数据预处理--离散变量处理
离散变量标签处理
1.类别变量映射为原始变量
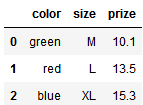
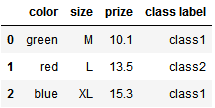
原始数据
import pandas as pd df = pd.DataFrame([ ['green', 'M', 10.1, 'class1'], ['red', 'L', 13.5, 'class2'], ['blue', 'XL', 15.3, 'class1']]) df.columns = ['color', 'size', 'prize', 'class label']
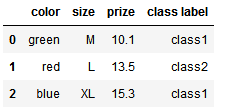
1.1 方法1:原始处理方法(将类别变量映射为数值变量)
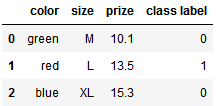
# 自动映射 class_mapping = {label:idx for idx,label in enumerate(set(df['class label']))} df['class label'] = df['class label'].map(class_mapping) # 指定映射对 size_mapping = { 'XL': 3, 'L': 2, 'M': 1} df['size'] = df['size'].map(size_mapping) color_mapping = { 'green': (0,0,1), 'red': (0,1,0), 'blue': (1,0,0)} df['color'] = df['color'].map(color_mapping) # 逆映射 inv_color_mapping = {v: k for k, v in color_mapping.items()} inv_size_mapping = {v: k for k, v in size_mapping.items()} inv_class_mapping = {v: k for k, v in class_mapping.items()} df['color'] = df['color'].map(inv_color_mapping) df['size'] = df['size'].map(inv_size_mapping) df['class label'] = df['class label'].map(inv_class_mapping)
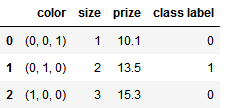
原始方法2:
# 方法1:将sex列中的male,female分别映射为0,1 titanic.loc[titanic["Sex"] == "male", "Sex"] = 0 titanic.loc[titanic["Sex"] == "female", "Sex"] = 1 #将Embarked列的S,C,Q分别映射为0,1,2 titanic.loc[titanic["Embarked"] == "S", "Embarked"] = 0 titanic.loc[titanic["Embarked"] == "C", "Embarked"] = 1 titanic.loc[titanic["Embarked"] == "Q", "Embarked"] = 2 # 方法2:将sex列中的male,female分别映射为0,1 titanic["Sex"]=np.where(titanic["Sex"]=="male",0,1) # 根据值不同映射为相应的值 data['type']=np.where(data['type']==0,data['type1'],data['type2'])
1.2 方法2:使用scikit LabelEncoder处理标签变量映射
# 标签类型----数值类型映射 from sklearn.preprocessing import LabelEncoder class_le = LabelEncoder() df['class label'] = class_le.fit_transform(df['class label']) # 逆映射 class_le.inverse_transform(df['class label'])
2. 类别变量热编码
2.1 方法1:OneHotEncoder(OneHotEncoder 必须使用整数作为输入,所以得先预处理一下)
# 数据预处理 color_le = LabelEncoder() df['color'] = color_le.fit_transform(df['color']) #热编码 from sklearn.preprocessing import OneHotEncoder ohe = OneHotEncoder(sparse=False) X = ohe.fit_transform(df[['color']].values)

2.2 方法2:get_dummies(只处理类别型变量)
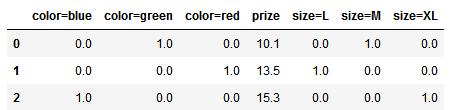
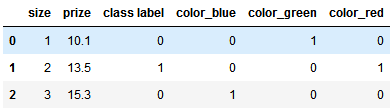
# 数据预处理 import pandas as pd df = pd.DataFrame([ ['green', 'M', 10.1, 'class1'], ['red', 'L', 13.5, 'class2'], ['blue', 'XL', 15.3, 'class1']]) df.columns = ['color', 'size', 'prize', 'class label'] size_mapping = { 'XL': 3, 'L': 2, 'M': 1} df['size'] = df['size'].map(size_mapping) class_mapping = {label:idx for idx,label in enumerate(set(df['class label']))} df['class label'] = df['class label'].map(class_mapping) # 热编码 pd.get_dummies(df)
2.3 方法3:scikit DictVectorizer 热编码(只处理类别型变量)
# 数据预处理 df.transpose().to_dict().values() feature = df.iloc[:, :-1] feature # 热编码 from sklearn.feature_extraction import DictVectorizer dvec = DictVectorizer(sparse=False) X = dvec.fit_transform(feature.transpose().to_dict().values()) pd.DataFrame(X, columns=dvec.get_feature_names())