深入理解数据库连接池:从概念到实践
深入理解数据库连接池:从概念到实践
引言
在现代Web应用开发中,数据库连接的管理是一个至关重要的环节。传统的数据库连接管理方式在高并发环境下存在性能瓶颈,而数据库连接池技术通过预先创建和管理数据库连接,显著提高了系统的性能和稳定性。本文将深入探讨数据库连接池的概念、优势、实现方式以及如何在实际项目中使用Druid连接池。
数据库连接池简介
什么是数据库连接池?
想象一下,你正在开发一个Web应用,用户频繁地访问数据库。每次用户请求都需要建立一个新的数据库连接,这就像每次吃饭都要重新买一套餐具一样,既浪费时间又浪费资源。数据库连接池就像一个餐具消毒柜,里面预先准备好了干净的餐具(数据库连接),用户可以直接使用,用完后放回消毒柜,下次再用。
数据库连接池是一个容器,负责分配、管理数据库连接(Connection)。它允许应用程序重复使用现有的数据库连接,而不是每次都重新建立连接。连接池还负责释放空闲时间超过最大空闲时间的数据库连接,以避免因未释放连接而引起的数据库连接遗漏。
数据库连接池的好处
- 资源重用:通过重复使用现有的数据库连接,减少了频繁创建和销毁连接的开销。
- 提升系统响应速度:预先创建的连接可以立即使用,减少了等待连接建立的时间。
- 避免数据库连接遗漏:连接池会自动释放空闲时间过长的连接,避免了因未释放连接而导致的资源泄漏。
数据库连接池的实现
标准接口:DataSource
SUN公司提供了数据库连接池的标准接口DataSource,由第三方组织实现此接口。DataSource接口的主要功能是获取数据库连接:
Connection getConnection()
常见的数据库连接池
- DBCP:Apache Commons Database Connection Pool,由Apache组织开发。
- C3P0:一个开源的JDBC连接池,支持JDBC3规范和JDBC2的标准扩展。
- Druid:阿里巴巴开源的数据库连接池项目,功能强大,性能优秀,是Java语言中最好的数据库连接池之一。
Druid连接池:阿里巴巴的杰作
Druid连接池的优势
Druid连接池是阿里巴巴开发的数据库连接池,号称“为监控而生”。它在功能、性能和扩展性方面都超过了其他数据库连接池,已经在阿里巴巴部署了超过600个应用,并经过一年多生产环境大规模部署的严苛考验,如双十一活动和春运抢票。
Druid常用的配置参数
- url:数据库连接字符串,如
jdbc:mysql://localhost:3306/数据库名。 - username:数据库用户名。
- password:数据库密码。
- driverClassName:驱动类名,通常根据url自动识别,可不配置。
- initialSize:初始化时建立的物理连接个数。
- maxActive:连接池中最大连接数。
- maxWait:获取连接时的最长等待时间,单位是毫秒。
Druid连接池的基本使用
核心类:DruidDataSourceFactory
Druid连接池的核心类是DruidDataSourceFactory,它提供了创建连接池的方法:
public static DataSource createDataSource(Properties properties);
Druid使用步骤
-
导入jar包:下载并导入
druid-1.1.12.jar。 -
定义配置文件:在项目根目录或
src目录下创建druid.properties文件,定义数据库连接参数。
# 数据库连接参数
url=jdbc:mysql://localhost:3306/day05
username=root
password=1234
driverClassName=com.mysql.jdbc.Driver
- 加载配置文件:使用
ClassLoader加载配置文件。
InputStream in = DruidDemo.class.getClassLoader().getResourceAsStream("druid.properties");
Properties prop = new Properties();
prop.load(in);
- 获取数据库连接池对象:使用
DruidDataSourceFactory创建连接池。
DataSource dataSource = DruidDataSourceFactory.createDataSource(prop);
- 获取连接:从连接池中获取数据库连接。
Connection conn = dataSource.getConnection();
- 执行SQL语句:使用获取的连接执行SQL操作。
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery("SELECT * FROM users");
- 关闭资源,归还连接:释放资源并将连接归还给连接池。
rs.close();
stmt.close();
conn.close(); // 将连接归还给连接池
详细步骤解析
1. 导入jar包
首先,你需要下载Druid的jar包并将其导入到你的项目中。你可以从Druid的GitHub页面下载最新的jar包。
2. 定义配置文件
在项目的src目录下创建一个名为druid.properties的文件,并在其中定义数据库连接参数。这些参数将用于配置Druid连接池。
# 数据库连接参数
url=jdbc:mysql://localhost:3306/day05
username=root
password=1234
driverClassName=com.mysql.jdbc.Driver
3. 加载配置文件
使用Java的ClassLoader加载配置文件。ClassLoader会从项目的src目录中查找并加载druid.properties文件。
InputStream in = DruidDemo.class.getClassLoader().getResourceAsStream("druid.properties");
Properties prop = new Properties();
prop.load(in);
4. 获取数据库连接池对象
使用DruidDataSourceFactory的createDataSource方法创建一个Druid连接池对象。这个方法会根据配置文件中的参数初始化连接池。
DataSource dataSource = DruidDataSourceFactory.createDataSource(prop);
5. 获取连接
从连接池中获取一个数据库连接。这个连接是预先创建好的,可以直接使用。
Connection conn = dataSource.getConnection();
6. 执行SQL语句
使用获取的连接执行SQL操作。例如,查询数据库中的用户信息。
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery("SELECT * FROM users");
7. 关闭资源,归还连接
在操作完成后,关闭ResultSet和Statement,并将连接归还给连接池。注意,这里的conn.close()并不会真正关闭连接,而是将连接归还给连接池,以便下次使用。
rs.close();
stmt.close();
conn.close(); // 将连接归还给连接池
demo
package d_druid;
import com.alibaba.druid.pool.DruidDataSourceFactory;
import javax.sql.DataSource;
import java.io.FileInputStream;
import java.io.IOException;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.util.Properties;
public class App {
public static void main(String[] args) {
try {
//1.导入jar包
//2.在src下面创建配置文件,书写配置参数
//3.使用德鲁伊核心类调用静态方法获取连接池对象
//创建属性集对象
Properties properties = new Properties();
properties.load(new FileInputStream("jdbc-app\\src\\druid.properties"));
DataSource dataSource = DruidDataSourceFactory.createDataSource(properties);
//4.使用连接池对象调用方法从连接池中获取连接池
Connection connection = dataSource.getConnection();
//5.使用连接对象获取预编译对象
PreparedStatement preparedStatement = connection.prepareStatement("select *from tb_account");
//6.执行sqL
ResultSet resultSet = preparedStatement.executeQuery();
//7.处理结果集
while(resultSet.next()){
int id = resultSet.getInt(1);
String userName = resultSet.getString(2);
String passWord = resultSet.getString(3);
System.out.println(id+"---"+userName+"---"+passWord);
}
//8.释放资源
if(resultSet!=null)
resultSet.close();
if(preparedStatement!=null)
preparedStatement.close();
if(connection!=null)
connection.close();
} catch (IOException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
}
}
connection = DriverManager.getConnection(url, userName, passWord);
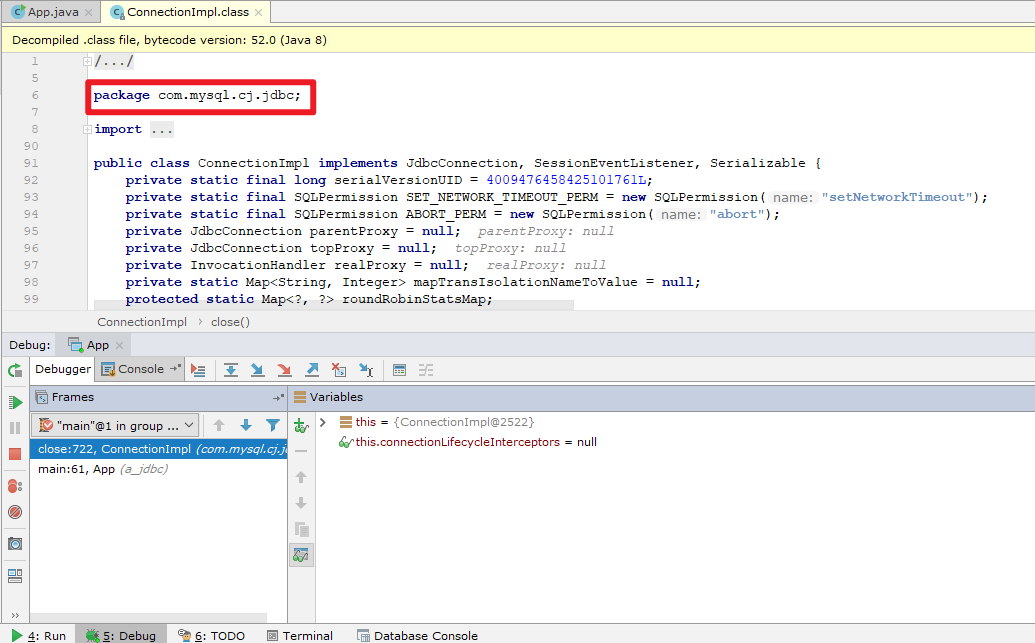
这种是通过 JDBC API 中的 DriverManager 类来获取数据库连接的。这种方式是传统的、直接的数据库连接方式,释放资源的时候 走的是package com.mysql.cj.jdbc下的close方法,打断点可以看到
Connection connection = dataSource.getConnection();
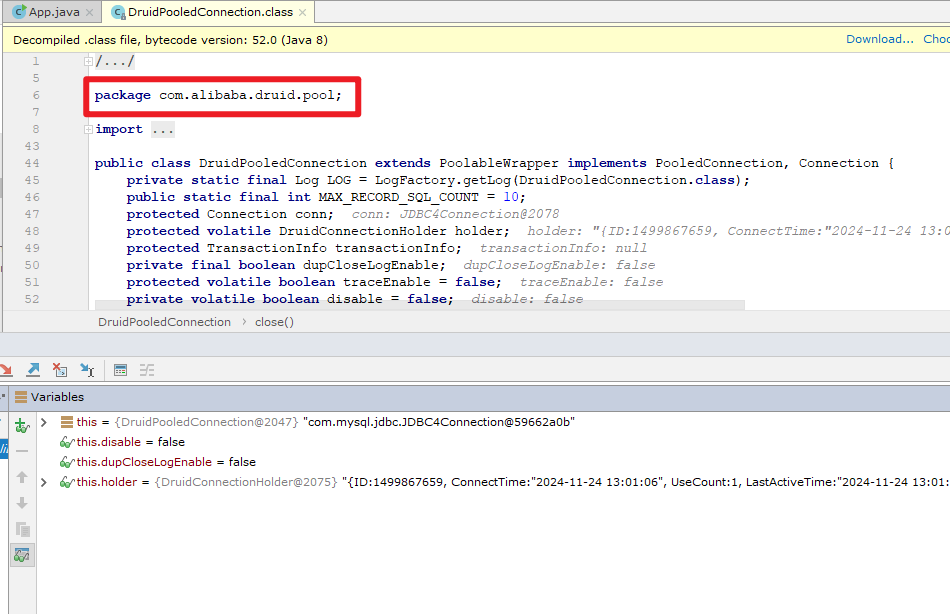
这种是通过 Druid 连接池获取数据库连接的。释放资源的时候 走的是package com.alibaba.druid.pool下的close方法 打断点可以看到
数据库连接池 线程池
Druid 数据库连接池和线程池在概念上有一些相似之处,但它们的功能和应用场景是不同的。
1. 数据库连接池(Druid)
- 功能:Druid 是一个开源的数据库连接池库,主要用于管理数据库连接的生命周期。它负责创建、管理和复用数据库连接,以提高数据库访问的效率和性能。
- 应用场景:主要用于数据库操作,如 SQL 查询、数据插入、更新等。
- 核心目标:优化数据库连接的创建和销毁过程,减少数据库连接的开销,提高数据库操作的效率。
2. 线程池
- 功能:线程池是一种并发编程技术,用于管理和复用线程。它负责创建、管理和复用线程,以减少线程创建和销毁的开销,提高并发处理能力。
- 应用场景:主要用于并发任务处理,如网络请求处理、文件操作、计算任务等。
- 核心目标:优化线程的创建和销毁过程,减少线程切换的开销,提高并发任务处理的效率。
相似之处
- 资源管理:两者都涉及对资源的复用和管理,以减少资源创建和销毁的开销。
- 性能优化:两者都旨在提高系统的性能和效率,通过复用资源来减少不必要的开销。
不同之处
- 资源类型:Druid 管理的是数据库连接,而线程池管理的是线程。
- 应用场景:Druid 主要用于数据库操作,而线程池主要用于并发任务处理。
- 实现方式:Druid 是一个具体的数据库连接池实现,而线程池是一个通用的并发编程概念,有多种实现方式(如 Java 的
ExecutorService)。
总结
虽然 Druid 数据库连接池和线程池在资源管理和性能优化方面有相似之处,但它们的功能和应用场景是不同的。Druid 专注于数据库连接的管理,而线程池专注于线程的管理。
总结
数据库连接池技术通过预先创建和管理数据库连接,显著提高了系统的性能和稳定性。Druid连接池作为阿里巴巴开源的优秀数据库连接池,在功能、性能和扩展性方面都表现出色,是Java开发中不可或缺的工具。通过合理配置和使用Druid连接池,可以有效提升Web应用的响应速度和资源利用率,避免数据库连接遗漏等问题。
希望本文能帮助你更好地理解数据库连接池的概念和使用方法,并在实际开发中应用这种技术,提升你的开发效率和系统性能。
参考资料
希望本文能帮助你更好地理解数据库连接池,并在实际开发中应用这种技术,提升你的开发效率和系统性能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号