args) throws Exception{
// 1、获取连接
ConnectionFactory factory = new ConnectionFactory();
// 1.1 设置连接参数
factory.setHost("192.168.22.100");
factory.setPort(5672);
factory.setUsername("admin");
factory.setPassword("admin");
factory.setVirtualHost("/");
// 1.2 建立连接
Connection connection = factory.newConnection();
// 2、 创建通道
Channel channel = connection.createChannel();
// 3、 创建队列
String queue = "simple.queue";
channel.queueDeclare(queue,false, false, false, null);
// 4、订阅消息
channel.basicConsume(queue, true ,new DefaultConsumer(channel){
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
System.out.println("获取到生产者发送的消息,开始消费:" + new String(body));
}
});
// 5、等待接收消息
System.out.println("主线程去忙别的了。~~");
}
}
使用SpringCloud中的AMQP
创建SpringBoot项目,引入SpringBoot及amqp启动器
<parent>
<artifactId>spring-boot-starter-parent</artifactId>
<groupId>org.springframework.boot</groupId>
<version>2.3.9.RELEASE</version>
</parent>
<!--AMQP依赖,包含RabbitMQ-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
配置application.yml(五步走)
spring:
rabbitmq:
host: 192.168.22.100
port: 5672
username: admin
password: admin
virtual-host: /
简单队列模型
-
通过一个单独的队列来完成消息的订阅与发送称为简单队列模型
-
消息发布者
@Test
public void publish() {
// 1、 准备消息
String message = "hello rabbitMQ";
// 2、 定义队列,routeKey好像就是队列
String queueName = "simple.queue";
// 3、发送消息
rabbitTemplate.convertAndSend(queueName, message);
System.out.println("发布者已经发布了消息:" + message);
}
- 消息发布者,编写如下代码监听队列,然后启动一下SpringBoot项目
@Component
public class SpringRabbitListener {
@RabbitListener(queues = "simple.queue")
public void listenSimpleQueue(String msg) {
System.out.println("消费者接收到消息:" + msg);
}
}
WrokQueue任务模型
-
该模型是多个消费者监听同一个队列,他们之间将会默认会很平均的分摊消费者发送的消息

-
发布者模块的代码可以稍微改动下,循环发送50条消息
@Test
public void publish() {
// 1、 准备消息
String message = "hello rabbitMQ";
// 2、 定义队列,routeKey好像就是队列
String queueName = "simple.queue";
// 3、发送消息
for (int i = 1; i <= 50; i++) {
rabbitTemplate.convertAndSend(queueName, message + i);
System.out.println("发布者已经发布了消息:" + message);
}
}
- 消费者模块需要再添加一个消费者
@Component
public class SpringRabbitListener {
@RabbitListener(queues = "simple.queue")
public void listenSimpleQueueConsumer1(String msg) {
System.out.println("消费者1号接收到消息:" + msg);
}
@RabbitListener(queues = "simple.queue")
public void listenSimpleQueueConsumer2(String msg) {
System.out.println("消费者2号接收到消息:" + msg + "-------------");
}
}
任务模型能者多劳的配置
-
从运行结果上看,发现2个任务所消费的消息数量均是一致的。
- 那是因为消费者在获取队列任务时,不管能不能执行完,先获取到再说
-
修改配置实现能者多劳
spring:
rabbitmq:
listener:
simple:
prefetch: 1 # 每次只能获取一条消息,处理完成才能获取下一个消息
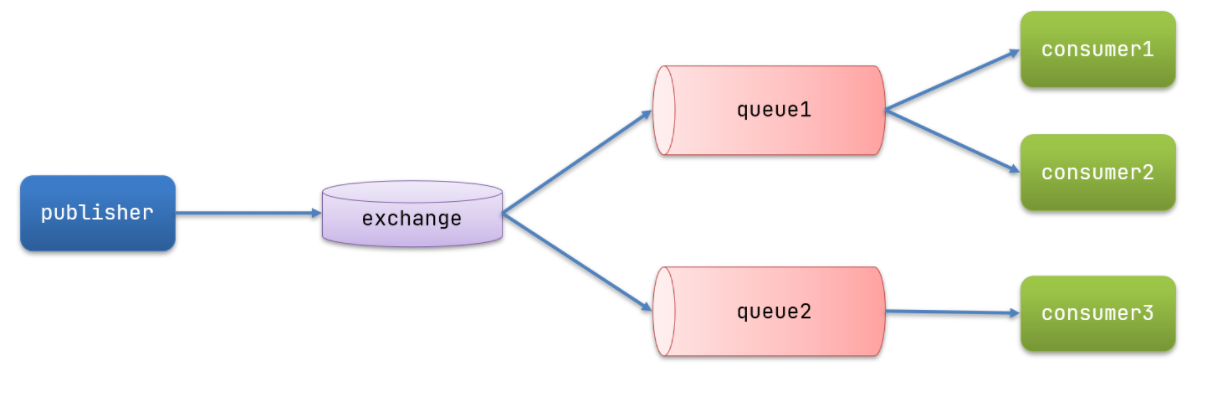
发布订阅模型概念解释
-
publisher 发布者,作用依然是发布消息,但是消息不再直接发送给queue了,而是发送给exchange
-
exchange 交换机,用于进行消息的路由,接收到publisher的消息后路由到指定的queue中
- fanout:广播,将消息路由给每所有绑定到了该交换机上的队列
- direct:定向,将消息路由给指定routeKey的队列
- Topic:通配符,将消息路由给指定routeKey的队列(但是可以使用通配符,#代表1个单词,*代表1个或多个单词)
-
queue 队列,用于进行数据的接收与缓存
-
consumer 消费者,作用一样,还是订阅队列
Fanout 广播发布订阅模型
在广播模式下,消息发送流程是这样的:
- 1) 可以有多个队列
- 2) 每个队列都要绑定到Exchange(交换机)
- 3) 生产者发送的消息,只能发送到交换机,交换机来决定要发给哪个队列,生产者无法决定
- 4) 交换机把消息发送给绑定过的所有队列
- 5) 订阅队列的消费者都能拿到消息
声明队列和交换机,使队列与交换机进行绑定
@Configuration
public class FanoutConfig {
/**
* 定义一个fanout交换机
* @return
*/
@Bean
public FanoutExchange fanoutExchange() {
return new FanoutExchange("fanoutExChange");
}
// 定义第一个队列
@Bean
public Queue queue1() {
return new Queue("fanout.queue1");
}
// 定义第一个绑定器,将队列与交换机绑定
@Bean
public Binding binding1 (FanoutExchange fanoutExchange, Queue queue1) {
return BindingBuilder.bind(queue1).to(fanoutExchange);
}
// 定义第二个队列
@Bean
public Queue queue2() {
return new Queue("fanout.queue2");
}
// 定义第二个绑定器,将队列与交换机绑定
@Bean
public Binding binding2 (FanoutExchange fanoutExchange, Queue queue2) {
return BindingBuilder.bind(queue2).to(fanoutExchange);
}
}
发布者发布消息给交换机
@Test
public void publishFanout() {
// 1、 准备消息
String message = "hello direct exchange";
// 2、定义交换机名称
String exChangeName = "fanoutExchange";
// 3、发送消息。中间那个没填的参数是 routingkey
rabbitTemplate.convertAndSend(exChangeName, "", message);
}
消费者监听队列消费消息
@Component
public class FanoutConsumer {
@RabbitListener(queues = "fanout.queue1")
public void receiveMessageFromQueue1(String message) {
System.out.println("Received message from Queue 1: " + message);
}
@RabbitListener(queues = "fanout.queue2")
public void receiveMessageFromQueue2(String message) {
System.out.println("Received message from Queue 2: " + message);
}
}
FanOut广播方式的总结(交换机的作用,会使用到的Bean)
交换机的作用是什么?
- 接收publisher发送的消息
- 将消息按照规则路由到与之绑定的队列
- 不能缓存消息,路由失败,消息丢失
- FanoutExchange的会将消息路由到每个绑定的队列
声明队列、交换机、绑定关系的Bean是什么?
- Queue
- FanoutExchange
- Binding
Direct定向发布订阅模型
- Direct模型中,发布者依然是发送消息给ExChange,但不同的是,ExChange只会将消息路由给指定routingkey的队列(前提也得是与交换机进行了绑定)。
发布者发布消息,需要指定routingkey和交换机
@Test
public void publishDirect() {
// 1、 准备消息
String message = "hello direct exchange";
// 2、定义交换机名称
String exChangeName = "directExChange";
// 3、发送消息。中间那个没填的参数是 routingkey
rabbitTemplate.convertAndSend(exChangeName, "red", message);
}
消费者消费消息,这里采用注解的方式完成队列与交换机的绑定(别忘了交换机的类型)
@Component
public class SpringRabbitListenerDirect {
// 消费者1号,监听direct.queue1 队列,与此同时接收routingkey为blue和red的消息
@RabbitListener(
bindings = @QueueBinding(
value = @Queue("direct.queue1"),
exchange = @Exchange(value = "directExChange", type = ExchangeTypes.DIRECT),
key = {"blue", "red"}
)
)
public void listenDirectConsumer1(String msg) {
System.out.println("消费者1号接收到消息:" + msg);
}
// 消费者2号,监听direct.queue2 队列,与此同时接收routingkey为blue消息
@RabbitListener(
bindings = @QueueBinding(
value = @Queue("direct.queue2"),
exchange = @Exchange(value = "directExChange", type = ExchangeTypes.DIRECT),
key = {"blue"}
)
)
public void listenDirectConsumer2(String msg) {
System.out.println("消费者2号接收到消息:" + msg);
}
}
Topic消费订阅模型
- 与direct唯一的区别就是,定义routingkey的时候可以使用通配符了。
配置队列与交换机的关系
@Configuration
public class TopicConfig {
/**
* 定义一个topic交换机
* @return
*/
@Bean
public TopicExchange topicExchange() {
return new TopicExchange("topicExChange");
}
// 定义第一个队列
@Bean
public Queue queue1() {
return new Queue("topic.queue1");
}
// 定义第一个绑定器,将队列与交换机绑定
// 为queue1配置china.#这个routingkey,能匹配chain.开头的routingkey,但是一个#仅能代表一个单词
@Bean
public Binding binding1 (TopicExchange topicExchange, Queue queue1) {
return BindingBuilder.bind(queue1).to(topicExchange).with("china.#");
}
// 定义第二个队列
@Bean
public Queue queue2() {
return new Queue("topic.queue2");
}
// 定义第二个绑定器,将队列与交换机绑定,
// 为queue2配置china.news这个routingkey,能匹配chain.开头的任意routingkey
@Bean
public Binding binding2 (TopicExchange topicExchange, Queue queue2) {
return BindingBuilder.bind(queue2).to(topicExchange).with("china.*");
}
}
发布者发布消息,与Direct一致
@Test
public void publishTopic() {
// 2、定义交换机名称
String exChangeName = "topicExChange";
// 3、发送消息。中间那个没填的参数是 routingkey,china.# 和 china.* 都能接收到
rabbitTemplate.convertAndSend(exChangeName, "china.study", "chind.study 消息");
// 3、发送消息。中间那个没填的参数是 routingkey,china.# 能接收到
rabbitTemplate.convertAndSend(exChangeName, "china.study.news", "chind.study.news 消息");
}
消费者消费消息
@Component
public class SpringRabbitListenerTopic {
// 消费者1号,监听topic.queue1 队列
@RabbitListener(queues = "topic.queue1")
public void listenTopicConsumer1(String msg) {
System.out.println("消费者1号接收到消息:" + msg);
}
// 消费者2号,监听topic.queue2 队列
@RabbitListener(queues = "topic.queue2")
public void listenTopicConsumer2(String msg) {
System.out.println("消费者2号接收到消息:" + msg);
}
}
使用JackSon的消息转换器
-
为什么需要使用到消息转换器?
-
因为通过rabbitMQ的图形化界面工具来查看发布者发送的消息,可以看到是使用application/x-java-serialized-object形式来发送与接收的
-
因此将其转换成了一个很长的字符串, 非常的耗费内存。
-
因此可以通过自定义转换器的方式,使其以 application/json的格式来发送与接收
-
-
引入jackson的依赖,如下2个都可以
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-json</artifactId>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.dataformat</groupId>
<artifactId>jackson-dataformat-xml</artifactId>
<version>2.9.10</version>
</dependency>
- 配置消息转换器,在消费者模块和发布者模块都配置如下的Bean
@Bean
public MessageConverter jsonMessageConverter(){
return new Jackson2JsonMessageConverter();
}
ElasticSearch分布式搜索
ElasticSearch的常见概念(索引、映射、文档、字段、DSL、ELK、倒排索引等、分片及副本)
- ElasticSearch的概念与Mysql中的概念对比
| MYSQL | ElasticSearch |
|---|---|
| table | index |
| 记录 | 文档 |
| cloumn | field |
| check | mapping |
| SQL | DSL |
-
ELK 表示辅助ElasticSearch使用的三件套
- E,ElasticSearch
- L,Logstash和Beats 完成分布式日志管理
- K,Kibana 日志统计展示与数据可视化
-
倒排索引
- 说到倒排索引就不得不说到我们的正向索引,向MYSQL使用的就是正向索引,以ID或二级字段作为关键字而构建的索引。
-
倒排索引
- 以文档数据的字或词来作为索引,以文档的ID作为该索引对应的值,一个索引可以对应多个文档ID
- 以ik分词器: “今天天气真好”,“昨天天气也真好”,2个文档为例,假设他们的id为1跟2
| 索引列 | 对应的id |
|---|---|
| 今天 | 1 |
| 天气 | 1,2 |
| 真好 | 1,2 |
| 昨天 | 2 |
| 也 | 2 |
- 分片
- 一般在集群当中才会有分片的概念,分片相当于存储数据的节点
- 而分片一般都会对应着副本
- 集群环境下,一定需要保证正在运行的服务器可以获取到所有分片的数据。
ElasticSearch的下载与安装(采用docker,注意与ES同一个网络)
- 使用docker命令获取相对应的镜像
docker pull elasticsearch:7.12.1
- 创建一个自定义的docker网络,使其网络内的容器可以相互连接
docker network create es-net
- 创建容器并启动,启动后访问
http://192.168.22.100:9200/即可看到响应
docker run -d \
--name es \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-v es-data:/usr/share/elasticsearch/data \
-v es-plugins:/usr/share/elasticsearch/plugins \
--privileged \
--network es-net \
-p 9200:9200 \
-p 9300:9300 \
elasticsearch:7.12.1
命令解释:
-e "cluster.name=es-docker-cluster":设置集群名称-e "http.host=0.0.0.0":监听的地址,可以外网访问-e "ES_JAVA_OPTS=-Xms512m -Xmx512m":内存大小-e "discovery.type=single-node":非集群模式-v es-data:/usr/share/elasticsearch/data:挂载逻辑卷,绑定es的数据目录-v es-logs:/usr/share/elasticsearch/logs:挂载逻辑卷,绑定es的日志目录-v es-plugins:/usr/share/elasticsearch/plugins:挂载逻辑卷,绑定es的插件目录--privileged:授予逻辑卷访问权--network es-net:加入一个名为es-net的网络中-p 9200:9200:端口映射配置
安装Kibana可视化界面工具
- 使用docker获取镜像
docker pull kibana:7.12.1
- 创建容器并运行
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=es-net \
-p 5601:5601 \
kibana:7.12.1
--network es-net:加入一个名为es-net的网络中,与elasticsearch在同一个网络中-e ELASTICSEARCH_HOSTS=http://es:9200":设置elasticsearch的地址,因为kibana已经与elasticsearch在一个网络,因此可以用容器名直接访问elasticsearch-p 5601:5601:端口映射配置
kibana启动一般比较慢,需要多等待一会,可以通过命令:
docker logs -f kibana
- 访问如下网址打开图形化界面
http://192.168.22.100:5601/
# 如下地址可以打开 开发者工具,可以向elasticsearch发送请求
http://192.168.22.100:5601/app/dev_tools#/console
安装IK分词器
-
IK分词器有2种
ik_smart:最大粒度分次,能4个字分成一个此就不会分成3个ik_max_word:最细切分,与ik_smart相反
-
在线安装ik插件(较慢)
# 进入容器内部
docker exec -it elasticsearch /bin/bash
# 在线下载并安装
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip
#退出
exit
#重启容器
docker restart elasticsearch
- 离线安装ik插件
- 先通过先前的设置查看当前数据卷所在的地址
docker volume ls docker volume inspect es-plugins- 进入到该插件目录,将下载好的IK插件解压后放进去
- 重启es即可生效
配置IK分词器忽略词 以及 添加一些词语
- 修改ik分词器config目录下的
IKAnalyzer.cfg.xml
# 注意 ext.dic 和 stopword.dic
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">ext.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">stopword.dic</entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
- 就在当前config目录下创建
ext.dic文件,一个词语按一个回车即可,最后不用留空行
白嫖
奥利给
疾风剑豪
亚索
- 重启es即可
docker restart es
部署ES集群
- 编写一个docker-compose.yml文件
version: '2.2'
services:
es01:
image: docker.elastic.co/elasticsearch/elasticsearch:7.12.1
container_name: es01
environment:
- node.name=es01
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es02,es03
- cluster.initial_master_nodes=es01,es02,es03
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- data01:/usr/share/elasticsearch/data
ports:
- 9200:9200
networks:
- elastic
es02:
image: docker.elastic.co/elasticsearch/elasticsearch:7.12.1
container_name: es02
environment:
- node.name=es02
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es03
- cluster.initial_master_nodes=es01,es02,es03
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- data02:/usr/share/elasticsearch/data
networks:
- elastic
es03:
image: docker.elastic.co/elasticsearch/elasticsearch:7.12.1
container_name: es03
environment:
- node.name=es03
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es02
- cluster.initial_master_nodes=es01,es02,es03
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- data03:/usr/share/elasticsearch/data
networks:
- elastic
volumes:
data01:
driver: local
data02:
driver: local
data03:
driver: local
networks:
elastic:
driver: bridge
- 直接运行
docker-compose up
索引库操作
mapping映射属性
-
mapping映射是对索引库内文档的约束,常见的mapping映射属性有:
- type 字段类型
- 字符型: text(全文检索),keyword(精确值,例如品牌、国家、ip地址等不可分割)
- 数值型: integer、long、short、byte、double、float
- 布尔: boolean
- 日期: date
- 对象: object
- index 是否创建索引
- analyzr:使用哪种分词器,默认为standard
- properties: 字段的子字段
- type 字段类型
-
mapping映射的使用语法
PUT /myindex
{
"mappings": {
"properties": {
"name": {
"type": "keyword",
"index": true
},
"age": {
"type": "short",
"index": false
}
}
}
}
创建索引库和映射(索引别写大写)
- 使用示例
PUT /myindex
{
"mappings": {
"properties": {
"name": {
"type": "keyword",
"index": true
},
"age": {
"type": "short",
"index": false
}
}
}
}
查询索引库
GET /myindex
修改索引库(添加mapping字段,注意请求的josn是否要携带mappings)
-
索引库一旦建立之后,无法对其中的字段进行修改
-
但是可以添加新的字段,示例如下
PUT /myindex/_mapping
{
"properties": {
"info" : {
"type": "text",
"index": true,
"analyzer": "ik_max_word"
}
}
}
删除索引库
DELETE /myindex
总结
-
索引库的增删改查均使用RestFul风格的请求
-
新增和修改使用:
PUT /indexName {请求体}- 修改时,需要 put /indexName_mapping,并且请求体不再需要mappings包裹
-
删除使用:
DELETE /indexName -
查询:
GET /indexName
文档操作
- 测试之前,先创建如下索引库
PUT /myindex
{
"mappings": {
"properties": {
"name": {
"type": "keyword",
"index": true
},
"age": {
"type": "short",
"index": false
},
"info": {
"type": "text",
"analyzer": "ik_smart"
}
}
}
}
新增文档(POST与PUT)
POST /myindex/_doc/1
{
"name": "张三",
"age": 18,
"info": "这是一个非常可爱的孩子,法外狂徒~~"
}
# 若文档ID存在,则覆盖掉原本ID为1的文档(字段只会剩下覆盖后的)。
# 若文档ID不存在,则相当于新增
PUT /myindex/_doc/1
{
"name": "张三",
"age": 88
}
删除文档
DELETE /myindex/_doc/1
修改文档
全量修改
# 文档ID存在则为修改
PUT /myindex/_doc/1
{
"name": "张三",
"age": 88
}
增量修改
POST /myindex/_update/1
{
"doc": {
"name": "张三",
"age": 11
}
}
查询文档
GET /myindex/_doc/1
RestAPI 使用Java来完成对索引库的增删改查、文档的增删改查
创建一个SpringBoot工程,引入如下依赖,并解决依赖仲裁问题
<properties>
<java.version>1.8</java.version>
<elasticsearch.version>7.12.1</elasticsearch.version>
</properties>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>
初始化RestClient完成对索引库的操作
- 初始化RestClient
private RestHighLevelClient restHighLevelClient;
@BeforeEach
public void before() {
restHighLevelClient = new RestHighLevelClient(
RestClient.builder(HttpHost.create("http://192.168.22.100:9200"))
);
}
@AfterEach
void tearDown() throws IOException {
this.client.close();
}
新增索引库
String MAPPING_TEMPLATE = "{\n" +
" \"mappings\": {\n" +
" \"properties\": {\n" +
" \"name\": {\n" +
" \"type\": \"text\",\n" +
" \"analyzer\": \"ik_smart\"\n" +
" }\n" +
" }\n" +
" }\n" +
"}";
@Test
void addIndex() throws IOException {
// 1、准备request对象
CreateIndexRequest request = new CreateIndexRequest("hotel");
// 2、封装DSL
request.source(MAPPING_TEMPLATE, XContentType.JSON);
// 3、发送请求
restHighLevelClient.indices().create(request, RequestOptions.DEFAULT);
}
删除索引库
@Test
void deleteIndex() throws IOException {
// 1、准备request对象
DeleteIndexRequest request = new DeleteIndexRequest("hotel");
// 2、发送请求
restHighLevelClient.indices().delete(request, RequestOptions.DEFAULT);
}
判断索引是否存在
@Test
void testExistsIndex() throws IOException {
// 1、准备request对象
GetIndexRequest request = new GetIndexRequest("hotel");
// 2、发送请求
boolean isExists = restHighLevelClient.indices().exists(request, RequestOptions.DEFAULT);
// 3、处理请求
System.out.println(isExists ? "索引存在" : "索引不存在");
}
查询索引库
@Test
void testExistsIndex() throws IOException {
// 1、准备request对象
GetIndexRequest request = new GetIndexRequest("hotel");
// 2、发送请求
GetIndexResponse response = restHighLevelClient.indices().get(request, RequestOptions.DEFAULT);
// 3、处理请求,这里可以通过response获取到索引的信息
System.out.println(response);
}
完成对文档的操作
新增文档
@Test
void testInsertDocument() throws IOException {
// 1、从数据库中查询一条数据
Hotel hotel = hotelService.getById(36934);
// 2、转换为文档类型
HotelDoc hotelDoc = new HotelDoc(hotel);
// 3.将HotelDoc转json
String json = JSON.toJSONString(hotelDoc);
// 1、准备request对象
IndexRequest request = new IndexRequest("hotel").id("1");
// 2、封装DSL
request.source(json,XContentType.JSON);
// 3、发送请求
restHighLevelClient.index(request, RequestOptions.DEFAULT);
}
删除文档
@Test
void testDeleteDocument() throws IOException {
// 1、准备request对象
DeleteRequest request = new DeleteRequest("hotel").id("1");
// 2、发送请求
restHighLevelClient.delete(request, RequestOptions.DEFAULT);
}
修改文档(增量,并且如果ID不存在则为新增)
@Test
void testUpdateDocument() throws IOException {
// 1、准备request对象
UpdateRequest request = new UpdateRequest("hotel", "2");
// 2、封装DSL,这个是增量修改
request.doc(
"price",1999,
"startName","四钻"
);
// 2、发送请求
restHighLevelClient.update(request, RequestOptions.DEFAULT);
}
查询文档
@Test
void testGetDocument() throws IOException {
// 1、准备request对象
GetRequest request = new GetRequest("hotel").id("2");
// 2、发送请求
GetResponse response = restHighLevelClient.get(request, RequestOptions.DEFAULT);
// 3、处理结果
String json = response.getSourceAsString();
// 3.1、将结果封装成实体类对象
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
System.out.println(hotelDoc);
}
批量插入文档
@Test
void testBulkDocument() throws IOException {
// 1、准备数据
List<Hotel> hotelList = hotelService.list();
// 2、将其封装成HotelDoc对象
List<HotelDoc> hotelDocList = hotelList.stream().map(HotelDoc::new).collect(Collectors.toList());
// 3、准备request对象
BulkRequest request = new BulkRequest("hotel");
// 4、封装DSL
hotelDocList.forEach(hotelDoc -> {
request.add(new IndexRequest()
.source(JSON.toJSONString(hotelDoc), XContentType.JSON)
.id(hotelDoc.getId().toString()));
});
// 5、发送请求
restHighLevelClient.bulk(request, RequestOptions.DEFAULT);
}
查询文档
SQL查询的分类
-
查询所有: match all
-
全文检索: match_query、multi_match_query
-
精确查询: trem_query、range_query、ids
-
地理查询: geo_distance、geo_bounding_box
-
复合查询: bool 、 function score
全文检索查询
-
适用范围: 需要根据用户输入的词条查询倒排索引时的情况
-
一般常见场景: 京东的搜索框、百度的搜索框
-
match_all示例
GET /hotel/_search
{
"query": {
"match_all": {}
}
}
match查询示例
- 查询语法
GET /indexName/_search
{
"query": {
"match": {
"FIELD": "TEXT"
}
}
}
- 查询示例
GET /hotel/_search
{
"query": {
"match": {
"all": "如家外滩"
}
}
}
multi_match查询示例
- 查询语法
GET /indexName/_search
{
"query": {
"multi_match": {
"query": "TEXT",
"fields": ["Field1","Field2","Field3"]
}
}
}
- 查询示例
GET /hotel/_search
{
"query": {
"multi_match": {
"query": "如家",
"fields": ["city","brand","name"]
}
}
}
精确查询
trem关键字查询
GET /hotel/_search
{
"query": {
"term": {
"city": "北京"
}
}
}
range范围查询
GET /hotel/_search
{
"query": {
"range": {
"price": {
"gte": 100,
"lte": 300
}
}
}
}
地理坐标查询
矩形范围查询
GET /hotel/_search
{
"query": {
"geo_bounding_box": {
"location": {
"top_left": {
"lat": 31.5,
"lon": 121.48
},
"bottom_right": {
"lat": 31.4,
"lon": 121.24
}
}
}
}
}
附近查询
GET /hotel/_search
{
"query": {
"geo_distance": {
"distance": "15km",
"location": "31.2, 121.48"
}
}
}
复合查询
相关性算分
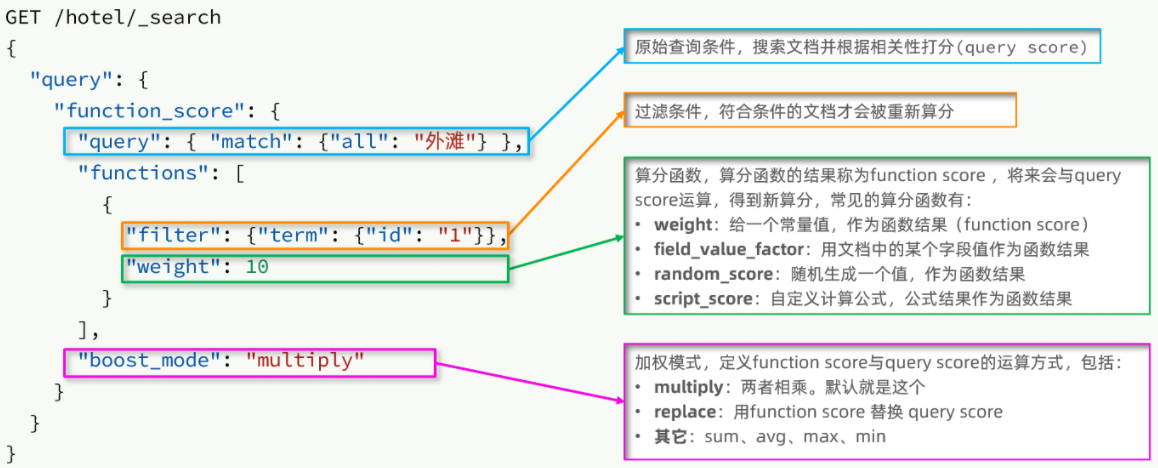
- 这个例子中,相当于把城市为上海,倒排索引中有如家|外滩的,分数都乘以了10倍
GET /hotel/_search
{
"query": {
"function_score": {
"query": {
"match": {
"all": "如家外滩"
}
},
"functions": [
{
"filter": {"term": {"city": "上海"}},
"weight": 10
}
],
"boost_mode": "multiply"
}
}
}
布尔查询(复合,注意畸形查询问题)
-
must: 必须要满足的条件(参与算分)
-
should:选择性匹配,(参与算分,相当于或)
-
must_not: 必须不匹配。不参与算分,类似于非
-
filter: 必须匹配,不参与算分
-
使用示例
GET /hotel/_search
{
"query": {
"bool": {
"must": [
{"term": {"city": "上海" }}
],
"should": [
{"term": {"brand": "皇冠假日" }},
{"term": {"brand": "华美达" }}
],
"must_not": [
{ "range": { "price": { "lte": 500 } }}
],
"filter": [
{ "range": {"score": { "gte": 45 } }}
]
}
}
}
搜索结果处理
排序(与query同级)
普通字段排序
GET /hotel/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"starName": {
"order": "desc"
}
},
{
"price": {
"order": "asc"
}
}
]
}
地理坐标排序
- 根据经纬度升序排序
- unit:最后能看到一个sort字段,可以看到距离有多少km
GET /hotel/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"_geo_distance": {
"location": {
"lat": 22.533753,
"lon": 114.122491
},
"order": "asc",
"unit": "km"
}
}
]
}
分页
基本分页
-
form 相当于mysql中limit的偏移量
-
size 需要显示多少条记录
GET /hotel/_search
{
"query": {
"match_all": {}
},
"from": 5,
"size": 5
}
深度分页
- 当查询分页深度较大时,汇总数据过多,对内存和CPU会产生非常大的压力,因此elasticsearch会禁止from+ size 超过10000的请求。
# 超过1万,直接报错
GET /hotel/_search
{
"query": {
"match_all": {}
},
"from": 9991,
"size": 10
}
- 官方提供了2种解决方案
- search after:分页时需要排序,原理是从上一次的排序值开始,查询下一页数据。官方推荐使用的方式。(无法往上翻页)
- scroll:原理将排序后的文档id形成快照,保存在内存。官方已经不推荐使用。
高亮
高亮原理及演示(搜索条件必须带关键字)
-
原理: 将匹配到的倒排索引单独领出来放在响应体的一个字段当中,默认会为其添加上em这个标签。当然标签也可以自定义。
-
注意事项
- 高亮是对关键字高亮,因此搜索条件必须带有关键字(比如range),而不能是范围这样的查询。
- 默认情况下,高亮的字段,必须与搜索指定的字段一致,否则无法高亮
- 如果要对非搜索字段高亮,则需要添加一个属性:required_field_match=false
-
使用示例
GET /hotel/_search
{
"query": {
"match": {
"all": "上海"
}
},
"highlight": {
"fields": {
"name": {
"require_field_match": "false"
}
}
}
}
RestClinet 查询文档(默认只能查询10条记录,注意size)
全文检索查询match
- 封装一个方法,用来处理响应结果
@Test
void testMatchAll() throws IOException {
// 1、准备requets
SearchRequest searchRequest = new SearchRequest("hotel");
// 2、封装DSL
MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();
searchRequest.source().query(matchAllQueryBuilder).size(100);
// 3、发送请求
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 4、处理响应结果
handlerResponse(response);
}
- match_all查询
@Test
void testMatchAll() throws IOException {
// 1、准备requets
SearchRequest searchRequest = new SearchRequest("hotel");
// 2、封装DSL
MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();
// 2.2 这里添加了size是希望查询出100条数据,不然默认只能查询出一条
searchRequest.source().query(matchAllQueryBuilder).size(100);
// 3、发送请求
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 4、处理响应结果
handlerResponse(response);
}
- match 查询
@Test
void testMatch() throws IOException {
// 1、准备requets
SearchRequest searchRequest = new SearchRequest("hotel");
// 2、封装DSL
MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("all", "上海");
searchRequest.source().query(matchQueryBuilder);
// 3、发送请求
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 4、处理响应结果
handlerResponse(response);
}
精确查询(term、range)
- term 精确查询QueryBuilders.termQuery()
@Test
void testTerm() throws IOException {
// 1、准备requets
SearchRequest searchRequest = new SearchRequest("hotel");
// 2、封装DSL
searchRequest.source().query(QueryBuilders.termQuery("city","北京")).size(100);
// 3、发送请求
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 4、处理响应结果
handlerResponse(response);
}
- range范围查询
@Test
void testRange() throws IOException {
// 1、准备requets
SearchRequest searchRequest = new SearchRequest("hotel");
// 2、封装DSL
searchRequest.source().query(QueryBuilders.rangeQuery("price").lte(300));
// 3、发送请求
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 4、处理响应结果
handlerResponse(response);
}
地理查询(geo_bounding_box、geodistance)
- 矩形范围查询geoBoundingBoxQuery
@Test
void testGeoBoundingBox() throws IOException {
// 1、准备requets
SearchRequest searchRequest = new SearchRequest("hotel");
// 2、封装DSL
GeoBoundingBoxQueryBuilder geoBoundingBoxQueryBuilder = QueryBuilders.geoBoundingBoxQuery("location");
geoBoundingBoxQueryBuilder.topLeft().reset(31.5, 121.48);
geoBoundingBoxQueryBuilder.bottomRight().reset(31.4, 121.24);
searchRequest.source().query(geoBoundingBoxQueryBuilder);
// 3、发送请求
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 4、处理响应结果
handlerResponse(response);
}
- 中心原点距离查询geoDistanceQuery
@Test
void testGeoDistance() throws IOException {
// 1、准备requets
SearchRequest searchRequest = new SearchRequest("hotel");
// 2、封装DSL
GeoDistanceQueryBuilder geoDistanceQueryBuilder = QueryBuilders
// 经纬度字段
.geoDistanceQuery("location")
// 设置维度、 经度
.point(31.4, 121.24)
// 设置查询距离中心原点 100km 范围内的
.distance("100", DistanceUnit.KILOMETERS);
searchRequest.source().query(geoDistanceQueryBuilder);
// 3、发送请求
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 4、处理响应结果
handlerResponse(response);
}
复合查询(score_function,bool),布尔的must和should如果存在相同匹配,则根据must的来
- 算分查询
@Test
void testFunctionScore() throws IOException {
// 1、准备requets
SearchRequest searchRequest = new SearchRequest("hotel");
// 2、封装DSL
FunctionScoreQueryBuilder functionScoreQueryBuilder = QueryBuilders.functionScoreQuery(
// 原始查询
QueryBuilders.matchQuery("all", "如家外滩"),
new FunctionScoreQueryBuilder.FilterFunctionBuilder[]{
new FunctionScoreQueryBuilder.FilterFunctionBuilder(
// 过滤条件,只对满足过滤条件的进行算分
QueryBuilders.termQuery("city","北京"),
// 定义算分规则,这里采用weight指定算分结果
ScoreFunctionBuilders.weightFactorFunction(10)
)
}
);
searchRequest.source().query(functionScoreQueryBuilder);
// 3、发送请求
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 4、处理响应结果
handlerResponse(response);
}
- bool布尔查询
@Test
void testBool() throws IOException {
// 1、准备requets
SearchRequest searchRequest = new SearchRequest("hotel");
// 2、封装DSL
BoolQueryBuilder boolQueryBuilder = QueryBuilders
.boolQuery()
.must(QueryBuilders.termQuery("city", "北京"))
.should(QueryBuilders.termQuery("brand", "君悦"))
.filter(QueryBuilders.matchQuery("name", "如家"))
.mustNot(QueryBuilders.rangeQuery("price").gte(1000));
searchRequest.source().query(boolQueryBuilder);
// 3、发送请求
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 4、处理响应结果
handlerResponse(response);
RestClient 搜索结果处理
排序
@Test
void testSort() throws IOException {
// 1、准备requets
SearchRequest searchRequest = new SearchRequest("hotel");
// 2、封装DSL
searchRequest.source().sort("price", SortOrder.DESC);
// 3、发送请求
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 4、处理响应结果
handlerResponse(response);
}
分页
@Test
void testPage() throws IOException {
// 0、准备分页数据
int pageNo = 2;
int pageSize = 5;
// 1、准备requets
SearchRequest searchRequest = new SearchRequest("hotel");
// 2、封装DSL
searchRequest.source()
.from((pageNo - 1) * pageSize)
.size(pageSize);
// 3、发送请求
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 4、处理响应结果
handlerResponse(response);
}
高亮
@Test
void testhignLigter() throws IOException {
// 0、准备分页数据
int pageNo = 2;
int pageSize = 5;
// 1、准备requets
SearchRequest searchRequest = new SearchRequest("hotel");
// 2、封装DSL
// 2.1 先根据关键字查询
searchRequest.source().query(QueryBuilders.matchQuery("all", "如家"));
// 2.2 设置高亮
searchRequest.source().highlighter(new HighlightBuilder().field("name").requireFieldMatch(false));
// 3、发送请求
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 4、处理响应结果
handlerResponse(response);
}
/**
* 处理响应结果
*
* @param response
*/
private void handlerResponse(SearchResponse response) {
SearchHit[] hits = response.getHits().getHits();
List<HotelDoc> list = new ArrayList<>();
for (SearchHit hit : hits) {
// 获取到每一条记录
String record = hit.getSourceAsString();
// 封装成HotelDoc对象
HotelDoc hotelDoc = JSON.parseObject(record, HotelDoc.class);
// 处理高亮字段
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
// 1、健壮性判断,判断Map集合是否为空
if(! CollectionUtils.isEmpty(highlightFields)) {
// 2、获取到高亮字段结果
HighlightField nameFiled = highlightFields.get("name");
// 3、判断结果是否为空
if(ObjectUtils.isNotEmpty(nameFiled)) {
// 获取到高亮的具体结果:Text
Text[] fragments = nameFiled.getFragments();
// 由于只需要获取到数组中第一个元素赋值,因此判断下
if (fragments.length > 0) {
hotelDoc.setName(fragments[0].string());
}
}
}
// 存储
list.add(hotelDoc);
}
list.forEach(System.out::println);
}
数据聚合aggregations
聚合的种类(3类,参加聚合的字段必须是keyword、日期、数值、布尔类型)
-
桶聚合(Bucket)
- TermAggregation : 按照文档字段进行聚合,类似于MYSQL的分组
- DateAggregation: 按照日期进行聚合,例如一周、一个月为一组
-
度量聚合(Metric)
- max
- min
- avg
- stats:同时求 最大、最小、平均
-
管道聚合(pipeline):以其他聚合的结果为基础进行聚合
使用DSL实现聚合(聚合名称、聚合字段、排序字段、显示个数)
Bucket桶聚合(有点像分组统计Count)
GET /hotel/_search
{
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 10
}
}
}
}
// 解释
GET /hotel/_search
{
"size": 0, // 设置size为0,结果中不包含文档,只包含聚合结果
"aggs": { // 定义聚合
"brandAgg": { //给聚合起个名字
"terms": { // 聚合的类型,按照品牌值聚合,所以选择term
"field": "brand", // 参与聚合的字段
"size": 20 // 希望获取的聚合结果数量
}
}
}
}
- 结果解析
统计结果按照统计数量升序排序
- 默认是按照统计数量降序排的,可以进行修改
GET /hotel/_search
{
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 10,
"order": {
"_count": "asc"
}
}
}
}
}
限定聚合范围查询
GET /hotel/_search
{
"size": 0,
"query": {
"term": {
"city": "北京"
}
},
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 10,
"order": {
"_count": "desc"
}
}
}
}
}
Metric聚合
- 按照评分,统计其 最大值、最小值、平均值、个数、总和
GET /hotel/_search
{
"size": 0,
"query": {
"term": {
"city": "北京"
}
},
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 10,
"order": {
"_count": "desc"
}
}
}
}
}
桶排序嵌套聚合分组,桶排序甚至可以使用嵌套的聚合分组的字段来进行排序
GET /hotel/_search
{
"size": 0,
"query": {
"term": {
"city": "北京"
}
},
"aggs": {
"bucketAgg": {
"terms": {
"field": "brand",
"size": 10,
"order": {
"scoreAgg.avg": "desc"
}
},
"aggs": {
"scoreAgg": {
"stats": {
"field": "score"
}
}
}
}
}
}
使用RestAPI实现聚合
桶Bucket聚合之Term
@Test
void testBucketTermAgg() throws IOException {
// 1、准备requets
SearchRequest searchRequest = new SearchRequest("hotel");
// 2、封装DSL
searchRequest.source()
.aggregation(AggregationBuilders
.terms("aggBucket")
.field("brand")
.size(10)
)
.size(0);
// 3、发送请求
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
}
度量Metric聚合
@Test
void testMetricStatsAgg() throws IOException {
// 1、准备requets
SearchRequest searchRequest = new SearchRequest("hotel");
// 2、封装DSL
searchRequest.source()
.aggregation(AggregationBuilders
.stats("aggScore")
.field("score")
)
.size(0);
// 3、发送请求
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 4、处理响应结果
handlerResponse(response);
}
自动补全功能
安装拼音分词器
https://github.com/medcl/elasticsearch-analysis-pinyin
-
安装的步骤与ik分词器一致
-
测试用法,
POST /_analyze
{
"text": "如家酒店还不错",
"analyzer": "pinyin"
}
分词器的三个组成部分
-
从pinyin分词器上直接来看,完全不符合我们的预期,因此需要自定义分词器
-
我们还需要考虑到我们需要中文分词的。因此可以先用中文分词器分词之后,再保留拼音分词器。
elasticsearch中分词器(analyzer)的组成包含三部分:
- character filters:在tokenizer之前对文本进行处理。例如删除字符、替换字符
- tokenizer:将文本按照一定的规则切割成词条(term)。例如keyword,就是不分词;还有ik_smart
- tokenizer filter:将tokenizer输出的词条做进一步处理。例如大小写转换、同义词处理、拼音处理等
自定义分词器(只是设置映射时需要使用拼音分词器,查询依然用ik)
PUT /test
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
}
},
"filter": {
"py": {
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "my_analyzer",
"search_analyzer": "ik_smart"
}
}
}
}
自动补全
-
需要自动补全的字段必须为 completion类型
-
自动补全的功能为suggest建议
-
使用示例
// 创建索引库
PUT test
{
"mappings": {
"properties": {
"title":{
"type": "completion"
}
}
}
}
// 示例数据
POST test/_doc
{
"title": ["Sony", "WH-1000XM3"]
}
POST test/_doc
{
"title": ["SK-II", "PITERA"]
}
POST test/_doc
{
"title": ["Nintendo", "switch"]
}
// 自动补全查询
GET /test/_search
{
"suggest": {
"title_suggest": {
"text": "s", // 关键字
"completion": {
"field": "title", // 补全查询的字段
"skip_duplicates": true, // 跳过重复的
"size": 10 // 获取前10条结果
}
}
}
}
酒店自动补全功能
-
前台: 监听键盘输入,输入后发送一个请求,向后台获取一个List<String>
-
后台实现思路
- 重建ES中的索引库,增加一个字段suggestion,类型为completion
- 与ES进行交互的POJO类也需要增加一个字段suggestion,类型为List<String>
- 从MYSQL向ES导入数据时,会用到该POJO类,将需要自动补全的字段的String内容add到suggesion这个List变量当中
- 重新为ES填充数据
- 直接查询就好,后台通过RestAPI进行处理
新建索引库(核心在于自定义分词器,还有一个自动补全的字段)
PUT /hotel
{
"settings": {
"analysis": {
"analyzer": {
"text_anlyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
},
"completion_analyzer": {
"tokenizer": "keyword",
"filter": "py"
}
},
"filter": {
"py": {
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"id":{
"type": "keyword"
},
"name":{
"type": "text",
"analyzer": "text_anlyzer",
"search_analyzer": "ik_smart",
"copy_to": "all"
},
"address":{
"type": "keyword",
"index": false
},
"price":{
"type": "integer"
},
"score":{
"type": "integer"
},
"brand":{
"type": "keyword",
"copy_to": "all"
},
"city":{
"type": "keyword"
},
"starName":{
"type": "keyword"
},
"business":{
"type": "keyword",
"copy_to": "all"
},
"location":{
"type": "geo_point"
},
"pic":{
"type": "keyword",
"index": false
},
"all":{
"type": "text",
"analyzer": "text_anlyzer",
"search_analyzer": "ik_smart"
},
"suggestion":{
"type": "completion",
"analyzer": "completion_analyzer"
}
}
}
}
添加POJO类字段
// 自动补全功能
private List<String> suggestion;
if (this.business.contains("/")) {
String[] arr = this.business.split("/");
this.suggestion = new ArrayList<>();
this.suggestion.add(this.brand);
Collections.addAll(this.suggestion, arr);
}else {
this.suggestion = Arrays.asList(this.brand, this.business);
}
后台处理请求的代码
@Override
public List<String> suggestion(String key) {
try {
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
request.source().suggest(new SuggestBuilder().addSuggestion(
"suggestions",
SuggestBuilders.completionSuggestion("suggestion")
.prefix(key)
.skipDuplicates(true)
.size(10)
));
// 3.发起请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析结果
Suggest suggest = response.getSuggest();
// 4.1.根据补全查询名称,获取补全结果
CompletionSuggestion suggestions = suggest.getSuggestion("suggestions");
// 4.2.获取options
List<CompletionSuggestion.Entry.Option> options = suggestions.getOptions();
// 4.3.遍历
List<String> list = new ArrayList<>(options.size());
for (CompletionSuggestion.Entry.Option option : options) {
String text = option.getText().toString();
list.add(text);
}
return list;
} catch (IOException e) {
throw new RuntimeException(e);
}
}
数据同步问题
-
我们的ES数据都是从MYSQL来的,那么一旦MYSQL的数据发生了增删改,就需要同步到ES中
-
这个时候可以考虑使用消息中间件
在MYSQL发生数据的增删改时,发送一个消息(采用Topic模型)
@PostMapping
public void saveHotel(@RequestBody Hotel hotel) {
hotelService.save(hotel);
// 通知更新ES
rabbitTemplate.convertAndSend("ElasticSearchExChange", "insertOrUpdate.es", hotel.getId());
}
@PutMapping()
public void updateById(@RequestBody Hotel hotel) {
if (hotel.getId() == null) {
throw new InvalidParameterException("id不能为空");
}
hotelService.updateById(hotel);
// 通知更新ES
rabbitTemplate.convertAndSend("ElasticSearchExChange", "insertOrUpdate.es", hotel.getId());
}
@DeleteMapping("/{id}")
public void deleteById(@PathVariable("id") Long id) {
hotelService.removeById(id);
// 通知更新ES
rabbitTemplate.convertAndSend("ElasticSearchExChange", "delete.es", id);
}
同步ES数据,监听
@Component
public class EsSyncListener {
@Autowired
IHotelService iHotelService;
@Autowired
RestHighLevelClient client;
/**
* 由于ES的增量更新,如果没有id,则为新建,因此一个足矣
*
* @param id
*/
@RabbitListener(bindings = @QueueBinding(
value = @Queue(value = "insertESQueue"),
exchange = @Exchange(value = "ElasticSearchExChange",type = ExchangeTypes.TOPIC),
key = "insertOrUpdate.es"
))
public void insertOrUpdateEs(Long id) {
try {
Hotel hotel = iHotelService.getById(id);
HotelDoc hotelDoc = new HotelDoc(hotel);
IndexRequest indexRequest = new IndexRequest("hotel");
indexRequest.source(JSON.toJSONString(hotelDoc), XContentType.JSON);
client.index(indexRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
/**
* 用于同步删除ES中的数据
*
* @param id
*/
@RabbitListener(bindings = @QueueBinding(
value = @Queue(value = "deleteESQueue"),
exchange = @Exchange(value = "ElasticSearchExChange",type = ExchangeTypes.TOPIC),
key = "delete.es"
))
public void deleteEs(Long id) {
try {
DeleteRequest request = new DeleteRequest("hotel", String.valueOf(id));
client.delete(request, RequestOptions.DEFAULT);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
感兴趣的话也可以定义个常量类
public class MqConstants {
/**
* 交换机
*/
public final static String HOTEL_EXCHANGE = "hotel.topic";
/**
* 监听新增和修改的队列
*/
public final static String HOTEL_INSERT_QUEUE = "hotel.insert.queue";
/**
* 监听删除的队列
*/
public final static String HOTEL_DELETE_QUEUE = "hotel.delete.queue";
/**
* 新增或修改的RoutingKey
*/
public final static String HOTEL_INSERT_KEY = "hotel.insert";
/**
* 删除的RoutingKey
*/
public final static String HOTEL_DELETE_KEY = "hotel.delete";
}
业务处理实战
封装查询条件
封装多个查询结果Bool
处理全文检索
处理关键字过滤
处理价格范围
设置经纬度范围排序
设置分页参数
设置排序
设置算分查询
封装处理高亮结果
处理响应结果
处理高亮字段
封装地理位置的距离
@Service
public class HotelService extends ServiceImpl<HotelMapper, Hotel> implements IHotelService {
@Autowired
private RestHighLevelClient client;
@Override
public PageResult search(RequestParams requestParams) {
try {
// 1、获取request
SearchRequest searchRequest = new SearchRequest("hotel");
// 2、封装DSL、封装查询条件
handlerBasicQuery(searchRequest, requestParams);
// 3、发送请求
SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);
// 4、处理结果 并 返回
return handlerResponse(response);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
/**
* 封装请求条件
* @param searchRequest
* @param requestParams
*/
private void handlerBasicQuery(SearchRequest searchRequest, RequestParams requestParams) {
String key = requestParams.getKey();
String brand = requestParams.getBrand();
String city = requestParams.getCity();
Integer minPrice = requestParams.getMinPrice();
Integer maxPrice = requestParams.getMaxPrice();
String starName = requestParams.getStarName();
Integer page = requestParams.getPage();
Integer size = requestParams.getSize();
String sortBy = requestParams.getSortBy();
String location = requestParams.getLocation();
// 1、构建一个Bool查询
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
// 2、处理全文检索
if (StringUtils.isNotBlank(key)) {
boolQueryBuilder.must(QueryBuilders.matchQuery("all", key));
}else {
// 没有关键字则查询所有
boolQueryBuilder.must(QueryBuilders.matchAllQuery());
}
// 3、处理品牌brand关键字过滤
if(StringUtils.isNotBlank(brand)) {
boolQueryBuilder.filter(QueryBuilders.termQuery("brand", brand));
}
// 4、处理城市city关键字过滤
if(StringUtils.isNotBlank(city)){
boolQueryBuilder.filter(QueryBuilders.termQuery("city",city));
}
// 5、处理价格范围
if(minPrice != null && maxPrice != null) {
boolQueryBuilder.filter(QueryBuilders.rangeQuery("price").gte(minPrice).lte(maxPrice));
}
// 6、处理星级酒店过滤
if (StringUtils.isNotBlank(starName)) {
boolQueryBuilder.filter(QueryBuilders.termQuery("starName", starName));
}
// 7、设置经纬度过滤
if (StringUtils.isNotBlank(location)) {
searchRequest
.source()
.sort(SortBuilders
.geoDistanceSort("location",new GeoPoint(location))
.unit(DistanceUnit.KILOMETERS)
.order(SortOrder.ASC));
}
// 8、设置分页参数
if (page != null || page > 0) {
// 设置分页参数
searchRequest.source().from((page - 1) * size).size(size);
}
// 9、设置排序
if (StringUtils.isNotBlank(sortBy) && !"default".equals(sortBy)) {
searchRequest.source().sort(sortBy);
}
// 10、算分查询,为投了广告的人搞一搞、将查询条件交给searchRequest
searchRequest.source().query(
QueryBuilders.functionScoreQuery(
// 10.1 算分查询的基础查询条件
boolQueryBuilder,
// 10.2 判断字段的isAd是否为true,如果为true,则为其 分数 * 10倍
new FunctionScoreQueryBuilder.FilterFunctionBuilder[]{
new FunctionScoreQueryBuilder.FilterFunctionBuilder(
QueryBuilders.termQuery("isAd", true),
ScoreFunctionBuilders.weightFactorFunction(10)
)
}).boostMode(CombineFunction.MULTIPLY)
);
}
private PageResult handlerResponse(SearchResponse response) {
SearchHits hits = response.getHits();
// 获取总条目数
long total = hits.getTotalHits().value;
// 封装数据
SearchHit[] hitList = hits.getHits();
List<HotelDoc> list = new ArrayList<>();
for (SearchHit hit : hitList) {
// 获取到每一条记录
String record = hit.getSourceAsString();
// 封装成HotelDoc对象
HotelDoc hotelDoc = JSON.parseObject(record, HotelDoc.class);
// 处理高亮字段
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
// 1、健壮性判断,判断Map集合是否为空
if (!CollectionUtils.isEmpty(highlightFields)) {
// 2、获取到高亮字段结果
HighlightField nameFiled = highlightFields.get("name");
// 3、判断结果是否为空
if (ObjectUtils.isNotEmpty(nameFiled)) {
// 获取到高亮的具体结果:Text
Text[] fragments = nameFiled.getFragments();
// 由于只需要获取到数组中第一个元素赋值,因此判断下
if (fragments.length > 0) {
hotelDoc.setName(fragments[0].string());
}
}
}
// 处理距离当前多远
Object[] sortValues = hit.getSortValues();
if(sortValues != null && sortValues.length > 0) {
hotelDoc.setDistance(sortValues[0]);
}
// 存储
list.add(hotelDoc);
}
// 返回结果
return new PageResult(list, total);
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号